Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
SQLAlchemy pozwala na translację pomiędzy strukturą relacyjną w relacyjnych bazach danych, a strukturą obiektową i odwrotnie. Jest to zdecydowanie wygodniejsze rozwiązanie niż używanie takich bibliotek jak cx_Oracle czy psycopg2. Aby rozpocząć pracę z SQLAlchemy musimy zainstalować niezbędny pakiet :
pip install flask-sqlalchemyPoza samym modułem potrzebujesz też lokalnej bazy PostgreSQL jeśli chcesz przetestować mój kod. Po zainstalowaniu PostgreSQL trzeba jeszcze utworzyć bazę danych i użytkownika poniższymi komendami z poziomu PGAdmina:
create database demo;
create user demo with password 'demo';Aby rozpocząć pracę z SQLAlchemy trzeba najpierw zainicjalizować podając jej właściwy kontekst:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://demo:demo@localhost/demo'
db = SQLAlchemy(app)Obiekt „db” to obiekt który będziemy wykorzystywać odwołując się do bazy. Przyszedł czas na obiektową reprezentację danych relacyjnych. Dla każdej tabelki/widoku tworzymy klasę dziedziczącą po klasie db.Model:
class Product(db.Model):
__tablename__ = "products"
productId = db.Column(db.Integer, name="product_id", primary_key=True)
productName = db.Column(db.String, name="product_name", unique=True)
productDescription = db.Column(db.String, name="product_description", nullable=True)
productPrice = db.Column(db.Numeric, name="product_price", index=True)W powyższym przykładzie użyłem kilku różnorakich argumentów by zaprezentować co ciekawsze możliwości. Nieco enigmatyczne pole „__tablename__” określa nazwę tabeli jeśli jest inna niż klasa - przydatne gdy w Pythonie używasz camelCase’a a w bazach takiego_nazewnictwa. Każde pole tej klasy jest obiektem klasy Column której argumenty inicjalizacyjne wymieniam poniżej:
Jeśli chciałbyś aby tabelki utworzyły się same, wywołaj jednokrotnie metodę:
db.create_all()Po jej uruchomieniu w bazie danych powstaną tabelki dla wszystkich klas dziedziczących po db.Model. Skutek po stronie PostgreSQL:
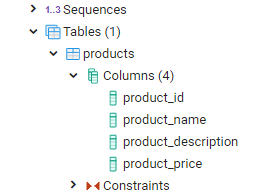
Jeśli jest jakiś problem z kontaktem z bazą, ujawni się na tym etapie.

