Czy do stosowania testów automatycznych w ogóle muszę kogokolwiek przekonywać? Wyobrażasz sobie że przy każdej zmianie kodu testujesz ręcznie wszystkie funkcjonalności systemu, bo jakaś zmiana mogła zepsuć działanie którejś z funkcji? Albo może testować metodą "powinno działać" ;) lub japońską metodą "jako-tako" i zakładać że przecież klient przetestuje na produkcji ( pozdrawiam Microsoft ;) ) ? Automatyczne testy sprawdzą poprawność działania Twojego kodu, za każdym razem gdy zechcesz w sposób automatyczny, w ułamkowej częsci czasu jaki musiałbyś poświęcić na testy ręczne. Czy zatem warto pisać testy? Myślę że po postawieniu tak retorycznego pytania możemy po prostu przejść do opisu tego jak to się robi.
Zaczniemy od stworzenia prostego testu jednostkowego dla banalnej funkcji sumującej dwie liczby. Stworzyłem nowy projekt, a w nim plik o nazwie narzedzia.py, którego zawartość wygląda następująco:
def sumuj(a,b):
return a+b
Chciałbym teraz przetestować poprawność działania tej funkcji. Dodaję więc plik o nazwie test_narzedzia.py a w nim umieszczam poniższy kod:
import narzedzia as n
def test_sumuj():
assert n.sumuj(5,3)==8
Nazwa pliku "test_narzedzia.py" nie jest przypadkowa. Które moduły i funkcje służą do testowania a które są testowane i jak je odróżnić? Pytest po uruchomieniu szuka automatycznie plików których nazwa zaczyna się od prefiksu "test_", a w nich poszukuje funkcji których nazwa również zaczyna się od "test_". Te właśnie funkcje uzna za testy do uruchomienia. Ot cała tajemnica.
Skoro już wiemy jak to działa, to przeanalizujmy zawartość pliku z testami (drugi przykład z kodem wyżej). W pierwszej kolejności trzeba oczywiście zaimportować moduł który będzie podlegał testom. Poniżej deklaruję funkcję o nazwie "test_sumuj" której zadaniem będzie przetestowanie funkcji "sumuj" z modułu "narzedzia". Ponieważ działanie funkcji "sumuj" sprowadza się do zwrócenia sumy dwóch liczb podanych przez argumenty - to poprawność takiego właśnie sposobu działania testujemy. Pojawia się tu słowo kluczowe "assert". Oznacza ono mniej więcej "upewnij się że". Linię:
assert n.sumuj(5,3)==8
moglibyśmy wytłumaczyć jako "upewnij się że wynik działania funkcji sumuj po podaniu jej 5 i 3 wynosi 8". Generalnie musi to być wyrażenie logiczne co do którego jesteśmy w stanie orzec czy jest prawdziwe czy nie. Równie dobrze mogłoby wyglądać tak:
assert 1==1
Czas uruchomić testy. Służy do tego konsolowe narzędzie "pytest". Wykona za nas całą pracę, musimy tylko je wywołać w odpowiedni sposób w odpowiednim miejscu. Przechodzimy do katalogu projektu z poziomu konsoli Windows, lub wybieramy "Terminal" w dolnej, lewej części interfejsu PyCharm. Wpisujemy "pytest" i naciskamy enter:
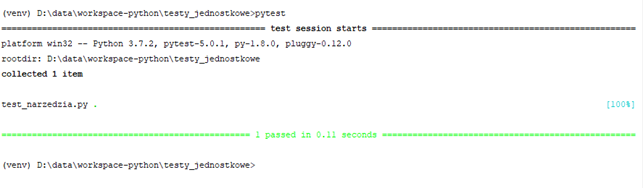
Jak widać na powyższej ilustracji, pytest sam odnalazł testy. Wykrył plik "test_narzedzia.py" który z racji posiadania w nazwie prefiksu "test_" został uznany za moduł z testami. Przeszukał plik w poszukiwaniu funkcji których nazwy również zawierają taki prefiks i je wykonał. Jako wynik widzimy potwierdzenie że 100% testów z pliku "test_narzedzia.py" zakończyło się z wynikiem pozytywnym.
