
Bazy danych są strukturą logiczną, choć wiążą się ze strukturą fizyczną. Każda baza danych ma swój osobny katalog na serwerze. Dane pomiędzy poszczególnymi bazami danych są od siebie odseparowane fizycznie i logicznie. Niestety nie są na tyle niezależne jak np. w Oracle czy SQL Server, by można było osobno robić kopie zapasowe i osobno przywracać bazy danych. Co prawda można wykonać eksport danych do pliku tekstowego za pomocą pg_dump, ale nie jest to kopia zapasowa w pełnym tego słowa znaczeniu i nie pozwala np. przywrócić bazy do wybranego punktu w czasie. W przypadku eksportu danych- możliwość późniejszego odtworzenia bazy ogranicza się do punktu w czasie, z którego pochodzi eksport. Należy mieć to na uwadze przy projektowaniu struktur bazodanowych. Jeśli potrzebujemy kilku baz dla kilku niezależnych od siebie systemów, to lepiej zamiast osobnych baz stworzyć osobne klastry. Dzięki temu będziemy mogli włączać i wyłączać poszczególne systemy niezależnie, osobno backupować i w razie potrzeby odtwarzać.
Wszystkie bazy danych współdzielą obszar pamięci dostępny dla całego klastra PostgreSQL, a zdefiniowany przez parametr "shared_buffers". To jest kolejny powód do separacji danych w osobnych klastrach. Jeśli w jednym klastrze będą dane kilku systemów, to każdy z nich będzie opóźniał działanie pozostałych.
Jakie bazy danych mamy w klastrze, możemy sprawdzić, wykonując:
select oid,datname from pg_database;
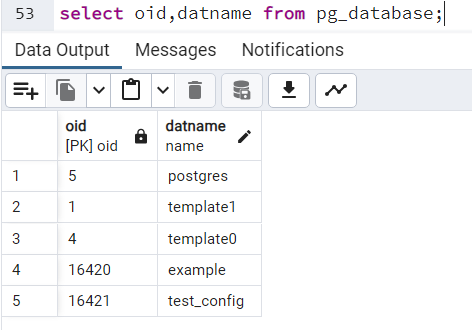
Jak widać, mamy w tym przypadku 5 baz danych. Bazy danych example i test_config zostały stworzone przy okazji jakiegoś przykładu, nie ma ich domyślnie. Baza "postgres" jest tworzona przez skrypt "initdb" w momencie inicjalizacji klastra. Bazy "template0" i "template1" to bazy wzorcowe. Każda nowa baza danych jest tworzona jako kopia bazy "template1". Oznacza to, że jeśli dodamy jakieś obiekty czy ustawienia dla tej bazy, będzie to duplikowane do każdej nowo tworzonej bazy. Baza "template0" również jest bazą wzorcową, jednak nie powinniśmy jej modyfikować. Ma ona pozostać “dziewicza” -jak określono w dokumentacji . Służyć będzie do tworzenia nowych pustych baz danych w przypadku, gdy zmodyfikujemy "template1", a chcielibyśmy nową czystą bazę.
Przy okazji należy porównać oid’y poszczególnych baz z nazwami katalogów w podkatalogu “base” (to tu są pliki danych naszych baz) PGDATA:

Jak widać, każda baza ma osobny katalog i jego nazwa pokrywa się z wartością oid dla każdej bazy. To powoduje, że możemy między innymi umieścić wybraną bazę na innym dysku. Nie sprawia to jednak, że można te katalogi osobno backupować, ponieważ pliki w nich zawarte są powiązane z innymi plikami w PGDATA.
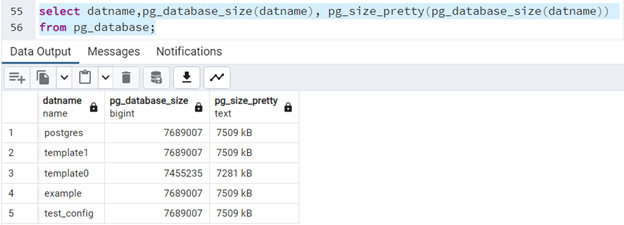
Możemy sprawdzić wielkość poszczególnych baz danych za pomocą funkcji: "pg_database_size" oraz outputu "pg_size_pretty":
select datname,pg_database_size(datname), pg_size_pretty(pg_database_size(datname))
from pg_database;
Przestrzeniami tabel jeszcze się nie zajmowaliśmy. Na potrzeby tego rozdziału należy przyjąć, że przestrzeń tabel to katalog, w którym mogą się znajdować pliki danych.
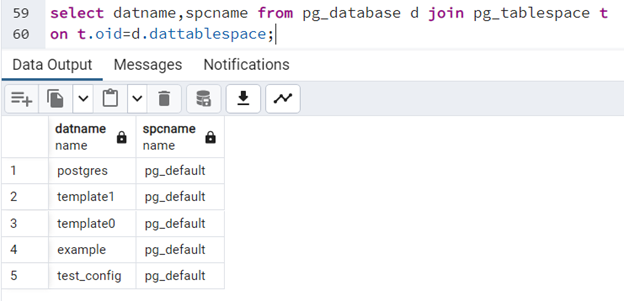
Jeśli chcielibyśmy sprawdzić, w jakim tablespace leżą poszczególne bazy, potrzebujemy wykorzystać dodatkowo słownik "pg_tablespace":
select datname,spcname from pg_database d join pg_tablespace t on t.oid=d.dattablespace;
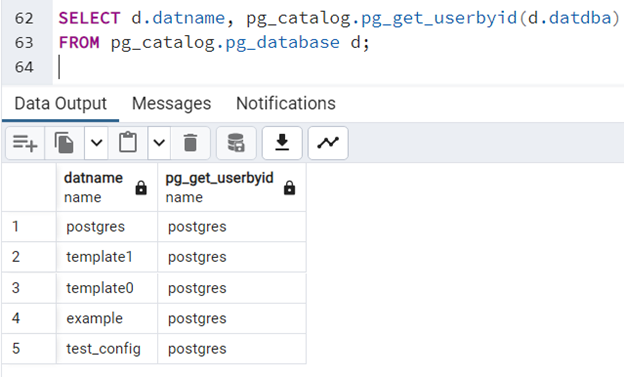
Korzystając z funkcji "pg_get_userbyid" znajdującej się w schemacie "pg_catalog", jesteśmy w stanie zweryfikować, kto jest właścicielem bazy danych:
SELECT d.datname, pg_catalog.pg_get_userbyid(d.datdba)
FROM pg_catalog.pg_database d;
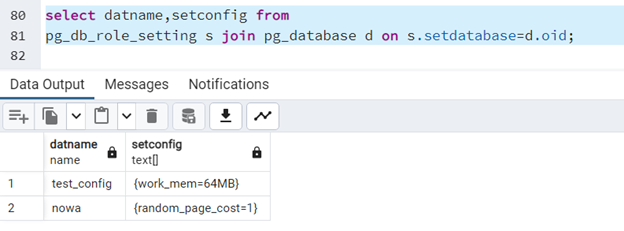
Niektóre z parametrów (np. random_page_cost, seq_page_cost) można ustawić na poziomie bazy danych. Bazy, które mają tak ustawione parametry, będą widoczne w słowniku "pg_db_role_setting". Co ważne - :nie figurują tam wszystkie bazy danych, a jedynie te, które mają parametry ustawione indywidualnie
select * from pg_db_role_setting;
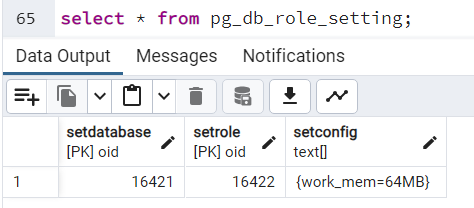
Zamiast nazwy bazy danych mamy jej oid. Potrzebujemy więc zapytania, by zwracało nam nazwy baz:
select datname,setconfig
from pg_db_role_setting s
join pg_database d on s.setdatabase=d.oid;
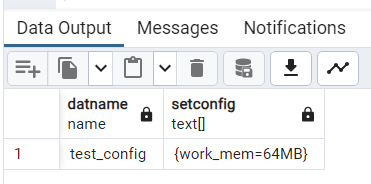
Ogólna konstrukcja polecenia tworzenia bazy danych jest następująca:
CREATE DATABASE NAZWA_BAZY
WITH OWNER = NAZWA UŻYTKOWNIKA
TEMPLATE = BAZA_ROBIĄCA_ZA_SZABLON
ENCODING = KODOWANIE
TABLESPACE = NAZWA_PRZESTRZENI
CONNECTION LIMIT = X
Najprostszy sposób stworzenia bazy:
create database druga;
W ramach takiej bazy utworzy się jeden schemat o nazwie public oraz ewentualnie inne obiekty, jeśli dodamy je do bazy "template1". Możemy też utworzyć bazę danych na podstawie innej bazy:
create database trzecia with template=test_config;
Stworzona w ten sposób kopia będzie zawierała kopię obiektów z bazy wzorcowej.Jest to ciekawy sposób na produkowanie baz developerskich czy testowych. Jedna uwaga – nie możemy w ten sposób stworzyć kopii bazy, do której została podłączona jakakolwiek sesja.
Możemy również umieścić bazę danych w określonej przestrzeni tabel (co za tym idzie i lokalizacji) w następujący sposób:
create database czwarta tablespace=pg_default;
Dane tak stworzonej bazy będą umieszczone w katalogu związanym z daną przestrzenią tabel.
Domyślnie właścicielem bazy danych będzie użytkownik ją tworzący. Aby stworzyć bazę, której właścicielem będzie określony użytkownik, trzeba wykonać polecenie:
create database piata owner=mapet;
Użytkownik, który jest właścicielem bazy danych, będzie mógł zrobić z nią wszystko - w tym nawet skasować, jeśli w danej bazie istnieją obiekty należące do innego użytkownika. Może też kasować i zmieniać obiekty wszystkich innych użytkowników - w tym obiekty stworzone przez użytkownika postgres - czyli administratora klastra.
Tym razem stworzymy nową bazę danych z domyślnym właścicielem "postgres" .Z jego poziomu utworzymy bazę danych.To będzie jej właściciel. Następnie zmienimy właściciela:
create database nowa;
select datname,pg_catalog.pg_get_userbyid(d.datdba) from pg_database d;
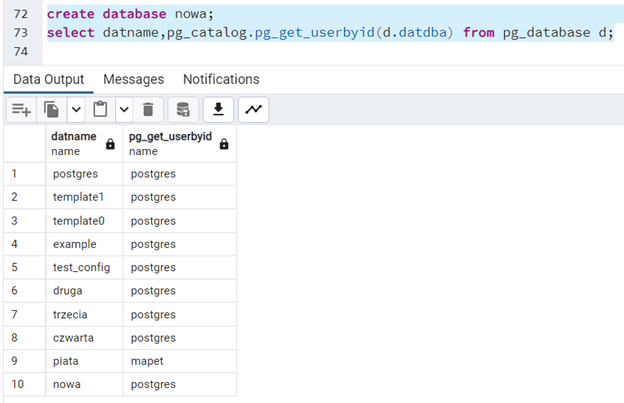
Widzimy wszystkie stworzone dotychczas bazy - w tym np. bazę “piata” należąca do użytkownika mapet. Nasza nowo stworzona baza “nowa” należy do użytkownika postgres. Zmieniamy właściciela na użytkownika mapet:
alter database nowa owner to mapet;
Sprawdzamy właściciela dla tej bazy:
select datname,pg_catalog.pg_get_userbyid(d.datdba) from pg_database d
where datname='nowa';
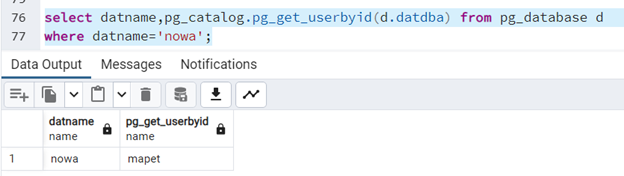
Właścicielem bazy “nowa” jest już użytkownik “mapet”.
Niektóre parametry można ustawiać na poziomie bazy danych. Aby zmienić parametry, wykonujemy poniższe zapytanie:
alter database nowa set random_page_cost=1;
Został użyty parametr: "random_page_cost" , ale może to być dowolny parametr konfigurowalny na poziomie bazy danych. Sprawdźmy jeszcze, czy to działa:
select datname,setconfig from
pg_db_role_setting s join pg_database d on s.setdatabase=d.oid;
Bazy danych przy tworzeniu będą lądowały w domyślnej przestrzeni tabel tj. "pg_default", czyli w podkatalogu "base" naszej PGDATA. Przestrzeń docelową możemy wskazać, tworząc bazę danych, ale jeśli taka już istnieje, możemy ją też przenieść. Przeniesienie bazy danych pomiędzy przestrzeniami tabel będzie się wiązało z fizycznym przeniesieniem jej plików pomiędzy katalogami. W związku z tym, by zapewnić spójność danych, baza w trakcie przenoszenia pomiędzy przestrzeniami tabel będzie niedostępna. Aby przenieść bazę do innej przestrzeni tabel, wykonujemy komendę wg schematu:
alter database do_przeniesienia set tablespace dane1;
Zmienimy nazwę bazy danych. W swoim klastrze mamy bazę o nazwie "example":
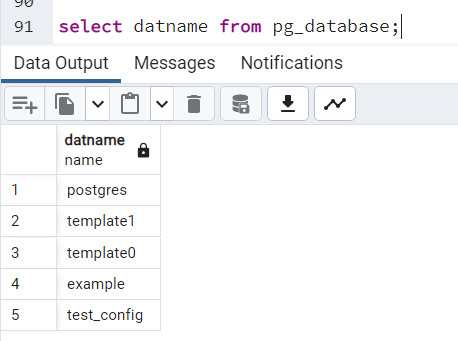
Zmieniamy nazwę z “example” na “samples”:
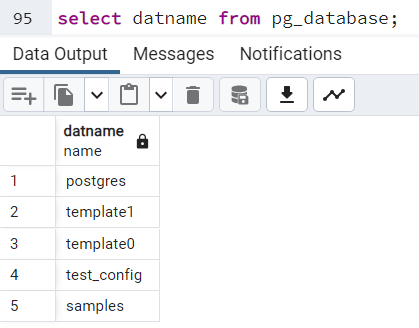
alter database example rename to samples;
Nazwa została zmieniona:
Jeśli chcemy skasować bazę danych, możemy wywołać:
drop database samples;
Wykonując tę operację, należy podpiąć się do innej bazy niż ta kasowana. Nie uda się też skasować bazy, jeśli jakiś użytkownik będzie do niej podpięty. Trzeba będzie ubić jego sesję. Każdą bazę niezależnie od tego, kto jest jej właścicielem, może skasować superużytkownik, np. postgres. Kasowanie bazy danych powoduje skasowanie wszystkich obiektów w niej zawartych.


Komentarze (0)
Brak komentarzy...