
[ Do realizacji przykładów z tego rozdziału potrzebujemy hostów 1 i 5. Przygotuj je według instrukcji ]
Krótki wstęp o projekcie. Jest to oprogramowanie z otwartym źródłem napisane w całości w Pythonie. Został rozpoczęty przez 2nd Quadrant, firmę konsultingową dla PostgreSQL, jedną z wiodących na rynku, w celu zapewnienia narzędzia dla kopii zapasowych postgresa, które będzie łatwe w obsłudze i niezawodne. Po przejęciu 2nd Quadrant przez EnterpriseDB EDB przejęło również rozwój nad projektem, anulowało rozwój swojego poprzedniego narzędzia do kopii zapasowych BART, a Barman zajął jego miejsce.
Barman umożliwia stworzenie scentralizowanego serwera kopii zapasowych oraz archiwum plików WAL dla wielu klastrów PostgreSQL, również dla różnych wersji. Możliwe jest także skonfigurowanie barmana lokalnie, na serwerze z bazą danych
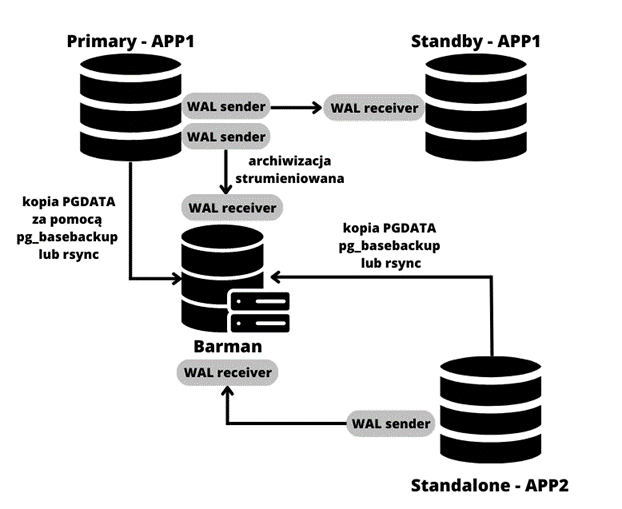
Do wyboru mamy dwie metody przeprowadzania kopii zapasowych SSH/rsync oraz backup strumieniowany za pomocą pg_basebackup.
Metoda SSH/rsync (backup_method = rsync) umożliwia wykorzystanie istniejących kopii zapasowych w celu skrócenia czasu potrzebnego na wykonanie backupu oraz pozwala na wykonywanie kopii za pomocą kilku procesów współbieżnych, co skraca czas potrzebny na wykonanie backupu.
Przed konfiguracją Barmana przygotujmy serwery, na których będziemy wykonywać przykłady zgodnie z instrukcją w rozdziale "Przygotowanie serwerów - Instalacja oprogramowania" na wybranym przez siebie systemie operacyjnym, Ubuntu 22.04 lub CentOS Stream 9. Stwórz hosty 1 i 5 z instrukcji.
Konfigurację przeprowadzimy na dwóch serwerach, z których jeden będzie pełnił rolę serwera repozytorium (host 5), na drugim zainicjalizujemy nowy klaster PostgreSQL (host 1 z instrukcji), skonfigurujemy archiwizację i backupy do repozytorium za pomocą pg_basebackup oraz strumieniowania plików WAL. Pierwszym serwerem, repozytorium Barmana, będzie serwer piąty z instrukcji do wdrożenia serwerów. Drugi serwer to host pierwszy z instrukcji, na którym będzie backupowany serwer bazy PostgreSQL.
Na serwerze repozytorium główny plik konfiguracyjny znajduje się w /etc/barman.conf
Najistotniejsze parametry to:
Przygotowanie plików konfiguracyjnych na serwerze repozytorium(zmiana dotyczy tylko minimum_redundancy, pozostałe powinny wyglądać jak poniżej domyślnie). Wykonujemy jako użytkownik z prawami do sudo.
1. Edycja głównego pliku konfiguracyjnego /etc/barman.conf:
sudo vi /etc/barman.conf
[barman]
; użytkownik systemowy który będzie właścicielem plików z kopiami
barman_user = barman
; katalog z dodatkowymi plikami konfiguracyjnymi dla poszczególnych serwerów
configuration_files_directory = /etc/barman.d
; katalog w którym będą przechowywane wszystkie kopie zapasowe
barman_home = /var/lib/barman
; lokacja w której zapisywany będzie plik logu
log_file = /var/log/barman/barman.log
; poziom logowania
log_level = INFO
; minimalna wymagana ilość kopii zapasowych
minimum_redundancy = 2
2. Stworzenie nowego pliku konfiguracyjnego o nazwie ułatwiającej nam identyfikację serwera, przykładowo /etc/barman.d/streaming-pg-5432.conf - Pamiętajmy o zmianie IP w tym configu na adres serwera, który będziemy backupować!
Poniższą sekcję z definicją serwera, który będziemy backupować na przykład [streaming-pg-5432], można również dodać na końcu /etc/barman.conf, ale dla większej czytelności oraz łatwiejszego zarządzania serwerami warto skorzystać z indywidualnych plików konfiguracyjnych dla każdego serwera. Pamiętajmy o podmianie adresu IP w poniższym configu:
sudo vi /etc/barman.d/streaming-pg-5432.conf
; alias/nazwa serwera który będzie backupowany
[streaming-pg-5432]
; definicja serwera i użytkownika który będzie sprawdzał klaster w trakcie backupa
conninfo = host=<X.X.X.X IP adres serwera Postgres> user=barman dbname=postgres
; definicja połączenia dla backupów strumieniowanych
streaming_conninfo = host=<X.X.X.X IP adres serwera Postgres> user=streaming_barman
; metoda kopii zapasowej, postgres/rsync
backup_method = postgres
; włączenie strumieniowania plików WAL
streaming_archiver = on
; nazwa fizycznego slota replikacyjnego wykorzystywanego do archiwizacji
slot_name = barman
; czy barman ma automatycznie próbować stworzyć slot jeżeli nie istnieje
create_slot = auto
; !! na serwerach z rodziny RHEL, lub jeżeli tworzymy kopie zapasowe dla różnych wersji postgresa
; dodajemy ścieżkę do plików wykonywalnych postgresa w wersji odpowiadającej serwerowi z bazą danych
path_prefix = /usr/pgsql-15/bin
Domyślny katalog na dodatkowe pliki konfiguracyjne, /etc/barman.d, posiada umask sprawiający, że wszystkie stworzone pliki mogą być przeczytane przez wszystkich, jeśli nadamy im uprawnienia 644. Właścicielem pozostaje root:root, dlatego zmieniając którykolwiek z nich, musimy mieć uprawnienia roota. Możemy to jednak zmienić w dowolnym momencie. Musimy tylko pamiętać, aby użytkownik barman mógł je odczytać.
