Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
O DevOpsie krąży sporo mitów. Jeden mówi, że to złota żyła, do której wystarczy obejrzeć kurs Dockera. Drugi - że to nieosiągalna magia dla wybrańców z dziesięcioletnim stażem. Prawda leży pośrodku i jest dużo ciekawsza: DevOps to konkretny zestaw umiejętności, których da się nauczyć w przewidywalnej kolejności, a rynek naprawdę za nie płaci. Ten przewodnik nie sprzedaje skrótów - pokazuje realną drogę: co opanować, w jakiej kolejności, jak to przećwiczyć na własnym sprzęcie i czego nie robić, żeby nie zmarnować pół roku.
Definicje w stylu „DevOps stoi na styku developmentu i operacji" niewiele mówią. Lepiej zobaczyć to w akcji. Wyobraź sobie poniedziałkowy poranek: alert z monitoringu informuje, że jeden z serwisów na produkcji zaczął zwracać błędy 5xx. DevOps nie panikuje - ma narzędzia i procedurę. Pierwsze pięć minut wygląda mniej więcej tak:
# Co się dzieje na klastrze? Które pody padają?
devops@k8s:~$ kubectl get pods -n shop --field-selector=status.phase!=Running
NAME READY STATUS RESTARTS AGE
checkout-7d9c8f4b6-2xk4p 0/1 CrashLoopBackOff 6 4m
# Dlaczego restartuje? Czytamy logi z poprzedniej instancji poda
devops@k8s:~$ kubectl logs checkout-7d9c8f4b6-2xk4p -n shop --previous --tail=5
FATAL: could not connect to database "shop": too many connections
# Diagnoza: wyczerpana pula połączeń do bazy. Szybkie złagodzenie - skalujemy w dół
devops@k8s:~$ kubectl scale deploy/checkout -n shop --replicas=2
deployment.apps/checkout scaledTo jest sedno roli: szybka diagnoza pod presją, znajomość narzędzi i systemu, a potem - co ważniejsze - trwałe rozwiązanie (np. pooler połączeń, zmiana limitów w konfiguracji jako kod), żeby ten sam incydent nie wrócił za tydzień. Praca DevOps to w 20% gaszenie pożarów, a w 80% budowanie tego, dzięki czemu pożary w ogóle nie wybuchają: automatyzacji, monitoringu i powtarzalnej infrastruktury.
W praktyce zakres obowiązków obejmuje:
Najczęstszy powód, dla którego ludzie odbijają się od DevOps, to zła kolejność nauki. Kubernetes wygląda atrakcyjnie, więc kuszące jest zacząć od niego - ale bez Linuksa, sieci i kontenerów K8s jest ścianą skrótów, których nie rozumiesz. Poniższa roadmapa układa wiedzę warstwami: każda kolejna faza opiera się na poprzedniej.
To etap, który najłatwiej zlekceważyć i najbardziej tego potem żałować. Linux jest językiem ojczystym DevOps - serwery, kontenery i klastry to w przeważającej części Linux. Musisz swobodnie poruszać się po systemie plików, rozumieć uprawnienia, procesy, sieć i pisać skrypty w bashu. Nie chodzi o wykucie komend, tylko o to, żeby diagnozować problemy:
# Który proces zajmuje port 8080? (typowe pytanie przy debugowaniu)
user@vps:~$ sudo ss -ltnp | grep :8080
LISTEN 0 511 0.0.0.0:8080 users:(("node",pid=2417,fd=18))
# Ile zostało miejsca i co je zjada?
user@vps:~$ df -h / && du -sh /var/log/* | sort -rh | head -3
/dev/sda1 40G 31G 9.0G 78% /
2.3G /var/log/journalObok Linuksa trzy filary: Git (gałęzie, rebase kontra merge, rozwiązywanie konfliktów - bo cała infrastruktura będzie wersjonowana), sieci (TCP/IP, DNS, HTTP/S, równoważenie obciążenia, firewalle - bez tego incydenty sieciowe będą dla Ciebie czarną skrzynką) oraz jeden język automatyzacji. Wybierz Python (popularniejszy w DevOps, świetny do skryptów i API chmury) albo Go (język, w którym napisano Dockera, Kubernetes i Terraform).