Nie wiemy jednak jakie funkcje zostały wywołane. Aby się tego dowiedzieć, możemy użyć przełącznika "-v":
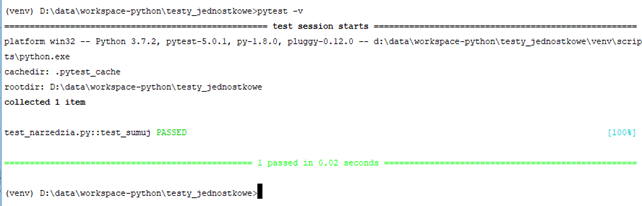
Tym razem widać, że wywołana została funkcja "test_sumuj". Teraz zmodyfikuję nieco funkcję testującą by umyślnie spowodować błąd:
def test_sumuj():
assert n.sumuj(5,3)==18
Wynik działania:
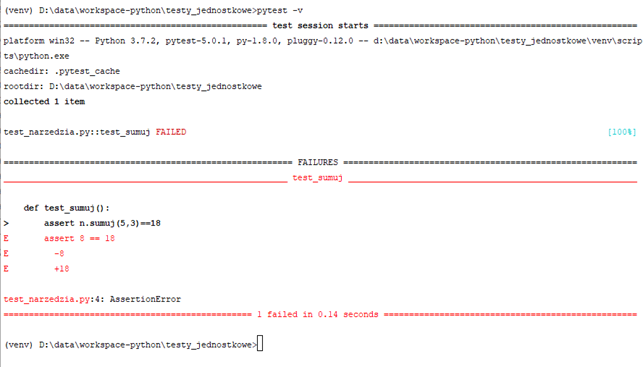
Tym razem oblaliśmy test. Pytest pokazał nam nawet w którym miejscu testy nie przeszły i przy jakiej wartości test przechodził a jaka jest teraz. Mam tu na myśli te linijki z wartościami "-8, +18". Przy wartości 8 test był ok, przy wartości 18 nie przechodzi. Tą informację odnośnie konkretnych wartości wcześniej i teraz dostaniemy tylko korzystając z przełącznika -v. Bez niego zobaczymy tylko jaka metoda i na której linijce nie przeszła:
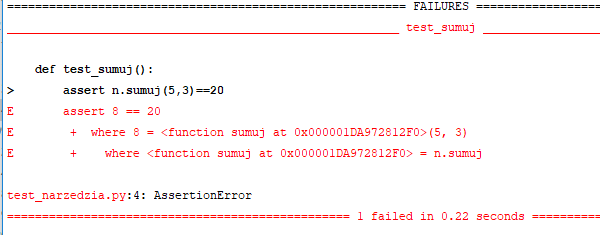
W tym przypadku mamy tylko jedną funkcję testującą, jednak warto wiedzieć że w przypadku oblania jednego z testów, pozostałe testy nadal są wykonywane.
Wracając jeszcze na moment do przełącznika "-v" i wartości jaka obowiązywała gdy test przechodził: skąd pytest to wie? Gdzieś musi gromadzić tego rodzaju informacje. Otóż w katalogu projektu tworzy sobie podkatalog ".pytest_cache" który zawiera te i inne informacje związane z pracą pytest.
Nie zawsze musimy chcieć uruchamiać wszystkie testy, biorąc pod uwagę zwłaszcza duże systemy gdzie ilość testów może sprawić, że sam proces testowania będzie trwał kilka minut. Dobrze jest więc wiedzieć jak uruchamiać tylko wybrane testy, a możliwości mamy tutaj kilka. Zanim omówimy konkretne przykłady, spójrzmy w jaki sposób zmodyfikowałem projekt. Do pliku "narzedzia.py" dodałem drugą funkcję, tak że w tej chwili zawartość tego pliku wygląda tak:
def sumuj(a,b):
return a+b
def dajCyfry():
return list(range(1,11))
Nowa funkcja "dajCyfry" zwraca liczby w zakresie 1-10 w postaci listy. Rozbudowie uległ też moduł testujący:
import narzedzia as n
def test_sumuj():
assert n.sumuj(5,3)==8
def test_dajCyfryMin():
tab=n.dajCyfry()
assert min(tab)==1
def test_dajCyfryMax():
tab=n.dajCyfry()
assert max(tab)==10
def test_dajCyfryLen():
tab=n.dajCyfry()
assert len(tab)==10
Pojawiły się trzy dodatkowe funkcje testujące funkcję "dajCyfry" z modułu "narzedzia". Pierwszy sprawdza czy najmniejsza wartość w zwracanej liście to 1, drugi czy największa to 10, trzeci czy lista zawiera 10 elementów. Do tego wszystkiego dodałem jeszcze w projekcie podkatalog o nazwie "tests", a w nim umieściłem jeden plik "test_rzeczywistosci.py" który zawiera jedną funkcję:
def test_czySwiatStanalNaGlowie():
assert 2!=1
Przejdźmy teraz do wybiórczego uruchamiania testów. Jeśli uruchomię komendę "pytest" w katalogu projektu, odnalezione zostaną wszystkie pliki zaczynające się od prefiksu "test_" i wykonane z nich wszystkie funkcje zaczynające się od tego samego prefiksu. Przeszukiwanie dotyczy nie tylko katalogu w którym się znajdujemy, ale również wszystkich jego podkatalogów.
