
Jeśli PostgreSQL nie uruchamia się bądź pojawiają się jakieś błędy, pierwsze miejsce, które powinniśmy sprawdzić, to logi serwera PostgreSQL. Zajmiemy się więc teraz konfiguracją tego, gdzie i w jakim formacie logi te będą wyrzucane.
W tym celu musimy omówić kilka istotnych parametrów. Plik konfiguracyjny, w którym znajdziemy ustawienia parametrów, nazywa się "postgresql.conf" i mieści się w katalogu instalacji klastra PostgreSQL - tam, gdzie między innymi pliki danych. W naszym przypadku przyjmujemy, że katalog instalacji klastra (czyli PGDATA) to /data_pg.
Pierwszym parametrem który będziemy musieli przestawić będzie "logging_collector" którego włączenie spowoduje dodatkowe przekierowanie strumienia loga do pliku tekstowego w PGDATA. Zmiana parametru "logging_collector" będzie wymagała restartu klastra. Zmiana pozostałych- tylko przeładowania konfiguracji.
Aby sprawdzić aktualne ustawienie dowolnego parametru, należy zalogować się z poziomu użytkownika systemowego postgres do psql i zastosować komendę: "show nazwa_parametru":
psql
show logging_collector;
Jeśli nie mamy dodanych binarek PostgreSQL do PATHa i system zgłosi, że nie wie, co to "psql", należy użyć ścieżki bezwzględnej do psql:
/usr/lib/postgresql/15/bin/psql
show logging_collector;
Aby zmienić parametr "logging_collector", musimy zalogować się z poziomu użytkownika systemowego postgres do psql, wykonać komendę: "ALTER SYSTEM", wyjść z psql i zrestartować cały klaster. Można też modyfikować bezpośrednio plik postgresql.conf znajdujący się w PGDATA.
psql
alter system set logging_collector=true;
\q
pg_ctl restart
Jeśli nie mamy dodanych binarek PostgreSQL do PATHa i ustawionego katalogu dla PGDATA, możemy użyć ścieżek bezwzględnych do wykorzystanych binarek i wskazać katalog PGDATA za pomocą przełącznika -D:
/usr/lib/postgresql/15/bin/psql
alter system set logging_collector=true;
\q
/usr/lib/postgresql/15/bin/pg_ctl -D /data_pg restart
Zmiana dowolnego z pozostałych parametrów (opisanych tu, związanych z logowaniem) wymaga tylko przeładowania konfiguracji. Logujemy się z poziomu użytkownika systemowego postgres do psql, wykonujemy komendę: "ALTER SYSTEM" i przeładowujemy konfigurację.
psql
alter system set log_directory='logi';
select pg_reload_conf();
Warto wiedzieć, że zmiana parametrów przez "ALTER SYSTEM" powoduje dodanie nowego wpisu do pliku postgresql.auto.conf. Plik ten jest czytany (razem z postgresql.conf i pg_hba.conf) przy przeładowaniu konfiguracji i starcie klastra. Ponieważ plik postgresql.auto.conf jest czytany po postgresql.conf, to ustawienia w postgresql.auto.conf nadpisują ustawienia postgresql.conf. Inaczej mówiąc, cokolwiek ustawimy przez "ALTER SYSTEM", będzie to nadpisywało ustawienia tego samego parametru bezpośrednio w pliku postgresql.conf.
Jest to parametr typu boolean - przyjmuje wartości true/false/on/off/t/f/1/0. Włączenie tego parametru powoduje uruchomienie procesu tła, który odpowiada za przekierowanie logów( lecących domyślnie do stderr w Ubuntu ) do plików logów PostgreSQL. W przypadku włączenia tworzony jest katalog w położeniu i nazwie określonych w parametrze "log_directory" i w nim znajdą się pliki logów. Domyślnie parametr "log_directory" ustawiony jest na wartość "log", czyli logi znajdują się w podkatalogu "log" katalogu PGDATA. Zmiana "logging_collector" wymaga restartu klastra.
