
Logiczna replika bardzo często ma źródło w klastrze HA, jednak logiczny slot replikacyjny znajduje się tylko na instancji głównej i nie tworzy się automatycznie po awansowaniu fizycznej repliki na primary. Nie możemy też stworzyć logicznego slota na fizycznej replice, co z kolei sprawia, że logiczna replikacja zostaje przerwana po każdej operacji failovera / switchovera, ponieważ replika fizyczna nie posiada slota replikacyjnego i nie przechowuje plików WAL, które będą wymagane przez logiczną replikę do kontynuacji odtwarzania zmian. Nawet jeżeli natychmiast po awansowaniu repliki stworzylibyśmy slot replikacyjny, będzie się on i tak zaczynał od momentu stworzenia slotu. W takiej sytuacji logiczna replikacja nie mogłaby, a raczej nie powinna, wznawiać pracy, ponieważ mogłoby jej brakować części wpisów WAL, które zostały utworzone przed stworzeniem slota.
Możemy jednak trochę oszukać postgresa i dodać logiczny slot replikacyjny na fizycznej instancji standby, pomimo że jest ona otwarta "tylko do odczytu" i dzięki temu wymusić na replice przechowywanie wszystkich plików WAL, które logiczna replika będzie potrzebowała po failoverze.
Na początku upewnijmy się, że zarówno serwer primary jak i fizyczna replika mają odpowiedni "wal_level", dla obu powinien to być "logical".
primary=# show wal_level ;
wal_level
-----------
logical
(1 row)standby=# show wal_level ;
wal_level
-----------
logical
(1 row)
Jeżeli jest inny niż logical, powinniśmy go zmienić i zrestartować postgresa, ponieważ ustawienia parametru wal_level wczytywane są tylko w momencie startu klastra.
psql -c "alter system set wal_level = logical;"
ALTER SYSTEMpg_ctl -D /data_pg/ restart -m fast
Zapytanie zwracające informacje o istniejących slotach replikacyjnych.
primary=# select * from pg_replication_slots ;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size | two_phase
------------+----------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+---------------------+------------+---------------+-----------
slot_drugi | pgoutput | logical | 13697 | postgres | f | f | | | 1843014 | 4/F50000D8 | 4/F50000D8 | reserved | | f
(1 row)
Próba stworzenia logicznego slotu replikacyjnego kończy się błędem "ERROR: logical decoding cannot be used while in recovery", a finalnie slot nie zostaje stworzony.
standby=# select pg_create_logical_replication_slot('slot_drugi', 'pgoutput');
2022-11-01 20:36:32.542 UTC [2815] ERROR: logical decoding cannot be used while in recovery
2022-11-01 20:36:32.542 UTC [2815] STATEMENT: select pg_create_logical_replication_slot('slot_drugi', 'pgoutput');
ERROR: logical decoding cannot be used while in recovery
standby=# select * from pg_replication_slots ;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size | two_phase
-----------+--------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+---------------------+------------+---------------+-----------
(0 rows)
Jak zatem go stworzyć? Każdy stały slot replikacyjny zapisuje informacje o sobie w katalogu $PGDATA/pg_replslot/<nazwa_slota>/ w binarnym pliku "state".
postgres@ubuntu:/data_pg$ ls -R /data_pg/pg_replslot/
pg_replslot/:
slot_drugipostgres@ubuntu:/data_pg$ ls -R /data_pg/pg_replslot/slot_drugi
pg_replslot/slot_drugi:
state
Na fizycznej replice katalog pg_replslot jest pusty, ponieważ pg_basebackup pomija jego zawartość przy kopiowaniu PGDATA, a postgres nie przesyła informacji o nim za pomocą strumieniowania wpisów WAL ani nie zapisuje ich w plikach WAL.
Aby wszystko zadziałało poprawnie, musimy skonfigurować połączenie SSH autoryzowane za pomocą klucza RSA. UWAGA, część z generowaniem klucza powinniśmy pominąć, jeżeli posiadamy już na serwerze plik "~/.ssh/id_rsa.pub". Nadal musimy jednak skopiować jego zawartość na pozostałe serwery i wykonać na nich resztę kroków. Aby wygenerować klucz ssh po stronie serwera primary (u nas host 1), należy wykonać polecenie ssh-keygen, a następnie skopiować zawartość klucza znajdującego się w pliku ~/.ssh/id_rsa.pub do pliku .ssh/authorized_keys po stronie serwera repliki, u nas pg2. W tym celu po stronie serwera primary (host 1) wywołujemy polecenia (jako użytkownik systemowy postgres):
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub
Następnie to, co zostanie wyrzucone po instrukcji "cat", umieszczamy po stronie serwera docelowego (dla klucza z pg1 zawartość kopiujemy na pg2 i odwrotnie, klucz z pg2 kopiujemy na pg1) w pliku ~/.ssh/authorized_keys jako użytkownik systemowy postgres:
vi ~/.ssh/authorized_keys
Po tej operacji sprawdzamy jeszcze, czy uda nam się zalogować na serwer repliki bez podawania hasła:
postgres@pg1:~$ ssh postgres@pg2postgres@pg2:~$ ssh postgres@pg1
Logowanie powinno przejść bez podawania hasła.
Podobnie skonfiguruj SSH pomiędzy hostem 1,2,3 do hosta 5.
Spróbujmy zatem go skopiować z instancji primary na fizyczną replikę za pomocą scp (wykonujemy jako użytkownik systemowy postgres,.Pamiętajmy o podmianie ip repliki na ip repliki fizycznej tj host 2).
postgres@pg1:/data_pg$ scp -r /data_pg/pg_replslot/* <IP repliki>:/data_pg/pg_replslot

Na replice sprawdźmy, czy widoczna jest informacja o skopiowanym slocie. Parametr -P pager=off sprawi, że wynik zostanie wyświetlony bezpośrednio w konsoli, a nie za pomocą narzędzia "more" lub "less", co często jest domyślnym zachowaniem postgresa przy zapytaniach z dużą liczba kolumn.
postgres@ubuntu:~$ psql -P pager=off -c "select * from pg_replication_slots";

Lista slotów jest pusta, ponieważ postgres wczytuje informacje o nich tylko w momencie wywołania funkcji "pg_create_*_replication_slot()" lub podczas startu instancji. Jako że na replice nie możemy stworzyć logicznego slota replikacyjnego, zostaje nam tylko druga opcja. Zrestartujmy więc klaster.
postgres@ubuntu:~$ pg_ctl -D /data_pg/ restart -m fast

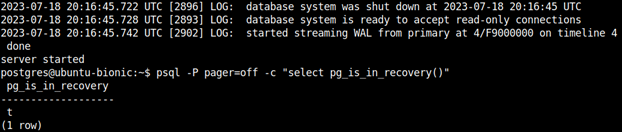
Po restarcie sprawdźmy, czy serwer wystartował jako replika, czy rozpoczął strumieniowanie plików WAL z instancji primary oraz czy widoczny jest nasz skopiowany slot replikacyjny.
postgres@ubuntu:~$ psql -c "select pg_is_in_recovery()"
postgres@ubuntu:~$ psql -P pager=off -c "select * from pg_replication_slots"
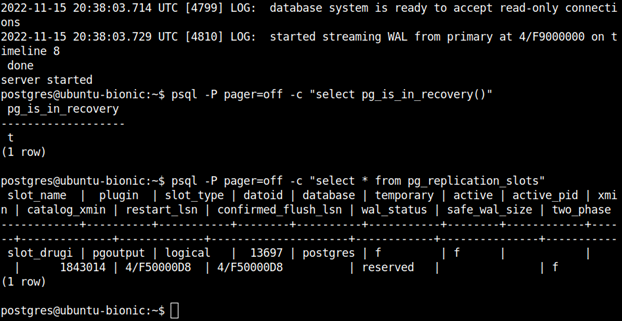
Kiedy slot stanie się widoczny na replice, ta natychmiast zacznie przetrzymywać wszystkie pliki WAL. Należy na to uważać, ponieważ jeżeli nie awansujemy repliki na primary i nie podłączymy procesu WAL receiver, pliki WAL będą przechowywane w nieskończoność, a replika nie będzie w stanie modyfikować wartości "catalog_xmin" oraz "LSN" dla slota replikacyjnego, co przy włączonej opcji hot_standby_feedback, może spowodować jeszcze więcej problemów na primary. Dlatego jeżeli już zdecydujemy się na wykonanie failovera dla logicznej repliki, najlepiej jest skopiować informacje o slocie oraz wykonać restart bezpośrednio przed przerzuceniem lidera.
Zatrzymajmy teraz postgresa na hoście pierwszym, przed promowaniem repliki.
postgres@ubuntu:~$ pg_ctl -D /data_pg/ stop -m fast
Możemy teraz wykonać promote repliki za pomocą funkcji pg_promote() wykonanej na replice.
postgres@ubuntu:~$ psql -c "select pg_promote()"
Następnie musimy zmodyfikować adres serwera źródłowego dla subskrypcji na logicznej replice, aby replika kontynuowała replikowanie zmian z nowej primary. Pamiętajmy o podmianie IP na adres nowego primary tj. host2, nowy primary:
ALTER SUBSCRIPTION druga_sub CONNECTION 'host=<nowy adres primary> dbname=postgres user=logicalrep password=logiczna_replika port=5432';
Po tej zmianie logiczna replika powinna ponownie rozpocząć aplikowanie zmian. Replikacja rozpocznie się od miejsca, w którym skończyła. Slot był skopiowany wcześniej, dlatego powinniśmy mieć więcej plików WAL niż potrzebujemy, a logiczna replika posiada informacje, od której lokacji w WAL chce replikować w informacjach dla "replication_origin", wcześniej ustawionego ręcznie.
Po wykonanym failoverze za pomocą zapytania możemy sprawdzić na instancji primary, czy zmiany są replikowane oraz czy żadna z subskrypcji nie ma problemów:
postgres=# SELECT slot_name, confirmed_flush_lsn as flushed, pg_current_wal_lsn(), (pg_current_wal_lsn() - confirmed_flush_lsn) AS lsn_distance, pg_size_pretty((pg_current_wal_lsn() - confirmed_flush_lsn)) AS slot_size FROM pg_catalog.pg_replication_slots;
Jeżeli któryś ze slotów replikacyjnych zacząłby lagować i lag cały czas by rósł, powinniśmy sprawdzić logi logicznej repliki, czy wszystko w porządku z subskrypcją korzystającą z tego slota, czy nie pojawiły się jakieś konflikty replikacji.


Komentarze (0)
Brak komentarzy...