Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!

Backup za pomocą pg_dump lub pg_dumpall jest backupem logicznym, czyli zawierającym struktury danych (jak tabele czy indeksy) i dane, ale nie struktury fizyczne. Jest to zawsze zrzut do pliku SQL lub jego binarnego (często skompresowanego) formatu. Zwykłe pliki SQL - mogą następnie być konsumowane przez choćby "psql", ich binarna postać przez pg_restore. Taki backup pozwala robić kopie zapasowe wszystkich lub wybranych baz danych, a nawet wybranych tabel. Możemy też potraktować taki plik backupu jak zwykły plik tekstowy, wyciąć i odtworzyć to, co nam jest potrzebne wybiórczo. Zarówno pg_dump jak i pg_dumpall są często wykorzystywane do kopiowania danych pomiędzy serwerami. Backup za pomocą pg_dump - czy pg_dumpall pozwoli nam - na tworzenie kopii zapasowych, które można przywrócić tylko do momentu ich wykonania. Ponadto taki backup nie zawiera danych o konfiguracji klastra zawartych w plikach takich jak "postgresql.conf" czy "pg_hba.conf". Różnica pomiędzy pg_dump a pg_dumpall jest taka, że pg_dump pozwala zbackupować wybrane bazy czy elementy, a pg_dumpall zawsze backupuje wszystkie bazy. Ponadto pg_dump nie zrzuca do skryptu instrukcji tworzenia użytkowników, a pg_dumpall to robi. Kopie zapasowe wykonywane za pomocą pg_dump i pg_dumpall są konsystentne i takie pozostaną nawet w przypadku, gdyby ktoś modyfikował dane w trakcie wykonywania kopii zapasowej. Dzieje się tak, ponieważ kopia ta wykonywana jest w trybie serializable. Oznacza to, - że zmiany wykonane po rozpoczęciu wykonywania backupu nie będą w nim ujęte.
Doświadczenie z wykonywaniem kopii zapasowych zaczniemy od stworzenia sobie tabeli.
create table do_zrzutu(x integer,y text); insert into do_zrzutu(x) select generate_series(1,1000000); update do_zrzutu set y='element numer '||x;
Sprawdzamy, - czy tabela istnieje i czy zawiera dodane dane:
select count(*) from do_zrzutu;
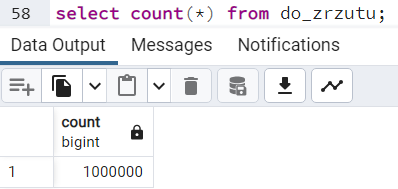
Zwróćmy uwagę na wielkość tabeli w bazie źródłowe - 91MB. Odniosę się do tego nieco później.

Aby wykonać kopię zapasową wybranej bazy za pomocą "pg_dump", wywołujemy (przełącznik -d stosujemy, by wskazać bazę, którą zamierzamy backupować - w tym przypadku postgres. Możemy ten przełącznik pominąć, ponieważ jeśli jesteśmy zalogowani jako użytkownik systemowy ";postgres", - to pg_dump będzie się domyślnie łączył jako użytkownik o takiej nazwie.):
pg_dump -d postgres > /tmp/postgres.sql
To spowoduje utworzenie pliku SQL z instrukcjami tworzącymi i zapełniającymi struktury danych. Możemy do tego pliku zajrzeć za pomocą VI czy NANO i zobaczyć mniej więcej coś takiego:
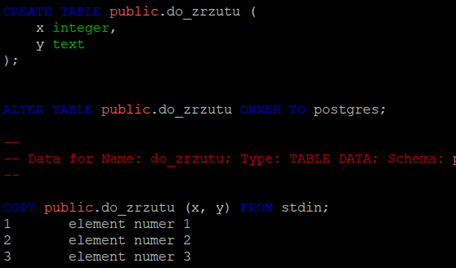
Jak widać, są to zwykłe komendy SQL. Można odtworzyć ten plik choćby za pomocą "psql". Żeby to przetestować, logujemy się do psql, tworzymy docelową bazę danych i ładujemy do niej dane z pliku zrzuconego przez pg_dump:
psql -c "create database kopia"; psql -d kopia -f /tmp/postgres.sql
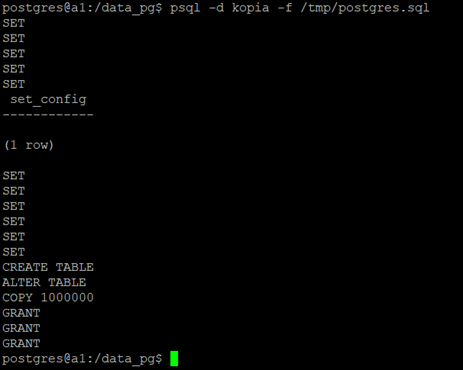
W zależności od liczby danych ten proces może trwać bardzo długo, w końcu trzeba wykonać wszystkie te komendy SQL zawarte w pliku.