Wstępna konfiguracja po stronie serwera PostgreSQL, który będziemy backupować:
sudo vi /data_pg/postgresql.conf
# określenie na których interfejsach sieciowych postgres powinien nasłuchiwać
# '*' nasłuchuje na wszystkich
listen_addresses = '*'
# maksymalna ilość procesów wysyłających wpisy WAL, domyślnie 10
max_wal_senders = 5
# maksymalna ilość slotów replikacyjnych, domyślnie 10
max_replication_slots = 5
# poziom logowania: minimal, replica, logical. Aby umożliwić odtwarzanie do
# wybranego punktu w czasie, musimy wybrać replica lub logical. Minimal pozwala
# tylko na przywrócenie danych do spójnego stanu po niespodziewanym zakończeniu
# procesu postgresa
wal_level = replica
# przekierowanie wyjścia dla procesu postgresa do logu, zamiast do konsoli
# na ubuntu jest domyślnie wyłączony, na centos włączony
logging_collector = on
2. Zmieniamy je w /data_pg/postgresql.conf i restartujemy postgresa z poziomu użytkownika systemowego postgres ("sudo su - postgres" uruchamiamy najpierw, by przełączyć się na użytkownika postgres) za pomocą:
# Ubuntu
postgres@pg1:~$ /usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ restart -m fast# CentOS
[postgres@pg1 ~]$ /usr/pgsql-15/bin/pg_ctl -D /data_pg/ restart -m fastJeżeli na początku ustawiliśmy zmienną środowiskową PATH w bash_profile (w tym przypadku dla użytkownika postgres (!!!) ), powinno wystarczyć samo "pg_ctl"
postgres@pg1:~$ pg_ctl -D /data_pg/ restart -m fast
3. Na serwerze PG (tym, który będzie backupowany, nie tym z barmanem), stwórzmy użytkowników barman oraz streaming_barman (na produkcyjnym środowisku ustawmy sobie inne niż "qwe123" hasło :D)
Użytkownik barman będzie wykorzystywany do sprawdzenia statusu klastra, przełączania w backup mode oraz tworzenia slotów replikacyjnych. Streaming_barman wykorzystywany będzie do wykonywania kopii zapasowej za pomocą narzędzia pg_basebackup oraz do odbierania wpisów WAL przez pg_walreceiver na serwerze z kopiami zapasowymi. Z poziomu użytkownika systemowego postgres:
postgres@pg1:~$ psql
postgres=# create user streaming_barman with replication password 'qwe123';
postgres=# create user barman with password 'qwe123';
Użytkownik wymaga uprawnień do wykonywania niektórych funkcji postgres oraz możliwości czytania ustawień i statystyk. Dlatego należy mu nadać uprawnienia superusera lub nadać wymagane uprawnienia. Dla wersji postgresa od 15 włącznie nadajemy poniższe GRANTy:
GRANT EXECUTE ON FUNCTION pg_backup_start(text, boolean) to barman;
GRANT EXECUTE ON FUNCTION pg_backup_stop(boolean) to barman;GRANT EXECUTE ON FUNCTION pg_switch_wal() to barman;
GRANT EXECUTE ON FUNCTION pg_create_restore_point(text) to barman;
GRANT pg_read_all_settings TO barman;
GRANT pg_read_all_stats TO barman;
Od wersji 15 zmieniła się nazwa funkcji rozpoczynających i kończących backup oraz przyjmowane zmienne, dlatego dla wersji wcześniejszych powinniśmy nadać uprawnienia do poniższych trzech, zamiast dwóch pierwszych, z powyższej listy. Poniższe wykonujemy tylko dla wersji DO 14 włącznie:
GRANT EXECUTE ON FUNCTION pg_switch_wal() to barman;
GRANT EXECUTE ON FUNCTION pg_create_restore_point(text) to barman;
GRANT pg_read_all_settings TO barman;
GRANT pg_read_all_stats TO barman;
4. (z poziomu użytkownika systemowego postgres) Aktualizacja /data_pg/pg_hba.conf i przeładowanie konfiguracji. W miejsce <X.X.X.X> podajemy adres swojego serwera barmana z maską /32, np. 192.168.1.101/32 lub adres podsieci z maską 192.168.1.0/24. Jest to wymagany krok, ponieważ barman regularnie łączy się z backupowanym klastrem, między innymi podczas każdego wykonania kopii zapasowej, aby przełączyć postgres w tryb backupu, w celu zagwarantowania spójności danych.
