
Po instalacji pliki klastra będą rozłożone w dwóch lokalizacjach. Osobno- binaria i osobno PGDATA - czyli katalog, w którym są np. pliki danych czy pliki konfiguracyjne. W domyślnej konfiguracji dla Ubuntu położenie plików jest następujące:
Katalog z binariami: /usr/lib/postgresql/15/bin/
Katalog domowy postgresa: /var/lib/postgresql
W domyślnej konfiguracji dla CentOSa położenie plików jest następujące:
Katalog z binariami: /usr/pgsql-15/bin/
Katalog domowy postgresa: /var/lib/pgsql
W ramach kursu tworzyliśmy naszą PGDATA w:
Katalog domowy postgresa: /data_pg/
W katalogu inicjalizacji klastra - czyli naszej PGDATA- znajdziemy wszystkie pliki konfiguracyjne i pliki danych niezbędne do działania klastra. Zobaczmy, co znajduje się w PGDATA. Zawartość tego katalogu powinna się prezentować w ten sposób:
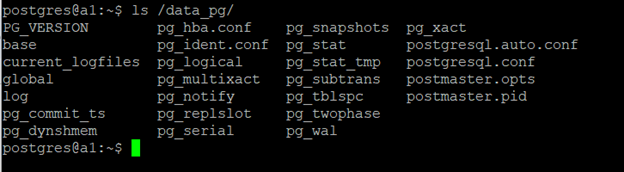
Co znajdziemy w PGDATA? Najpierw pliki:
| Nazwa pliku | Opis |
|---|---|
| pg_hba.conf | Plik zawierający ustawienia dotyczące tego, z jakich hostów/sieci można łączyć się z klastrem oraz jakiego rodzaju uwierzytelniania to wymaga. |
| postgresql.conf | Główny plik konfiguracyjny klastra. |
| postgresql.auto.conf | Plik konfiguracyjny zawierający ustawienia wprowadzone komendą: "alter system". Od wersji 9.6. |
| postmaster.opts | Plik zawierający opcje wiersza poleceń, które są implementowane podczas startu procesu postmaster. |
| postmaster.pid | Zawiera identyfikator systemowego procesu postmaster. Istnieje tylko wtedy, gdy serwer działa lub jego działanie zostało przerwane w wyniku awarii. |
| pg_ident.conf | Pozwala mapować użytkowników systemowych na bazodanowych. |
| PG_VERSION | Zawiera informacje o wersji klastra PostgreSQL. |
Następnie katalogi:
| Nazwa katalogu | Opis |
|---|---|
| base | Główny katalog danych. Każda baza danych posiada swój katalog danych, w którym przechowywane są pliki tabel i innych obiektów. Katalogi z plikami danych poszczególnych baz będą podkatalogami tego katalogu. Każda baza będzie posiadała swój podkatalog na pliki o nazwie odpowiadającej OID bazy. |
| global | Pliki danych tabel klastra bazy danych, tj. słowników niezwiązanych z konkretną bazą a z klastrem. Na przykład pg_database - lista baz danych. |
| pg_wal | Pliki WAL (Write Ahead Log). |
| log | Katalog zawierający logi klastra (w starszych wersjach pg_xlog). |
| pg_commit_ts | Zawiera informacje o wystąpieniach commitów. Aby ten katalog był uzupełniany, trzeba jeszcze włączyć parametr track_commit_timestamp. |
| pg_logical | Dane związane z replikacją logiczną (wprowadzone od wersji 9.4). |
| pg_notify | Katalog wykorzystywany w systemie powiadomień i subskrypcji (zachęcam do zapoznania się z funkcją pg_notify). |
| pg_serial | Zawiera informacje na temat zatwierdzonych serializowanych transakcji. |
| pg_stat | Trwałe pliki systemu statystyk. |
| pg_subtrans | Pliki statusu podtransakcji. |
| pg_twophase | Status zatwierdzania dwufazowego lub przygotowanej transakcji. Zachęcam do zapoznania się z komendą: „PREPARE TRANSACTION”. |
| current_logfiles | Zawiera informację o aktualnym pliku, do którego zrzucane są logi. |
| pg_dynshmem | Zawiera pliki wykorzystywane przez system zarządzania pamięcią. |
| pg_multixact | Pliki statusu blokad na poziomie wierszy. |
| pg_replslot | Dane potrzebne do replikacji. |
| pg_stapshots | Wyeksportowane snapshoty (z pg_dump). |