Domyślną wartością dla Ubuntu jest off. Domyślną wartością dla CentOS jest on. W przypadku Ubuntu logi lecą do /var/log/postgresql/. W przypadku CentOs logi domyślnie znajdą się w podkatalogu "log" umiejscowionym w PGDATA.
Na potrzeby testowania pozostałych ustawień opisanych w tym rozdziale należy ustawić ten parametr na on.
Parametr ten określa katalog, w którym będą powstawać pliki logów PostgreSQL. Domyślne ustawienie:
log_directory='log'
Jako wartość możemy podać zarówno ścieżkę bezwzględną jak i względną wobec PGDATA (katalog instalacji klastra). Domyślnie pliki logów będą powstawały w katalogu "log" w PGDATA. Jeśli zamierzamy ustawić ścieżkę bezwzględną, to należy pamiętać, by użytkownik systemowy "postgres" miał uprawnienia do pisania w tym katalogu.
Zmiana "log_directory" wymaga tylko przeładowania ustawień.
PostgreSQL wspiera kilka metod logowania wiadomości serwera, między innymi stderr, csvlog, syslog. Domyślna wartość to "stderr". Jeśli chcemy, by logi były dodatkowo zapisywane w pliku csv (np. w celu późniejszego importu do bazy i analizy), musimy zmodyfikować ustawienie tego parametru na taką wartość:
log_destination='stderr,csvlog'
Zmiana "log_directory" wymaga tylko przeładowania ustawień.
Parametr określa nazwę pliku loga. Domyślna jego wartość dla Ubuntu:
"postgresql-%Y-%m-%d_%H%M%S.log"
Nazwa loga będzie zawierała datę i czas powstania loga.
Domyślna wartość dla CentOS:
"postgresql-%a.log"
Nazwa loga będzie zawierała skróconą nazwę dnia tygodnia.
Kolejny plik będzie powstawał po upływie czasu określonego w parametrze "log_rotation_age", którego domyślną wartością jest 1 doba.
W nazwie pliku loga możemy stosować wszystkie znaczniki strftime. Listę dostępnych znajdziemy np. tutaj: https://strftime.org/
Zmiana "log_filename" wymaga tylko przeładowania ustawień.
Parametr określa maksymalny czas, po jakim tworzony jest nowy plik logu. Domyślną wartością dla tego parametru jest "1d", co oznacza jeden dzień. Jeśli podajemy wartość bez jednostki, np. tak:
log_rotation_age=30,
będzie to oznaczało 30 minut, bo taka jest przyjmowana domyślna jednostka. Jeśli chcemy mieć nowy plik loga tworzony co 30 dni a nie minut, to musimy dodać literkę "d":
log_rotation_age=30d
Wartość domyślna (jedna doba) jest dobra dla środowisk produkcyjnych. Dla testów wydajnościowych warto ustawić na 1 godzinę. Parametr ten możemy przestawić na zero, powodując wyłączenie nadpisywania logów:
log_rotation_age=0
Zmiana "log_filename" wymaga tylko przeładowania ustawień.
Parametr zbliżony do "log_rotation_age". Dotyczy jednak wielkości logów. Możemy za jego pomocą spowodować, że nowy log będzie tworzony po przekroczeniu przez loga określonej wielkości. Domyślnie parametr ten ustawiony jest na 10MB. Podając wartość liczbową większą od 0, podajemy wartość wyrażoną w kB. Możemy ją ustawić np. tak:
log_rotation_size=1024
lub podając jednostkę:
log_rotation_size='1MB'
co będzie oznaczało w obu przypadkach, że log zostanie nadpisany, gdy osiągnie wielkość 1MB.
Zmiana "log_rotation_size" wymaga tylko przeładowania ustawień.