host replication streaming_barman <X.X.X.X>/32 scram-sha-256
host postgres barman <X.X.X.X>/32 scram-sha-256[postgres@pg1 ~]$ psql -c "select pg_reload_conf()"
barman@pgbckp:~$ cat <<EOF > ~barman/.pgpass
<X.X.X.X>:5432:*:barman:qwe123
<X.X.X.X>:5432:*:streaming_barman:qwe123
EOFbarman@pgbckp:~$ chmod 600 ~barman/.pgpass
barman@pgbkp:~$ psql -U streaming_barman -h <X.X.X.X> -c "IDENTIFY_SYSTEM" replication=1
barman@pgbkp:~$ psql -U barman -h <X.X.X.X> postgres -c "select now()"
barman@pgbkp:~$ cat /etc/cron.d/barman
# /etc/cron.d/barman: crontab entries for the barman package
MAILTO=root
* * * * * barman [ -x /usr/bin/barman ] && /usr/bin/barman -q cron
barman@pgbkp:~$ crontab -e
* * * * * /usr/bin/barman cron
barman@pgbkp:~$ barman check streaming-pg-5432
Pierwsze sprawdzenie statusu barmana za pomocą polecenia "barman check" na nowym klastrze może zakończyć się błędem:WAL archive: FAILED
i/lubreceive-wal running: FAILED (See the Barman log file for more details)
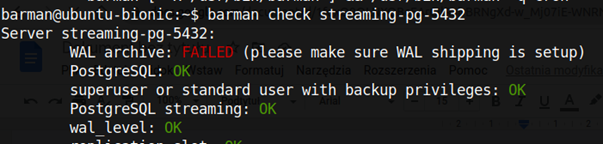
Dzieje się tak dlatego, że klaster najprawdopodobniej jest bezczynny i żadne zmiany nie są archiwizowane na serwerze repozytorium przez barmana.
Na potrzeby testu spróbujmy wymusić zmianę pliku WAL na nowy oraz jego archiwizację (w naszym przypadku nazwa serwera to streaming-pg-5432):
barman switch-wal --archive --archive-timeout 60 <nazwa_serwera>
Następnie ponownie testujemy:
barman@pgbkp:~$ barman check streaming-pg-5432
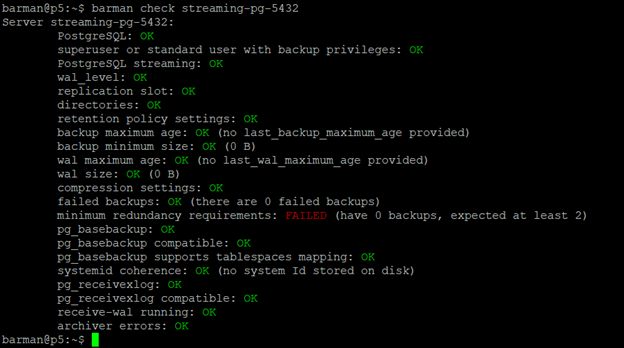
Po wymuszeniu rotacji pliku WAL ponowne sprawdzenie konfiguracji dla serwera zwraca informację, że wszystkie kontrole przeszły test pomyślnie. No może oprócz jednego "checku" - miminum redundancy requirements, który sprawdza, ile mamy kopii zapasowych i jakie są ustawienia redundancji w konfiguracji. Aktualnie barman oczekuje minumum dwóch kopii zapasowych, a nie posiada ani jednej. Ten błąd możemy spokojnie zignorować. Po wykonaniu dwóch kopii zapasowych "naprawi" się sam.
Po ustawieniu parametrów w globalnym pliku konfiguracyjnym barmana, utworzeniu definicji serwera dla naszego testowego klastra i sprawdzeniu, czy konfiguracja serwera działa poprawnie jesteśmy gotowi na wykonanie pierwszej kopii zapasowej (w naszym przypadku nazwa serwera to streaming-pg-5432):
barman backup <nazwa_serwera> --wait
Przełącznik --wait dodajemy, żeby barman zaczekał na pliki WAL potrzebne do odzyskania spójnej wersji danych. Jeżeli jej nie dodamy, backup zakończy się, nie czekając na wszystkie wymagane pliki WAL, ale oczekując ich archiwizacji w przyszłości. Jeżeli pliki te nie zostaną z jakiegokolwiek powodu zarchiwizowane, Barman nie będzie w stanie odtworzyć klastra z takiej kopii zapasowej.
Należy pamiętać, że Barman, wykonując kopie zapasowe w trybie strumieniowania, zawsze wykonuje pełną kopię. Wynika to z tego, że backup strumieniowy to tak naprawdę pg_basebackup, który nie ma możliwości wykonywania kopii różnicowych ani wykorzystywania innych backupów jako źródło do kopiowania.
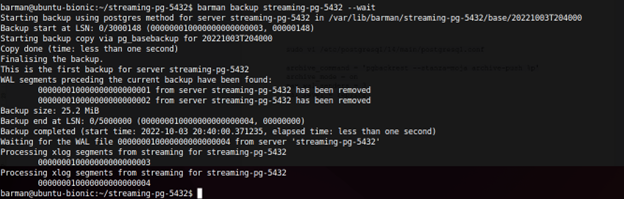
Po wykonaniu pierwszego backupu możemy zaplanować codzienne wykonywanie kopii zapasowych w crontabie (w naszym przypadku nazwa serwera to streaming-pg-5432):
# otwieramy crontab poleceniem
crontab -e# dodajemy do niego poniższy wiersz
0 22 * * * /usr/bin/barman backup <nazwa_serwera> --wait
Wylistować wszystkie kopie zapasowe dla danego serwera możemy za pomocą polecenia:
barman list-backup <nazwa_serwera>
np:
barman list-backup streaming-pg-5432

Wiemy już, jak wykonać nową kopię zapasową, wylistować dostępne backupy. Następnym krokiem będzie usunięcie starych, niepotrzebnych już kopii zapasowych. W tym celu możemy skorzystać z jednego z poleceń:
barman delete <nazwa_serwera> <nazwa_backupu> # usunięcie konkretnego backupu
barman delete <nazwa_serwera> oldest # usunięcie najstarszego backupu
Opcja oldest usunie najstarszy już niepotrzebny backup według ustawień minimum_redundancy w /etc/barman.conf, nie sprawdzając, czy kopia była wykonana poprawnie czy też nie.