| pg_stat_tmp | Tymczasowe pliki systemu statystyk. |
| pg_tblspc | Łącza do zewnętrznych przestrzeni tabel. |
| pg_xact | pg_xact Logi metadanych transakcji. |
Sprawdźmy też, co znajduje się w katalogu z binariami:
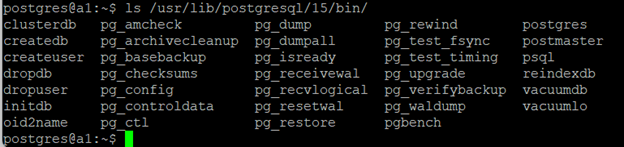
| Plik | Opis |
|---|---|
| clusterdb | Narzędzie do reklastrowania sklastrowanych tabel. Odnajduje tabele, które zostały sklastrowane i reklastruje je z użyciem indeksu wykorzystanego pierwotnie. |
| createdb | Służy do tworzenia baz danych, choć można użyć komendy: CREATE DATABASE. |
| createuser | Służy do tworzenia użytkowników, choć można użyć komendy: CREATE USER. |
| dropdb | Służy do kasowania baz danych, choć można użyć komendy: DROP DATABASE. |
| dropuser | Służy do kasowania użytkowników, choć można użyć komendy: DROP USER. |
| initdb | Skrypt inicjalizujący klaster PostgreSQL tworzący wszystkie niezbędne pliki w PGDATA. |
| pg_archivecleanup | Bardzo przydatne narzędzie! Służy do zarządzania zarchiwizowanymi plikami WAL. Można je wykorzystać do usuwania plików WAL starszych niż np. właśnie zrobiony backup, ale też do kasowania niepotrzebnych już plików WAL serwera replikującego. |
| pg_basebackup | Narzędzie pozwalające wykonać backup klastra. Wykorzystywane jest też do stworzenia duplikatu klastra na potrzeby replikacji. |
| pgbench | Benchmark dla PostgreSQL |
| pg_checksums | Dostępne od wersji 12! Służy do wyliczania sum kontrolnych wykorzystywanych do wykrywania uszkodzeń danych. |
| pg_config | Wyświetla informację o podstawowych konfiguracjach – położenie katalogu z binariami, wersji serwera etc. |
| pg_controldata | Wyświetla podstawowe informacje kontrolne o klastrze. |
| pg_ctl | Zatrzymuje i uruchamia klaster PostgreSQL. Umożliwia też przeładowanie konfiguracji. |
| pg_dump | Pozwala wykonać eksport wskazanej bazy danych do pliku SQL. |
| pg_dumpall | pg_dumpall Pozwala wykonać eksport wszystkich baz danych do pliku SQL. |
| pg_isready | Narzędzie do sprawdzania, czy da klaster akceptuje połączenia. |
| pg_receivewal | Służy do strumieniowego przekazywania wpisów WAL w replikacji (od wersji 10). |
| pg_resetwal | Służy do resetowania plików WAL i niektórych parametrów zawartych w pg_control. Używany w przypadku uszkodzenia danych. |
| pg_restore | Służy do odtwarzania bazy danych na podstawie zrzutów produkowanych przez pg_dump. |
| pg_rewind | Służy do synchronizacji klastra z inną kopią klastra. Wykorzystywany np. do przywracania serwera master (w replikacji) po jego awarii. |
| pg_test_fsync | Narzędzie używane przy zmianie wal_sync_method. |
| pg_test_timing | Służy do mierzenia narzutu obciążenia. Wykonuje wielokrotne wywołanie funkcji systemowej i zwraca histogram z informacją, ile razy udało się tę czynność wykonać w jakim czasie. |
| pg_upgrade | Służy do aktualizacji plików danych klastra przy jego upgrade. |
| pg_verifybackup | Od wersji 13! Służy do sprawdzania integralności kopii zapasowych wytworzonych przy użyciu pg_basebackup. |
| pg_waldump | Służy do przeglądania zawartości plików WAL. |
| psql | Prosty klient bazodanowy. |
| reindexdb | Służy do reindeksowania bazy danych. Zamiast niego można użyć komendy: REINDEX. |
| vacuumdb | Służy do wykonywania vacuum na bazach danych – oczyszczania z pozostałości po transakcjach. Zamiast niego można użyć komendy :VACUUM. |


Komentarze (0)
Brak komentarzy...