Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!

Żeby zrozumieć działanie checkpointów i plików WAL, trzeba najpierw poznać, w jaki sposób PostgreSQL zapisuje dane.
W pierwszej kolejności zmiany odnotowuje się w plikach WAL. Pliki WAL rejestrują wszystkie zmiany, jakie są dokonywane na danych w klastrze (z wyłączeniem zmian na tabelach nielogowanych). Wprowadza się je tam na potrzeby ewentualnego odtwarzania danych. Zapis do plików WAL jest szybszy od modyfikacji na plikach danych obiektów bazodanowych, między innymi dlatego, że mamy tu do czynienia z zapisem sekwencyjnym, a nie losowym. Użytkownik, by otrzymać potwierdzenie wprowadzenia/zmiany danych, musi zaczekać tylko na wprowadzenie wpisu do pliku WAL, nie jest potrzebne oczekiwanie na utrwalenie zmian danych w plikach. Dzięki temu mechanizmowi nie tylko zapewniamy sobie bezpieczeństwo w razie awarii, ale też zmiany na danych mogą być wykonywane szybciej. Każdy plik WAL waży 16MB. Od wersji 10 PostgreSQL pliki WAL są w katalogu "pg_wal" znajdującym się w PGDATA. We wcześniejszych wersjach były przechowywane w katalogu "pg_xlog".
W kolejnym kroku dane są zmieniane na poziomie bufora "shared_buffers". Jeśli mamy do czynienia z operacją zmieniającą dane, trzeba je będzie najpierw do tego bufora wczytać (o ile nie zostały wcześniej wczytane w wyniku działania cache). Po wczytaniu są one modyfikowane na poziomie bufora. Jeśli wstawiamy nowe dane, muszą one zostać załadowane do "shared_buffer". Niezależnie od tego, czy są to dane nowo dodawane czy zmieniane, do czasu aż nie zostaną zapisane w plikach danych, noszą nazwę "brudnych bloków".
W tej chwili mamy informacje o zmianach wprowadzonych do plików WAL. Zostały one zmienione na poziomie bufora. Nie są jeszcze utrwalone w plikach danych. Kiedy następuje zapis do plików danych? Wtedy, gdy następuje "checkpoint"...
W chwili, gdy następuje "checkpoint", wszystkie brudne bloki znajdujące się w buforze są flush'owane na dysk. Checkpoint gwarantuje nam, że wszystkie operacje przed nim zostały utrwalone w plikach danych.
W przypadku awarii PostgreSQL sprawdza punkt czasowy ostatniego checkpoint'a, by określić punkt, od którego ma rozpocząć odzyskiwanie REDO na podstawie plików WAL. Dzięki temu wie, od którego pliku WAL i jakiego offsetu w tym pliku ma rozpocząć odzyskiwanie. Klaster przy uruchamianiu po awarii automatycznie powtarza wszystkie zmiany wprowadzone do plików WAL, które nie zostały utrwalone w plikach danych. W konsekwencji odzyskujemy stan klastra z chwili przed awarią. Odtwarzanie dotyczy tylko transakcji zatwierdzonych.
Mamy gwarancję, że wszystkie dane zmienione przed checkpoint'em zostały utrwalone w plikach danych na dysku, więc nie musimy powtarzać operacji je zmieniających. Pliki WAL, które dotyczą zmian przed checkpoint'em, mogą zostać usunięte, ponieważ nie będą już potrzebne do odzyskiwania danych. Są one nadpisywane kolejnymi plikami WAL w ramach kolejki.
Checkpoint może zostać uruchomiony w kilku sytuacjach.
Do zarządzania zachowaniem checkpointów i plików WAL mamy kilka przydatnych parametrów. Wszystkie opisane niżej parametry związane z checkpointami i plikami WAL mają zasięg klastra, czyli możemy je ustawić dla całego klastra, ale nie na niższych poziomach granulacji.
Ten parametr określa maksymalną przestrzeń, jaką mogą zająć pliki WAL. Jest to limit "miękki", co oznacza, że może on zostać przekroczony w sytuacjach takich jak masowe ładowanie danych czy błąd w wykonywaniu "archive_command". Domyślną wartością - parametru "max_wal_size" jest 1GB. Jeśli ustawimy tę wartość zbyt nisko, checkpointy będą występowały częściej (w związku z częstszym docieraniem do granicy przestrzeni na nie przeznaczonej). Jeśli ustawimy ten parametr na wysoką wartość, w przypadku ewentualnej awarii czas odzyskiwania będzie dłuższy, ponieważ do przetworzenia będzie więcej plików WAL. - Możemy go zmienić w ten sposób:
alter system set max_wal_size='10G'; select pg_reload_conf();
Ten parametr określa, co jaki czas ma następować automatyczny checkpoint. Domyślna wartość tego parametru to 5 minut. Może przyjąć wartości w zakresie 30-3600s.
Wydłużenie czasu pomiędzy kolejnymi checkpointami może przynieść korzyść w przypadku systemów często zmieniających te same dane. Wiele zmian na tych samych danych może zostać dokonanych na poziomie bufora, by potem jednorazowo przy checkpoincie wprowadzić ostateczną wersję do plików danych, zamiast utrwalać każdą zmianę osobno.
Zmiana tego parametru będzie miała wpływ nie tylko na wydajność, ale też na czas odzyskiwania danych w przypadku awarii. Im większe damy tu okno czasowe, tym więcej będzie plików WAL do przetworzenia w czasie odtwarzania REDO i tym dłużej to odtwarzanie będzie trwało. Aby zmienić ten parametr, wykonujemy:
alter system set checkpoint_timeout='15min'; select pg_reload_conf();
Checkpointy wiążą się z dużym obciążeniem I/O w związku z utrwalaniem brudnych bloków na dysku. Gdyby w chwili, gdy checkpoint następuje, PostgreSQL zapisywał je najszybciej, jak to możliwe, to mielibyśmy bardzo dużo I/O w krótkim czasie. Konsekwencją byłyby znaczne opóźnienia wszystkich operacji, które dzieją się w tym samym czasie. W związku z tym PostgreSQL dławi ten zapis w taki sposób, by rozłożyć go w czasie. To, w jakim czasie, zależy od ilorazu dwóch parametrów: "checkpoint_timeout" i "checkpoint_completion_target". "checkpoint_completion_target" określa, w jakiej części czasu zdefiniowanego w "checkpoint_timeout" ma się zmieścić zapis wszystkich brudnych bloków na dysk. Domyślną wartością dla "checkpoint_timeout" jest 5 minut, a dla "checkpoint_completion_target" wartość 0.5. Oznacza to, że w przypadku tak ustawionych parametrów zapis brudnych bloków zostanie rozłożony na 2.5 minuty. Im bardziej zwiększymy "checkpoint_completion_target", tym bardziej równomiernie rozłożymy w czasie operacje wynikające z utrwalania brudnych bloków. Dzięki temu wydajność naszego klastra nie będzie "szarpać". Wartość tego parametru możemy ustawić w zakresie od 0 do 1.
Wskazane jest ustawienie wartości parametru "checkpoint_completion_target" na wartość od 0.7 do 0.9. Do wersji 13 włącznie parametr ten miał domyślne ustawienie 0.5, od wersji 14 parametr ten ma wartość 0.9.
Do czasu zakończenia checkpointa pliki WAL zawierające zmiany od poprzedniego checkpointa nie mogą zostać usunięte.
Wartość - parametru checkpoint_completion_target można przestawić w ten sposób:
alter system set checkpoint_completion_target=0.9; select pg_reload_conf();
Parametr "log_checkpoints" pozwala na monitorowanie pojawiających się checkpointów. Od chwili jego włączenia do logu będą trafiały informacje o każdym pojawiającym się checkpoincie razem z pewną ilością informacji statystycznych na jego temat. Włączyć rejestrację checkpointów możemy w ten sposób:
alter system set log_checkpoints=on; select pg_reload_conf();
Aby mieć jakieś dane statystyczne, stworzymy teraz tabelę, załadujemy do niej dane i spowodujemy checkpoint:
create table omg(x integer); insert into omg select generate_series(1,1000000); checkpoint;
Możemy teraz zajrzeć do loga:

Widzimy, że "checkpoint" nastąpił z powodu wywołania ręcznego. To właśnie oznacza wpis "checkpoint starting: immediate force wait". Po frazie "checkpoint complete" mamy trochę informacji na temat - wykonanego checkpointa. Co one oznaczają?
"wrote xxx buffers (xx.x%)" określa, ile brudnych bloków zostało zapisanych w ramach tego checkpointa. W tym przypadku jest to 4447 bloków po 8kB każdy, czyli około 34 MB.
Mamy ustawiony shared_buffers na 128MB i brudne bloki stanowiły 27.1% tego bufora. Upewnijmy się jeszcze:
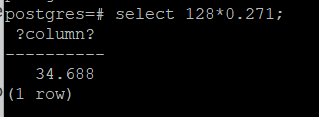
Faktycznie 27.1% z 128MB to w przybliżeniu 34MB.
"0 WAL file(s) added, 0 removed, 4 recycled" oznacza, że 0 nowych plików WAL zostało dodanych, 0 plików WAL zostało usuniętych z pg_wal, a zawartość 4 została już utrwalona w plikach danych w wyniku tego checkpointa. Nie będą one potrzebne do ewentualnego odtwarzania awaryjnego.
"write=0.297s, sync=1.169s, total=1.525s" Write określa, ile czasu trwał zapis do plików danych. "sync" - ile czasu trwała synchronizacja plików, tj. sprawdzenie, czy na pewno wszystkie dane zostały utrwalone w plikach danych. Total jest sumą obu wymienionych.
"sync files=18, longest=1.152 s, average=0.065s; distance=62771 kB, estimate=454038 kB" "sync files" określa, ilu plików systemu operacyjnego zostało "dotkniętych" punktem kontrolnym. Znajdziemy tu też czas trwania najdłuższej synchronizacji pliku, średni czas trwania synchronizacji pojedynczego pliku. Ostatnie dwa parametry oznaczają odległość pomiędzy dwoma checkpointami wyrażoną w bajtach.
Przypuśćmy, że chcielibyśmy zmodyfikować wartość parametru "checkpoint_timeout". Jeśli wydłużymy czas pomiędzy checkpointami, będzie potrzebna większa przestrzeń na pliki WAL. Jeśli w ślad za zmianą "checkpoint_timeout" nie zmienimy "max_wal_size", to checkpointy i tak mogą następować częściej niż wynika to z "checkpoint_timeout". Tym razem będzie to jednak wynikało z docierania do granicy przestrzeni dyskowej przeznaczonej na pliki WAL. I tutaj stajemy przed kluczowym pytaniem. Na jaką wartość ustawić "max_wal_size", by dopasować wielkość przestrzeni przeznaczonej na pliki WAL do ustawionego "checkpoint_timeout"?
Każdy wpis w pliku WAL ma swój określony identyfikator zwany "Log Sequence Number" - LSN. - Możemy porównać wartości LSN dwóch wpisów, by dowiedzieć się, ile danych leży pomiędzy nimi.
Na podstawie tych danych możemy oszacować przestrzeń utylizowaną przez pliki WAL w oknie czasowym wyznaczonym przez "checkpoint_timeout". Przyjmijmy więc, że chcielibyśmy ustawić "checkpoint_timeout" na 10 minut i oszacować, jakiej wielkości "max_wal_size" będzie - potrzebny. Określamy więc aktualny LSN:
select pg_current_wal_insert_lsn();
Otrzymaliśmy w odpowiedzi wartość "2/E1C11100". Czekamy 10 minut, by po tym czasie sprawdzić aktualny LSN ponownie. Zakładamy, że na bazie, na której to sprawdzamy, - następują jakieś zmiany, - które będą rejestrowane w plikach WAL. Jeśli nie, należy uruchomić jakiś skrypt ładujący dane do tabeli. Możemy wykorzystać np. taki kod (jego wykonanie zajmie co najmniej kilka minut):
create table testowa(x integer,y text); do $$ begin for x in 1..100000000 loop insert into testowa values (x,'element numer '||x); end loop; end $$;
Po upływie - 10 minut - ponownie sprawdzamy aktualny LSN (nawet jeśli powyższy kod jeszcze się wykonuje). Możemy go też przerwać albo sprawdzić lsn z innej sesji):
select pg_current_wal_insert_lsn();
Dostajemy w odpowiedzi wartość "4/F1F6C0E8". Ile danych znalazło się w plikach WAL pomiędzy - obiema wartościami LSN? Możemy to sprawdzić za pomocą funkcji "pg_wal_lsn_diff". Jako pierwszy argument dajemy późniejszy LSN, inaczej otrzymamy wartość ujemną:
select pg_wal_lsn_diff('4/F1F6C0E8','2/E1C11100');
Wartość zostanie zwrócona w bajtach. - Wygląda to tak:

Wartość jest wyrażona w bajtach, ale na szczęście w PostgreSQL znajduje się pomocna funkcja "pg_size_pretty", która nam tę wielkość - sformatuje:
select pg_size_pretty(pg_wal_lsn_diff('4/F1F6C0E8','2/E1C11100'));
Wynik:

W ciągu tych 10 minut PostgreSQL zutylizował 8451MB. Tyle więc potencjalnie powinienem mieć dostępnej przestrzeni dla plików WAL. Weźmy pod uwagę, - że jest to obciążenie w danej chwili. Poziom obciążenia może być zmienny na przestrzeni czasu. Może się więc okazać, że w innym momencie obciążenie będzie znacznie wyższe i - nie wystarczy nam ta przestrzeń.



Komentarze (0)
Brak komentarzy...