Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!

Zanim pentester uruchomi pierwszy exploit, spędza godziny - nierzadko całe dni - na pasywnym recon. Dobry OSINT potrafi ujawnić rzeczy, których nie znajdziesz żadnym skanerem: hasła w leaked dumps z poprzednich lat, wewnętrzne adresy IP ukryte w metadanych dokumentów PDF, profile pracowników na LinkedIn, które wprost zdradzają technologie używane w firmie. Wszystko to z publicznie dostępnych źródeł, bez wysyłania choćby jednego pakietu na serwer celu.
W tym artykule przejdziesz przez pełną metodologię OSINT - od planowania i zbierania informacji, przez konkretne narzędzia i komendy, po raportowanie znalezisk. Każdą technikę opiszemy zarówno z perspektywy ofensywnej (jak działa atakujący), jak i defensywnej (co możesz zrobić, żeby ograniczyć własny footprint).
OSINT (Open Source Intelligence) - wywiad otwartoźródłowy - to metodologia zbierania i analizowania informacji wyłącznie z publicznie dostępnych źródeł. Termin pochodzi z wojskowości i wywiadu, ale od lat stanowi fundament testów penetracyjnych i analizy bezpieczeństwa w sektorze komercyjnym.
Źródła OSINT obejmują szeroki zakres danych:
OSINT jest legalny, gdy dotyczy własnej organizacji, jest wykonywany w ramach autoryzowanego testu penetracyjnego (z pisemną zgodą właściciela systemu) lub jest częścią CTF (Capture The Flag). Art. 267 Kodeksu karnego penalizuje nieautoryzowany dostęp do systemów informatycznych - sama analiza publicznie dostępnych danych jej nie narusza.
Defensywne użycie OSINT - regularne sprawdzanie własnego footprintu z perspektywy atakującego - to element dojrzałości bezpieczeństwa każdej organizacji. Jeśli Ty to widzisz, widzi to też przeciwnik.
Profesjonalny OSINT nie polega na chaotycznym "googlowaniu". Każde badanie powinno przejść przez cztery etapy Intelligence Cycle:
Zdefiniuj cel: domena, organizacja, konkretna osoba, zakres IP. Określ pytania, na które chcesz odpowiedzieć: Czy firma ma publicznie dostępne subdomeny z panelami administracyjnymi? Czy pracownicy używają firmowych emaili w zewnętrznych serwisach? Czy w repozytoriach kodu są hardcodowane klucze API? Bez jasnego celu zbierasz góry danych bez wartości.
Pasywne zbieranie (recon) oznacza, że cel nie zobaczy Twojego ruchu w logach - korzystasz z danych pośrednich (Google, Shodan, crt.sh). Aktywne zbieranie wysyła zapytania bezpośrednio do infrastruktury celu (nslookup, ping, skanowanie portów) - zostawia ślady. W pentestach czarnoskrzynkowych zacznij od pasywnego.
Sam fakt, że firma używa Apache 2.4.49, nic nie znaczy - ale w połączeniu z informacją, że ta wersja jest podatna na CVE-2021-41773 (path traversal RCE), i że serwer jest publicznie dostępny na porcie 80, staje się znaleziskiem krytycznym. Do analizy powiązań świetnie sprawdza się Maltego lub proste grafy w Obsidian/draw.io.
Każde znalezisko: timestamp kiedy znalezione, źródło (URL, narzędzie), screenshot lub surowe dane, ocena ryzyka. Dobrze udokumentowany OSINT to podstawa raportu z pentestu i dowód w przypadku sporu co do zakresu badania.
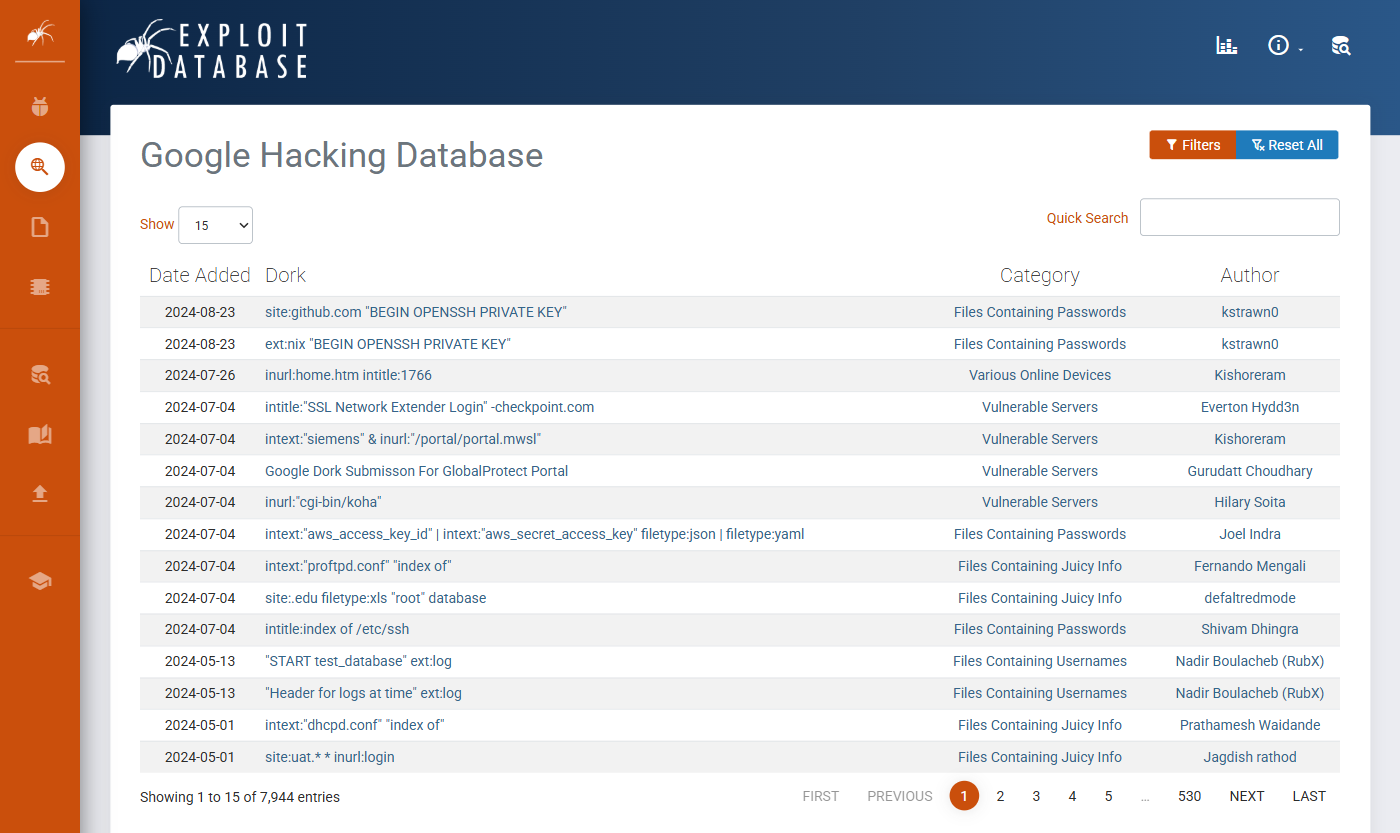
Google Dorks (zwane też Google Hacking) to zaawansowane operatory wyszukiwania, które pozwalają precyzyjnie wskazywać typy plików, frazy w tytułach stron czy zawartości URL. To jedno z najpotężniejszych narzędzi OSINT - i nie wymaga instalacji niczego.
# Dokumenty z potencjalnie wrażliwą zawartością
site:target.pl filetype:pdf "confidential"
site:target.pl filetype:xlsx "password"
site:target.pl filetype:docx "internal use only"
# Otwarte katalogi (directory listing)
intitle:"index of" site:target.pl
intitle:"index of" "backup" site:target.pl
# Panele administracyjne
inurl:admin site:target.pl
inurl:login inurl:admin site:target.pl
inurl:wp-admin site:target.pl
inurl:phpmyadmin site:target.pl
# Błędy baz danych (świadczą o podatnościach SQL Injection)
site:target.pl "ORA-01756" OR "ORA-00907"
site:target.pl "mysql_fetch_array" OR "mysql_num_rows"
site:target.pl "Uncaught exception" OR "Fatal error"
site:target.pl "Warning: pg_connect()"
# Pliki konfiguracyjne i backupy
site:target.pl ext:conf OR ext:cfg OR ext:ini OR ext:env
site:target.pl ext:bak OR ext:backup OR ext:old
site:target.pl "config.php" OR ".env" OR "web.config"
# Subdomeny (pasywne wyliczanie)
site:*.target.pl -www -mail -smtp -pop3
# Wycieki kredencjałów na GitHub
"target.pl" site:github.com password OR secret OR api_key OR token
"@target.pl" site:github.com "BEGIN RSA PRIVATE KEY"
"target.pl" site:pastebin.com
site: w Google - jednym zapytaniem zwraca wszystkie zaindeksowane podstrony domeny. To punkt wyjścia do dalszych dorków zawężających po typie pliku, tytule czy fragmencie URL.Gotowe dorki dla znanych podatności znajdziesz w Google Hacking Database (GHDB) na exploit-db.com - tysiące skategoryzowanych zapytań dla paneli logowania, kamer IP, plików konfiguracyjnych i wiele więcej. Używaj z głową i tylko na autoryzowanych celach.
Bing (ip: operator) indeksuje inne strony niż Google. DuckDuckGo bywa mniej agresywny w filtrowaniu wyników. Yandex szczególnie dobrze indeksuje zasoby wschodnioeuropejskie. Używaj kilku wyszukiwarek równolegle - każda ma inne indeksy.
Subdomeny to często zapomniane wejścia do infrastruktury: dev.target.pl, staging.target.pl, vpn-old.target.pl - środowiska testowe ze starym oprogramowaniem, panele administracyjne bez zewnętrznego dostępu z głównej domeny, zapomniane serwery. Pasywna enumeracja subdomen jest całkowicie legalna i nie zostawia śladów w logach celu.
