
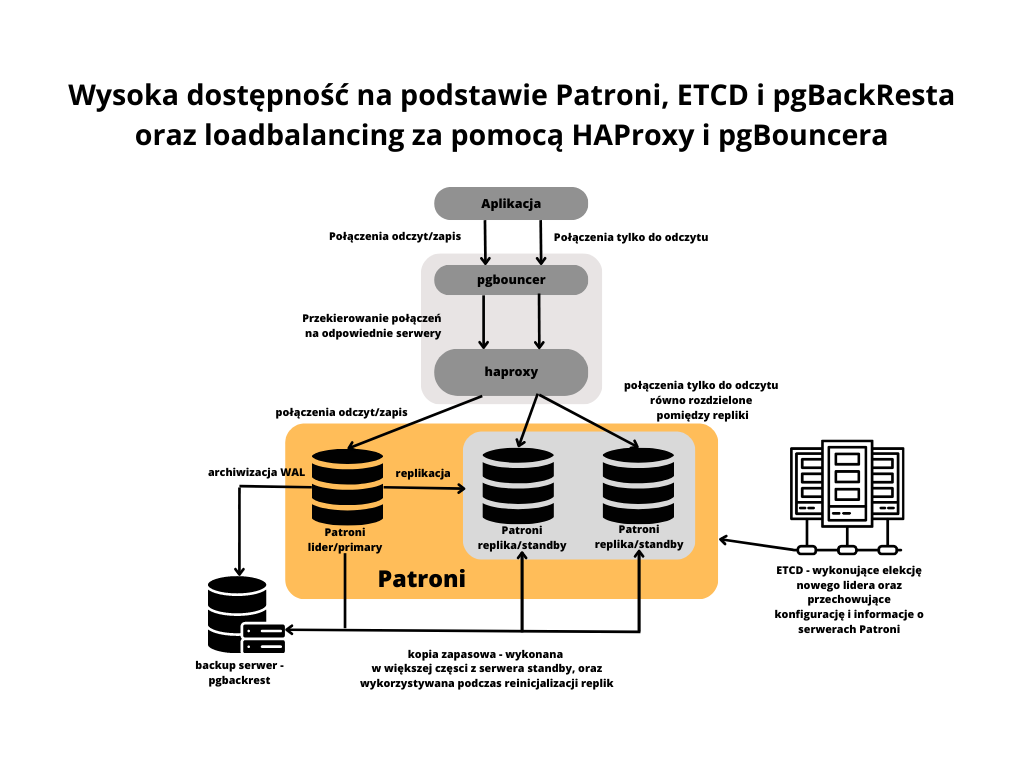
HAProxy to popularne bezpłatne oprogramowanie z otwartym źródłem umożliwiające load balancing, czyli automagiczne dystrybuowanie zapytań w grupie serwerów, przez co obniżamy obciążenie na pojedynczych serwerach, a często też przyspieszamy obsługę zapytań. Dzięki możliwości monitorowania dostępności oraz roli serwerów PostgreSQL, pozwala automatycznie rozdystrybuować połączenia wykonujące sam odczyt na wiele replik. Potrafi także sprawdzać ich status i natychmiast reagować na sytuacje, kiedy serwer lidera był awaryjnie przełączony, natychmiast przekierowując cały ruch na nowy serwer primary.
HAProxy również bardzo dobrze współpracuje z Patroni, między innymi pozwala na wykluczenie repliki z load balancingu poprzez ustawienie jej tagu "noloadbalance" w konfiguracji patroni oraz automatyczne śledzenie lidera po "failoverze/switchoverze".
W połączeniu z pgBouncerem i Patroni możemy stworzyć wysoce dostępny klaster, który bez problemu spełnia wymagania czterech czwórek w dostępności (SLA czyli dostepnosc serwera przez 99,99% czasu czyli 52 minuty w roku może nie banglać), a możemy osiągnąć ich jeszcze kilka. Po automatycznym failoverze haproxy w sam poszuka , na którym serwerze jest nowy lider Patroni, a dzięki połączeniu z pgbouncerem połączone aplikacje nie stracą połączenia i będą kontynuowały pracę na nowej instancji primary. Jedyne utracone transakcje to te, które były zacommitowane podczas failovera.
Znając możliwości API Patroni, skonfigurujemy HAProxy dla serwera mastera oraz zmienimy konfigurację pgBouncera, aby łączył się do patroni przez haproxy.
Najpierw kopiujemy plik konfiguracyjny z domyślną konfiguracją, a następnie tworzymy nowy plik configa haproxy. Dzięki temu nie musimy wykomentowywać wielu linii.