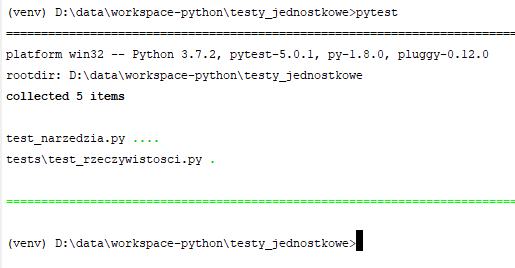
Jak widać powyżej pytest znalazł też dodatkowy zestaw testów w podkatalogu. Gdybym zechciał by zostały wykonane tylko testy z jednego pliku, podaję ścieżkę do niego jako argument pytest:
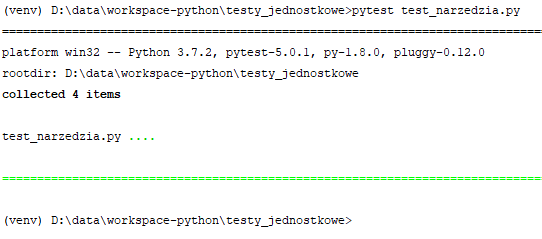
Raczej można się było tego domyślić ;) Możesz też nakazać wykonanie testów ze wskazanego katalogu wywołując pytest ze ścieżką tego katalogu jako argumentem:
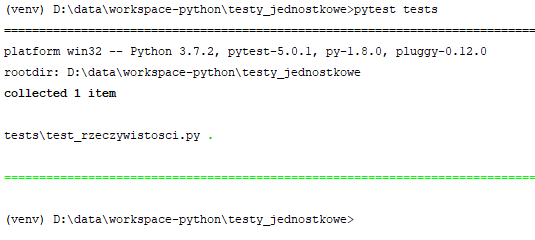
Rzecz znacznie mniej oczywista to możliwość uruchamiania testów które zawierają określony ciąg w nazwie:
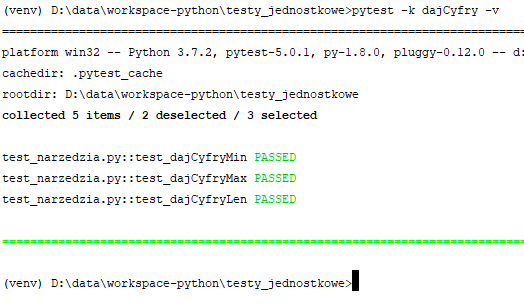
Służy do tego przełącznik "-k" po którym podajemy fragment nazwy. Jak widać, uruchomione zostały trzy funkcje testujące - wszystkie miały w nazwie "dajCyfry" który to ciąg zdeklarowałem jako filtr. Użyłem tu dodatkowo przełącznika -v, tylko po to by wyświetlił mi funkcje które uruchomił (normalnie tego nie robi). Nie zawsze chcemy lub możemy sobie pozwolić na zmianę nazwy funkcji testującej, np. po to by jak w powyższym przypadku wybierać część z nich. Na szczęście pytest dostarcza też dekoratory które umożliwiają oznaczanie i grupowanie funkcji:
import pytest
import narzedzia as n
@pytest.mark.podstawowe
def test_sumuj():
assert n.sumuj(5,3)==8
@pytest.mark.szczegolowe
def test_dajCyfryMin():
tab=n.dajCyfry()
assert min(tab)==1
@pytest.mark.szczegolowe
def test_dajCyfryMax():
tab=n.dajCyfry()
assert max(tab)==10
@pytest.mark.podstawowe
def test_dajCyfryLen():
tab=n.dajCyfry()
assert len(tab)==10
Oznaczenie "@pytest.mark.XXX" pozwala na wyznaczenie grup funkcji. Ja swoje podzieliłem na dwie grupy - testy podstawowe i testy szczegółowe. Zwróć uwagę na dodanie importu "import pytest" do pliku - bez tego powyższe dekoratory nie będą działać. Aby wywołać tylko testy oznaczone jakimś "tagiem" używam przełącznika "-m" pytesta. "-v" jak i wcześniej jest tu tylko po to by pokazywał jakie funkcje uruchamia:
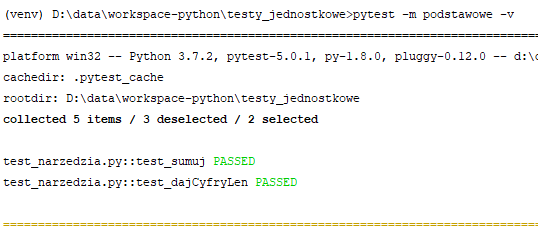
Przyjmijmy że mamy do czynienia z taką sytuacją: tworzymy system który łączy się różnymi bazami danych i wykonuje na nich różne zapytania. Jak więc będą wyglądały testy? Trzeba będzie podłączyć się do każdej z baz i wykonać próbne zapytanie, sprawdzając czy ta czynność nie spowoduje jakiegoś wyjątku. Przygotujmy więc background z testami, korzystając tylko z tego co wiemy dotychczas. Treść pliku "modulik.py":