# WHOIS - właściciel domeny, dane rejestracyjne, daty wygaśnięcia
whois target.pl
whois 1.2.3.4 # odwrotny WHOIS dla IP
# Rekordy DNS - wszystkie typy naraz
dig target.pl ANY
dig +short MX target.pl # serwery mailowe (wynika technologia email: GSuite, O365, własny)
dig +short TXT target.pl # SPF, DMARC, weryfikacje usług (Google Workspace, HubSpot...)
dig +short NS target.pl # name serwery (provider hostingu)
nslookup -type=TXT target.pl
# Subdomain brute-force (aktywne - wysyła zapytania DNS)
dnsenum --dnsserver 8.8.8.8 --enum target.pl -f /usr/share/wordlists/dnsmap.txt
subfinder -d target.pl -o subdomains.txt
amass enum -passive -d target.pl # tryb pasywny (tylko zewnętrzne źródła)
amass enum -active -brute -d target.pl # aktywny brute-force
# Certificate Transparency - PASYWNE, absolutnie nie zostawia śladów
# crt.sh to publiczne logi certyfikatów SSL - każdy cert wystawiony dla *.target.pl jest widoczny
# (do parsowania JSON potrzebny jq: sudo apt install jq)
curl "https://crt.sh/?q=%.target.pl&output=json" | jq -r '.[].name_value' | sort -u
# Reverse DNS dla zakresu IP - znajdź inne domeny na tym samym serwerze
for ip in $(dig +short target.pl); do
dig +short -x $ip
done
# DNS zone transfer - rzadko działa, ale warto sprawdzić
dig axfr target.pl @ns1.target.pl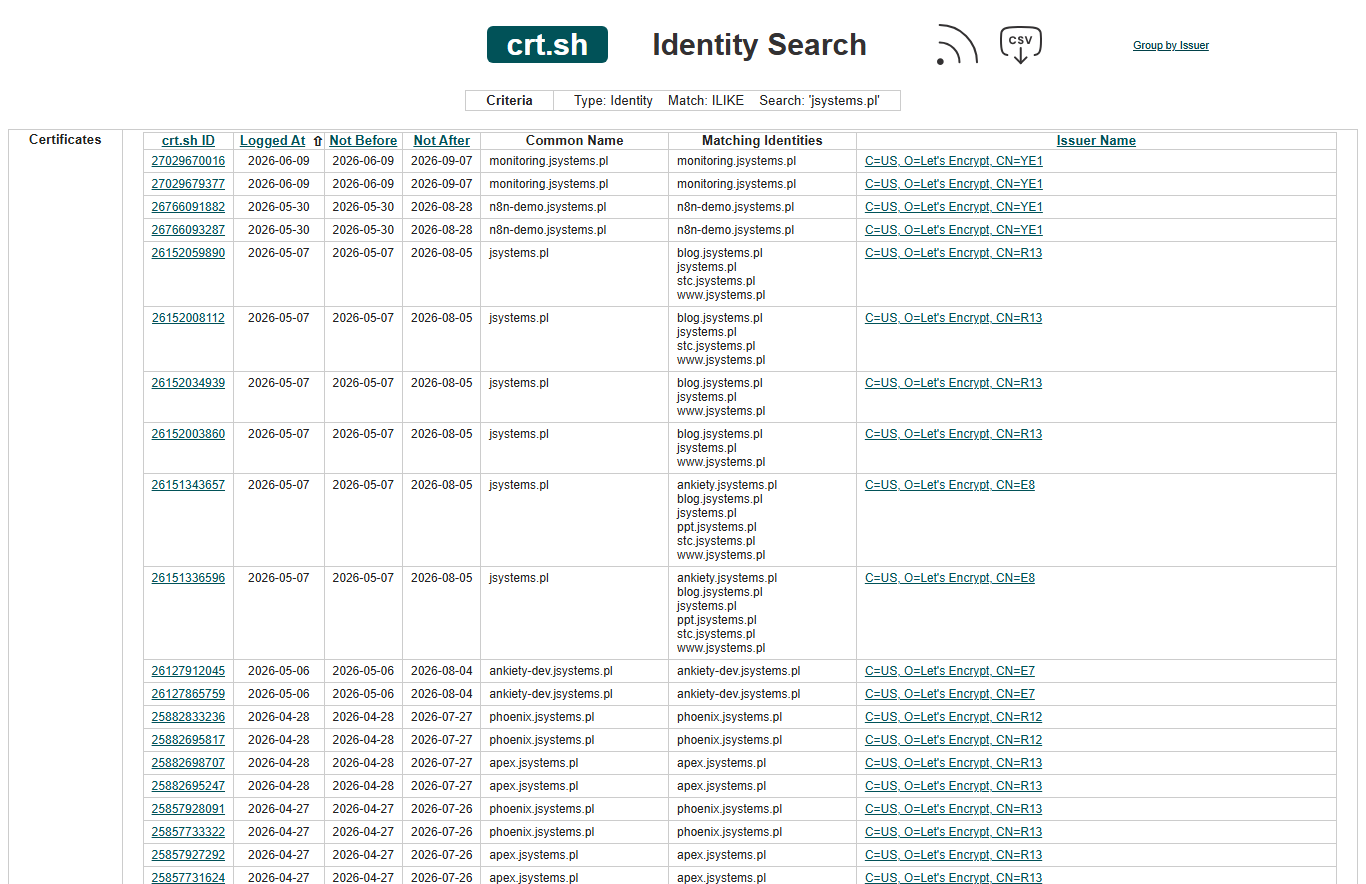
DNSDumpster (dnsdumpster.com) to darmowy web tool, który agreguje rekordy DNS i rysuje mapę infrastruktury - świetny punkt startowy. SecurityTrails i VirusTotal prowadzą historyczne rekordy DNS - pokazują, jak adresy IP i serwery domeny zmieniały się w czasie, co często ujawnia zapomniane lub wycofane hosty.
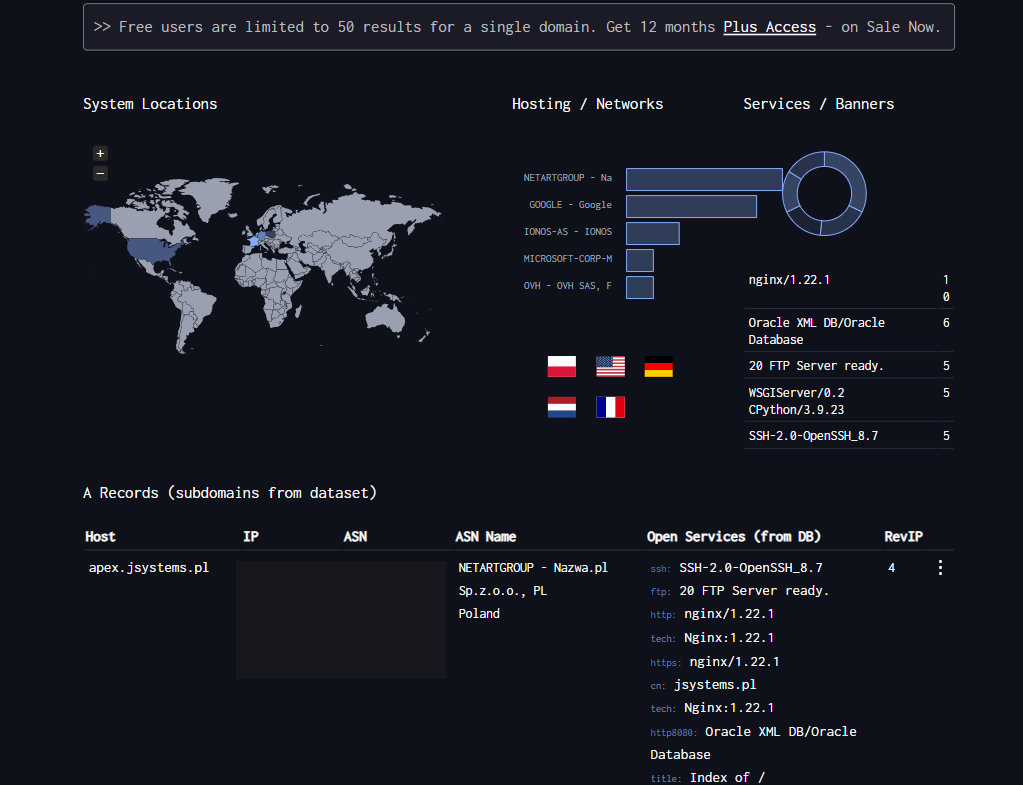
Shodan to wyszukiwarka, która zamiast stron internetowych indeksuje usługi sieciowe: otwarte porty, bannery serwisów, certyfikaty SSL, wersje oprogramowania. Skanuje cały internet i aktualizuje indeks regularnie - wystarczy zapytanie, żeby zobaczyć co dana organizacja wystawia na świat.
# Szukaj po organizacji (ASN/ISP)
org:"Firma XYZ Sp. z o.o."