Jeżeli spróbujemy usunąć najstarszą kopię, otrzymamy ostrzeżenie o niedostatecznej liczbie kopii zapasowych:
barman delete streaming-pg-5432 oldest

Dzieje się tak dlatego, że w pliku /etc/barman.conf ustawiliśmy parametr "minimum_redundancy = 2" i dlatego barman chce mieć zawsze dostępne minimum dwie kopie zapasowe w repozytorium dla każdego klastra.
Stwórzmy teraz kilka kolejnych kopii i spróbujmy usunąć najstarszą (w naszym przypadku nazwa serwera to streaming-pg-5432):
barman backup <nazwa_serwera> --wait
barman backup <nazwa_serwera> --wait
barman list-backup <nazwa_serwera>
barman delete <nazwa_serwera> oldest
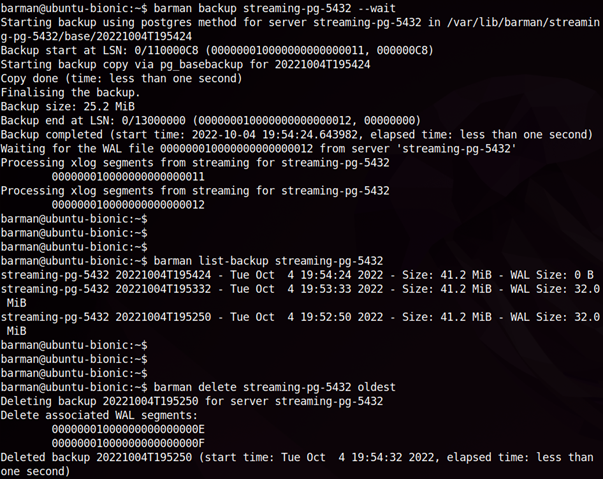
W wyniku polecenia "delete oldest" barman usunął kopię zapasową razem ze wszystkimi powiązanymi z nią plikami WAL z archiwum, które nie są wymagane przez żadną z pozostałych kopii.
Spróbujmy wymusić teraz na barmanie gwarancję przechowywania kopii zapasowych przez określony czas. Dodajmy do konfiguracji (jako użytkownik systemowy z uprawnieniami do sudo) /etc/barman.conf parametr retention_policy. Parametr ten przyjmuje wartości:
retention_policy = {REDUNDANCY wartość | RECOVERY WINDOW OF wartość {DAYS | WEEKS | MONTHS}}Na potrzeby przykładu wykorzystajmy opcję z REDUNDANCY, ponieważ będzie łatwiej to zobrazować na przykładach. Opcja REDUNDANCY w parametrze retention_policy określa, ile poprawnie wykonanych kopii zapasowych jest zawsze wymagane. Druga możliwość "RECOVERY WINDOW OF ...;" określa czas, przez jaki kopie zapasowe powinny być przechowywane. W pliku /etc/barman.conf ustawiamy wartość parametru retention_policy na "REDUNDANCY 3". Pamiętajmy o wykonaniu tego z sudo, np. "sudo nano /etc/barman.conf" (oczywiście użytkownik systemowy, z którego operujemy, musi mieć prawa do sudo, więc nie może to być barman ani postgres):
retention_policy = REDUNDANCY 3
Wykonajmy teraz nowe kopie zapasowe (znowu jako użytkownik barman) tak, aby w sumie mieć 3 kopie. Spróbujmy wykonać jeszcze raz polecenie "delete oldest" (w naszym przypadku nazwa serwera to streaming-pg-5432):
barman backup <nazwa_serwera> --wait
barman backup <nazwa_serwera> --wait
barman delete <nazwa_serwera> oldest
Dlaczego udało się nam usunąć trzecią kopię i zostały nam tylko dwie, mimo że retention_policy ustawiliśmy na "REDUNDANCY 3"?
Polecenie "delete oldest" nie sprawdza ustawień polityk, jedyny parametr, który jest dla niego ważny do minimum_redundancy.
W jaki sposób zatem działa parametr "retention_policy"?
Wykonajmy dwa kolejne backupy i spróbujmy wylistować wszystkie nasze kopie.
barman backup <nazwa_serwera> --wait
barman list-backup <nazwa_serwera>
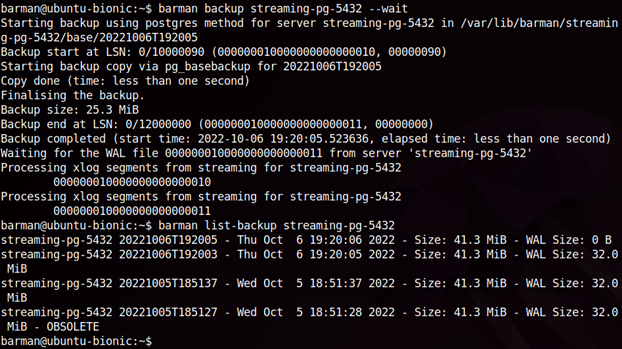
Czwarta, najstarsza, kopia została oznaczona jako "OBSOLETE". Stało się tak dzięki ustawieniu parametru retention_policy na "REDUNDANCY 3". W ten sposób możemy zarządzać, które backupy są dla nas istotne, a które możemy już usunąć.
Aby usunąć niepotrzebne backupy (czyli te OBSOLETE), wystarczy teraz wykonać polecenie:
barman cron
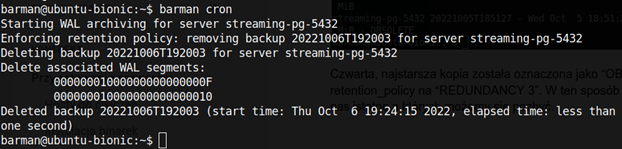
Barman nie posiada żadnej usługi działającej w tle. Zamiast tego mamy polecenie "barman cron", które odpowiada za dopilnowanie, czy posiadamy odpowiednią liczbę kopii zapasowych wg retention_policy, za archiwizację plików WAL i ich kompresję, jeżeli dodaliśmy ją do konfiguracji.