# serwer pgbouncer
sudo mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg_old
sudo vi /etc/haproxy/haproxy.cfgglobal
maxconn 300defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5slisten stats
mode http
bind *:7000
stats enable
stats uri /listen primary
bind *:5000
option httpchk OPTIONS /master
http-check expect status 200
default-server inter 1s fall 3 rise 2 on-marked-down shutdown-sessions
server pg1 pg1:5432 maxconn 100 check port 8008
server pg2 pg2:5432 maxconn 100 check port 8008
server pg3 pg3:5432 maxconn 100 check port 8008listen replica
bind *:5001
option httpchk OPTIONS /replica
http-check expect status 200
balance roundrobin
default-server inter 1s fall 3 rise 2 on-marked-down shutdown-sessions
server pg1 pg1:5432 maxconn 100 check port 8008
server pg2 pg2:5432 maxconn 100 check port 8008
server pg3 pg3:5432 maxconn 100 check port 8008
Sekcja GLOBAL parametry ustawiane na poziomie całego HAProxy oddziałujące na całość procesu, wszystkie listenery, itp.
Sekcja DEFAULTS zawiera domyślne ustawienia dla wszystkich zdefiniowanych backendów, frontendów czy listenerów.
Sekcje z definicją listenerów LISTEN
Konfiguracja zawarta w sekcji "listen primary" oraz "listen replica" sprawia, że haproxy odpytuje serwery pg1, pg2 i pg3 na porcie 8008, na którym nasłuchuje RestAPI Patroni. Wywołując zapytania z odpowiednio /master oraz /replica, sprawdza, który z serwerów odpowiada kodem 200, oznacza to, że serwer ten pełni odpytywaną rolę i haproxy połączy się do nich, kiedy otrzyma połączenie na porcie 5000 dla mastera/primary oraz na porcie 5001 dla replik.
Następnym krokiem będzie restart usługi haproxy oraz test połączenia
sudo systemctl restart haproxypsql -h pgbouncer -p 5000 -U postgres -c "select pg_is_in_recovery()"
pg_is_in_recovery
-------------------
f
(1 row)psql -h pgbouncer -p 5001 -U postgres -c "select pg_is_in_recovery()"
pg_is_in_recovery
-------------------
t
(1 row)
Spróbujmy jeszcze wykonać switchover i sprawdźmy, czy haproxy połączy nas do nowej instancji primary.
# Na dowolnym serwerze patroni
patronictl -c /etc/patroni/config.yml switchover szkolenie# Na serwerze z pgbouncerem i haproxy
psql -h pgbouncer -p 5000 -U postgres -c "select pg_is_in_recovery()"
Teraz możemy zmodyfikować konfigurację pgbouncera, aby ten łączył się z postgresem przez haproxy. Najważniejszą zmianą jest przepisanie sekcji [databases], gdzie ustawiamy dwa aliasy, z których będziemy korzystać, łącząc się do bazy:
# serwer pgbouncer
sudo vi /etc/pgbouncer/pgbouncer.ini[databases]
master = host=pgbouncer port=5000 dbname=postgres pool_size=90
replica = host=pgbouncer port=5001 dbname=postgres pool_size=90[pgbouncer]
logfile = /var/log/postgresql/pgbouncer.log
pidfile = /var/run/postgresql/pgbouncer.pid
unix_socket_dir = /var/run/postgresqllisten_addr = *
listen_port = 6432
pool_mode = transaction
max_client_conn = 10000
max_db_connections = 250
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
admin_users = postgres
Sprawdźmy teraz połączenie oraz wykonajmy testowo switchover.
# z serwera z pgbouncerem
psql -h pgbouncer -p 6432 -U postgres mastermaster=# select pg_is_in_recovery(),now(),inet_server_addr();
pg_is_in_recovery | now | inet_server_addr
-------------------+-------------------------------+------------------
f | 2022-11-29 21:28:40.225751+00 | 192.168.56.12
(1 row)master=# \watch 1
# na serwerze z patroni
patronictl -c /etc/patroni/config.yml switchover szkolenieTue Nov 29 21:29:12 2022 (every 1s)
pg_is_in_recovery | now | inet_server_addr
-------------------+-------------------------------+------------------
f | 2022-11-29 21:29:12.452795+00 | 192.168.56.12
(1 row)Tue Nov 29 21:29:13 2022 (every 1s)
pg_is_in_recovery | now | inet_server_addr
-------------------+-------------------------------+------------------
f | 2022-11-29 21:29:28.536762+00 | 192.168.56.11
Całkowita przerwa w działaniu aplikacji wyniosła ok 16 sekund. Połączenie pozostało aktywne i mogło kontynuować pracę po wykonaniu failovera. Musiało jedynie poczekać, aż haproxy znajdzie nową instancję primary.


Komentarze (0)
Brak komentarzy...