Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
Dodanie rollup do group by spowoduje wyświetlenie w ostatnim wierszu wyświetlenia podsumowanie wszystkich pogrupowanych elementów. Natomiast przy grupowaniu po więcej niż jednej kolumnie lub wyrażeniu otrzymamy nie tylko pogrupowane wyniki, ale także podsumowanie dla pierwszej kolumny lub wyrażenia, użytego do pogrupowania wyników.
select count(*) IlośćWierszy, ProductCategoryID, from SalesLT.Product where ProductCategoryID in (9,10,22,24) group by rollup (ProductCategoryID);
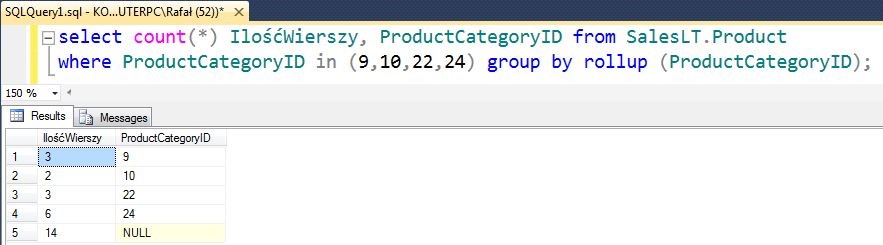
Wyświetlona została ilość wierszy z pogrupowaniem na odpowiedni identyfikator kategorii produktu. Do grupowania został dodany rollup dzięki czemu w ostatnim wierszu otrzymaliśmy podsumowanie wszystkich przeliczanych rekordów. Filtrowanie zostało użyte by pokazać działanie na mniejszej ilości danych.
select count(*) IlośćWierszy, ProductCategoryID, ProductModelID from SalesLT.Product where ProductCategoryID in (9,10,22,24) group by rollup (ProductCategoryID, ProductModelID);
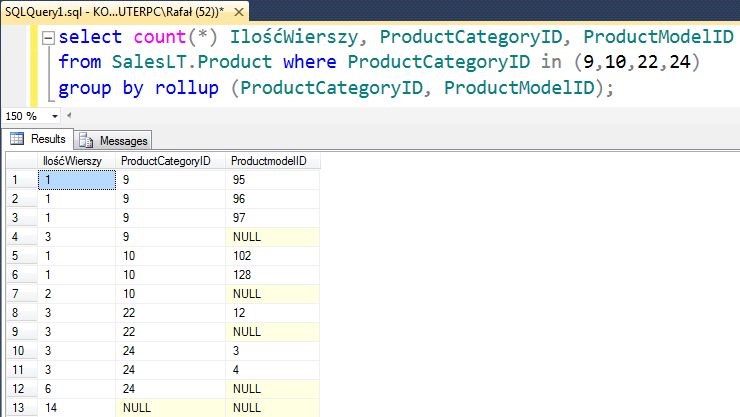
Wyświetlona została ilość wierszy, która została pogrupowana z uwzględnieniem odpowiedniego identyfikatora kategorii produktu, a następnie w ramach tych grup, nastąpiło kolejne grupowanie z rozróżnieniem na identyfikator modelu produktu. Do grupowania został dodany rollup dzięki czemu otrzymaliśmy podsumowanie dla pierwszego grupowania - po identyfikatorze kategorii produktu w ramach tej grupy, przed przejściem do grupowania do grupy – widać to w wierszu 4, 7, 9 i 12. W wierszu 13 otrzymaliśmy podsumowanie wszystkich przeliczanych rekordów.
Natomiast dodanie do instrukcji grupowania, przy grupowaniu po więcej niż jednej kolumnie lub wyrażeniu słowa cube spowoduje wygenerowanie podsumowań dla wszystkich możliwych kombinacji kolumn lub wyrażeń wymienionych w zapytaniu oraz dołączenie podsumowania wszystkich przeliczanych rekordów, lecz tym razem nie nastąpi to już w ostatnim wierszu wyświetlenia.
select count(*) IlośćWierszy, ProductCategoryID, ProductModelID from SalesLT.Product where ProductCategoryID in (9,10,22,24) group by cube (ProductCategoryID, ProductModelID);
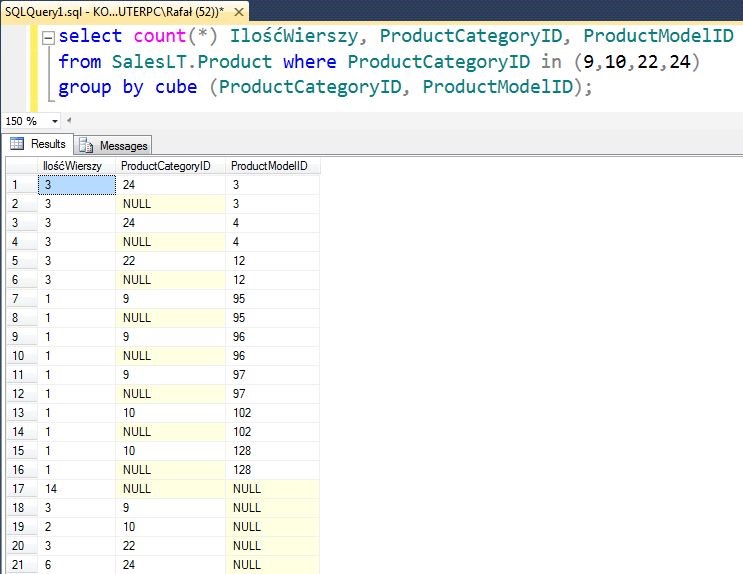
Wyświetlona została ilość wierszy, która została pogrupowana z uwzględnieniem odpowiedniego identyfikatora kategorii produktu, a następnie w ramach tych grup, nastąpiło kolejne grupowanie z rozróżnieniem na identyfikator modelu produktu. Do grupowania został dodany cube dzięki czemu otrzymaliśmy podsumowanie dla drugiego grupowania - po identyfikatorze modelu produktu w ramach tej grupy, przed przejściem do grupowania do grupy – widać to w wierszu 2, 4, 6, 8, 10, 12, 14, 16. W wierszu 17 otrzymaliśmy podsumowanie wszystkich przeliczanych rekordów. Natomiast dalej, w wierszu 18. 19. 20 i 21 otrzymaliśmy podsumowanie dla pierwszego grupowania - po identyfikatorze kategorii produktu.

Komentarze (0)
Brak komentarzy...