podpietaBaza=None
def podepnijBaze(nazwa):
global podpietaBaza
podpietaBaza=nazwa
def wykonajZapytanie():
global podpietaBaza
print('Wykonuję zapytanie z użyciem bazy {}'.format(podpietaBaza))
if(podpietaBaza=='MS SQL'):
raise Exception('FUUUUUUU')
return "ok"
Metoda "wykonajZapytanie" będzie powodowała wyjątek gdy zostanie podłączony SQL Server. Zawartość modułu testów "test_modulik.py":
import modulik
def test_podepnijBaze():
bazy=['Oracle','PostgreSQL','MS SQL','MySQL']
for b in bazy:
modulik.podepnijBaze(b)
assert modulik.wykonajZapytanie()=='ok'
pass
Funkcja testująca "test_podepnijBaze" podpina po kolei kolejne bazy z listy i usiłuje wykonać na nich zapytanie. Jak pewnie pamiętasz z poprzedniego listingu - funkcja "wykonajZapytanie" spowoduje wyjątek gdy trafi na "MS SQL". W pozostałych przypadkach zwróci ciąg tekstowy "ok". Tak więc dla pierwszych 2 baz test powinien przejść, a następnie wyłożyć się na trzecim. Sprawdźmy zatem co się stanie. Po uruchomieniu testu:
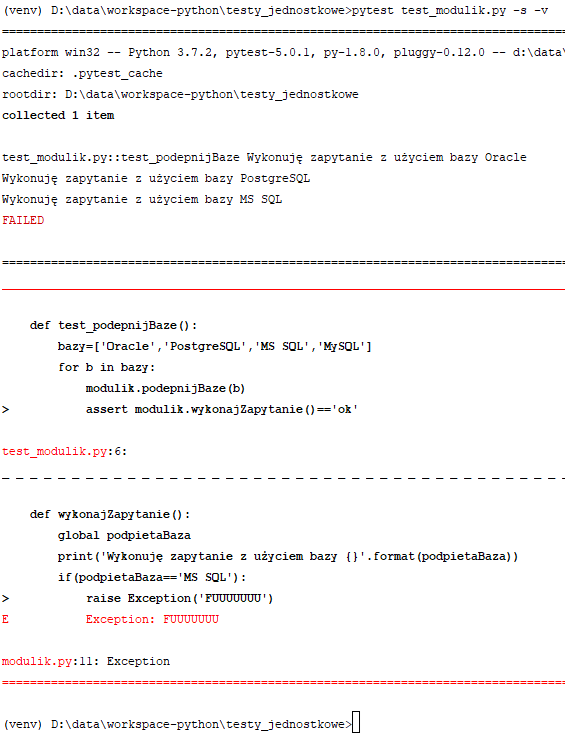
Test zgodnie z oczekiwaniami nie przeszedł, mamy też informację w którym miejscu pojawił się wyjątek. Same testy jednak nie mówią nam dla jakiej wartości nastąpił ten wyjątek. Dodałem sobie drukowanie informacji o podpiętej bazie, i tylko po tym mogę ewentualnie poznać na której bazie się wyłożył test. Ponadto, jeśli na jednej bazie testy polegną, to nie przejdą do sprawdzania kolejnych, tylko zostaną przerwane. Aby rozwiązać oba te problemy, wykorzystamy dekorator "@pytest.mark.parametrize". Mała przeróbka modułu testowego:
import modulik
import pytest
dbs = ["Oracle", 'PostgreSQL', 'MS SQL', 'MySQL']
@pytest.mark.parametrize('baza',dbs)
def test_podepnijBaze(baza):
modulik.podepnijBaze(baza)
print('{}\n'.format(baza))
assert modulik.wykonajZapytanie()=='ok'
Powyższa funkcja będzie testowana tylukrotnie, ile wartości znajdzie się na liście "dbs". Dla każdej wartości pytest wygeneruje osobny test. Tym razem funkcja przyjmuje bazę danych przez parametr (w miejsce iteracji po liście baz wewnątrz funkcji). Wartość dla tego parametru zostaje podana dzięki dekoratorowi "@pytest.mark.parametrize". Pierwszym parametrem tego dekoratora jest nazwa parametru do którego wstrzykujemy wartość, drugim lista (lub inna kolekcja po której da się iterować) z której będą pobierane wartości do testów. Pytest dla każdej wartości w kolekcji "dbs" wywoła funkcję test_podepnijBaze raz, podając przez argument funkcji tę wartość. Sprawdźmy teraz wyniki działania:
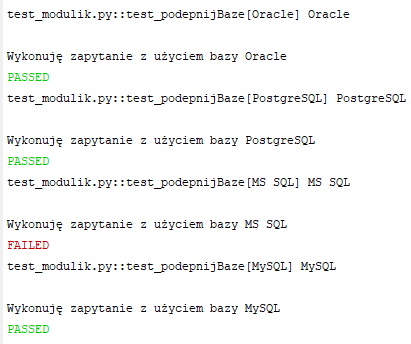
Obserwujemy spodziewany wynik działania. Dla każdej bazy został wykonany jeden test. Mimo porażki testu na "MS SQL" kolejne testy nadal były wykonywane.
Tworzę moduł który będzie robił za coś w stylu lokalnej pamięciowej bazy danych. Jak widać w poniższym fragmencie kodu, mamy w ramach tego modułu listę która jest ładowana przez funkcję "loadDB", a z której dane są pobierane przez funkcje "getData" i "getOne".
baza=[]
def loadDB():
print("############## ŁADOWANIE BAZY ##############")
global baza
baza=[
(1,"Marian"),
(2,"Czesław"),
(3,"Zenon"),
(4,"Florian")
]
def getData():
global baza
return baza
def getOne(x):
global baza
return baza[x]
Aby dwie ostatnie funkcje mogły cokolwiek zwracać, trzeba najpierw wywołać funkcję "loadDB". Przyjrzyjmy się teraz testom przygotowanym do tego modułu:
import nibyDB
def test_getData():
nibyDB.loadDB()
assert len( nibyDB.getData() )>0
pass
def test_getOne():
nibyDB.loadDB()
assert nibyDB.getOne(0)[1]=='Marian'
pass
Testy będą działały tak długo, jak długo w powyższych funkcjach przed sięgnięciem do danych będę wywoływał funkcję loadDB. To jest pierwszy problem. Jeśli przy którymś testów o tym zapomnę to test się nie powiedzie, ale nie z powodu wadliwości testowanej funkcji. Drugi problem jest taki, że ładowanie następuje przy każdym teście. Wyobraź sobie teraz że funkcja ładująca pobiera duże ilości danych z jakiejś zdalnej bazy albo ogromnego pliku. Uruchamiam test by sprawdzić jak to wygląda z tym ładowaniem bazy. W normalnym trybie pytest przechwytuje wszystkie komunikaty lecące na konsolę, więc jeśli chcesz by były one pokazywane, użyj przełącznika "-s":
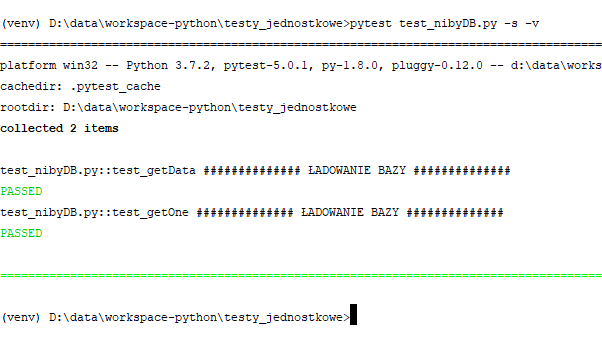
Ładowanie bazy zostało wykonane dwukrotnie, ponieważ wywoływał je każdy z testów. Teraz poza wielkim plikiem dodajmy sobie jeszcze setki takich testów... Dużo rozsądniejszym wyjściem będzie załadowanie danych przed wszystkimi testami jednokrotnie, zamiast każdorazowo przed każdym testem.
