Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!

Beautiful Soup transformuje dokumenty HTML do postaci drzewa obiektów Python ( z dokumentacji : https://www.crummy.com/software/BeautifulSoup/bs4/doc/ ).
Pakiet Beautiful Soup 4 będziemy zwykle wykorzystywać w połączeniu z pakietem requests:
import requests as req
from bs4 import BeautifulSoup
Na potrzeby tego kursu przygotowałem plik html dostępny pod adresem:
http://jsystems.pl/static/data/pnl/dane.html
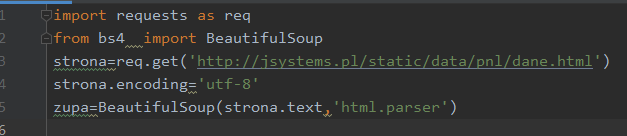
Tę właśnie stronę będziemy przetwarzać z użyciem biblioteki Beautiful Soup. Cała praca na stronie będzie się odbywać z użyciem obiektu klasy BeautifulSoup. Obiekt ten będzie reprezentował zawartość strony internetowej podczas jej przetwarzania. Przyjmuje on jako argument „konstruktora” tekst html strony. Podajemy mu ją jako tekst pobrany wcześniej za pomocą funkcji get biblioteki requests. Jako drugi argument „konstruktora” podajemy rodzaj parsera. Z użyciem tej biblioteki możemy parsować również pliki XML. W przedostatniej linii ustawiam jeszcze kodowanie. Na sąsiedniej stronie znajdziesz kod html który będziemy przetwarzać.
<html>
<head>
<title>Tytuł strony!</title>
<meta name="Author" content="Andrzej Klusiewicz"/>
</head>
<body>
<div id="calosc" class="bazowa">
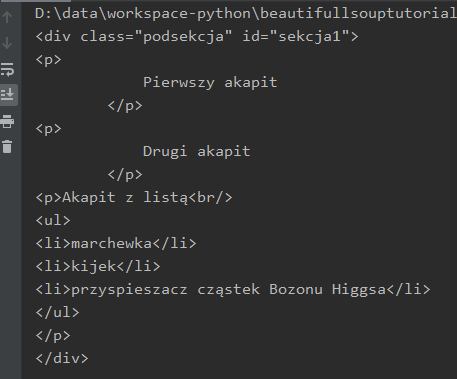
<div id="sekcja1" class="podsekcja">
<p>
Pierwszy akapit
</p>
<p>
Drugi akapit
</p>
<p>Akapit z listą<br>
<ul>
<li>marchewka</li>
<li>kijek</li>
<li>przyspieszacz cząstek Bozonu Higgsa</li>
</ul>
</p>
</div>
<div id="sekcja2" class="podsekcja">
Zawartość sekcji numer 2
</div>
<div id="sekcja3">
<div>
<p>Coś ciekawego przed
<h3>OMG!</h3> i coś ciekawego po</p>
</div>
</div>
<div id="sekcja4">
<ul>
<li class="punkty">punkt 1</li>
<li class="punkty">punkt 2</li>
<li class="punkty">punkt 3</li>
<li class="punkty">punkt 4</li>
</ul>
<table id="tabelka" border="1" width="50%" class="windows95">
<tr>
<td>1</td>
<td>Antarktyda</td>
</tr>
<tr>
<td>2</td>
<td>Syberia</td>
</tr>
<tr>
<td>3</td>
<td>Sosnowiec</td>
</tr>
</table>
</div>
<div name="stopka">To jest stopka</div>
</div>
</body>
</html>
Obiekt klasy BeautifulSoup (na który odtąd będę mówił zupa z racji że tak nazwałem zmienną) umożliwia wyszukiwanie elementów strony wg różnorakich kryteriów. Korzystając z nazw typów elementów – jak H1, TABLE, UL – możemy odnajdywać pierwsze wystąpienie takich elementów:
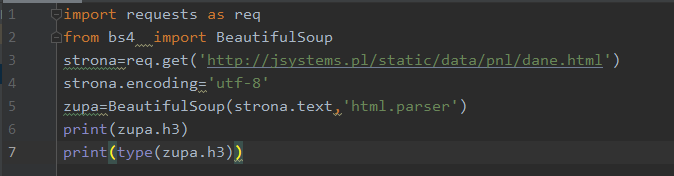
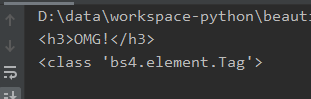
Wewnątrz div od id „sekcja3” znajduje się nagłówek H3 o treści „OMG!”. Powyższy kod pobiera pierwsze wystąpienie elementu h3 w całym dokumencie, a jest to właśnie wspomniany nagłówek. Przy okazji sprawdzam i drukuję również jego klasę:
Na elementach klasy Tag można wykonywać takie same operacje przeszukiwania jak na „zupie”. Toteż umożliwia to dalsze wchodzenie w głąb struktury. Równoznaczne byłoby zastosowanie funkcji find:
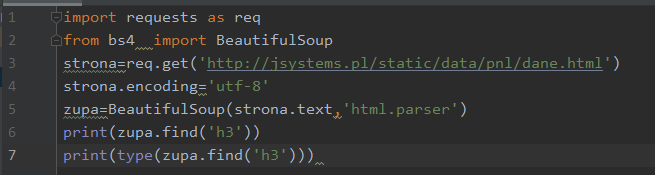
Jeśli jako argument funkcji find podamy rodzaj elementu, zostanie nam zwrócone pierwsze wystąpienie takiego elementu w pobranej stronie lub jej części.
Jeśli element do którego chcemy sięgnąć posiada ID możemy odnaleźć go stosując argument id dla funkcji find:
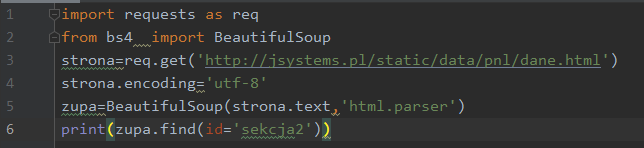
Zwrócone dane:
Funkcja find przyjmuje również argument class_ umożliwiający odniesienie się do klasy css wyszukiwanego elementu:
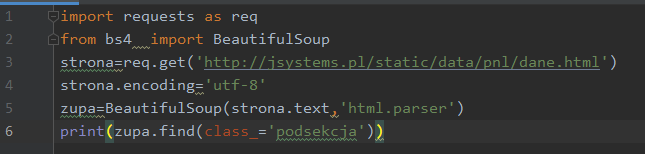
W sytuacji gdyby kilka elementów posiadało tę samą klasę (co jest całkiem naturalne) funkcja zwróci pierwsze wystąpienie takiego elementu. W związku z tym, wynik działania skryptu wygląda tak:
Jeśli element nie posiada id ani nie używa klasy css a chcielibyśmy mieć do niego jakiś uchwyt, możemy posłużyć się którymś z jego atrybutów. Taki element znajduje się na końcu wspomnianego na początku rozdziału dokumentu HTML:
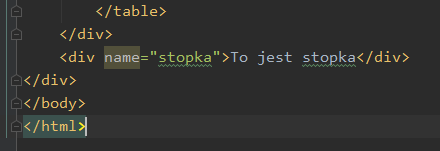
To może być zresztą jakikolwiek inny atrybut. Funkcja find posiada argument attrs. Podajemy do niego słownik z nazwami atrybutów i charakteryzującymi je wartościami:
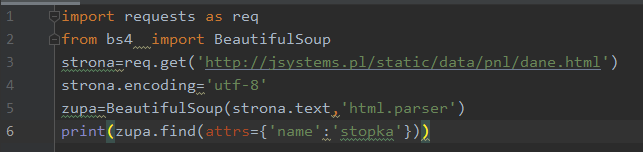
Wynik działania:
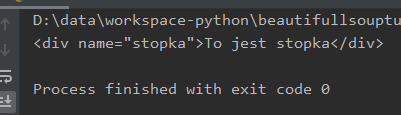
Każdy element zwracany przez funkcję find, ale również opisywane wcześniej uchwyty odnoszące się do nazw tagów html będą zwracały obiekt klasy Tag. Taki obiekt pozwala zagnieżdżać się dalej. W zasadzie nie ma tu ograniczeń ilościowych. Poniżej przykład takiego zagnieżdżania:
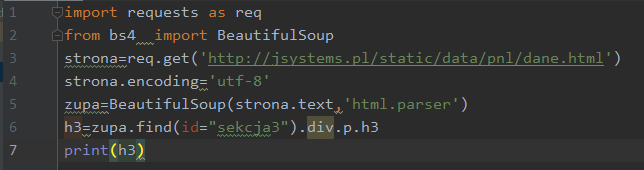
Wynik:
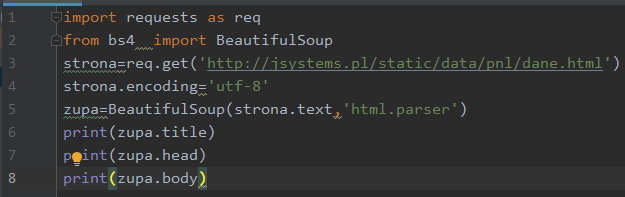
Podobnie jak mogliśmy wyszukiwać elementy po nazwach tagów – H1, UL, DIV etc tak możemy sięgać do nagłówka , tytułu strony czy jego body. Wyniku działania tego skryptu z czystej przyzwoitości nie przytoczę 12.