Tabelka została utworzona przez SQLAlchemy automagicznie. Jeśli nie chcesz tworzyć tabel tylko korzystać z istniejących tabel, zwyczajnie nie wywołuj metody create_all(). Gdyby przy zapytaniu okazało się że tabelka jednak nie istnieje, otrzymamy wyjątek. Istnieje też metoda db.drop_all(), a jej nazwa chyba wyjaśnia wszystko ;). Na potrzeby dalszych działań wzbogaciłem moją klasę o dwie dodatkowe metody i w całości wygląda ona teraz tak:
class Product(db.Model):
__tablename__ = "products"
productId = db.Column(db.Integer, name="product_id", primary_key=True)
productName = db.Column(db.String, name="product_name", unique=True)
productDescription = db.Column(db.String, name="product_description", nullable=True)
productPrice = db.Column(db.Numeric, name="product_price", index=True)
def __init__(self, pn, pd, pp):
self.productName=pn
self.productDescription=pd
self.productPrice=pp
def __str__(self):
return f'productId={self.productId}, productName={self.productName}, productDescription={self.productDescription}, productPrice={self.productPrice}'Aby dodać dane do bazy należy w pierwszej kolejności utworzyć obiekty encyjne - tj. obiekty które mamy zamiar utralać. W poniższym przykładowym kodzie tworzę 3 trakie obiekty, a następnie przekazuję je jako argument do metody add. Jest to zapis transakcyjny, toteż aby zmiany w bazie były widoczne trzeba zatwierdzić transakcję, co czynimy wywołując metodę commit():
def loadSomeData():
p1 = Product('Bulbulator', 'Robi bul bul', 100)
p2 = Product('Półoś do Jelcza', '3ma koło', 80)
p3 = Product('Wahacz to taczki', 'Do taczek wyścigowych', 500)
db.session.add(p1)
db.session.add(p2)
db.session.add(p3)
db.session.commit()Całość opakowałem w funkcję by móc osobno wywołać proces jednorazowo, co też po deklaracji uczyniłem. Tobie proponuję zrobić to samo, zanim przejdziemy do dalszej części.
Przypomnij sobie deklarację klasy Product. Był tam taki fragment:
class Product(db.Model):oznaczający że nasza klasa dziedziczy po klasie Model. Dzięki temu dziedziczeniu użytkujemy kilka ciekawych możliwości. Między innymi nasze obiekty będą posiadały metody umożliwiające pobieranie danych z bazy:
def getAllProducts():
return Product.query.all()Aby pobierać dane z bazy należy zatem po nazwie klasy podać „query” i metodę zwracającą dane. W powyższym przykładzie pokazuję pobieranie wszystkich danych, stosuję zatem metodę all(). Teraz zastosujemy filtrowanie:
def getProductsPriceOver(price):
return Product.query.filter(Product.productPrice>price).all()Tym razem pojawia nam się jeszcze metoda filter. Przyjrzyjmy się jej zawartości. Jest nazwa klasy, nazwa pola i warunek „>price”, gdzie price to argument metody. Funkcja ta zwróci wszystkie produkty o cenie wyższej niż podana przez argument. Gdybyś zechciał dodać kolejne warunki, robisz to w ten sposób:
def getProductsPriceOver(price):
return Product.query.filter(Product.productPrice>price).filter(1==1).all()Czyli po kropce stosujesz kolejne wywołania metody filter. Cały czas mówimy o zwracaniu listy elementów. Co jednak jeśli zechcemy zrobić funkcję zwracającą zawsze jeden obiekt. Nie ma sensu opakowywać go w listę poprzez metodę all(). W sytuacji gdy wiemy że zawsze będzie zwracany dokładnie jeden obiekt (bo filtrujemy z użyciem unikalnej kolumny) możemy wykorzystać metodę „first()”:
def getOneProductById(productId):
return Product.query.filter(Product.productId==productId).first()Do sortowania wyniku stosujemy metodę „order_by”. Umożliwia ona sortowanie rosnące i malejące. Jeśli chcesz posortować dane rosnąco robisz to w ten sposób:
def getAllProductsOrdered():
return Product.query.order_by(Product.productPrice).all()Należy podać nazwę pola po którym dane mają być sortowane. Gdybyś wolał sortowanie malejące:
def getAllProductsOrdered():
return Product.query.order_by(Product.productPrice.desc()).all()Metody filter i order_by można też stosować jednocześnie, należy jedynie pamiętać o właściwej kolejności:
def getProductsPriceOver(p):
return Product.query.filter(Product.productPrice>p).order_by(Product.productPrice).all()Ciekawostka - jaką funkcją aktualizujemy dane? Otóż jest to ta sama funkcja której używaliśmy do ich dodawania…

def changePrice(product,newPrice):
product.productPrice=newPrice
db.session.add(product) db.session.commit()Skąd zatem SQLAlchemy wie czy chcemy stworzyć nowy wpis w bazie czy zaktualizować istniejący? Na podstawie wypełnionego albo nie id obiektu. Oznaczyliśmy na etapie deklaracji klasy która kolumna jest kluczem głównym:
productId = db.Column(db.Integer, name="product_id", primary_key=True)Zatem jeśli chcesz zaktualizować obiekt, uzupełnij jego ID. Jeśli chcesz dodać nowy, podajesz go bez ID. Jeśli zmienisz id w obiekcie i wywołasz na nim zapis, dokonana zostanie aktualizacja ID a nie dodanie nowego obiektu.
Tu nie ma nic zaskakującego. Jak zapewne po zapoznaniu się z poprzednimi przykładami można się domyślić, istnieje metoda delete umożliwiająca nam takie działanie:
def deleteProduct(product):
db.session.delete(product)
db.session.commit()SQLAlchemy rozpoznaje obiekt do skasowania na podstawie wartości w kluczu głównym, podobnie jak w przypadku aktualizacji.
Zdarzają się sytuację że dostajemy od SQLAlchemy jakieś dziwne wyjątki i nie możemy zdiagnozować źródła problemu. W takich sytuacjach bardzo pomaga możliwość zweryfikowania generowanego przez SQLAlchemy SQLa. W tym celu zamiast od razu wywoływać metodę all(), odbierzemy najpierw obiekt zapytania. Jego reprezentacja po wydrukowaniu pokazuje właśnie wygenerowanego SQLa:
def showMeSQL(price):
q=Product.query.filter(Product.productPrice>price)
print(q)
return q.all()
showMeSQL(40)Zapytanie które otrzymałem:
SELECT products.product_id AS products_product_id, products.product_name AS products_product_name, products.product_description AS products_product_description, products.product_price AS products_product_price
FROM products
WHERE products.product_price > %(product_price_1)

Komentarze (0)
Brak komentarzy...