Zaleca się, aby polecenie "barman cron" dodać do crontaba użytkownika barman i wykonywać je co minutę. Żeby mieć pewność, że wszystkie zmiany z plików WAL zostały zarchiwizowane i skompresowane, a kopie, których już nie potrzebujemy, zostały usunięte.
# otwarcie crontaba w edytorze tekstu, u użytkownika Barman
crontab -e
# dodajemy poniższą linię i zapisujemy
* * * * * /usr/bin/barman cron
Barman w nowszych wersjach powinien automatycznie dodać swój plik crona do /etc/cron.d po instalacji pakietu. Zarówno na Ubuntu jak i CentOS.
barman@ubuntu:/etc/cron.d$ cat /etc/cron.d/barman
# /etc/cron.d/barman: crontab entries for the barman package
MAILTO=root
* * * * * barman [ -x /usr/bin/barman ] && /usr/bin/barman -q cron
Barman umożliwia nam w bardzo łatwy sposób odtworzyć bazę do dowolnego miejsca w czasie (--target-time), do dowolnej transakcji (--target-xid), do wybranej sekwencji w logu (--target-lsn), do wcześniej utworzonego restore pointa (--target-name) lub po prostu do pierwszego momentu, w którym baza będzie posiadała spójne dane (--target-immediate).
Dane możemy odzyskiwać lokalnie lub na zdalny serwer, możemy automatycznie dodać konfigurację serwera standby czy przemapować przestrzenie tabel, aby odzyskać je do innych katalogów.
Przetestujmy teraz, jak działa odzyskiwanie. Stwórzmy tabelę "test" i dodajmy do niej dwie wartości, poprzez skopiowanie poniższych 6 linii do terminala psql (jako użytkownik systemowy postgres):
#psql
create table restore_test (a int, b varchar);
insert into restore_test values (1, 'wartość przed wystąpieniem problemu');
select now();
#CZEKAMY CHWILKĘ...
select pg_sleep(30);
insert into restore_test values (1, 'wartość po wystąpieniu problemu');
select now();
postgres=# create table restore_test (a int, b varchar);
insert into restore_test values (1, 'wartość przed wystąpieniem problemu');
select now();
select pg_sleep(30);
insert into restore_test values (1, 'wartość po wystąpieniu problemu');
select now();
CREATE TABLE
INSERT 0 1
now
-------------------------------
2022-10-06 19:51:23.162501+00:00
(1 row)
INSERT 0 1
now
-------------------------------
2022-10-06 19:51:23.324806+00
(1 row)
postgres=#
Barman jest skonfigurowany w trybie archiwizacji ciągłej poprzez strumieniowanie wszystkich zmian na serwer repozytorium, do archiwum plików WAL. Dlatego wszystkie zmiany powinny być automatycznie archiwizowane i dostępne w razie potrzeby ich odzyskania.
Wykonajmy teraz restore z ostatniej kopii, którą zrobiliśmy wcześniej, do czasu zwróconego przez pierwsze "now()", pomiędzy insertami. Ale zanim przejdziemy do odzyskiwania, musimy skonfigurować połączenie SSH bez hasła. W tym celu należy wygenerować klucze RSA na serwerze postgresa jako użytkownik postgres i serwerze barmana jako użytkownik barman.
Na obu hostach wykonujemy (na serwerze PostgreSQL jako użytkownik systemowy postgres, na serwerze repozytorium backupów jako użytkownik systemowy barman):
ssh-keygen -t rsa
Hasła pozostawmy puste, aby umożliwić połączenie SSH bez potrzeby podawania żadnych haseł. Trzykrotnie klikamy enter.
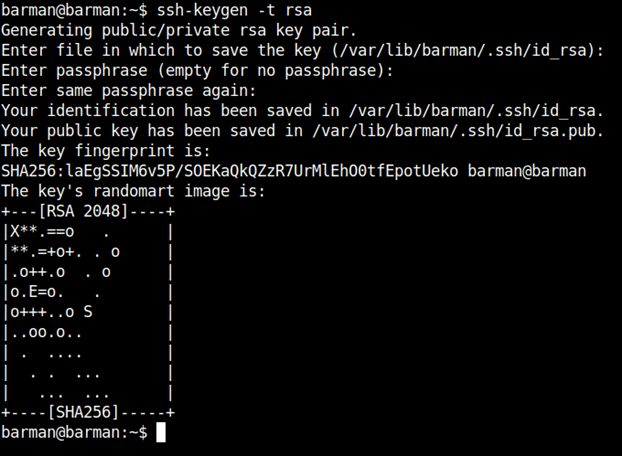
Po wygenerowaniu kluczy kopiujemy zawartość ~/.ssh/id_rsa.pub z serwera postgresa na serwer barmana do pliku ~/.ssh/authorized_keys użytkownika barman, i odwrotnie, z użytkownika barman na serwerze barman, na serwer postgresa dla użytkownika postgres.
Sprawdźmy teraz, czy ssh działa poprawnie, logując się z użytkownika postgres na serwerze postgresa na serwer barmana jako użytkownik barman i odwrotnie.
# z serwera barman na db serwer
ssh postgres@<IP serwera PostgreSQL>
# z db serwera na serwer kopii zapasowych
ssh barman@<IP repozytorium backupów>
Test połączenia ssh jest też wymagany w celu dodania serwera do pliku known_hosts. Samo dodanie nastąpi automatycznie podczas nawiązywania połączenia SSH. Warto tu pamiętać, że wpis jest dodawany z nazwą/adresem, które podaliśmy podczas połączenia, czyli w powyższych przypadkach adresy IP. Barman będzie działał tylko z adresem lub nazwą hosta, która jest dodana w known_hosts.