Obiekty klasy BeautifulSoup i Tag posiadają pole attrs zawierające w postaci słownika atrybuty elementu:
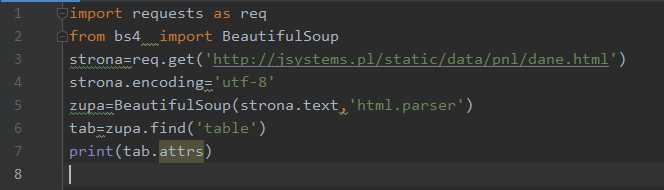
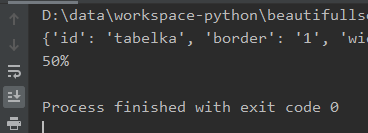
Analizowany przypadek to tabelka z takimi atrybutami:

Dane wyciągnięte z attrs:

Skoro to słownik to możemy go tak właśnie przetwarzać. Dopisuję jeszcze jedną linijkę kodu do skryptu by dostać się do wartości dla klucza „width”:

Wynik:
Każdy element ma name, nie każdy ma string. Name służy do sprawdzania nazwy elementu. Może to być użyteczne do sprawdzania jakiego rodzaju jest element wyszukany np. po id albo klasie. String do zawartość elementu – tekst z pomiędzy tagów początkowego i końcowego. Uwaga – nie każdy element będzie miał tam jakąś wartość – nie będą jej miały elementy będące jedynie kontenerami. Dla przykładu sięgnąłem do pierwszego elementu będącego tabelą i sprawdziłem jego typ. Następnie sięgnąłem do pierwszego akapitu i wyświetliłem jego zawartość:
Wynik:
Dotychczas operowaliśmy funkcją find, bądź odnosiliśmy się do pierwszych wystąpień elementów. Za każdym jednak razem pracowaliśmy z pojedynczym obiektem. Teraz przyszedł czas na przetwarzanie list elementów. Dla funkcji find_all działają te same filtry co dla funkcji find. Możesz wyszukiwać elementy w oparciu o ich id, klasę css czy atrybuty. Różnica polega jednak na tym, że tym razem nie dostaniemy w wyniku obiektu klasy Tag, a ResultSet. Jest to implementacja wzorca projektowego Iterator. Na początek użyjemy funkcji find_all bez jakichkolwiek argumentów. W efekcie dostaniemy listę wszystkich elementów (pierwszego poziomu zagnieżdżenia ale i tych głębiej) występujących w dokumencie. Iteruję po zwróconej liście i wyświetlam nazwy typu elementu:
Wynik działania skryptu:
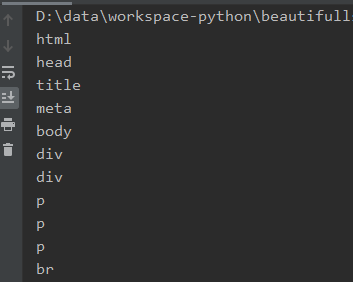
Uciąłem sporą część ze względu na objętość jaką zajmował cały wynik. Widzimy tu dosłownie wszystkie elementy – od strukturalnych jak head do akapitów.