Określa poziom logowania, czyli co ma być rejestrowane w logu. Domyślnym ustawieniem jest "warning", ale możemy ten parametr przestawić w ten sposób:
log_min_messages=info
Poniżej lista dostępnych trybów. Każdy poziom obejmuje również rejestrację z wszystkich wyższych poziomów:
| Poziom | Opis |
|---|---|
| PANIC | Wpisy o krytycznych błędach powodujących przerwanie działania klastra |
| FATAL | Zdarzenia typu przerwanie jakiegoś procesu w sposób nieplanowany np przerwanie sesji wykonującej jakieś działanie. |
| LOG | Informacje takie jak nawiązywanie nowego połączenia, czy kończenie połączenia (ale tylko jeśli ustawimy log_connections i log_disconnections). |
| ERROR | Błędy spowodowane przez aplikacje. Na przykład próba dodania wiersza do tabeli z naruszeniem klucza głównego, czy próba odczytu danych z nieistniejącej tabeli. |
| WARNING | Ostrzeżenia od PostgreSQL które mogą być potencjalnie niebezpieczne. Przykładowo informacja o zbyt często pojawiających się checkpointach. |
| NOTICE | Informacje które mogą być użyteczne dla użytkowników - np. wywołane przez RAISE NOTICE w funkcjach plpgsql. |
| INFO | Powoduje logowanie dodatkowych informacje do operacji wywołanych przez użytkownika, np. poprzez dodanie “VERBOSE” do operacji VACUUM. Sam VACUUM nie zapisze się w logu, ale VACUUM VERBOSE zwróci szczegółowe informacje do terminala i do pliku loga. |
| DEBUG1-DEBUG5 | Informacje związane z debugowaniem samego PostgreSQL. |
Zmiana "log_min_messages" wymaga tylko przeładowania ustawień.
Parametr ten umożliwia rejestrowanie w logach informacji o wszystkich zapytaniach trwających dłużej niż czas określony w tym parametrze. Domyślną jednostką tego parametru są milisekundy. Możesz mu ustawić jakąś wartość by wyłapywać zapytania które warto poddać optymalizacji. Domyślna wartość tego parametru to -1, czyli logowanie takich zapytań jest wyłączone. Wartość 0 spowoduje rejestrowanie wszystkich zapytań, w tym zapytań do słowników systemowych, towarzyszących każdemu zapytaniu - więc nie warto tego robić, ponieważ log będzie szybko zapełniany zbędnymi wpisami. Warto ustawić na jakąś rozsądną wartość, np zapytania trwające powyżej 1000ms.
Możesz tę wartość ustawić podając w milisekundach np:
log_min_duration_statement=1000
Lub podając jednostkę:
log_min_duration_statement=1s
albo:
log_min_duration_statement=1min
Zmiana "log_min_duration_statement" wymaga tylko przeładowania ustawień.
Parametr ten umożliwia rejestrowanie w logach informacji o operacjach autovacuum trwających dłużej niż czas określony w tym parametrze.Domyślna wartość tego parametru to -1, czyli logowanie operacji autovacuum jest wyłączone. Wartość 0 spowoduje rejestrowanie wszystkich operacji autovacuum.
Możesz tę wartość ustawić podając w milisekundach np:
log_autovacuum_min_duration=1000
Lub podając jednostkę:
log_autovacuum_min_duration=1s
albo:
log_autovacuum_min_duration=10min
Zmiana "log_autovacuum_min_duration" wymaga tylko przeładowania ustawień.
Parametr ten jest domyślnie włączony i powoduje rejestrowanie wszystkich zdarzeń checkpoint. Wraz z informacją o samym fakcie wystąpienia checkpointa otrzymamy też informacje o czasie jego trwania, a także ilości zapisanych w jego ramach danych. Możesz pozostawić go włączonego:
log_checkpoints=on
lub wyłączyć:
log_checkpoints=off
Zmiana "log_checkpoints" wymaga tylko przeładowania ustawień.
Parametr ten umożliwia rejestrowanie w logu wszystkich zdarzeń nawiązania połączenia z klastrem. Rejestrowany jest również adres IP hosta z którego połączenie jest nawiązywane, użytkownik, baza danych i nazwa aplikacji. Domyślnie parametr ten jest wyłączony. Możesz go włączyć:
log_connections=on
lub wyłączyć:
log_connections=off
Zmiana "log_connections" wymaga restartu klastra.