Możemy teraz spróbować odzyskać bazę do stanu przed wystąpieniem problemu.
barman recover <nazwa_serwera-alias_barman> <IDENTYFIKATOR BACKUPU> /data_pg/test_restore --remote-ssh-command "ssh postgres@<IP docelowego dbserwera>" --target-time "2022-10-06 19:51:23.162501+00:00" --get-wal
barman recover streaming-pg-5432 20221006T192005 /data_pg/test_restore --remote-ssh-command "ssh postgres@192.168.56.13" --target-time "2022-10-06 19:51:23.162501+00:00" --get-wal
Parametry, które wykorzystamy przy odtwarzaniu, to nazwa klastra podana w konfiguracji barmana, ID kopii, którą wykorzystamy do odzyskania danych, docelowy katalog na nową PGDATA, --remote-ssh-command, w którym podajemy, na jakim serwerze i jako który użytkownik powinniśmy odzyskać dane, --target-time punkt w czasie, do którego chcemy odtworzyć klaster oraz --get-wal, aby postgres przy odtwarzaniu korzystał z polecenia barman-get-wal, które umożliwia czytanie niekompletnych plików wal (.partial) z archiwum (zapewnienie jak najlepszego RPO).
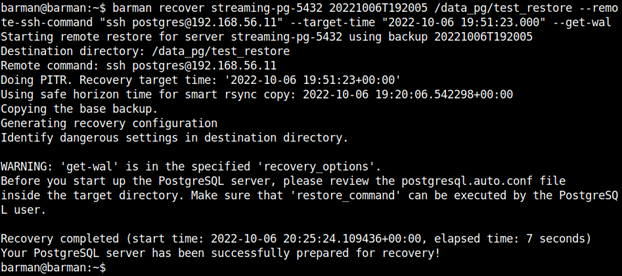
Odzyskiwanie przebiegło pomyślnie. Zostaliśmy jednak ostrzeżeni, żeby przed uruchomieniem serwera sprawdzić, czy parametr "restore_command" jest poprawny w pliku "postgresql.auto.conf" w katalogu /data_pg/test_restore - czyli tam, gdzie odzyskaliśmy klaster, a nie bezpośrednio w /data_pg - aktualnie działający klaster (wykonujemy jako użytkownik systemowy postgres).

W tym przypadku wystarczy zmienić nazwę hosta na adres IP repozytorium backupów - Barmana (ten drugi "barman" po -U) lub dodać hosta barmana do /etc/hosts. Pamiętajmy o odpowiednim wpisie do .ssh/known_hosts. Powinien być dodany dla adresu IP lub nazwy hosta, w zależności czego użyjemy w restore_command. Po poprawieniu polecenia możemy wystartować świeżo odzyskany klaster.
Przykładowo po poprawieniu zawartość pliku może wyglądać tak:
vi /data_pg/test_restore/postgresql.auto.conf
restore_command = 'barman-wal-restore -P -U barman 192.168.56.15 streaming-pg-5432 %f %p'
Parametry, które zostały automatycznie dodane do barman-wal-restore, to -P -aby barman odzyskał również częściowe pliki WAL z archiwum, -U -definicja użytkownika, pod którym są skonfigurowane kopie zapasowe na serwerze z backupami, domyślnie barman, kolejny to nazwa serwera kopii zapasowych oraz nazwa/alias konfiguracji serwera. Ostatnie dwa parametry są uzupełniane automatycznie przez postgresa, %f to nazwa pliku WAL do odtworzenia, %p katalog docelowy dla odtworzonego pliku WAL. Struktura tego wpisu wygląda tak:
barman-wal-restore -P -U <barman użytkownik linuxowy> <nazwa hosta z kopiami zapasowymi> <nazwa/alias w konfiguracji barmana>
Najpierw powinniśmy zatrzymać stary klaster, dlatego że działa na tym samym porcie, na którym chcemy wystartować "nowy". Możemy też zmienić port dla odtworzonego klastra w pliku konfiguracyjnym /data_pg/test_restore/postgresql.conf:
/usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ stop
Następnie możemy wystartować klaster odzyskany z kopii zapasowej:
/usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/test_restore/ start
Pierwsze linie w logu postgresa to błędy o brakującym pliku ".history". Możemy je ignorować, to typowe zachowanie postgresa, podczas wykonywania recovery, sprawdza, czy istnieją w archiwum pliki z wyższej linii czasu. Jeżeli nie, po prostu kontynuuje odtwarzanie zmian.
Następnie widzimy informację o rozpoczęciu odzyskiwania danych do punktu w czasie, zadanego w poleceniu "barman recover", listę plików WAL, które zostały odtworzone, oraz informację o zakończonym odtwarzaniu, również że klaster oczekuje wykonania funkcji "pg_wal_replay_resume()".
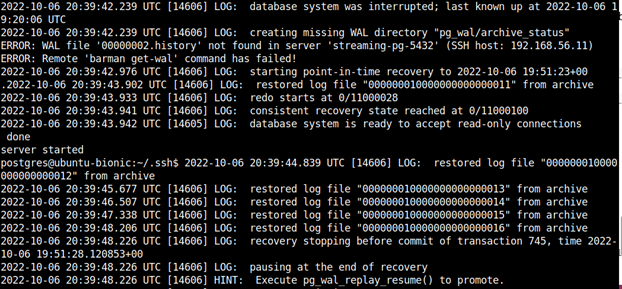
Postgres jest aktualnie dostępny w trybie tylko do odczytu. Aby otworzyć instancję, umożliwiając zapisywanie danych, musimy wykonać funkcję, o którą postgres prosił w logu. Dopóki jej nie wykonamy, możemy wrócić do postgresql.auto.conf i zmienić czas, do którego chcemy odzyskać dane, ale zmienić możemy go tylko do przodu. Po każdej takiej zmianie musimy zrestartować postgresa. W ten sposób możemy powoli odtwarzać kolejne transakcje/sekundy, a kiedy już jesteśmy gotowi i odzyskaliśmy wszystkie potrzebne dane, możemy wykonać funkcję "select pg_wal_replay_resume();".