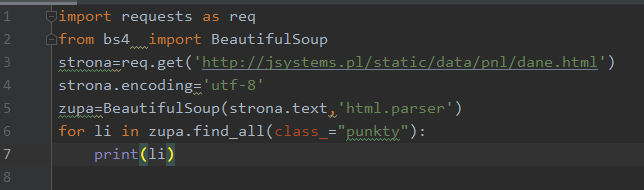
Podobnie jak funkcja find, funkcja find_all przyjmuje różnorakie argumenty. Wszystkie argumenty omawiane dla funkcji find mają zastosowanie również tutaj. Poniżej przykład wyszukiwania i wyświetlania tylko elementów będących punktami listy:
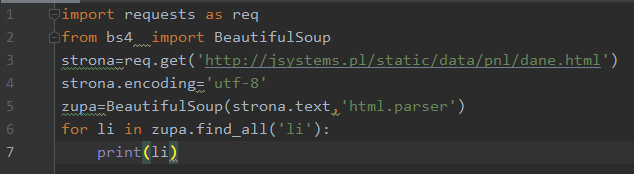
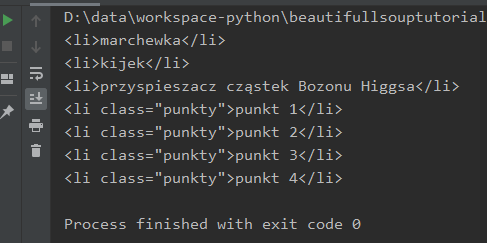
W sumie w dokumencie mamy dwie listy, ale w powyższym przykładzie nie ma to znaczenia. Wyciągneliśmy wszystkie elementy li występujące w dokumencie:
Jeśli chcielibyśmy wyciągnąć tylko punkty zawarte na liście znajdującej się w div o id „sekcja4” to zgodnie z zasadami zagnieżdżania omówionymi wcześniej robimy to w ten sposób:
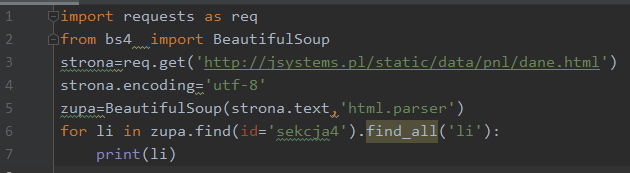
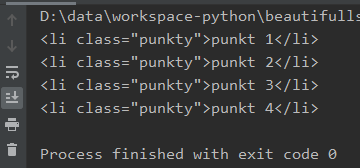
Wynik:
Alternatywnie można ten sam efekt osiągnąć wyszukując elementy wg klasy css. Dla poniższego kodu wynik jest identyczny z powyższym.
Pole contents pozwala nam zaglądać do elementów zawartych w konterze. W naszym kodzie html mamy tabelkę:
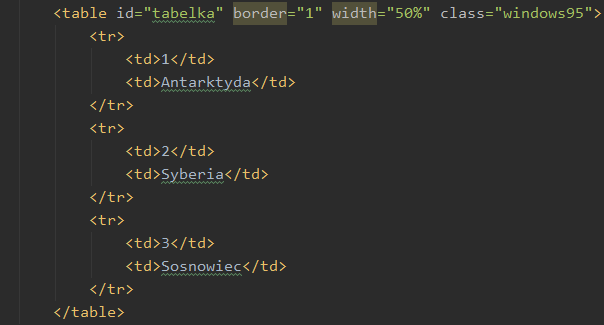
Chcemy docelowo dobrać się do tekstu „Antarktyda”. Jest to druga kolumna drugiej linii tabeli. Zobaczmy więc co znajduje się w polu contents tabeli, ile jest tam elementów i jakiego typu dane znajdziemy w contents:
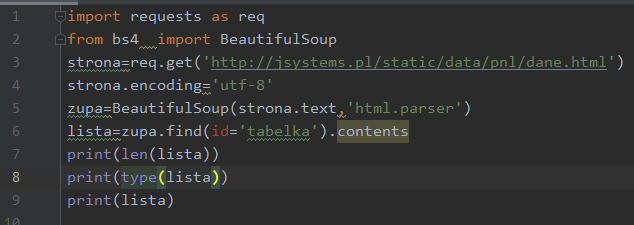