Parametr ten umożliwia rejestrowanie zakończenie trwania połączenia do klastra. Rejestrowany jest adres IP hosta z którego było to połączenie, użytkownik, baza danych, nazwa aplikacji i czas trwania połączenia. Domyślnie parametr ten jest wyłączony. Możesz go włączyć:
log_disconnections=on
lub wyłączyć:
log_disconnections=off
Zmiana "log_disconnections" wymaga restartu klastra.
Pozwala skonfigurować prefiks każdej linii logu. Każda linia logu będzie miała format ustawiony przez ten parametr. Warto rozszerzyć sobie standardowe ustawienie o dodatkowe taki, ponieważ domyślnie logowany będzie tylko identyfikator procesu i timestamp (czyli domyślnie jest %m [%p]).Musimy pamiętać, że nie wszystkie tagi będą zawsze uzupełniane - np. w przypadku procesów wewnętrznych. Nierozpoznane tagi będą ignorowane. Dostępne tagi:
| Symbol | Znaczenie |
|---|---|
| %a | Nazwa aplikacji | %u | Nazwa użytkownika |
| %d | Nazwa bazy danych |
| %r | Nazwa zdalnego hosta lub jego IP oraz port. |
| %h | Nazwa zdalnego hosta lub jego IP. |
| %b | Rodzaj backendu |
| %p | ID procesu |
| %t | Timestamp bez milisekund |
| %m | Timestamp z milisekundami |
| %n | Timestamp z milisekundami (UNIX epoch) |
| %i | Typ komendy |
| %e | Kod błędu SQLSTATE |
| %c | ID sesji |
| %l | Numer linii loga |
| %s | Timestamp rozpoczęcia procesu |
| %v | ID transakcji wirtualnej |
| %x | ID transakcji |
Przykładowe ustawienie poniżej, moim zdaniem w miarę wystarczające. Daje nam ono informację o nazwie aplikacji, nazwie hosta, bazy danych, której log dotyczy, użytkownika, który spowodował powstanie loga, id sesji, id procesu systemowego i timestampie zdarzenia:
log_line_prefix='%m [%p]:[%l] user=%u,db=%d,app=%a'
Zmiana "log_line_prefix" wymaga tylko przeładowania ustawień.
Parametr log_lock_waits powoduje rejestrowanie w logu transakcji które blokują inne transakcje przez czas określony w parametrze deadlock_timeout. Parametr log_lock_waits jest domyślnie wyłączony. Możesz go włączyć:
log_lock_waits=on
lub wyłączyć:
log_lock_waits=off
Zmiana "log_lock_waits" i "deadlock_timeout" wymaga tylko przeładowania ustawień.
Pozwala określić jakie operacje na danych i strukturach będą logowane. Możemy mu ustawić "none" (tak jest domyślnie) - czyli nic nie jest logowane (chyba że wpis do loga będzie wynikał z log_min_duration_statement, log_lock_waits lub log_temp_files). "ddl" - czyli wszystkie operacje tworzące, zmieniające czy kasujące struktury danych. "mod" - czyli operacje zmieniające dane ale nie struktury danych. "all" - wszystkie operacje. Możesz go ustawić w ten sposób:
log_statement='ddl'
Zmiana "log_statement" wymaga tylko przeładowania ustawień.
Pozwala rejestrować w logach wszystkie zdarzenia które spowodowały tworzenie plików tymczasowych, takie jak sortowanie, hashowanie czy grupowanie. Pomaga nam znaleźć zapytania warte optymalizacji. Domyślną wartością tego parametru jest -1, czyli rejestracja jest wyłączona. Wartość 0 spowoduje zarejestrowanie wszystkich powstających plików tymczasowych. Wartość większa od 0 określa wielkość pliku tymczasowego wyrażonego w kilobajtach powyżej której fakt tworzenia pliku tymczasowego zostanie odnotowany. Możesz go ustawić np. w ten sposób:
log_temp_files=1024
Zmiana "log_temp_files" wymaga tylko przeładowania ustawień.