Po zakończeniu ładowania łączymy się do docelowej bazy i sprawdzamy jej zawartość:
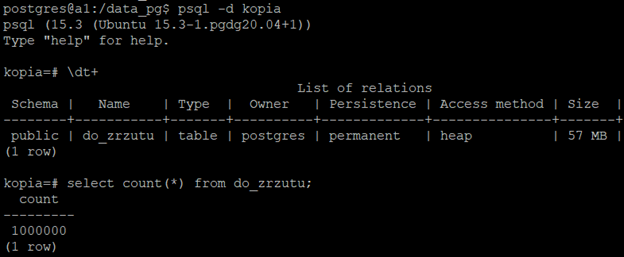
Ktoś dociekliwy mógłby zauważyć, że co prawda liczba wierszy jest taka sama w obu bazach, ale wielkość się różni. Dlaczego? Ponieważ w przypadku tej źródłowej tabeli wykonywaliśmy "update", - w związku z czym powstało wiele martwych wierszy. Druga baza miała dane ładowane od razu w docelowym stanie, więc takie martwe wiersze nie powstawały. Jak to zweryfikować? Najprościej zalogować się do bazy źródłowej, wykonać "vacuum full" na tej tabeli i porównać wielkości:
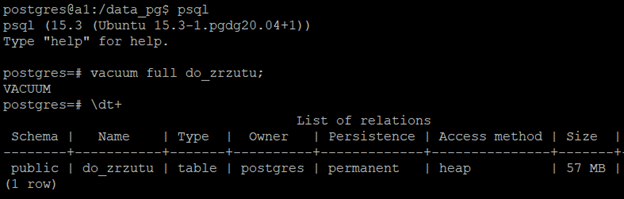
Zrzucić możemy również kilka baz na jeden - raz. Tu na potrzeby przykładu wcześniej tworzymy nową bazę:
psql -c "create database nowa" pg_dump -d postgres -d nowa > /tmp/dwie_bazy.sql
Zrzucić możemy również wybraną tabelę:
pg_dump -t do_zrzutu > /tmp/do_zrzutu.sql
Nie podajemy tutaj, do jakiej bazy się łączymy, więc domyślnie łączymy się do bazy "postgres" dlatego, że w systemie jesteśmy zalogowani jako użytkownik "postgres". Domyślnie też łączymy się do bazy o nazwie takiej jak użytkownik. Z tego wynika, że niejawnie łączymy się jako użytkownik "postgres" do bazy "postgres". Możemy tu stosować przełączniki takie jak przy psql tj. -d (baza), -h (host), -U (użytkownik) -p (port) etc. w dowolnej kolejności:
pg_dump -h localhost -d nowa -t do_zrzutu -U postgres -p 5432 > /tmp/dump.sql
Możemy też zrzucić zbiór tabel- stosujemy po prostu -t wielokrotnie. Najpierw jednak tworzymy - tabelę, by pg_dump nie rzucił błędem o braku drugiej tabeli:
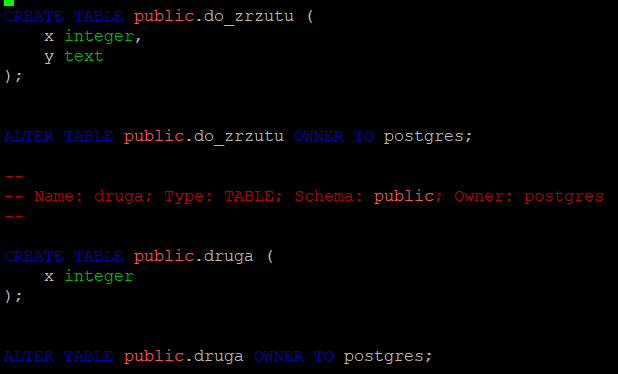
psql -c "create table druga(x integer)" pg_dump -t do_zrzutu -t druga > /tmp/obie_tabele.sql
Obie tabele znajdą się we wspólnym pliku SQL. Fragment zawartości pliku "/tmp/obie_tabele.sql":
Narzędziem pg_dumpall możemy - stworzyć kopię zapasową wszystkich baz w klastrze:
pg_dumpall > /tmp/all.sql
Ponieważ pliki tak tworzonej kopii zapasowej są w rzeczywistości plikiem tekstowym, ładnie się kompresują. Warto stosować kompresję, by nasze kopie zapasowe zajmowały mniej miejsca. Domyślnie dostaniemy kopię zapasową bez kompresji. Zrzucamy i sprawdzamy wielkość kopii zapasowej bazy postgres:
pg_dumpall > /tmp/all.sql
Ponieważ pliki tak utworzonej kopii zapasowej są w rzeczywistości plikiem tekstowym, ładnie się kompresują. Warto stosować kompresję, - by nasze kopie zapasowe zajmowały mniej miejsca. Domyślnie dostaniemy kopię zapasową bez kompresji. Zrzucamy w wersji skompresowanej i sprawdzamy wielkość kopii zapasowej bazy postgres utworzonej wcześniej bez kompresji oraz kopii zapasowej w wersji skompresowanej:
pg_dump > /tmp/postgres.tar -Fc -Z9 ls -latr --block-size=M /tmp
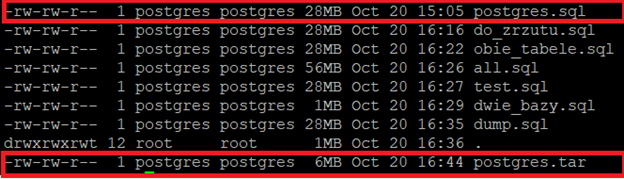
Wersja bez kompresji zajmowała 28MB, z kompresją 6MB. Możemy posłużyć się przełącznikiem "-Fc" powodującym customowy tryb formatu. Po nim musi nastąpić wskazanie poziomu kompresji za pomocą "-ZX". Dostępne są wartości od -Z0 do -Z9 o wzrastającym stopniu kompresji. - Wybraliśmy najwyższą możliwą kompresję.