grep, awk, potoki i przekierowania nie są dla Ciebie naturalne, faza 2 będzie walką.Tu zaczyna się „prawdziwy" DevOps. Najpierw Docker: czym jest obraz, czym kontener, jak napisać sensowny Dockerfile i jak złożyć kilka usług przez docker compose. Dobry obraz jest mały, warstwowy i nie zawiera sekretów. Przykład wielostopniowego budowania, które zmniejsza obraz aplikacji w Go z setek megabajtów do kilkunastu:
# Etap budowania - pełne środowisko Go
FROM golang:1.23 AS build
WORKDIR /src
COPY . .
RUN CGO_ENABLED=0 go build -o /app ./cmd/api
# Etap finalny - mikroskopijny obraz tylko z binarką
FROM gcr.io/distroless/static
COPY --from=build /app /app
EXPOSE 8080
ENTRYPOINT ["/app"]Następnie Kubernetes - serce nowoczesnego DevOps. Bez niego praktycznie nie ma ofert na poziomie mid i senior. Musisz rozumieć architekturę klastra (węzły, control plane), podstawowe obiekty (Pod, Deployment, Service, Ingress), zarządzanie konfiguracją i sekretami oraz pakowanie aplikacji w Helmie. W Kubernetesie deklarujesz stan docelowy w plikach YAML, a klaster sam do niego dąży:
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3 # utrzymuj 3 instancje
selector:
matchLabels: { app: checkout }
template:
metadata: { labels: { app: checkout } }
spec:
containers:
- name: checkout
image: registry.example.com/checkout:1.4.2
resources:
requests: { cpu: "100m", memory: "128Mi" }
limits: { cpu: "500m", memory: "256Mi" }Postaw klaster lokalnie. kind (Kubernetes-in-Docker) albo minikube uruchomią pełnoprawny klaster na laptopie w minutę. Jeśli masz domowy serwer lub stary komputer, postaw na nim Proxmoxa i kilka maszyn wirtualnych - dostaniesz realne środowisko z siecią, na którym przećwiczysz wszystko od instalacji po awarię węzła. Homelab to najlepsza inwestycja w naukę DevOps.
Skoro umiesz już budować obrazy i wdrażać je na klaster, czas to zautomatyzować. Pipeline CI/CD sprawia, że każdy commit jest budowany, testowany i (jeśli przejdzie) wdrażany bez ręcznego klikania. Minimalny, ale realny pipeline w GitHub Actions:
name: build-and-deploy
on: { push: { branches: [main] } }
jobs:
ship:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Testy
run: go test ./...