Domyślny format logu jest z reguły niewystarczający do analizy danych w nich zawartych jeżeli nie mamy dobrej znajomości linuksowych narzędzi do parsowania plików teksowych, takich jak grep czy awk. W domyślnej konfiguracji logi zrzucane są do pliku tekstowego, który nadaje się do podglądania pojawiających się komunikatów o błędach etc, ale nie pozwalają np. wyłapać wszystkich wpisów dotyczących długo trwających zapytań. Znalezienie wszystkich takich wpisów w zwykłym pliku tekstowym wymagałoby napisania jakiegoś parsera. Mamy jednak możliwość rejestrowania logów do pliku CSV, który następnie możemy załadować do tabeli. Dzięki temu będziemy mogli przeszukiwać logi za pomocą SQL!
Przede wszystkim musimy spowodować, żeby logi zaczęły być rejestrowane do pliku CSV. W tym celu modyfikujemy parametr "log_destination". Możemy zmienić go w pliku "postgresql.conf" lub za pomocą "alter system...". Trzeba tylko pamiętać o przeładowaniu konfiguracji za pomocą pg_reload_conf(). Jego wartość powinna wyglądać tak:
log_destination='stderr,csvlog'
Osiągamy to na przykład tak:
psql
alter system set log_destination='stderr,csvlog';
select pg_reload_conf();
Dodajemy frazę "csvlog", domyślnie jest tylko "stderr", by nie nadpisać stderr, a dodać frazę csvlog.
Po tej operacji w naszym katalogu z logami powinien znaleźć się dodatkowy plik z rozszerzeniem "csv":

Wpisy w tym pliku będą miały stały format prefiksu loga. Ustawienie "log_line_prefix" nie ma na niego wpływu. Wynika to z tego, że załadujemy ten log do tabeli, która ma z góry zdefiniowany format i dane muszą do tego formatu pasować.
Poniżej komenda tworząca tabelę, do której będziemy ładować dane.Należy pamiętać, że między wersjami struktura tej tabeli będzie różna i dane mogą nie pasować do tabeli. Poniższy przykład dotyczy wersji 15. Jeśli korzystamy z innej wersji, trzeba odnaleźć właściwą strukturę w dokumentacji.
Zalogujemy się do psql z poziomu użytkownika systemowego postgres i stworzymy tę tabelę:
CREATE TABLE postgres_log
(
log_time timestamp(3) with time zone,
user_name text,
database_name text,
process_id integer,
connection_from text,
session_id text,
session_line_num bigint,
command_tag text,
session_start_time timestamp with time zone,
virtual_transaction_id text,
transaction_id bigint,
error_severity text,
sql_state_code text,
message text,
detail text,
hint text,
internal_query text,
internal_query_pos integer,
context text,
query text,
query_pos integer,
location text,
application_name text,
backend_type text,
leader_pid integer,
query_id bigint,
PRIMARY KEY (session_id, session_line_num)
);
Do załadowania tej tabeli posłużymy się poleceniem "copy". Wskazujemy tabelę docelową oraz plik, który ma zostać załadowany. Z poziomu psql wywołujemy (oczywiście zmieniając nazwę pliku loga):
copy postgres_log from '/data_pg/log/postgresql-2023-08-16_000000.csv' with csv;
Po tej czynności w bazie "postgres", w schemacie public, w tabeli postgres_log znajdą się nasze logi. Sprawdzamy je:
\x
select * from postgres_log limit 1;Lub zmieniamy ustawienia pagera, wyłączając zawijanie wierszy i dodając ich numerację
\setenv PAGER 'less -S -N'
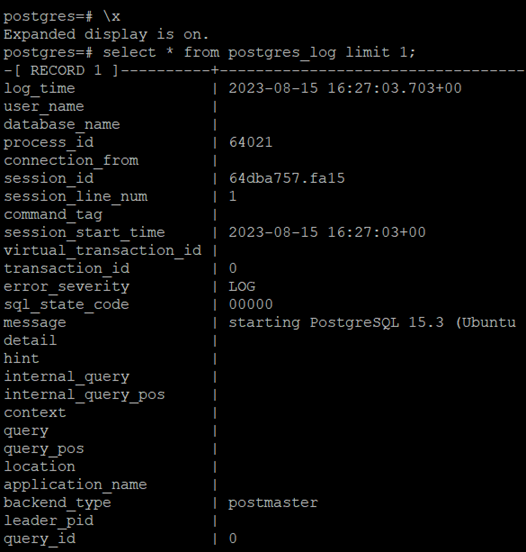
Możemy teraz użyć SQLa do przeszukiwania logów pod kątem interesujących nas informacji.