Zalogujmy się do postgresa przez psql i sprawdźmy, czy odzyskaliśmy dane "przed wystąpieniem problemu". Jeżeli tak, wykonajmy funkcję, o którą poprosił.
postgres@ubuntu:~$ psql -p 5433
psql (15.3)
Type "help" for help.postgres=# select * from restore_test ;
a | b
---+-------------------------------------
1 | wartość przed wystąpieniem problemu
(1 row)
postgres=# select pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)
W logu natychmiast możemy zobaczyć informację o tym, że postgres zakończył odzyskiwanie danych i jest gotowy do otrzymywania połączeń. T
2022-10-06 20:40:52.795 UTC [14606] LOG: selected new timeline ID: 2
2022-10-06 20:40:52.841 UTC [14606] LOG: archive recovery complete
2022-10-06 20:40:53.793 UTC [14605] LOG: database system is ready to accept connectionsAby odtworzyć backup i wszystkie dostępne pliki WAL z archiwum, wykonujemy bardzo podobne kroki jak w przypadku odtwarzania do wybranego punktu w czasie. Pomijamy jednak parametr wskazujący czas, do którego chcemy wykonać odtwarzanie zmian (wykonujemy to z poziomu użytkownika systemowego barman).
barman recover <nazwa_serwera-alias_barman> 20221006T192005 /data_pg/test_restore --remote-ssh-command "ssh postgres@<IP docelowego dbserwera>" --get-wal
Modyfikujemy postgresql.auto.conf, aby zawierał odpowiedni restore_command (podając oczywiście właściwy IP i nazwę hosta):
vi /data_pg/test_restore/postgresql.auto.conf
restore_command = 'barman-wal-restore -P -U barman <adres backup serwer> <nazwa/alias serwera> %f %p'restore_command = 'barman-wal-restore -P -U barman 192.168.56.15 streaming-pg-5432 %f %p'
Ponownie używamy polecenia barman-wal-restore z parametrem -P, aby korzystał z niepełnych plików WAL przy odtwarzaniu.
Po czym uruchamiamy klaster.
/usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/test_restore/ start
W logu zobaczymy podobne do poniższych wpisy.
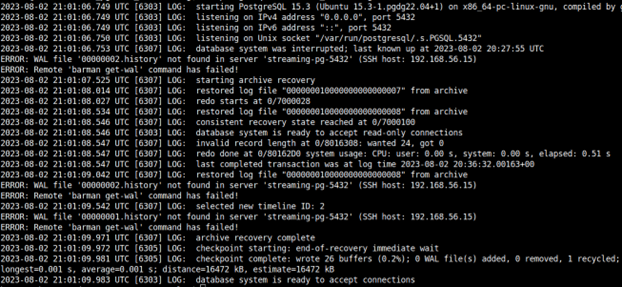
Następnie widzimy, że rozpoczął recovery z archiwum, pobrał i odtworzył dwa pliki WAL. Po osiągnięciu spójnego stanu danych otworzył bazę tylko do odczytu, po czym kontynuował odtwarzanie zmian. Kiedy wszystkie dostępne pliki WAL zostały już odtworzone, podniósł linię czasu do 2, wykonał checkpoint na koniec procesu recovery oraz otworzył bazę do zapisu.
Wstępna konfiguracja jest bardzo podobna do tej dla backupów strumieniowych.
Przygotowanie plików konfiguracyjnych na serwerze repozytorium (pliki edytujemy jako użytkownik z uprawnieniami roota):
sudo vi /etc/barman.conf
[barman]
; użytkownik systemowy który będzie właścicielem plików z kopiami
barman_user = barman
; katalog z dodatkowymi plikami konfiguracyjnymi dla poszczególnych serwerów
configuration_files_directory = /etc/barman.d
; katalog w którym będą przechowywane wszystkie kopie zapasowe
barman_home = /var/lib/barman
; lokacja w której zapisywany będzie plik logu
log_file = /var/log/barman/barman.log
; poziom logowania
log_level = INFO
; minimalna wymagana ilość kopii zapasowych
minimum_redundancy = 2
; polityki retencji dla kopii zapasowych
retention_policy = RECOVERY WINDOW OF 2 WEEKS
vi /etc/barman.d/rsync-pg-5432.conf
; alias/nazwa serwera który będzie backupowany
[rsync-pg-5432]
; definicja serwera i użytkownika który będzie sprawdzał klaster w trakcie backupa
conninfo = host=<X.X.X.X IP adres serwera Postgres> user=barman dbname=postgres
; polecenie ssh wykorzystywane do wywoływania rsync i kopiowania plików danych
; barman bardzo nie lubi dostawać jakichkolwiek odpowiedzi po nawiązaniu połączenia
; dlatego warto dodać tutaj -q, quiet, aby zminimalizować ryzyko błędów podczas
; wywoływania kopii zapasowych
ssh_command = ssh -q postgres@<X.X.X.X IP adres serwera Postgres>
; definicja połączenia dla backupów strumieniowanych
streaming_conninfo = host=<X.X.X.X IP adres serwera Postgres> user=streaming_barman
; metoda kopii zapasowej, postgres/rsync
backup_method = rsync
; włączenie strumieniowania plików WAL
streaming_archiver = on
; nazwa fizycznego slota replikacyjnego wykorzystywanego do archiwizacji
slot_name = barman
; czy barman ma automatycznie próbować stworzyć slot jeżeli nie istnieje
create_slot = auto
; na serwerach z rodziny RHEL, lub jeżeli tworzymy kopie zapasowe dla różnych wersji postgresa
; dodajemy ścieżkę do plików wykonywalnych postgresa w wersji odpowiadającej serwerowi z bazą danych
path_prefix = /usr/pgsql-15/bin
Wstępna konfiguracja po stronie serwera PostgreSQL
vi /data_pg/postgresql.conf
# określenie na których interfejsach sieciowych postgres powinien nasłuchiwać
# '*' nasłuchuje na wszystkich, możemy też wskazać wybrany adres IP, lub listę adresów
# po przecinku
listen_addresses = '*'