- name: Zbuduj i wypchnij obraz
run: |
docker build -t registry.example.com/checkout:${{ github.sha }} .
docker push registry.example.com/checkout:${{ github.sha }}
- name: Wdróż na klaster
run: kubectl set image deploy/checkout checkout=registry.example.com/checkout:${{ github.sha }}Druga noga tej fazy to Infrastructure as Code. Zamiast klikać w konsoli chmury, opisujesz infrastrukturę kodem - dzięki temu jest powtarzalna, wersjonowana i recenzowalna jak każdy inny kod. Terraform tworzy zasoby w chmurze, a Ansible konfiguruje serwery. Fragment Terraform, który tworzy serwer:
resource "aws_instance" "web" {
ami = "ami-0abcd1234"
instance_type = "t3.small"
tags = { Name = "web-prod", Env = "production" }
}A tak wygląda playbook Ansible, który na tym serwerze instaluje i uruchamia nginx:
- name: Konfiguracja serwera web
hosts: web
become: true
tasks:
- name: Zainstaluj nginx
ansible.builtin.package:
name: nginx
state: present
- name: Uruchom i włącz przy starcie
ansible.builtin.service:
name: nginx
state: started
enabled: trueOstatnia warstwa to chmura (AWS lub Azure - wybierz jedną i zrób certyfikat poziomu associate: AWS Solutions Architect Associate albo Azure AZ-104) oraz obserwowalność. Nie da się utrzymywać systemu, którego nie widać. Prometheus zbiera metryki, Grafana je wizualizuje, a Loki lub ELK centralizują logi. Typowe zapytanie w języku PromQL, które pokazuje udział żądań kończących się błędem:
# Udział odpowiedzi 5xx w całym ruchu serwisu checkout (ostatnie 5 min)
sum(rate(http_requests_total{service="checkout",status=~"5.."}[5m]))
/
sum(rate(http_requests_total{service="checkout"}[5m]))Tak wygląda w praktyce Grafana podpięta pod klaster Proxmox - te same panele, które mamy na naszym serwerze szkoleniowym. Każdy węzeł jest monitorowany osobno, widać zarówno chwilowe skoki CPU jak i trend zużycia RAM w czasie:
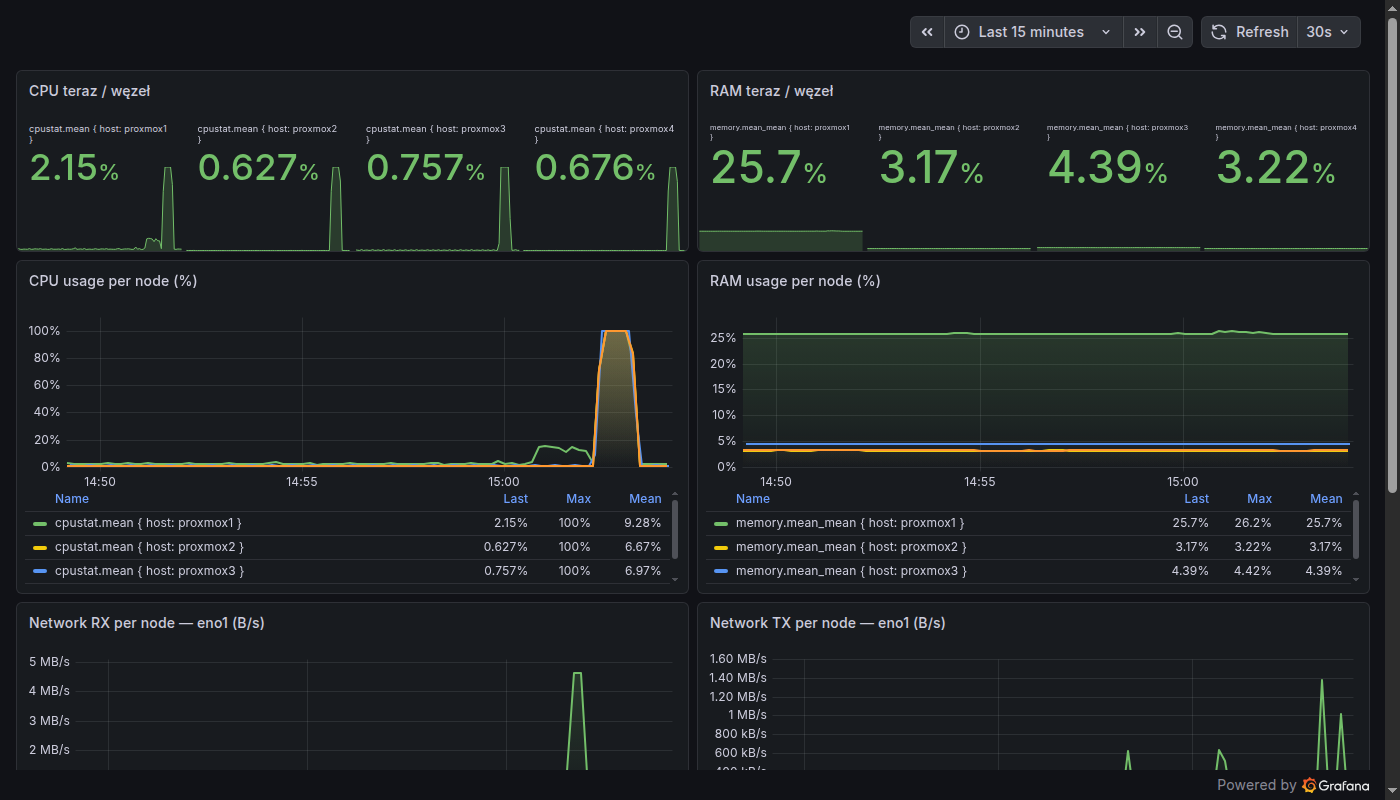
Zarobki w DevOps są wysokie, ale nie biorą się znikąd - rosną dokładnie z tymi umiejętnościami, które trudno zdobyć: Kubernetes, chmura i bezpieczeństwo. Poniższe widełki to mediana rynku z portali pracy (JustJoin.it, NoFluffJobs, Q1 2026), kontrakty B2B netto.