PostgreSQL umożliwia rejestrowanie nowo nawiązywanych sesji. Aby rejestrować nowe połączenia, będziemy musieli włączyć parametr "log_connections", a następnie zrestartować klaster (pg_reload_conf() nie przeładowuje tego parametru). W pierwszej kolejności z poziomu użytkownika systemowego postgres zmiana parametru za pomocą psql:
psql
alter system set log_connections=on;
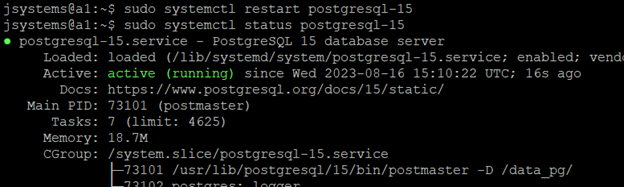
Po tej operacji cofamy się do poziomu użytkownika z prawami do sudo, restartujemy usługę i sprawdzamy jej status:
sudo systemctl restart postgresql-15
sudo systemctl status postgresql-15
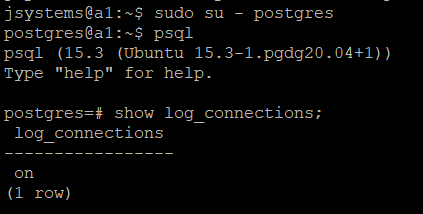
Wracamy do użytkownika systemowego postgres i sprawdzamy ustawienie parametru "log_connections":
psql
show log_connections;
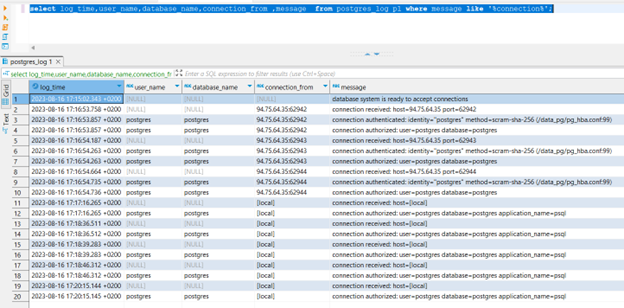
Po wykonaniu tej operacji parokrotnie zalogowałem się i wylogowałem z serwera, zarówno lokalnie jak i po sieci (wymagało to dodatkowych nieopisanych tutaj czynności - dostępem po sieci zajmiemy się nieco później). Następnie podłączyłem się do PostgreSQL (w tym przypadku za pomocą programu DBeaver) i wyświetliłem logi związane z połączeniami za pomocą zapytania:
select log_time,user_name,database_name,connection_from ,message from postgres_log pl where message like '%connection%';
Mój wynik:



Komentarze (1)
0
0
Ogólnie instukcje OK, ale na końcu z tym DBeaver zmyłka, bo powinno być wspomniane, aby uzyskać taki dostęp do testów z pytaniem SELECT trzeba przejść jeszcze 2 następne kroki (wraz pomocniczo z linkami do artykułów: Dostęp do klastra z sieci i połączenie za pomocą PGAdmin4 - oraz - Ustawianie hasła administratora i innych użytkowników +HotFix z PREWORK