# maksymalna ilość procesów wysyłających wpisy WAL, walsender, domyślnie 10
max_wal_senders = 5
# maksymalna ilość slotów replikacyjnych, domyślnie 10
max_replication_slots = 5
# poziom logowania: minimal, replica, logical. Aby umożliwić odtwarzanie do
# wybranego punktu w czasie, musimy wybrać replica lub logical. Minimal pozwala
# tylko na przywrócenie danych do spójnego stanu po niespodziewanym zakończeniu
# procesu postgresa
wal_level = replica
# przekierowanie wyjścia dla procesu postgresa do logu, zamiast do konsoli
# na ubuntu jest domyślnie wyłączony, na centos włączony
logging_collector = on
/usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ restart
postgres@pg1:~$ psql
postgres=# create user streaming_barman with replication password 'qwe123';
postgres=# create user barman with password 'qwe123';
GRANT EXECUTE ON FUNCTION pg_backup_start(text, boolean) to barman;
GRANT EXECUTE ON FUNCTION pg_backup_stop(boolean) to barman;
GRANT EXECUTE ON FUNCTION pg_switch_wal() to barman;
GRANT EXECUTE ON FUNCTION pg_create_restore_point(text) to barman;
GRANT pg_read_all_settings TO barman;
GRANT pg_read_all_stats TO barman;
GRANT EXECUTE ON FUNCTION pg_start_backup(text, boolean, boolean) to barman;
GRANT EXECUTE ON FUNCTION pg_stop_backup() to barman;
GRANT EXECUTE ON FUNCTION pg_stop_backup(boolean, boolean) to barman;
vi /data_pg/pg_hba.conf
host replication streaming_barman <X.X.X.X>/32 scram-sha-256
host postgres barman <X.X.X.X>/32 scram-sha-256postgres@pg1:~$ psql -c "select pg_reload_conf()"
Wstępna konfiguracja po stronie serwera kopii zapasowych
cat <<EOF > ~barman/.pgpass
<X.X.X.X>:5432:*:barman:qwe123
<X.X.X.X> :5432:*:streaming_barman:qwe123
EOFchmod 600 ~barman/.pgpass
<X.X.X.X>):barman@pgbkp:~$ psql -U streaming_barman -h <X.X.X.X> -c "IDENTIFY_SYSTEM" replication=1
systemid | timeline | xlogpos | dbname
---------------------+----------+-----------+--------
7257255100077767480 | 1 | 0/154BB90 |
(1 row)barman@pgbkp:~$ psql -U barman -h <X.X.X.X> postgres -c "select now()"
now
-------------------------------
2023-08-02 20:23:02.184783+00
(1 row)
vagrant@ubuntu:~$ cat /etc/cron.d/barman
# /etc/cron.d/barman: crontab entries for the barman package
MAILTO=root
* * * * * barman [ -x /usr/bin/barman ] && /usr/bin/barman -q cron
crontab -e
* * * * * /usr/bin/barman cron
barman@pgbackup:~$ ssh-keygen -t rsa
postgres@pg1:~$ ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub
vi ~/.ssh/authorized_keys
barman@pgbackup:~$ ssh postgres@pg1
postgres@pg1:~$ ssh barman@pgbackup
barman@ubuntu:~$ barman switch-wal --archive --archive-timeout 60 rsync-pg-5432
barman@ubuntu:~$ barman check rsync-pg-5432
barman backup rsync-pg-5432 --wait
WARNING: No backup strategy set for server 'rsync-pg-5432' (using default 'concurrent_backup').
Starting backup using rsync-concurrent method for server rsync-pg-5432 in /var/lib/barman/rsync-pg-5432/base/20230623T204712
Backup start at LSN: 0/3000028 (000000010000000000000003, 00000028)
This is the first backup for server rsync-pg-5432
WAL segments preceding the current backup have been found:
000000010000000000000001 from server rsync-pg-5432 has been removed
Starting backup copy via rsync/SSH for 20230623T204712
Copy done (time: 1 second)
This is the first backup for server rsync-pg-5432
Asking PostgreSQL server to finalize the backup.
Backup size: 25.2 MiB
Backup end at LSN: 0/3000100 (000000010000000000000003, 00000100)
Backup completed (start time: 2023-06-23 20:47:12.491670, elapsed time: 2 seconds)
Waiting for the WAL file 000000010000000000000003 from server 'rsync-pg-5432'
Processing xlog segments from streaming for rsync-pg-5432
000000010000000000000002
000000010000000000000003
barman backup rsync-pg-5432 --wait --reuse-backup=link
WARNING: No backup strategy set for server 'rsync-pg-5432' (using default 'concurrent_backup').
Starting backup using rsync-concurrent method for server rsync-pg-5432 in /var/lib/barman/rsync-pg-5432/base/20230706T220533
Backup start at LSN: 0/A000028 (00000001000000000000000A, 00000028)
Starting backup copy via rsync/SSH for 20230706T220533
Copy done (time: less than one second)
Asking PostgreSQL server to finalize the backup.
Backup size: 76.4 MiB. Actual size on disk: 8.8 KiB (-99.99% deduplication ratio).
Backup end at LSN: 0/A000138 (00000001000000000000000A, 00000138)
Backup completed (start time: 2023-07-06 22:05:33.718684, elapsed time: 1 second)
Waiting for the WAL file 00000001000000000000000A from server 'rsync-pg-5432'
Processing xlog segments from streaming for rsync-pg-5432
000000010000000000000009
00000001000000000000000A
Backup size: 76.4 MiB. Actual size on disk: 8.8 KiB (-99.99% deduplication ratio).


Komentarze (0)
Brak komentarzy...