Powyższy kod zwraca nam informację o 7 elementach. Jest to kolekcja typu lista, a zawartość tej listy to kolejne wiersze tabeli, oraz znaki „enter”:
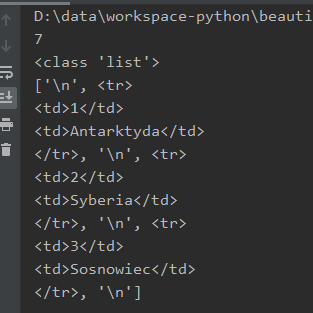
Szukamy gdzie ta nasza Antarktyda. Znajduje się ona w elemencie o indeksie 1. Wydrukujmy więc ten element:
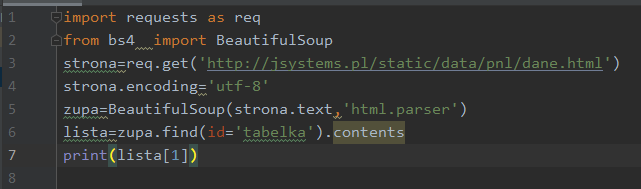
Dobraliśmy się do wiersza:
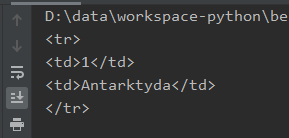
Taki wiersz również ma składowe – kolumny. Zobaczmy jak BS4 to rozbije:
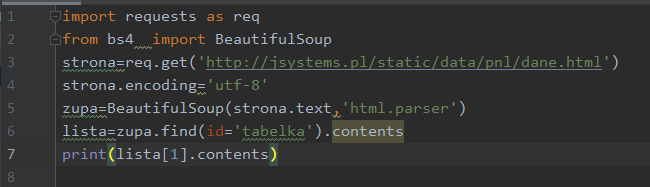
Wynik działania:

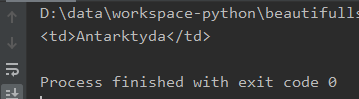
Nasz wiersz składa się zatem z kolumn oraz znaków „enter” będących pozostałością po formatowaniu dokumentu. Fraza „Antarktyda” znajduje się w elemencie o indeksie 3. Zajrzyjmy więc do niego:
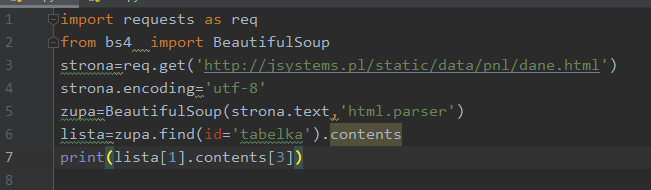
Wynik:
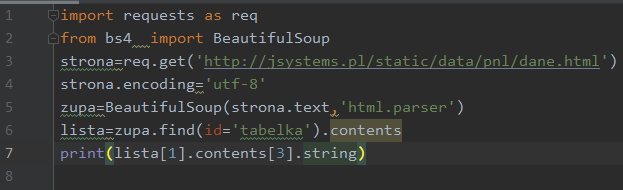
Teraz możemy odnieść się do „string” aby dobrać się do poszukiwanej frazy:
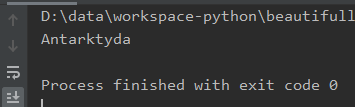
Wynik:
Zamiast rozbijać wyszukiwanie na atomy, możemy skorzystać z zagnieżdżania:
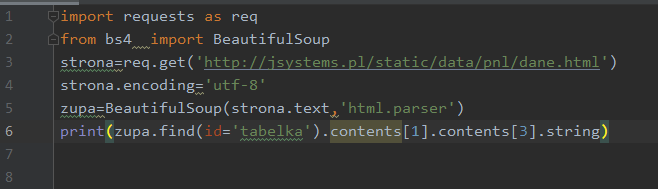
Dającego nam dokładnie ten sam wynik. Tłumacząc wynik wyszukiwania z linii 6 kodu: Znajdź element o id równym „tabelka”, sięgnij do drugiego (o indeksie 1) z zawartych w nim elementów, z tego elementu wyciągnij czwarty (o indeksie 3) jego podelement, a z niego wysupłaj zawartość.

Komentarze (0)
Brak komentarzy...