org:"JSystems"
# Szukaj po domenie/hostname
hostname:target.pl
hostname:.target.pl # wszystkie subdomeny
# Szukaj po zakresie IP
net:1.2.3.0/24
# Specyficzne usługi i porty - Polska
port:3389 country:PL # RDP dostępne publicznie w Polsce
port:22 banner:"OpenSSH 7" country:PL # stare wersje SSH
port:5432 country:PL # PostgreSQL wystawiony publicznie
port:27017 country:PL "MongoDB" # MongoDB bez autentykacji
# Podatne wersje oprogramowania
product:"Apache httpd" version:"2.4.49" # CVE-2021-41773 (RCE)
product:"Microsoft IIS" version:"6.0" # Windows Server 2003 - EOL
product:"OpenSSL" version:"1.0.1" # podatna na Heartbleed
# Domyślne hasła, panele administracyjne
"default password" country:PL
http.title:"Cisco IOS" country:PL
http.title:"Router Login" country:PL
http.title:"phpMyAdmin" port:80 country:PL
# Wyszukaj certyfikat SSL powiązany z domeną
ssl:"target.pl"
ssl.cert.subject.cn:target.pl
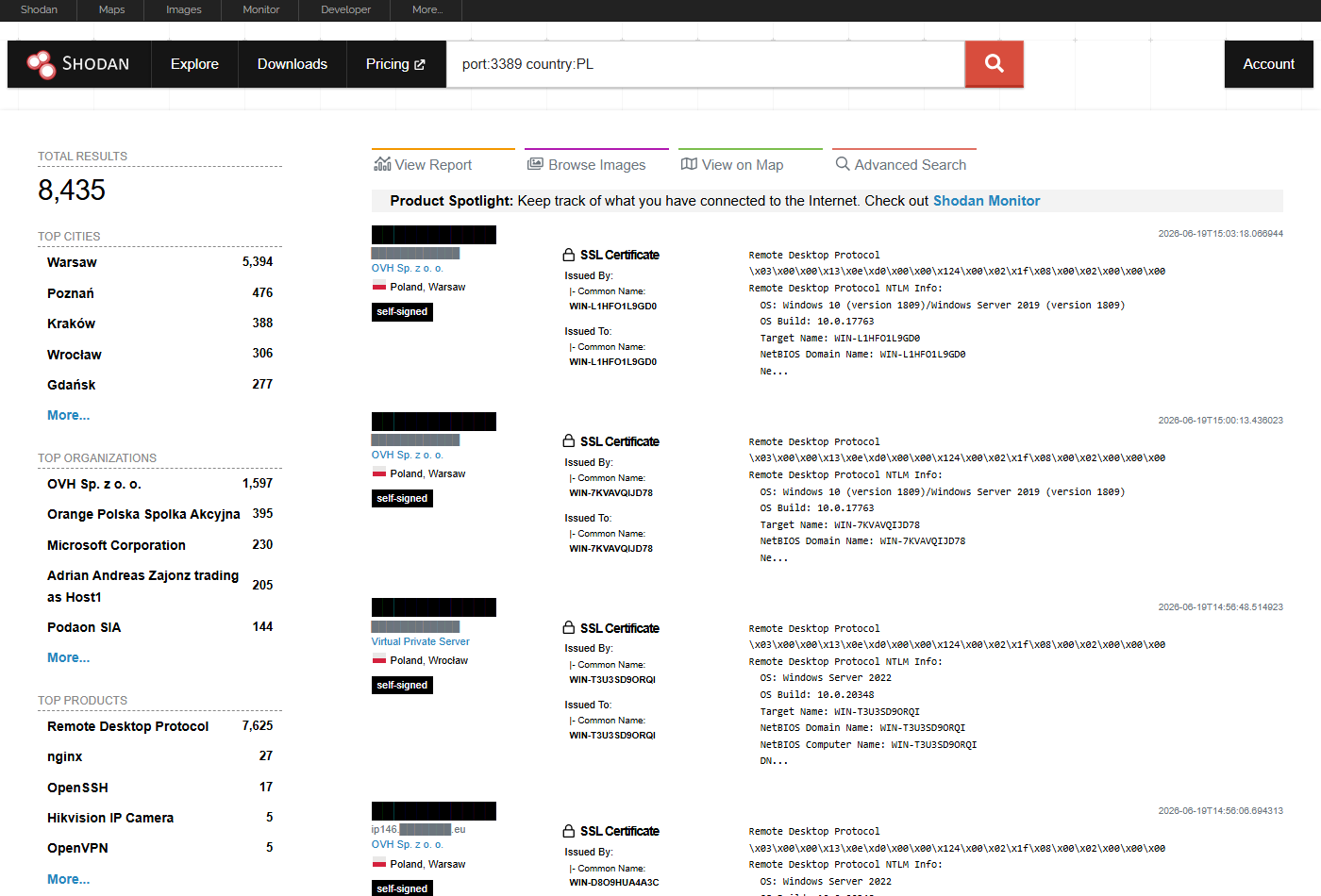
port:3389 country:PL - ponad 8 tysięcy usług Pulpitu zdalnego (RDP) wystawionych publicznie w Polsce, z rozbiciem na miasta, dostawców i produkty. Każdy z tych hostów to gotowa powierzchnia ataku (zgadywanie haseł, podatności RDP). Adresy IP i nazwy hostów zamaskowaliśmy - na żywym Shodanie są jawne.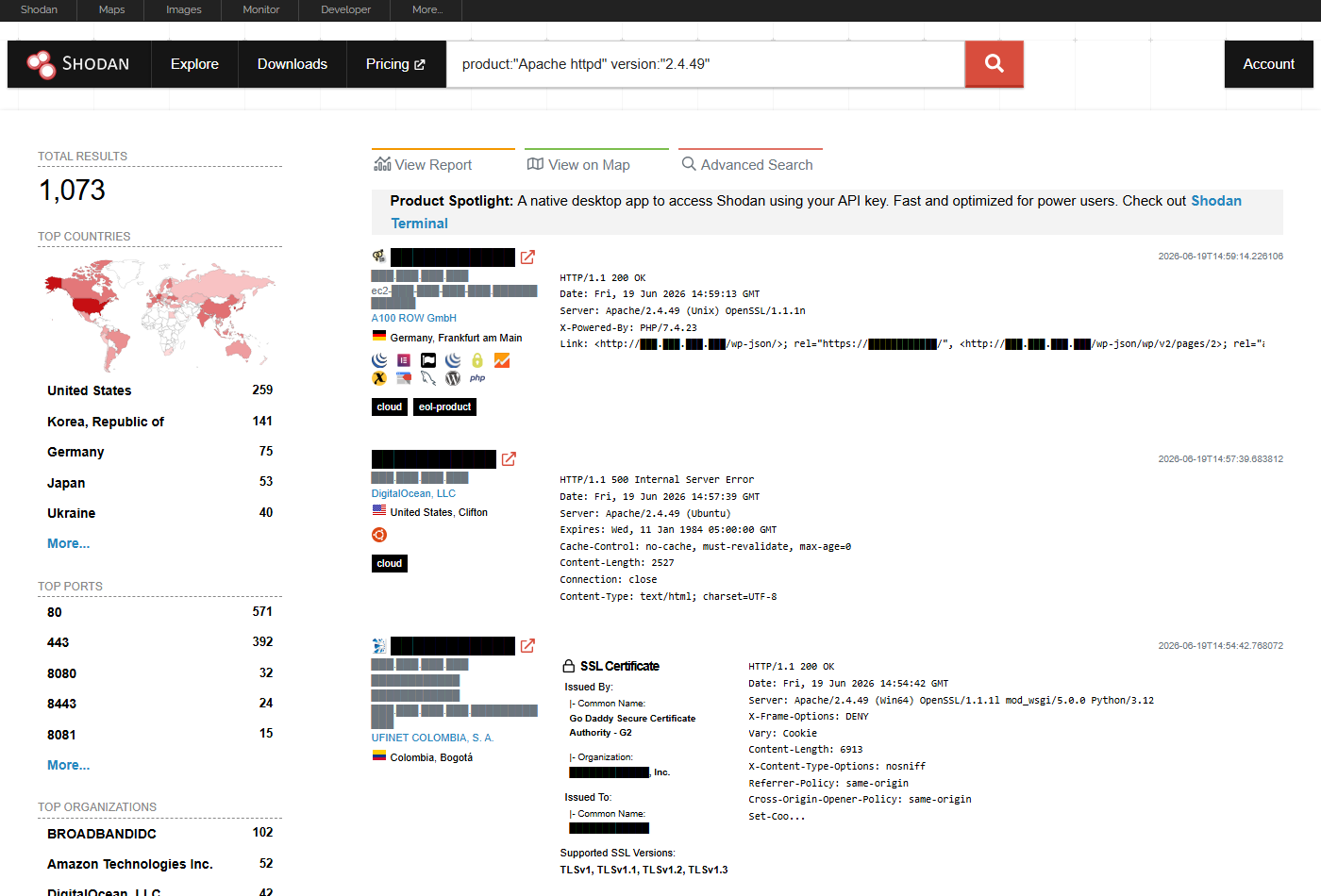
product:"Apache httpd" version:"2.4.49" - ponad tysiąc serwerów wciąż na Apache 2.4.49, wersji podatnej na CVE-2021-41773 (path traversal prowadzący do zdalnego wykonania kodu). Nagłówek Server: Apache/2.4.49 w bannerze zdradza wersję wprost - to praktycznie gotowa lista celów. Adresy zamaskowaliśmy.# Instalacja CLI
pip install shodan
shodan init YOUR_API_KEY
# Wyszukiwanie przez CLI
shodan search --fields ip_str,port,org "hostname:target.pl"
shodan host 1.2.3.4 # informacje o konkretnym IP
# Python API - automatyczne skanowanie zakresu
import shodan
api = shodan.Shodan("YOUR_API_KEY")
results = api.search("org:'Firma XYZ' country:PL")
for r in results['matches']:
print(f"{r['ip_str']}:{r['port']} - {r.get('product','')} {r.get('version','')}")Shodan Monitor (płatna funkcja) pozwala skonfigurować alert - gdy nowe IP z Twojej organizacji pojawi się w indeksie, dostaniesz powiadomienie. Dla zespołów security to must-have.
Alternatywy: Censys (lepszy przy analizie certyfikatów SSL), FOFA (chiński odpowiednik, czasem indeksuje inne zasoby), ZoomEye (warto sprawdzić przy celach globalnych).
Pamiętaj: Shodan tylko indeksuje dane - sam fakt, że sprawdzasz domenę w Shodan, nie generuje ruchu na serwerze celu. To w pełni pasywna technika.
Jednym z najcenniejszych znalezisk w OSINT są adresy email pracowników połączone z informacją, że ich hasła wyciekły w przeszłości. W świecie, gdzie ponowne używanie tego samego hasła (password reuse) jest nagminne, nawet 5-letni wyciek może dawać aktualny dostęp.
Stąd bierze się popularny atak zwany password spray („rozpylanie hasła"). Zamiast bombardować jedno konto tysiącem haseł - co szybko wywoła blokadę konta - atakujący odwraca logikę: bierze jedno hasło (popularne, jak Wiosna2026!, albo wprost wykradzione z wycieku) i próbuje go po kolei na setkach kont firmowych. Wystarczy, że pasuje do jednego pracownika, a każde konto dostaje tylko jedną próbę - poniżej progu blokady. Dlatego lista nazwisk i loginów z OSINT plus jedno hasło z wycieku to gotowy scenariusz włamania.