Tym razem nieco zmodyfikuję zawartość modułu z testami:
import nibyDB
def setup_module():
print("\n############## setup ##############")
nibyDB.loadDB()
def teardown_module():
print("\n############## bye ##############")
def test_getData():
assert len( nibyDB.getData() )>0
pass
def test_getOne():
assert nibyDB.getOne(0)[1]=='Marian'
pass
Pojawiły się dwie nowe funkcje - "setup_module" i "teardown_module". Nazwy nie są przypadkowe - pytest wywoła te funkcje automatycznie odpowiednio przed wszystkimi testami w danym module, oraz po nich. Możemy to wykorzystać do wstępnej inicjalizacji na początku i np. wyczyszczenia danych na końcu. Kod modułu testującego przerobiłem w taki sposób, że wywołanie funkcji "loadDB" pojawia się tylko raz - w funkcji setup_module() zamiast w każdej funkcji testującej. Skutek działania:
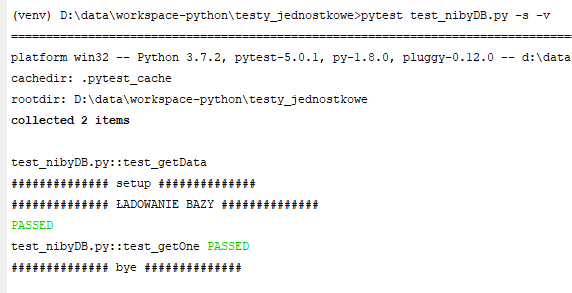
Jak widzimy na powyższej ilustracji, komunikat ładowania bazy pojawia się tylko raz.
Pytest dostarcza ponadto dekoratory które pozwalają uzyskać zbliżony efekt w inny sposób.
import nibyDB
import pytest
@pytest.fixture
def load_stuff():
print("\n############## load ##############")
nibyDB.loadDB()
def test_getData(load_stuff):
assert len( nibyDB.getData() )>0
pass
def test_getOne(load_stuff):
assert nibyDB.getOne(0)[1]=='Marian'
pass
Przyjrzyj się powyższemu przykładowi. W miejsce funkcji "setup_module" pojawia się funkcja "load_stuff" - tym razem jest to nazwa wymyślona przeze mnie. Nad tą funkcją mamy dekorator "@pytest.fixture". Ten dekorator powoduje automatyczne wywołanie funkcji "load_stuff" przed uruchomieniem każdej z funkcji testujących która ma podane w argumencie nazwę funkcji "load_stuff":
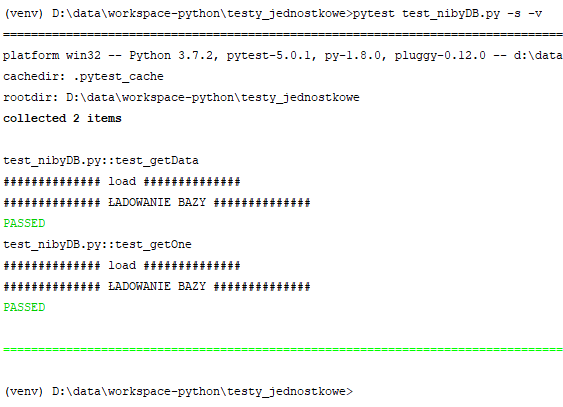
W powyższym przykładzie wróciliśmy do wielokrotnego ładowania bazy. Wystarczy do naszego dekoratora dodać atrybut "scope=module" by działało to tak jak setup_module:
@pytest.fixture(scope='module')
def load_stuff():
print("\n############## load ##############")
nibyDB.loadDB()
Poza tym nic nie zmieniałem w pozostałym kodzie. Tym razem ładowanie nastąpiło raz, w związku z uruchomieniem tego modułu testującego. Tak więc jeśli chcesz by jakaś funkcja przygotowująca dane (lub jakakolwiek inna, to przecież bez znaczenia) była wykonywana każdorazowo przed każdą funkcją testującą to dodajesz do niej "@pytest.fixture", a do funkcji testującej dodajesz do argumentów nazwę funkcji przygotowującej (bez podania argumentów czy nawiasów). Jeśli zaś chcesz uruchomić funkcję przygotowującą na przed wszystkimi testami jednorazowo, do dekoratora dodajesz ponadto "(scope="module")
Jeśli drażni Cię (podobnie jak i mnie) konieczność podawania nazwy funkcji przygotowującej jako argument funkcji testującej, możesz wykorzystać przełącznik "autouse":
import nibyDB
import pytest
@pytest.fixture(autouse=True)
def load_stuff():
print("\n############## load ##############")
nibyDB.loadDB()
def test_getData():
assert len( nibyDB.getData() )>0