Odtwarzanie pliku stworzonego w ten sposób trzeba będzie wykonać za pomocą pg_restore, ponieważ nie jest to standardowy format backupu (tu dodatkowo tworzymy - nową bazę, do której wczytamy ten backup):
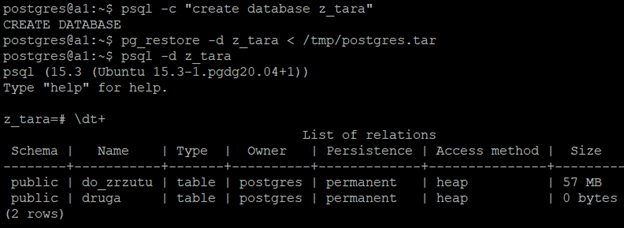
psql -c "create database z_tara" pg_restore -d z_tara < /tmp/postgres.tar
Zaglądamy do nowej bazy, obie tabele są:
pg_dumpall zwykle będziemy uruchamiali z którymś z przełączników: -g, -s, -r. Oznaczają one kolejno
Zarówno pg_dump jak i pg_dumpall pozwalają na wykonanie kopii zapasowej "po sieci" ze zdalnego serwera:
pg_dump -h 13.81.53.1 > /tmp/po_sieci.sql
Musimy jedynie pamiętać o odpowiednim wpisie w pg_hba.conf po stronie serwera docelowego i przeładowaniu konfiguracji po ewentualnej zmianie tego pliku.
W przypadku serwera zdalnego (lokalnie dostępny jest trust w pg_hba.conf) podczas wykonywania takiej kopii zapasowej zostaniemy poproszeni o hasło. Jeśli chcemy zautomatyzować tworzenie backupu np. za pomocą CRONa, pojawi się problem, ponieważ nie mamy wtedy jak wstukać hasła. Istnieje i na to metoda. Wystarczy stworzyć w katalogu domowym użytkownika postgres plik ".pgpass" i umieścić w nim niezbędne dane. - Zaczniemy od przejścia do właściwego katalogu i utworzenia pliku. Nadajemy mu też koniecznie chmod 600:
cd ~ touch .pgpass chmod 600 .pgpass nano .pgpass
We wnętrzu tego pliku musimy wprowadzić dane wg systematyki:
ip_hosta_którego_robimy_backup:port:baza_danych:użytkownik:hasło
W tym przypadku zawartość tego pliku będzie wyglądała tak:
13.81.53.1:5432:postgres:postgres:super_tajne_haslo
Przy kolejnym wywołaniu pg_dump nie zostaniemy już poproszeni o hasło.
Jeśli zamierzamy po prostu skopiować dane z jednego serwera na inny możemy posłużyć się taką konstrukcją (tu dodatkowo tworzymy bazę docelową):
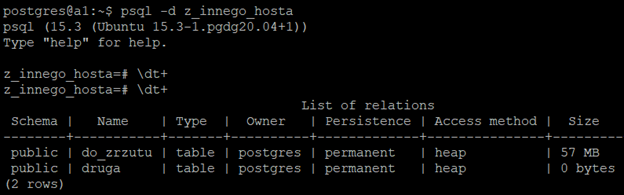
psql -c "create database z_innego_hosta" pg_dump -h 13.81.53.1 -d postgres - | psql -h 13.81.53.1 -d - z_innego_hosta
Tu został wykorzystany ten sam adres IP, ale oczywiście mogą to być różne hosty. Można osobno zrzucić bazę źródłową do pliku, a następnie osobno ją wczytać za pomocą psql. W takiej sytuacji po drodze tworzony byłby (być może bardzo duży) plik, co mogłoby znacząco wydłużyć cały proces. My za pomocą "|" przekierowujemy strumień danych do psql, zamiast kierować dane do pliku. Sprawdzam jeszcze, logując się do docelowej bazy, czy dane zostały skopiowane:


Komentarze (0)
Brak komentarzy...