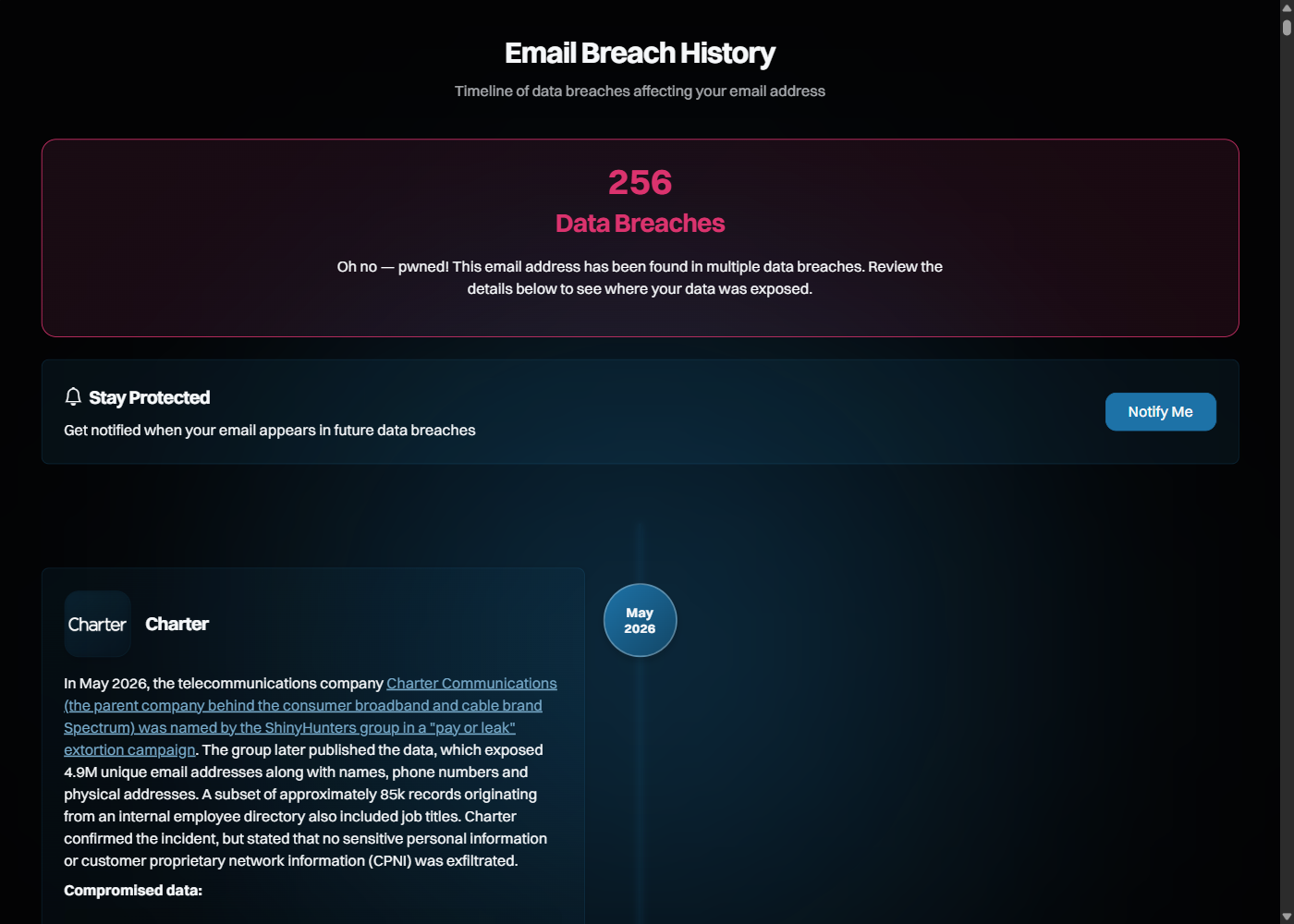
Podstawowym narzędziem do takiego sprawdzenia jest Have I Been Pwned (HIBP) - bezpłatny serwis haveibeenpwned.com stworzony przez badacza bezpieczeństwa Troya Hunta, gromadzący dane z setek publicznie ujawnionych naruszeń. Wpisujesz adres email, a HIBP pokazuje, w ilu i w których wyciekach ten adres się pojawił oraz jakie kategorie danych ujawniono (hasła, numery telefonów, adresy). Dla analityka OSINT to pierwszy ruch w fazie zbierania: sprawdzić, czy adresy pracowników celu figurują w znanych wyciekach. Poniższy zrzut to wynik realnego sprawdzenia pojedynczego adresu - serwis zwrócił historię naruszeń, w których się pojawił.
HIBP odpowiada na pytanie „czy ten adres wyciekł", ale najpierw trzeba mieć listę adresów i hostów do sprawdzenia. Do ich zebrania służy theHarvester - klasyczne, darmowe narzędzie open source autorstwa Christiana Martorelli (Edge-Security), jedno z pierwszych, po które sięga pentester w fazie rozpoznania. Jednym poleceniem odpytuje kilkanaście publicznych źródeł naraz (m.in. certyfikaty z crt.sh, DuckDuckGo, AlienVault OTX, RapidDNS, HackerTarget, Certspotter, a po podaniu kluczy API także Shodan i VirusTotal) i zwraca adresy email pracowników, subdomeny oraz hosty powiązane z badaną domeną - wszystko pasywnie, bez wysyłania ruchu na serwer celu.
Tylko w Kali Linux (i Parrot OS) theHarvester jest gotowym pakietem w repozytorium - wystarczy jedno polecenie. Uwaga: w zwykłym Debianie ani Ubuntu tego pakietu nie ma (apt install theharvester zwróci „Unable to locate package"), a pakiet theHarvester z PyPI to nieaktualna zaślepka. Tam instalujesz go ze źródeł menedżerem uv. Poniższy zestaw poleceń przeszedłem na czystej Ubuntu 24.04 - kończy się globalnie dostępną komendą theHarvester:
# === Kali Linux / Parrot OS (jest w repo dystrybucji) ===
sudo apt update && sudo apt install theharvester
theHarvester -h # weryfikacja: banner + pomoc
# === Debian / Ubuntu 24.04 / macOS / dowolny system: ze źródeł przez uv ===
# Czysta Ubuntu nie ma nawet git ani curl - najpierw je doinstaluj:
sudo apt update && sudo apt install -y git curl
# Menedżer uv (po instalacji dodaj go do PATH bieżącej sesji):
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
# Pobierz źródła i zainstaluj jako globalne narzędzie (komenda theHarvester w PATH):
git clone https://github.com/laramies/theHarvester
uv tool install ./theHarvester
theHarvester -h # weryfikacja: banner + pomoc (działa globalnie)Po tej instalacji komenda theHarvester działa z dowolnego katalogu. Jeśli wolisz nie instalować jej globalnie, możesz pominąć uv tool install i uruchamiać narzędzie z katalogu repozytorium poleceniem uv run theHarvester ... (po wcześniejszym uv sync).
Podstawowe wywołanie wskazuje domenę (-d), listę źródeł rozdzieloną przecinkami bez spacji (-b) i limit wyników na źródło (-l). Poniższy zestaw źródeł nie wymaga żadnych kluczy API - działa od razu po instalacji:
# Pasywne zbieranie z darmowych źródeł (bez kluczy API)
theHarvester -d jsystems.pl -b crtsh,otx,hackertarget,rapiddns,duckduckgo,certspotter -l 500
# Zapis wyników do raportu (-f tworzy raport.json i raport.xml)
theHarvester -d jsystems.pl -b crtsh,otx,hackertarget,rapiddns,certspotter -f raport
# Źródła wymagające klucza API (shodan, hunter, virustotal, securityTrails)
# podajesz w pliku /etc/theHarvester/api-keys.yaml - wtedy dorzucasz je do -bLista dostępnych źródeł zmienia się między wersjami - pełny, aktualny zestaw zobaczysz poleceniem theHarvester -h (sekcja -b). Nazwy takie jak google, bing czy linkedin z dawnych poradników w nowych wydaniach już nie istnieją - jeśli podasz nieobsługiwane źródło, narzędzie zwróci błąd.
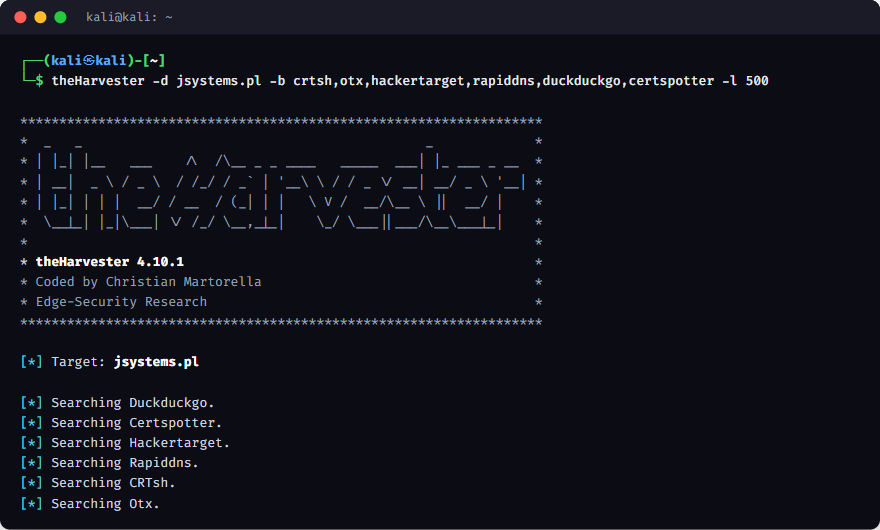
Po kilku sekundach theHarvester zwraca zagregowaną listę. Dla jsystems.pl wynik to 25 hostów - w tym subdomeny, których nie ma w głównym menu strony: środowiska deweloperskie (ankiety-dev, stc-dev), instancje narzędzi (n8n-demo, monitoring) i aplikacje wewnętrzne. Każda z nich to potencjalny, słabiej pilnowany punkt wejścia. To samo ćwiczenie warto zrobić na własnej domenie, żeby zobaczyć, co wystawiasz na świat.