pass
def test_getOne():
assert nibyDB.getOne(0)[1]=='Marian'
pass
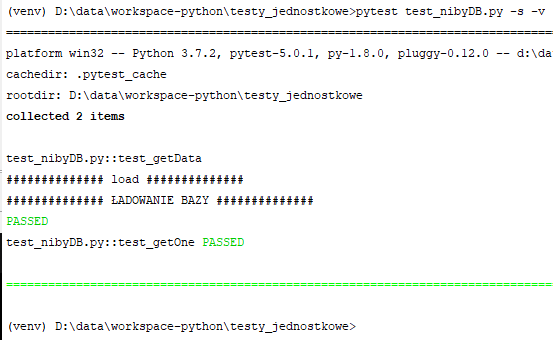
Autouse powoduje po prostu że funkcja której dekorator dotyczy zostanie wywołana przed każdą funkcją testującą (co stałoby się również po prostu po dodaniu tego dekoratora bez żadnych przełączników), z tą różnicą że teraz nie będzie trzeba podawać nazwy funkcji przygotowującej jako argument funkcji testującej. Możesz również użyć obu przełączników : autouse=True i scope='module' w jednym dekoratorze. Skutek jest łatwy do przewidzenia. Nie trzeba będzie modyfikować argumentów funkcji testujących, a funkcja przygotowująca zostanie wywołana raz przed wszystkimi testami. I to jest chyba najbardziej sensowny wariant w tego typu sytuacjach. Kod całego modułu testującego będzie wyglądał ostatecznie w ten sposób:
import nibyDB
import pytest
@pytest.fixture(autouse=True,scope="module")
def load_stuff():
print("\n############## load ##############")
nibyDB.loadDB()
def test_getData():
assert len( nibyDB.getData() )>0
pass
def test_getOne():
assert nibyDB.getOne(0)[1]=='Marian'
pass
I skutek jego działania:
Po przebrnięciu przez te wszystkie przykłady czas odpowiedzieć sobie na podstawowe pytanie: Czym więc jest fikstura? Fikstura to funkcja która przygotowuje dane, lub wykonuje czynności inicjalizacyjne na potrzeby testów.
Makiety służą zastępowaniu prawdziwych danych na czas testów. Przyjrzyjmy się przykładowi takiej makiety. Stosowanie makiet samo w sobie nie jest w żaden sposób powiązane z pytest.
from unittest import mock
makieta=mock.Mock()
makieta.pole1=20
makieta.pole2='Element tekstowy'
print('pole1={}, pole2={}'.format(makieta.pole1,makieta.pole2))
W powyższym przykładzie widzimy że tworzę obiekt klasy Mock, do dwóch jego pól przypisuję a następnie wyświetlam wartości. "Też mi cuda", mógłby powiedzieć ktoś kto ma pojęcie choćby o podstawach obiektowości w Pythonie. Przecież mogę w ten sposób tworzyć pola w dowolnym obiekcie, nie potrzebuję do tego klasy Mock! I to jest jak najbardziej prawda. Popatrzmy co dalej możemy tutaj zrobić. Dynamicznie mogę tworzyć również metody. Całość:
from unittest import mock
makieta=mock.Mock()
makieta.pole1=20
makieta.pole2='Element tekstowy'
print('pole1={}, pole2={}'.format(makieta.pole1,makieta.pole2))
makieta.dawajPi.return_value=3.14
print( makieta.dawajPi)
Wynik na konsoli:
pole1=20, pole2=Element tekstowy
<Mock name='mock.dawajPi' id='2765903240720'>
Process finished with exit code 0
Wyświetlenie zawartości dynamicznie tworzonych pól nikogo nie zaskakuje, to już ustaliliśmy. W ostatnich dwóch linijkach odwołuję się jednak do czegoś co się nazywa "dawajPi". Jest to funkcja którą dynamicznie tworzę dla obiektu makiety. Z pomocą linii:
makieta.dawajPi.return_value=3.14
Tworzę i deklaruję zwracaną wartość tejże funkcji. Takie obiekty możesz teraz użyć do testów, w miejsce danych pobieranych np. z bazy w której w ramach testów nie chcielibyśmy mieszać.