| Poziom | Doświadczenie | Widełki (B2B netto) | Co realnie odróżnia ten poziom |
|---|---|---|---|
| Junior | 0-1 rok | 8 000 - 12 000 zł | Ogarnia Linuksa, Dockera i podstawy CI/CD pod opieką seniora |
| Mid | 2-4 lata | 14 000 - 20 000 zł | Samodzielnie utrzymuje Kubernetes i pipeline'y, zna jedną chmurę |
| Senior | 5+ lat | 22 000 - 35 000 zł | Projektuje architekturę, ogarnia bezpieczeństwo i koszty chmury |
| Lead / Architect | 8+ lat | 30 000 - 50 000+ zł | Strategia platformy, prowadzenie zespołu, decyzje technologiczne |
Co istotne, ofert nie brakuje. Na JustJoin.it - największym polskim portalu z ofertami IT w 2026 roku - w kategorii DevOps stale wisi grubo ponad tysiąc ogłoszeń - to jeden z najgłębszych segmentów rynku, obok danych i Javy. Popyt jest realny, a konkurencja po stronie kandydatów wciąż mniejsza niż przy klasycznym programowaniu.
Rekruter nie pyta „jakie masz certyfikaty", tylko „co zbudowałeś". Te projekty pokrywają całą roadmapę i dają konkretne tematy do rozmowy:
Dockerfile i zmiennymi środowiskowymi.kind albo na homelabie.Wrzuć je na publiczne repozytorium z porządnym plikiem README opisującym architekturę i decyzje. To Twoja najlepsza wizytówka.
Certyfikat nie zastąpi projektów, ale dobrze dobrany potwierdza kompetencje i przechodzi przez filtry rekrutacyjne:
Najkrótsza droga. Rozumiesz kod, Git i logikę aplikacji - dokładasz administrację Linuksa, Kubernetes, CI/CD i chmurę. Realistycznie 6-9 miesięcy intensywnej nauki z projektami.
Masz Linuksa i sieci - dokładasz konteneryzację, Infrastructure as Code, programowanie (Python) i chmurę. 6-12 miesięcy. Twoja przewaga to rozumienie, jak systemy zachowują się pod obciążeniem.
Możliwe, ale wymaga cierpliwości - minimum 12-18 miesięcy systematycznej nauki. Klucz to kolejność: zacznij od Linuksa i sieci, nie od Kubernetesa. Pierwsza praca może być jako młodszy administrator albo wsparcie techniczne, z którego naturalnie wejdziesz w DevOps.
Coraz częściej tak, choć nie w roli „magicznego guzika". AI realnie skraca rutynę DevOps: generuje i recenzuje konfiguracje (Terraform, Helm, Ansible), pomaga przeszukiwać logi i korelować alerty przy incydentach, a agenci potrafią automatyzować powtarzalne zadania operacyjne. Inżynier, który sensownie korzysta z tych narzędzi, oszczędza kilka godzin dziennie i ma przewagę na rynku. To nie zastępuje wiedzy - przyspiesza tych, którzy ją mają.
DevOps pasuje do osób, które lubią rozumieć, jak rzeczy działają „od spodu", nie boją się terminala i czerpią satysfakcję z automatyzowania nudnych zadań. Wymaga ciągłej nauki - stos technologiczny zmienia się szybko - oraz odporności na stres, bo część pracy to reagowanie na awarie produkcji. Jeśli to brzmi zachęcająco, a nie odstraszająco, jesteś we właściwym miejscu. Reszta to kwestia konsekwencji i właściwej kolejności kroków.


Komentarze (0)
Brak komentarzy...