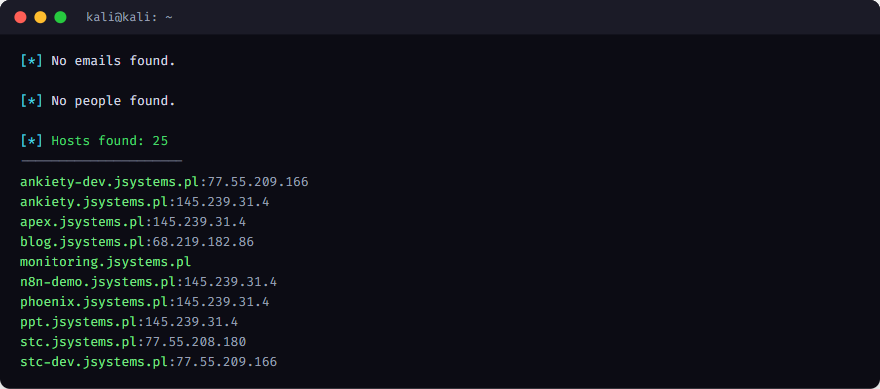
W tym pasywnym przebiegu theHarvester nie znalazł adresów email (na zrzucie sekcja „No emails found") - przy darmowych źródłach to częste, bo większość maili siedzi za logowaniem albo w źródłach wymagających klucza API (Hunter.io, dehashed). Gdy jednak adresy się pojawią - z theHarvester po dodaniu kluczy, z Hunter.io albo z metadanych dokumentów - kolejnym krokiem jest sprawdzenie ich w bazie HIBP: czy któryś figuruje w znanych wyciekach. Zapytanie do API wymaga klucza (HIBP udostępnia go odpłatnie):
# Sprawdź pojedynczy adres w Have I Been Pwned (HIBP)
curl -s "https://haveibeenpwned.com/api/v3/breachedaccount/user@jsystems.pl" \
-H "hibp-api-key: YOUR_HIBP_KEY" \
-H "User-Agent: OSINT-Assessment"
# Masowe sprawdzanie listy adresów z pliku emails.txt
while read email; do
result=$(curl -s -H "hibp-api-key: YOUR_HIBP_KEY" \
"https://haveibeenpwned.com/api/v3/breachedaccount/$email")
if [ "$result" != "null" ] && [ -n "$result" ]; then
echo "WYCIEK: $email - $result"
fi
sleep 1.5 # limit zapytań: maks. 1 co 1,5 s
done < emails.txtHunter.io (hunter.io) - wpisz domenę, zwraca listę emaili z publicznych źródeł + schemat formatu (imie.nazwisko@target.pl lub i.nazwisko@target.pl). Darmowe 25 zapytań miesięcznie.
# Hunter.io API
curl "https://api.hunter.io/v2/domain-search?domain=target.pl&api_key=YOUR_KEY"
# Emailrep.io - reputacja adresu email (wymaga darmowego klucza API; bez niego limit zapytań / HTTP 429)
curl "https://emailrep.io/user@target.pl" -H "Key: YOUR_EMAILREP_KEY"
# Zwraca: czy email w breach DB, czy używany w social media, data ostatniej aktywnościMonitoring Pastebin i GitHub: Usługi takie jak Leakix.net, Breachforums (monitoruj przez bezpieczne przeglądarki) czy IntelX (intelligence.x) indeksują wycieki w czasie rzeczywistym. Dedykowane narzędzia jak PasteHunter automatyzują monitoring Pastebin pod kątem fraz związanych z Twoją organizacją.
Dokumenty publikowane na stronach firmowych (raporty roczne, specyfikacje, prezentacje, instrukcje) niosą w sobie metadane: nazwisko autora, login domenowy, wewnętrzne ścieżki plików, używane oprogramowanie i jego wersje, daty modyfikacji, nazwy serwerów. To kompletna mapa środowiska - gotowa do odkrycia bez jednego pakietu sieciowego na cel.
# Pobierz pliki PDF i DOCX z domeny (wget spider)
wget -r -l 2 -A ".pdf,.docx,.xlsx,.pptx" \
--no-parent -nd -P ./docs \
https://target.pl/
# ExifTool - wyciągnij wszystkie metadane z pliku
exiftool dokument.pdf
# Przykładowe wyniki:
# Author : jan.kowalski@target.pl
# Creator : Microsoft Word 2019
# Creator Tool : Acrobat PDFMaker 21 for Word
# Company : Target Sp. z o.o.
# Last Saved By : WIN-SERVER2019\jan.kowalski
# Template : \\fileserver\szablony\raport_roczny.dotx
# Masowe wyciąganie metadanych - szukaj loginów domenowych i emaili
exiftool -r -Author -Creator -LastSavedBy -Company \
-Software -Producer -Template ./docs/ \
| grep -iE '@target|\\target|target\\'
# Wyciągnij tylko autentyczne emaile z metadanych (unikaj śmieci)
exiftool -r -Author ./docs/ | grep -oP '[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}'
# Usuń metadane ze swojego dokumentu przed publikacją
exiftool -all= -overwrite_original dokument.pdfTe polecenia tworzą kompletny łańcuch. Najpierw wget w trybie pająka pobiera z domeny wszystkie pliki PDF, DOCX, XLSX i PPTX (do dwóch poziomów w głąb) do katalogu ./docs. Potem exiftool wyciąga z nich metadane - dla pojedynczego pliku albo, z flagą -r (rekurencyjnie), dla całego katalogu naraz.
Najważniejsze jest to masowe polecenie. Exiftool przechodzi po wszystkich pobranych dokumentach i wypisuje tylko wybrane pola (autor, twórca, „ostatnio zapisał", firma, oprogramowanie, szablon), a grep -iE '@target|\\target|target\\' przesiewa ten wysyp pod kątem trzech najcenniejszych wzorców: adresów email (fragment @target), ścieżek sieciowych UNC (\\target, czyli \\serwer\udział) oraz loginów domenowych (target\, czyli DOMENA\użytkownik). Słowo target podmieniasz na nazwę badanej firmy. Efekt: jednym łańcuchem poleceń wyłuskujesz z publicznych dokumentów nazwiska, loginy i nazwy wewnętrznych serwerów - bez logowania się gdziekolwiek. Ostatnia komenda (-all=) działa odwrotnie - czyści metadane z Twojego pliku, zanim go opublikujesz.
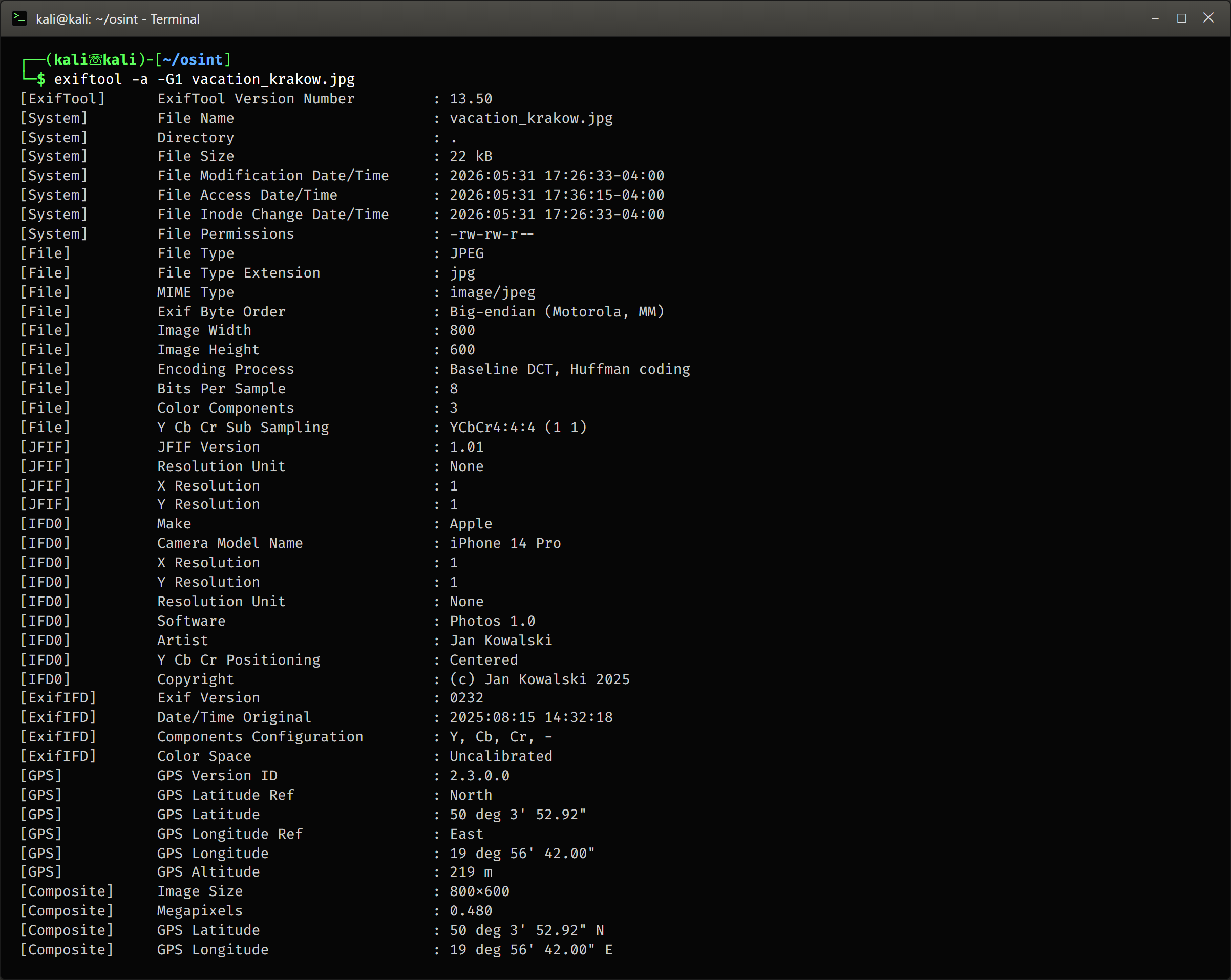
Co można znaleźć w metadanych? Historyczne loginy domenowe (DOMENA\uzytkownik) umożliwiają budowanie listy nazw użytkowników do ataków password spray. Wewnętrzne ścieżki UNC (\\fileserver\share\projekt) zdradzają nazwy serwerów wewnętrznych i strukturę zasobów. Wersje Acrobata czy Word mogą wskazywać niezałatane oprogramowanie.
FOCA (Fingerprinting Organizations with Collected Archives) to dedykowane narzędzie do automatycznej analizy metadanych - pobiera dokumenty z domeny, analizuje i wizualizuje znaleziska. Dostępne dla Windows.
LinkedIn to kopalnia informacji dla atakującego. Pracownicy sami publikują: stanowisko, zakres obowiązków, technologie których używają, projekty nad którymi pracują. Administrator sieci, który napisał „zarządzam środowiskiem Cisco ASA 5506 i Palo Alto" właśnie zdradził, jakiego firewalla używa jego pracodawca - bez żadnego skanowania. Prześledźmy to na publicznym profilu prawdziwej firmy - InPost (operator paczkomatów), korzystając wyłącznie z danych widocznych po zalogowaniu na zwykłe konto.