Testy fajnie się pisze jeśli musisz przetestować funkcję dla kilku wartości. Kilku Janów Kowalskich czy Nowaków zawsze się wymyśli. Co jednak gdy chodzi o różne ciągi tekstowe (tu pewnie zwykle następuje "dfgfdgdsgdgsdfg" :D ) czy daty, albo choćby i te wspomniane nazwiska - jednak ilościowo idące w tysiące? Warto wiedzieć że dla Pythona dostępna jest ciekawa biblioteka "Faker". Pozwala ona generować takie właśnie losowe dane. Poniżej przykład:
from unittest import mock
import faker
m=mock.Mock()
f=faker.Faker()
m.losowaOsoba=f.name()
m.losowaSentencja=f.sentence()
m.losowaData=f.date()
print(m.losowaOsoba)
print(m.losowaSentencja)
print(m.losowaData)
Możesz powyższy tekst skopiować i uruchomić u siebie. Dane są losowe, za każdym razem będzie to coś innego. U mnie np. wyswietliło:
Brooke Glover
Light during throughout receive.
1981-08-08
Warto jest sprawdzać stopień pokrycia kodu testami. Możemy dzięki temu sprawdzić które funkcje czy moduły nie zostały jeszcze przetestowane i wymagają dorobienia testów. Z jego użyciem możemy też wykryć nieużywane fragmenty kodu który jako martwy możemy usunąć. Aby rozpocząć pracę musimy zainstalować wtyczkę "pytest-cov" do pytest'a. Robimy to z poziomu pip'a:
pip install pytest-cov
Od tego momentu do pytest możemy dodawać przełącznik "--cov", dzięki któremu możemy przetestować wskazany moduł lub cały projekt pod kątem pokrycia testami. Poerwszy wariant - dla całego projektu, drugi dla wybranego modułu:
pytest --cov
pytest test_modulik.py --cov
Wynik działania:
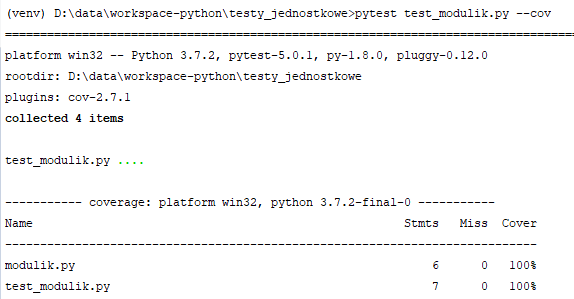
Istnieje również możliwość generowania raportów pokrycia testami w formacie html. Trzeba tylko użyć dodatkowego przełącznika --cov-report:
pytest test_modulik.py --cov --cov-report=html
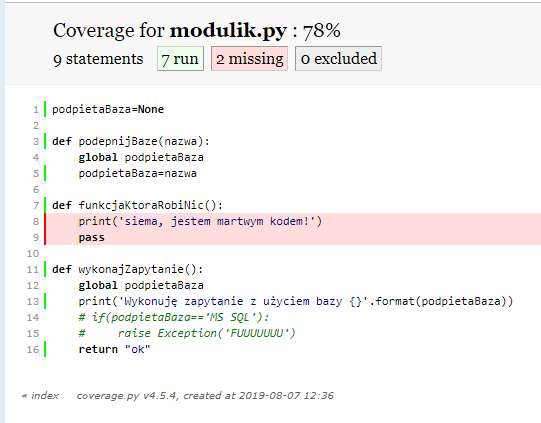
Po uruchomieniu testów w ten sposób, w katalogu projektu (lub miejscu w którym uruchamiałeś testy) powstaje katalog "htmlcov" pełen raportów w formacie html. Do modułu "modulik.py" dodałem umyślnie jedną nic nie robiącą funkcję. Generuję raporty w formacie html. Uruchamiam znajdujący się w katalogu "htmlcov" plik "index.html":

Widzę że "modulik" nie jest w 100% pokryty testami. Klikam więc na jego nazwę (która jest linkiem), by zobaczyć co nie jest pokryte testami i oto otrzymuję wynik: