
Gorący backup w przeciwieństwie do zimnego nie wymaga wyłączania klastra. I to jest jego podstawowa zaleta. Nie zawsze możemy sobie pozwolić na wyłączanie klastra bazodanowego ilekroć zechcemy zrobić kopię zapasową. Ponadto pozwala odtworzyć klaster nie tylko do punktu w którym został wykonany backup, ale wykorzystując archiwizację ciągłą również do punktu w czasie pomiędzy kopią zapasową a awarią.
Bardzo wygodnym narzędziem stworzonym do tego celu opisywany wcześniej jest pg_basebackup, ale nie jest to jedyna metoda. Tym razem zajmiemy się metodą niskopoziomową, z użyciem funkcji "pg_backup_start" (lub pg_start_backup w przypadku wersji wcześniejszych niż 15). Ta metoda jest wykorzystywana m.in przez pgBackRest. Jest też bardziej elastyczna, masz pełną kontrolę nad całym przebiegiem procesu wykonywania kopii zapasowej. Podobnie jak w przypadku pg_basebackup i w tym przypadku wymagana jest archiwizacja ciągła. Daje nam to możliwość przywrócenia klastra do stanu późniejszego niż moment wykonania backupu.
Przede wszystkich rozpocząć musimy od skonfigurowania archiwizacji ciągłej. Tworzymy katalog na zarchiwizowane pliki WAL i ustawiamy użytkownika systemowego postgres jako jego właściciela. Poniższe instrukcje wykonujemy z poziomu użytkownika systemowego z prawami do "sudo" a nie użytkownika postgres:
sudo mkdir /archs
sudo chown postgres:postgres /archs
Ustawiamy niezbędne parametry. Parametr wal_level powinien być ustawiony na "replika" już domyślnie, ale gdybyś miał do czynienia z klastrem w wersji starszej niż 10, musisz go ustawić bo obowiązywała wtedy wartość "minimal". Za pomocą parametru archive_mode włączam proces archiwizacji ciągłej. Aby ta archiwizacja mogła się odbywać, konfiguruję też parametr archive_command który archiwizuje pliki WAL. Może tu wystąpić dowolna komenda systemu operacyjnego. %p oznacza pełną nazwę archiwizowanego pliku WAL wraz ze ścieżką, %f odnosi się do nazwy pliku bez ścieżki. W poniższym przykładzie każdy archiwizowany WAL będzie kopiowany do katalogu /archs który stworzyliśmy przed chwilą.
psql
alter system set wal_level='replica';
alter system set archive_mode=on;
alter system set archive_command='cp %p /archs/%f';
Skoro już jesteśmy przy konfiguracji parametrów, możemy już sobie ustawić przy okazji jak pliki WAL mają być odtwarzane w przypadku odtwarzania klastra z kopii zapasowej. Wykorzystamy w tym celu parametr restore_command który jest odwrotnością archive_command. Jego zadaniem jest wskazanie w jaki sposób i skąd mają być pobierane do wczytania zarchiwizowane pliki WAL gdy po odtworzeniu plików klastra z kopii zapasowej zaciągamy jeszcze zawarte w zarchiwizowanch plikach WAL zmiany od momentu backupu. Znaczenie %f i %p jest takie samo jak w przypadku archive_command. W poniższym przykładzie w przypadku restore, zarchiwizowane pliki WAL będą kopiowane z katalogu /archs w celu odtworzenia. Warto ten parametr mieć już od razu ustawiony, bo to jedna rzecz mniej do zrobienia w przypadku awaryjnego odtwarzania. Samo ustawienie tego parametru nic nie zmienia w normalnym działaniu klastra. Zmieniamy:
alter system set restore_command='cp /archs/%f %p';
To już by było na tyle w materii ustawiania parametrów. Jednak aby zmiana archive_mode nastąpiła musimy jeszcze zrestartować klaster:
pg_ctl -D /data_pg/ restart
Jeśli jeszcze nie posiadamy, tworzymy katalog na potrzeby kopii zapasowej i sprawiamy, że staje się on własnością użytkownika postgres. Poniższe instrukcje wykonujemy z poziomu użytkownika systemowego z prawami do "sudo" a nie użytkownika postgres:
sudo mkdir /backups
sudo mkdir /backups/hb
sudo chown postgres:postgres /backups -R
Loguję się za pomocą psql do bazy i tworzę tabelkę. Teraz działamy jako użytkownik postgres:
create table dane(x integer);
Na razie pozostawiam ją pustą. Wykonamy teraz kopię zapasową zawierającą pustą tabelkę. Po wykonaniu kopii zapasowej dodamy do tej tabelki wiersz, a zmiana ta pojawi się tylko w aktualnych plikach WAL, jeszcze nie zarchiwizowanych. Następnie odtworzymy klaster z użyciem nie tylko zarchiwizowanych plików WAL (które nie będą zawierały tego inserta), ale również aktualnych plików WAL, pochodzących z katalogu pg_wal klastra. Oczywiście moglibyśmy się ograniczyć tylko do odtwarzania z samych zarchiwizowanych plików WAL, ale wtedy najprawdopodobniej utracimy ostatnie zmiany. To jak duża będzie to utrata jest zależne od tego jak często są switchowane i archiwizowane pliki WAL. My oczywiście nie chcemy pozwolić na jakąkolwiek utratę danych, więc zastosujemy sposób nieco bardziej wymagający.
Aby rozpocząć wykonywanie kopię zapasową muszę wejść w tryb backupu. Zapewni on spójność kopii zapasowej. W tym celu w psql wywołujemy:
select pg_backup_start(label=>'hb', fast=>false);
Powyższą komendę uruchamiamy z poziomu psql, a sesja ta musi być aktywna przez cały czas wykonywania kopii zapasowej. Do wykonywania kolejnych czynności nawiąż więc osobną sesję shell. W wersjach starszych niż 15 funkcja "pg_backup_start" nazywała się "pg_start_backup". Poza tym argumenty nie uległy zmianie. Argument "label" to po prostu unikatowa nazwa kopii zapasowej. Przełącznik fast dotyczy checkpointa. Przed rozpoczęciem wykonywania kopii zapasowej potrzebne jest wykonanie checkpointa. Ustawienie przełącznika "fast" na "false" oznacza, że PostgreSQL będzie czekał na najbliższego "naturalnego" checkpointa wynikającego z parametru "checkpoint_timeout". Może więc to trwać dosyć długo. Możesz ustawić argument fast na "true" powodując wykonanie natychmiastowego checkpointa, ale to się będzie wiązać z chwilowym znacznie większym obciążeniem klastra, wynikającym z natychmiastowego checkpointa który pomija ustawienie parametru "checkpoint_completion_target".

Mając cały czas uruchomioną sesję psql z której uruchomiliśmy funkcję "pg_backup_start" możemy przejść do kopiowania PGDATA klastra do folderu na kopię zapasową (z innej sesji ssh):
cp -R /data_pg/* /backups/hb/
ls /backups/hb/

Po skopiowaniu plików możemy wyjść z trybu backupu. Z sesji psql w której wcześniej wywoływaliśmy "pg_backup_start" wywołujemy teraz poniższą instrukcję by wyłączyć tryb backupu:
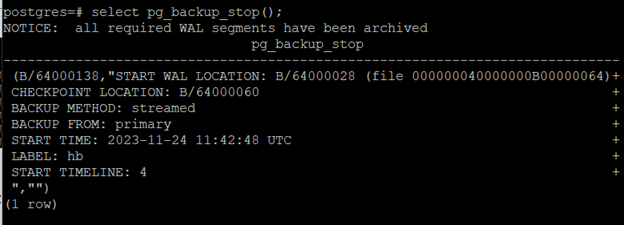
select pg_backup_stop();
Po wykonaniu tej instrukcji dostaniemy widok podobny do poniższego, zawierający informacje na temat backupu:
Skoro backup już wykonany, przechodzimy do wstawienia wiersza do tabeli "dane". Informacji o tym wierszu nie będzie w kopii zapasowej. Znajdzie się ona w bieżących plikach WAL, a następnie w zarchiwizowanych plikach WAL (w naszym przypadku w /archs).
insert into dane values (999);
Nie wykonuję switcha plików WAL, na samym klastrze nic się nie dzieje, parametr "archive_timeout" mam ustawiony na domyślnej wartości 0 (czyli nie następuje automatyczne przełączenie WALi wymuszone czasem), więc informacja o tym insercie będzie w bieżących plikach WAL i raczej nie zdąży się skopiować do zarchiwizowanych WAL.
Możemy teraz przejść do awaryjnego odtwarzania klastra. Odtworzymy go z kopii do bocznej lokalizacji "/data_pg2" którą najpierw musimy utworzyć. Poniższe instrukcje wykonujemy z poziomu użytkownika systemowego z prawami do "sudo" a nie użytkownika postgres:
sudo mkdir /data_pg2
sudo chown postgres:postgres /data_pg2 -R
sudo chmod 700 /data_pg2
Kładziemy oryginalny klaster (żeby nie było konfliktu portu nasłuchu) i przywracamy klaster z kopii zapasowej do katalogu "na boku":
pg_ctl -D /data_pg stop
cp -R /backups/hb/* /data_pg2/
Moglibyśmy teraz przejść do odtwarzania plików WAL, ale wczytał by nam tylko te zarchiwizowane. To mogłoby skutkować utratą pewnej części zmian - tych które znajdują się w bieżących plikach WAL i jeszcze nie zostały zarchiwizowane. Ponieważ chcemy odzyskać wszystkie zmiany, musimy najpierw skopiować bieżące pliki WAL do pg_wal naszego klastra "na boku", by również zmiany w nich zawarte zostały odtworzone. Najpierw będą odtworzone te z /archs, a następnie te z pg_wal w PGDATA.
cp /data_pg/pg_wal/* /data_pg2/pg_wal/ -R
Oczywiście pewna część plików WAL będzie taka sama, ale chodzi nam o skopiowanie tych których nie mamy. PostgreSQL wczytuje pliki WAL sekwencyjnie wg numeracji w HEX. Struktura niezarchiwizowanych plików WAL i zarchiwizowanych plików WAL jest dokładnie taka sama. W końcu jest to kopia pliku WAL tworzona przez archive_command. PostgreSQL więc nie odróżnia czy plik był zarchiwizowany czy nie.
Tworzymy plik "recovery.signal" w PGDATA naszego klastra "na boku" - czyli tego gdzie odtwarzamy. Plik ma być pusty. Sam fakt istnienia tego pliku powoduje wejście w tryb odtwarzania przy uruchomieniu.
touch /data_pg2/recovery.signal
Zanim uruchomimy odzyskany klaster, włączymy sobie podgląd logów w osobnej sesji:
tail -f /data_pg2/log/postgresql.log
Następnie uruchamiamy (z pierwszej sesji) klaster i patrzymy co się dzieje w logach:
pg_ctl -D /data_pg2/ start
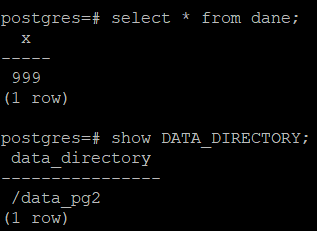
Jeżeli w logach nie pojawiły się żadne krytyczne błędy, powinniśmy mieć wszystko odtworzone, włącznie z wierszem dodanym do tabeli "dane". Upewniam się też, że jesteśmy podpięci do właściwego klastra:
psql
select * from dane;
show DATA_DIRECTORY;


Komentarze (0)
Brak komentarzy...