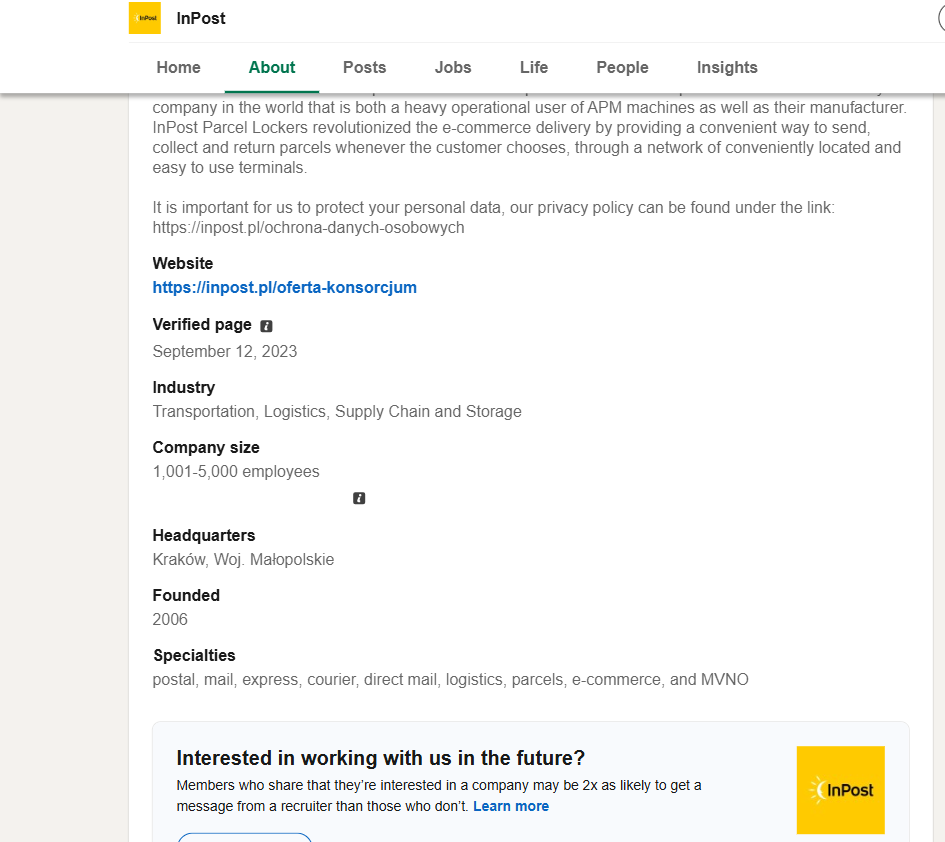
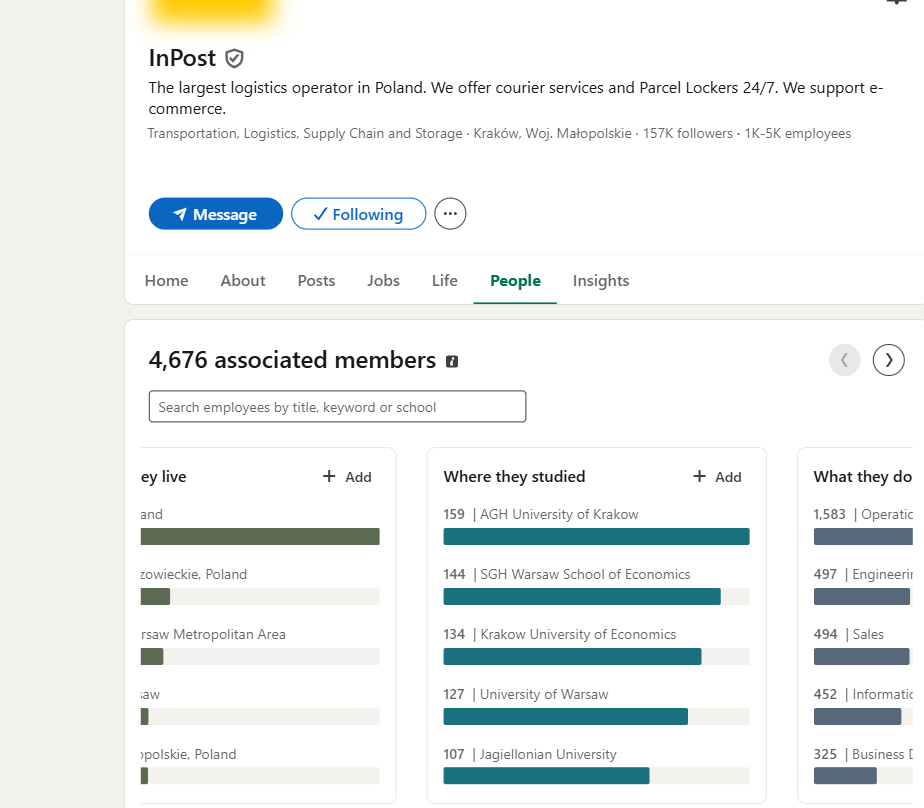
Zakładka „About" strony firmowej to gotowa metryczka organizacji. W przypadku InPostu czytamy z niej wprost: branża (Transport, logistyka, łańcuch dostaw), wielkość (przedział 1 001-5 000 pracowników), siedziba (Kraków), rok założenia (2006), oficjalna witryna oraz lista specjalizacji (od usług kurierskich po MVNO). Dla atakującego to ramy całego badania: skala firmy, główna lokalizacja (a więc i prawdopodobne strefy czasowe pracy oraz uczelnie, z których rekrutuje) i obszary działalności.
Zakładka „People" daje coś cenniejszego niż pojedyncze profile - zagregowaną analitykę całej załogi, bez potrzeby wchodzenia w czyjekolwiek dane osobowe. LinkedIn sam pokazuje, gdzie pracownicy mieszkają, gdzie studiowali i czym się zajmują. Dla InPostu (4 676 powiązanych członków na LinkedIn) widać, że załoga rekrutuje się głównie z krakowskich i warszawskich uczelni (AGH, SGH, Uniwersytet Ekonomiczny, UW, UJ), a w podziale funkcyjnym dominuje pion operacyjny, ale działy „Engineering" i „Information Technology" liczą po kilkaset osób. To gotowa mapa: które uczelnie podsuwać w pretekstach phishingu, jak duży jest zespół techniczny i gdzie szukać celów. Pole „Search employees by title, keyword or school" pozwala dodatkowo zawęzić listę po stanowisku - na przykład do osób z „security" albo „DevOps" w tytule.
Żeby z tysięcy pracowników wyłuskać konkretne role, używasz operatorów boolowskich - zarówno w wyszukiwarce LinkedIn, jak i w Google przez operator site:. Na przykład site:linkedin.com/in "InPost" (DevOps OR "Site Reliability" OR security) zwróci publiczne profile osób z tych obszarów. Operatory AND, OR, NOT, cudzysłowy (fraza dokładna) i nawiasy (grupowanie) działają jak w SQL - budujesz precyzyjne zapytanie zamiast przeglądać listę ręcznie. Tak powstaje orgchart: kto jest CTO, kto odpowiada za bezpieczeństwo, kto ma w tytule „cloud" czy „Kubernetes". To zarazem lista potencjalnych celów spear phishingu.
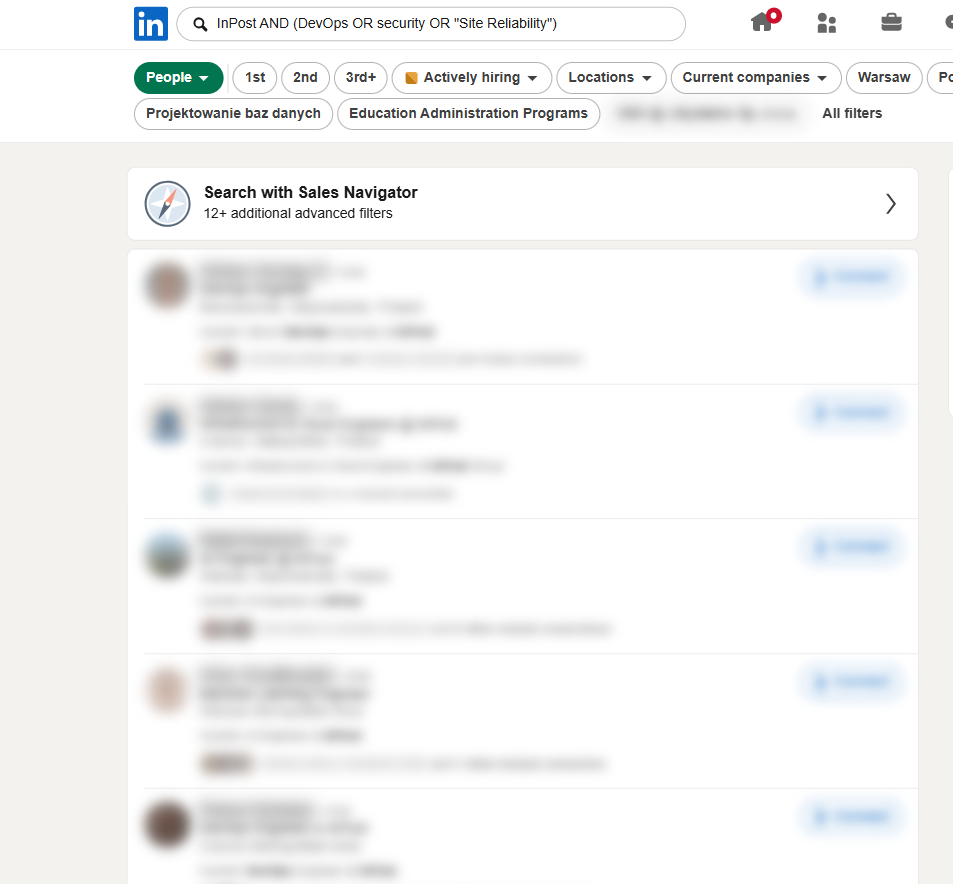
InPost AND (DevOps OR security OR "Site Reliability") zwraca listę pracowników z tych obszarów (tu m.in. DevOps, Cloud i AI Engineers). Zdjęcia i nazwiska zamaskowaliśmy - na żywo widać pełne profile, stanowiska i wspólne kontakty. Operatory AND/OR/NOT i cudzysłowy filtrują dokładnie ten dział, który Cię interesuje.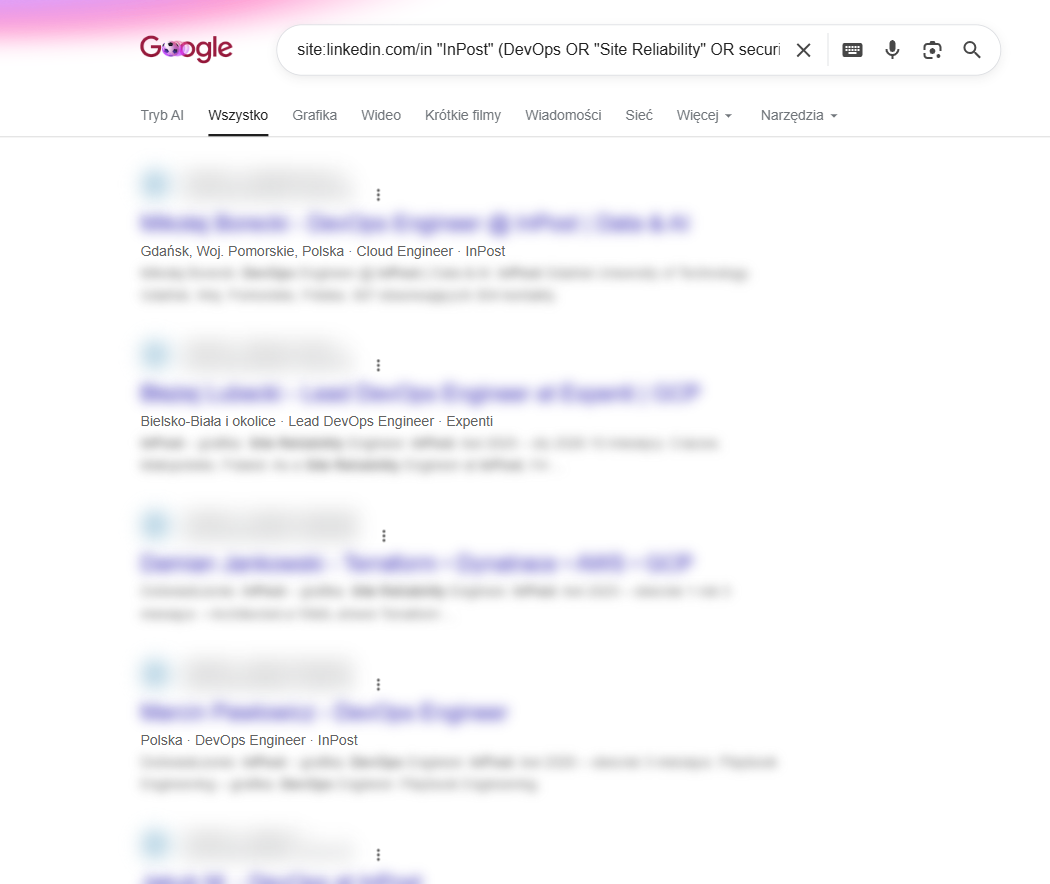
site:linkedin.com/in "InPost" (DevOps OR "Site Reliability" OR security) zwraca publiczne profile pasujące do zapytania. Nazwiska i tytuły zamaskowaliśmy, ale w snippetach widać role i lokalizacje (Cloud Engineer, DevOps Engineer, Kraków/Gdańsk) - gotowy materiał wywiadowczy bez jednego kliknięcia w profil.Najbardziej niedoceniane źródło to ogłoszenia o pracę - firma sama opisuje w nich swój stos technologiczny, żeby przyciągnąć kandydatów. Spójrzmy na realną ofertę „Data Engineer" w InPoście. W sekcji „Main Activities" czytamy wprost, na czym stoi ich platforma danych: strumieniowanie na Apache Kafka (z ekosystemem Kafka Streams i Kafka Connect), przetwarzanie rozproszone w Apache Spark (PySpark i Scala) na Databricks, magazyn typu Delta Lake oraz bazy SQL i NoSQL. Jedno ogłoszenie - i znasz architekturę danych celu, wersje narzędzi i to, czy korzysta z chmury. Ogłoszenie „DBA SQL Server - wymagana znajomość SQL Server 2016" zdradziłoby z kolei starą, prawdopodobnie niezałataną wersję. Monitoruj LinkedIn Jobs, Pracuj.pl i NoFluffJobs pod kątem ofert celu.

Mając listę nazwisk pracowników (z LinkedIn albo z Google), robisz kolejny krok: zamieniasz je na konkretne nazwy kont i sprawdzasz, gdzie te osoby są obecne w sieci. Służą do tego trzy narzędzia wiersza poleceń:
jkowalski, jan.kowalski, j.kowalski...) - gotową listę pod atak password spray.Najważniejsze: linkedin2username nie jest w repozytoriach systemu (ani w apt, ani gotowy w pip) - pobierasz go ze źródeł z GitHuba i instalujesz menedżerem uv (tym samym, co theHarvester wyżej). Wymaga też zainstalowanej przeglądarki - Chrome, Chromium albo Firefox - bo logowanie do LinkedIn odbywa się ręcznie w oknie, które narzędzie samo otworzy. Brak przeglądarki to typowy błąd Could not find a supported browser for Selenium. Z tego samego powodu narzędzie potrzebuje środowiska graficznego (pulpitu) - na serwerze bez GUI nie da się przejść ręcznego logowania.
# 1) Przeglądarka dla Selenium (bez niej: "Could not find a supported browser")
# Ubuntu/Debian - Firefox z repozytorium albo Google Chrome z paczki .deb:
sudo apt install -y firefox # lub: pobierz google-chrome-stable_*.deb i: sudo apt install ./google-chrome*.deb
# 2) linkedin2username - ze źródeł, instalacja przez uv (tak jak theHarvester)
git clone https://github.com/initstring/linkedin2username
cd linkedin2username
uv sync # tworzy venv i instaluje zależności (requests, selenium)
# 3) uruchomienie: -c = nazwa firmy z adresu URL profilu, -n = domena doklejana do loginów
# narzędzie otworzy OKNO przeglądarki - logujesz się do LinkedIn ręcznie, potem Enter w terminalu
uv run python linkedin2username.py -c "target-firma" -n target.pl
# Sherlock - po nicku znajdź konta w setkach serwisów
# (na Ubuntu instaluj w aktywnym venv jak wyżej albo przez pipx)
pip install sherlock-project
sherlock jan.kowalski
# socialscan - sprawdź dostępność username/email na wybranych platformach
pip install socialscan
socialscan --platforms github twitter jan.kowalski@target.pl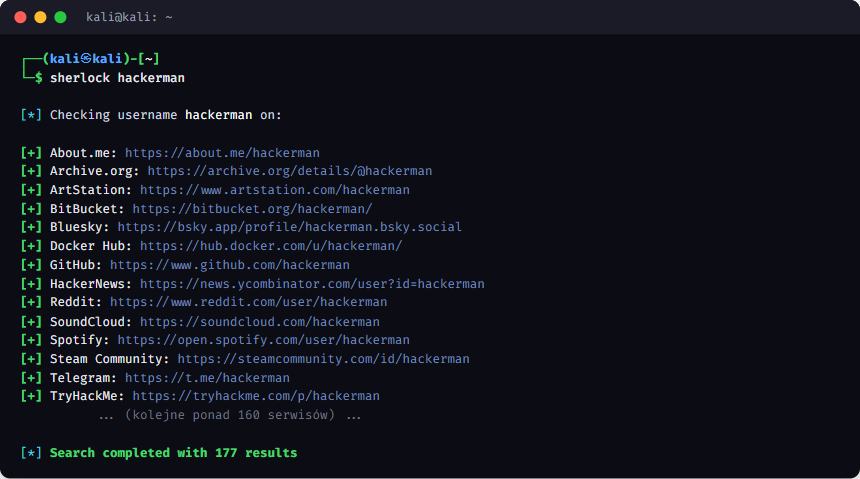
sherlock hackerman sprawdził nick w setkach serwisów i zgłosił trafienia (GitHub, Reddit, Spotify, Docker Hub, TryHackMe...) - łącznie 177 wyników. To zarazem ostrzeżenie: tak duża liczba to w sporej części fałszywe pozytywy (patrz niżej), które trzeba zweryfikować ręcznie.GitHub OSINT: Wyszukaj @target.pl na github.com. Pracownicy często pushują z firmowych emaili - ich repozytoria mogą zawierać fragmenty konfiguracji, hardcodowane klucze API, skrypty do wewnętrznej infrastruktury. Trufflehog i GitLeaks automatyzują skanowanie repozytoriów pod kątem sekretów.
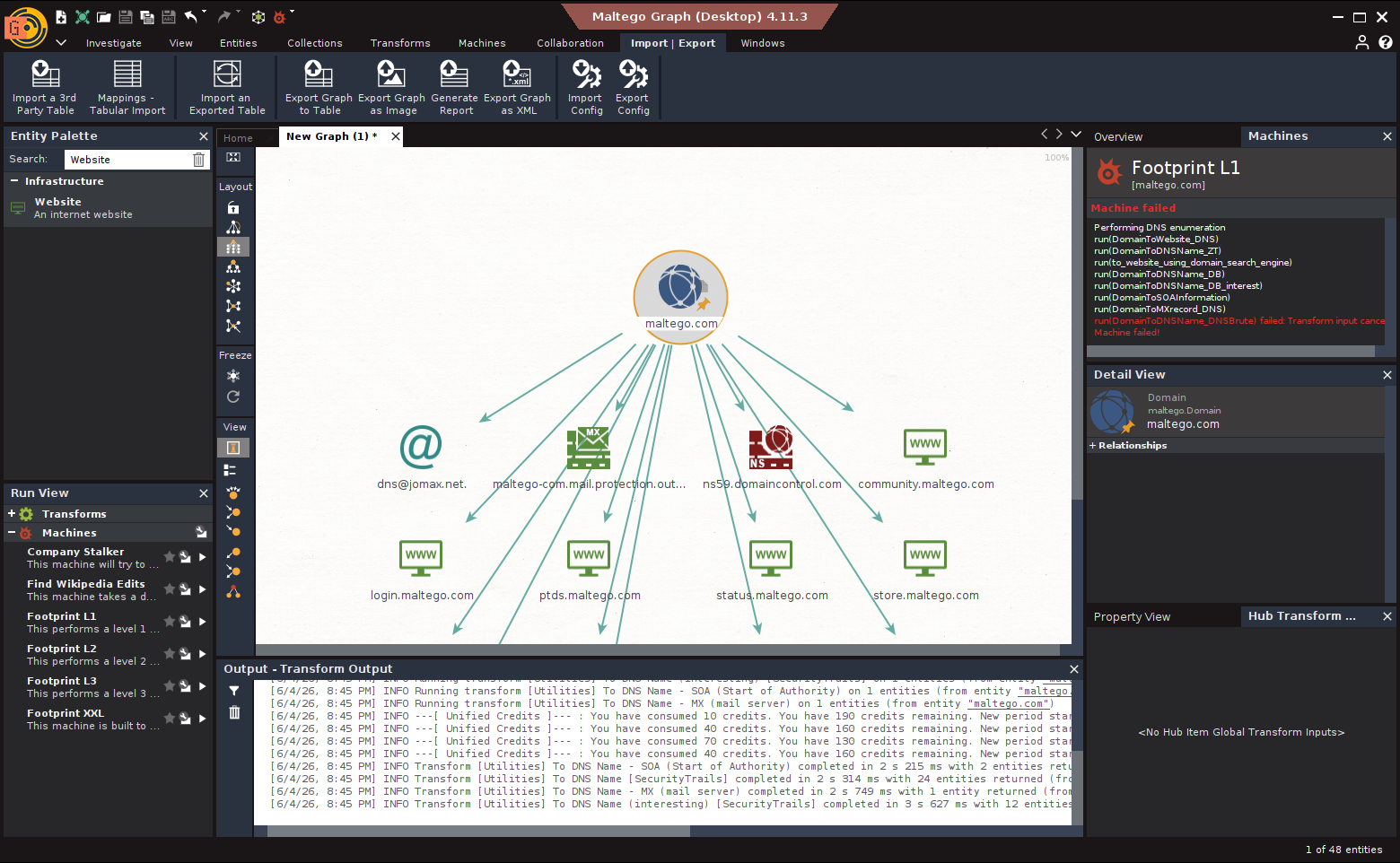
Maltego to platforma do wizualnej analizy OSINT - tworzy grafy powiązań między podmiotami (domenami, emailami, osobami, adresami IP, numerami telefonów). Zamiast ręcznie łączyć dane z kilkunastu narzędzi, uruchamiasz transforms - wtyczki, które automatycznie odpytują zewnętrzne źródła i rysują wyniki na grafie.
Maltego Community Edition (CE) jest darmowe - wymaga rejestracji, ogranicza wyniki do 12 encji na transform. Dla pentestów i nauki w zupełności wystarczy. Wersja Professional (ok. 999 USD/rok) usuwa limity i dodaje dodatkowe transform huby.
Zacznij od encji domeny (target.pl) i uruchom transforms kolejno:
W 30 minut budujesz kompletną mapę organizacji: domena --> 23 subdomeny --> 8 zakresów IP --> 47 emaili --> 12 kont GitHub --> 3 emaile w breach databases --> 2 serwery z otwartym RDP. Bez Maltego to kilka godzin ręcznej pracy.
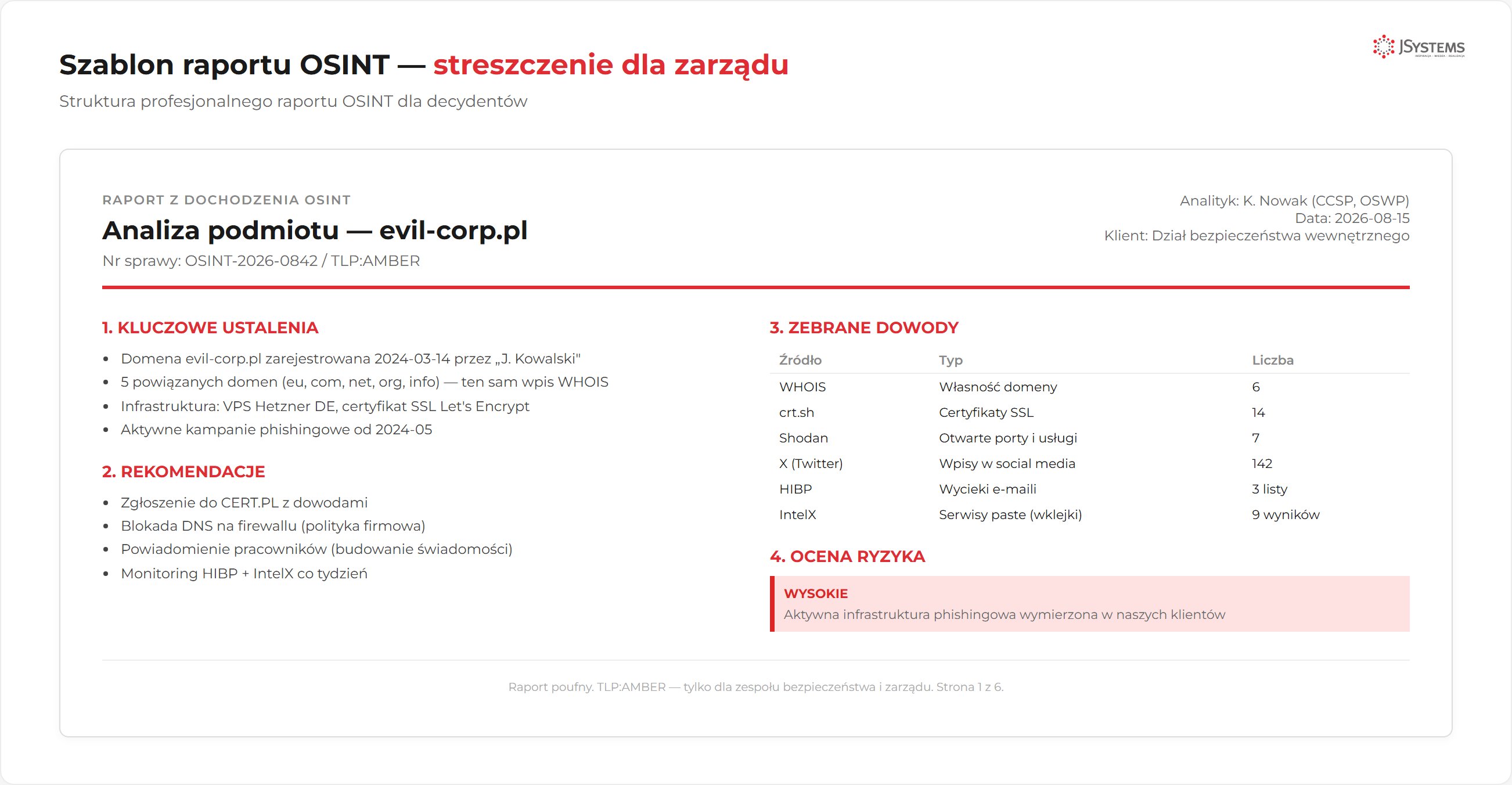
Profesjonalny raport OSINT nie jest listą "co znalazłem". Jest dokumentem biznesowym, który pomaga decydentom zrozumieć ryzyko i podjąć konkretne działania naprawcze. Każde znalezisko musi mieć ocenę ryzyka, dowód i rekomendację.
| ID | Znalezisko | Ryzyko | Źródło | Rekomendacja |
|---|---|---|---|---|
| F-001 | 3 emaile pracowników w bazie Have I Been Pwned (LinkedIn 2021 breach) | CRITICAL | HIBP API + theHarvester | Reset haseł + MFA dla tych kont |
| F-002 | Panel phpMyAdmin na dev.target.pl bez auth, port 80 | HIGH | Shodan + Google Dork | Wyłączyć lub zabezpieczyć VPN-only |
| F-003 | Login domenowy (WIN-SRV\jan.kowalski) w metadanych PDF raportu rocznego | MEDIUM | ExifTool | Czyścić metadane przed publikacją |
| F-004 | Otwarte directory listing na backup.target.pl/old/ | LOW | Google Dork | Wyłączyć directory listing w Apache |
OSINT na własną organizację to jedno z najcenniejszych ćwiczeń security review, które możesz zrobić. Jeśli Ty widzisz te dane, widzi je każdy potencjalny atakujący. Poniżej konkretne działania ochronne.
# Usuń WSZYSTKIE metadane z dokumentu przed publikacją
exiftool -all= -overwrite_original dokument.pdf
exiftool -all= -overwrite_original raport.docx
# Sprawdź co zostało
exiftool dokument.pdf | grep -iE "author|creator|producer|company|path"
# Masowe czyszczenie całego katalogu
exiftool -all= -overwrite_original -r ./do_publikacji/# Wyłącz zone transfer (AXFR) - nikt poza własnymi NS nie powinien mieć dostępu
# W BIND9 (/etc/named.conf):
zone "target.pl" {
type master;
allow-transfer { none; }; # zamiast domyślnego "any"
};
# Sprawdź czy zone transfer jest wyłączony
dig axfr target.pl @ns1.target.pl
# Oczekiwane: "Transfer failed" lub "REFUSED"
# SPF, DKIM, DMARC - utrudniają email spoofing (phishing pod Twoją domenę)
# Weryfikacja rekordu SPF:
dig TXT target.pl | grep "v=spf"
# Weryfikacja DMARC:
dig TXT _dmarc.target.plNajwiększa słabość to ludzie. Polityka bezpieczeństwa powinna jasno określać: co pracownicy mogą publikować o pracy na LinkedIn (technologie, projekty, nazwy systemów), zakaz używania firmowych emaili przy rejestracji w zewnętrznych serwisach, obowiązek zgłaszania gdy konto firmowe pojawi się w wycieku. Regularne szkolenia z rozpoznawania prób social engineeringu są konieczne - wiedza o tym, że atakujący zbiera dane z LinkedIn, zmienia świadomość pracowników.
Chcesz opanować OSINT w praktyce - od rekonesansu i Google Dorks, przez Shodan, theHarvester i Maltego, po analizę social media i raportowanie, na realnych celach (CTF)? Sprawdź nasze szkolenie z terminem gwarantowanym:

OSINT to nie jedna technika - to systematyczne podejście do zbierania informacji, które poprzedza każdy efektywny test penetracyjny i powinno być regularną praktyką w każdym zespole security. Atakujący spędzają na recon znacznie więcej czasu niż na samym ataku - znają Twoją infrastrukturę, pracowników i technologie zanim pierwszy raz dotkną granicy sieci.
Kluczowe narzędzia, które omówiliśmy:
Każdą z tych technik możesz wdrożyć defensywnie - sprawdzając co atakujący mógłby znaleźć o Twojej organizacji, zanim on to zrobi. To najprostszy i najtańszy sposób na poprawę poziomu bezpieczeństwa: sam OSINT wymaga przede wszystkim wiedzy, nie drogich narzędzi.
Newsletter bloga JSystems
Nowe artykuły pojawiają się co poniedziałek i czwartek.
Zapisz się na newsletter -->
Komentarze (0)
Brak komentarzy...