
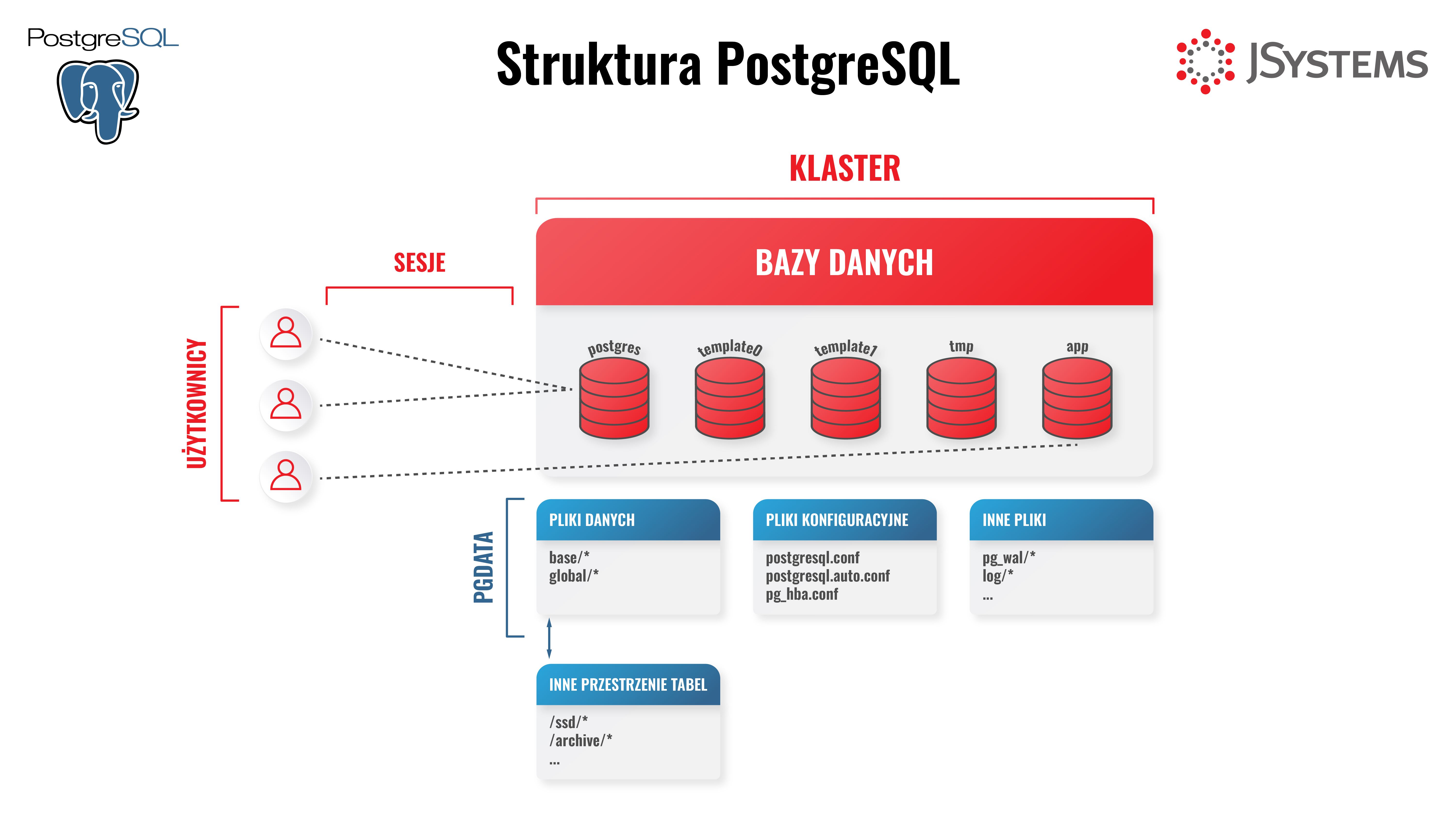
Pojedyncza instancja instalacji serwera PostgreSQL. Klaster zawiera wszystkie pliki niezbędne do działania serwera PostgreSQL. Są to pliki danych, pliki konfiguracyjne, a także inne pliki niezbędne do działania serwera np. pliki WAL.
Klaster zawiera w sobie bazy danych, przestrzenie tabel, schematy etc. Klaster ma wspólną konfigurację w plikach takich jak postgresql.conf, postgresql.auto.conf czy pg_hba. Ustawienia na tym poziomie dotyczą wszystkich baz danych.
Przestrzeń pamięci operacyjnej klastra jest współdzielona przez wszystkie zawarte w nim bazy danych. Wspólne są też procesy.
Fizyczne kopie zapasowe (zimne i gorące) robimy zawsze na poziomie klastra. Nie możemy zrobić fizycznej (w przeciwieństwie do logicznej) kopii zapasowej wybranej bazy danych.
Główny katalog klastra PostgreSQL. Znajdują się tu wszystkie pliki danych, pliki konfiguracyjne oraz wszelkie pliki niezbędne do działania klastra z wyłączeniem plików binarnych, które znajdują się w innej lokalizacji.
Baza danych to osobny zbiór danych w ramach klastra. Umożliwiają odseparowanie logiczne danych np. różnych systemów.
Bazy danych są strukturą logiczną, choć wiążą się ze strukturą fizyczną. Każda baza danych ma swój osobny katalog na serwerze. Dane pomiędzy poszczególnymi bazami danych są od siebie odseparowane fizycznie i logicznie. Niestety nie są na tyle niezależne jak np. w Oracle czy SQL Server, by można było osobno robić fizyczne kopie zapasowe i osobno przywracać bazy danych. Co prawda można wykonać eksport danych do pliku tekstowego za pomocą pg_dump, ale nie jest to kopia zapasowa w pełnym tego słowa znaczeniu i nie pozwala np. przywrócić bazy do wybranego punktu w czasie.
Przestrzenie tabel fizycznie są katalogami. Zakłada się je na przykład, by trzymać część danych na osobnym dysku. Robi się tak, kiedy chcemy rozłożyć obciążenie I/O na kilka dysków i dzięki temu poprawić wydajność. Możemy też wykorzystać osobne przestrzenie tabel, gdy kończy się miejsce na dysku zawierającym klaster PostgreSQL. W przestrzeniach tabel możemy umieszczać pojedyncze obiekty (tabele, indeksy etc.), ale też całe bazy danych.
Użytkownik to po prostu konto na które się logujemy. Umożliwia łączenie się do serwera bazodanowego i wykonywanie na nim operacji. Jeśli potrzebujemy konta które ma być właścicielem jakichś obiektów ale nikt nie powinien się na nie logować, tworzymy rolę - czyli użytkownika bez możliwości logowania.
Sesja to połączenie do bazy danych. Łącząc się do klastra zawsze łączymy się do wybranej bazy danych jako konkretny użytkownik. Każda sesja jest związana ze swoim procesem w systemie operacyjnym po stronie serwera baz danych.
PostgreSQL wywodzi się od Ingresa, systemu zarządzania bazami danych mającego swoje początki na Uniwersytecie Kalifornijskim Berkeley. Dlatego też wiele pojęć z którymi możemy spotkać się w dokumentacji Postgresa, bądź słuchając/czytając ludzi zajmujących się głównie postgresem, możemy usłyszeć nazwy niepokrywające się z pozostałymi systemami danych.
Pierwszy przykład to właśnie “tuple”, po polsku “krotka” czyli uporządkowana kolekcja stałych wartości lub inaczej tablica stałych wartości. A tak naprawdę “tuple” to po prostu wiersz w tabeli.
Tak samo jak w przypadku tuple, relacja to w języku naukowym to po prostu tabela. Warto o tym pamiętać, ponieważ nawet sam PostgreSQL się do tego w ten sposób odwołuje. Np. w widoku pg_class, wartość relkind wskazuje na typ obiektu. I tak kolejno: i = index, S = sequence, t = TOAST table, v = view, m = materialized view, c = composite type, f = foreign table, p = partitioned table, I = partitioned index i wreszcie r = table.
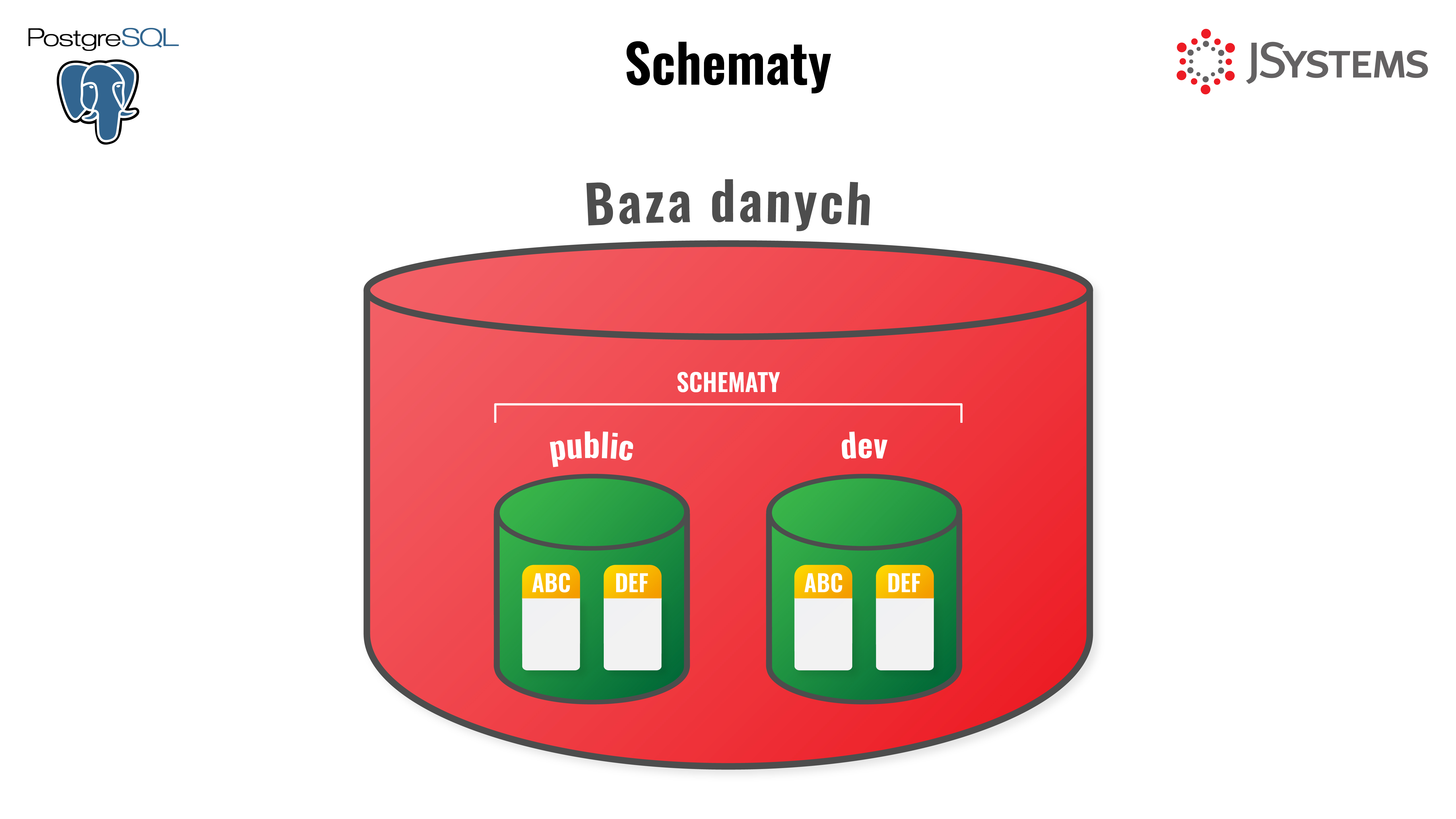
Bazy danych zawierają jeden lub więcej schematów, w których znajdują się obiekty bazodanowe. Podział na schematy nie wiąże się z podziałem fizycznym, jest to tylko podział logiczny. Umożliwiają posiadanie kilku tabel o tej samej nazwie, ale w różnych schematach. Pozwalają też łatwiej zarządzać obiektami bazy danych dzięki zorganizowaniu w podgrupy, a także zbiorowe nadawanie i odbieranie uprawnień do obiektów.
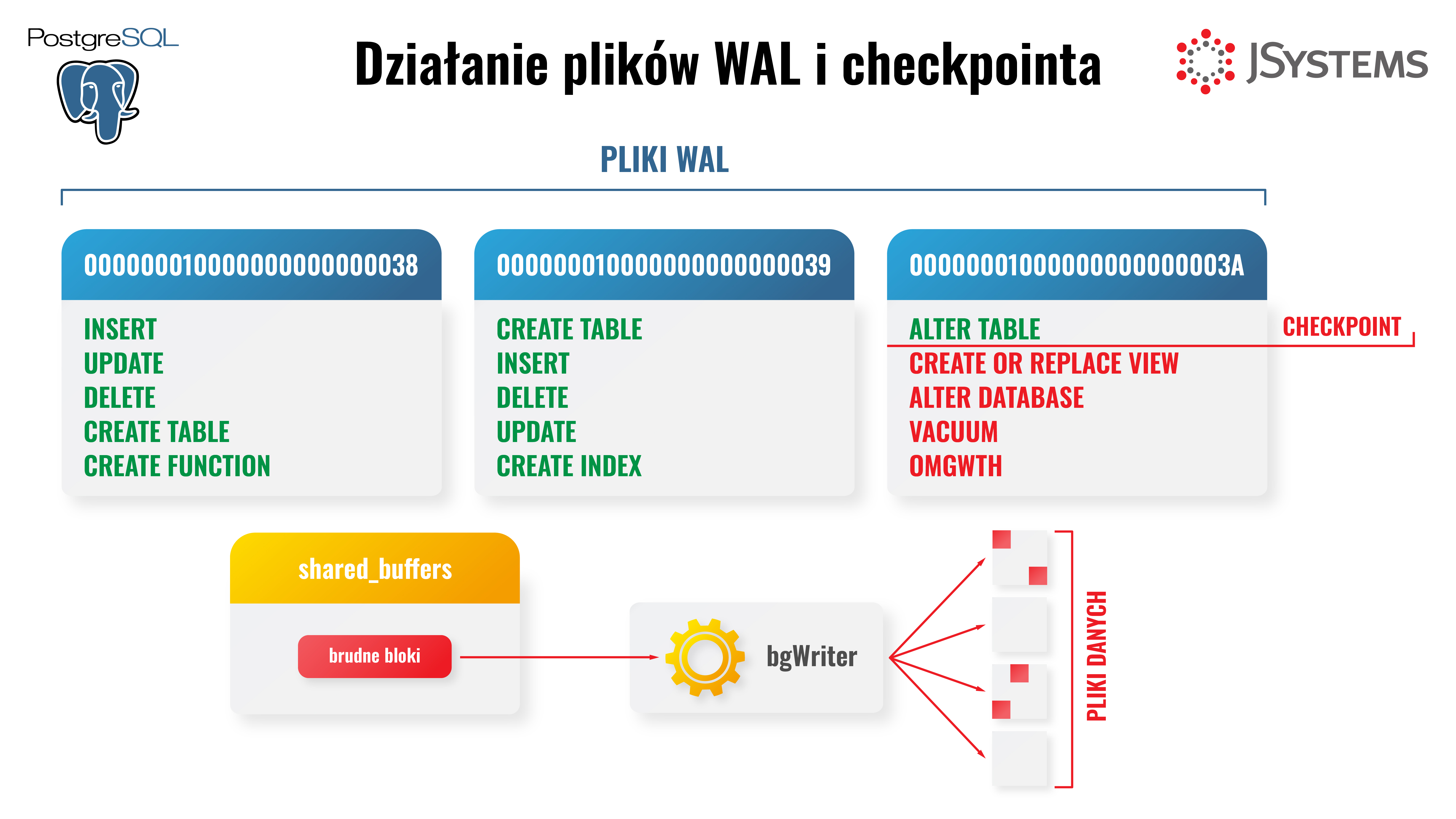
Zanim zmiany na danych zostaną wprowadzone do plików danych, odnotowywane są w plikach WAL. Zapis do plików WAL musi zawierać wszystko co potrzebne do powtórzenia operacji. Zapis do plików danych następuje w zdarzeniu “checkpoint”, wtedy utrwalane są w nich wszystkie brudne bloki – czyli zmiany które znajdują się tylko w plikach WAL, a nie zostały jeszcze zmienione na poziomie plików danych. Pliki WAL są niezbędne w sytuacji odtwarzania stanu klastra po ewentualnej awarii. W takiej sytuacji przy uruchamianiu serwer PostgreSQL odczytuje wpisy z plików WAL od ostatniego checkpointa i powtarza je, celem odtworzenia stanu klastra tuż przed awarią. Po takim awaryjnym odtworzeniu następuje automatyczny checkpoint.
W trakcie checkpointa następuje zapis wszystkich brudnych bloków do plików danych. W przypadku awarii PostgreSQL sprawdza punkt czasowy ostatniego checkpoint'a, by określić punkt, od którego ma rozpocząć odzyskiwanie REDO na podstawie plików WAL. Dzięki temu wie, od którego pliku WAL i jakiego offsetu w tym pliku ma rozpocząć odzyskiwanie.
Kopia klastra zawierająca pliki danych, pliki konfiguracyjne i inne pliki niezbędne do działania klastra. Taka kopia umożliwia odtworzenie tylko całego klastra, a nie pojedynczych baz danych.
Dzięki kopii fizycznej i plikom WAL możemy odtworzyć klaster do wskazanego punktu w czasie.
Takie kopie zapasowe tworzymy np za pomocą pg_basebackup.
To kopia zawierająca instrukcje tworzenia i wypełniania struktur bazodanowych, użytkowników etc. Dotyczy więc tylko logicznej struktury danych. Nie zawiera plików konfiguracyjnych klastra. Plikiem wynikowym może być plik SQL lub plik binarny. Nie współpracuje z plikami WAL, więc nie umożliwia odtworzenia klastra do wskazanego punktu w czasie. Pozwala tworzyć kopie zapasowe dla wybranych baz danych, ale także np dla wybranych tabel. Takie kopie zapasowe tworzymy za pomocą narzędzi pg_dump i pg_dumpall.
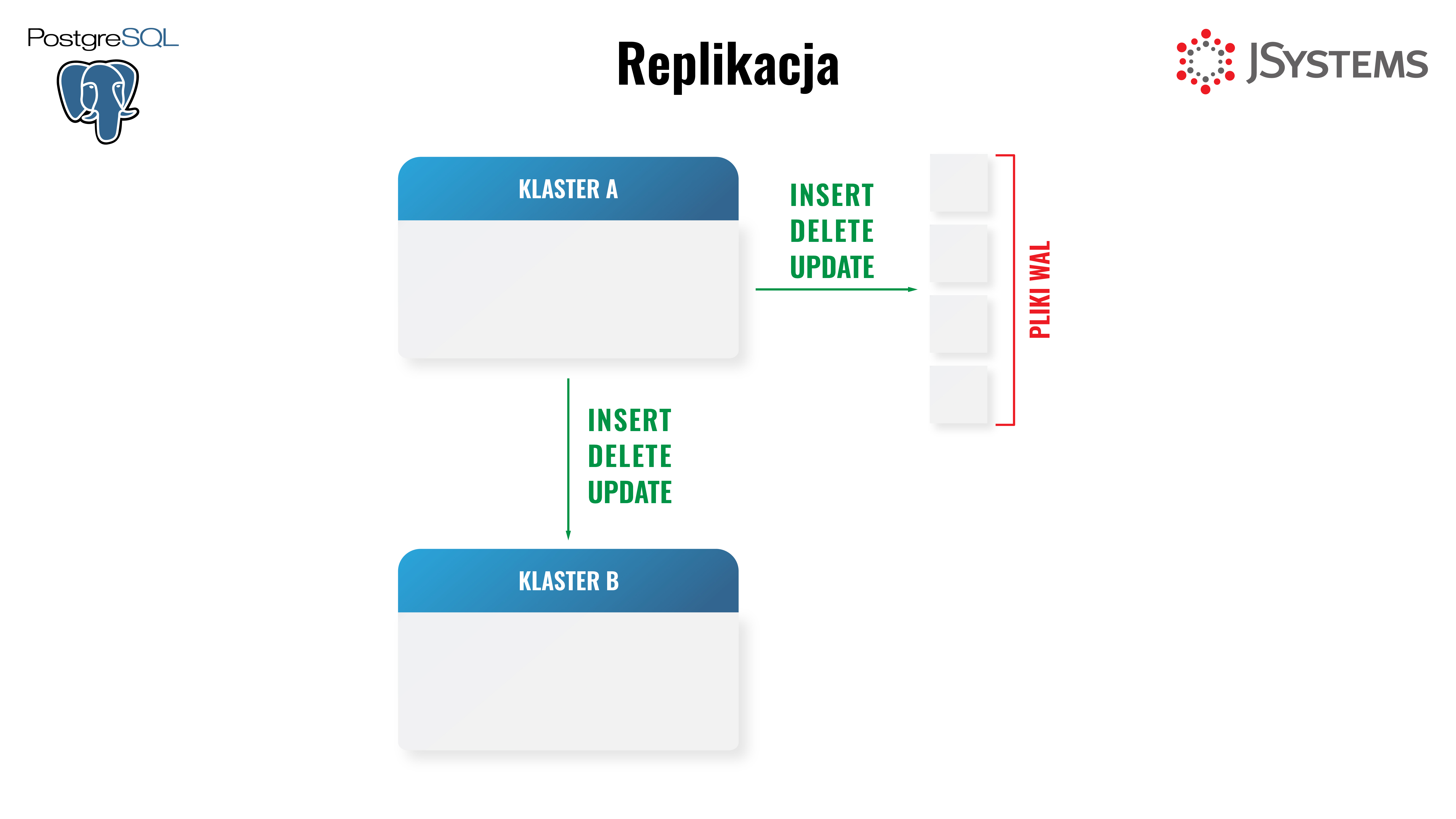
PostgreSQL umożliwia stworzenie repliki, czyli serwera będącego kopią serwera źródłowego zasilanego zmianami z serwera źródłowego. Dzięki temu, stan repliki cały czas pozostaje identyczny jak stan serwera master. Aby stworzyć replikę, najpierw tworzymy kopię serwera master na serwerze repliki, a następnie strumieniujemy wszystkie zmiany w plikach WAL z serwera master na serwer repliki. Serwer replikujący pozostaje w stanie tylko do odczytu. Posiadanie takiej repliki może być użyteczne gdy chcemy stworzyć osobny serwer na potrzeby analityczne - tak aby związane z tym obciążenie przenieść na replikę. Może też nam się przydać gdy coś się stanie z serwerem źródłowym. Możemy przełączyć replikę do trybu zapis-odczyt i dzięki temu może ona przejąć rolę serwera źródłowego.
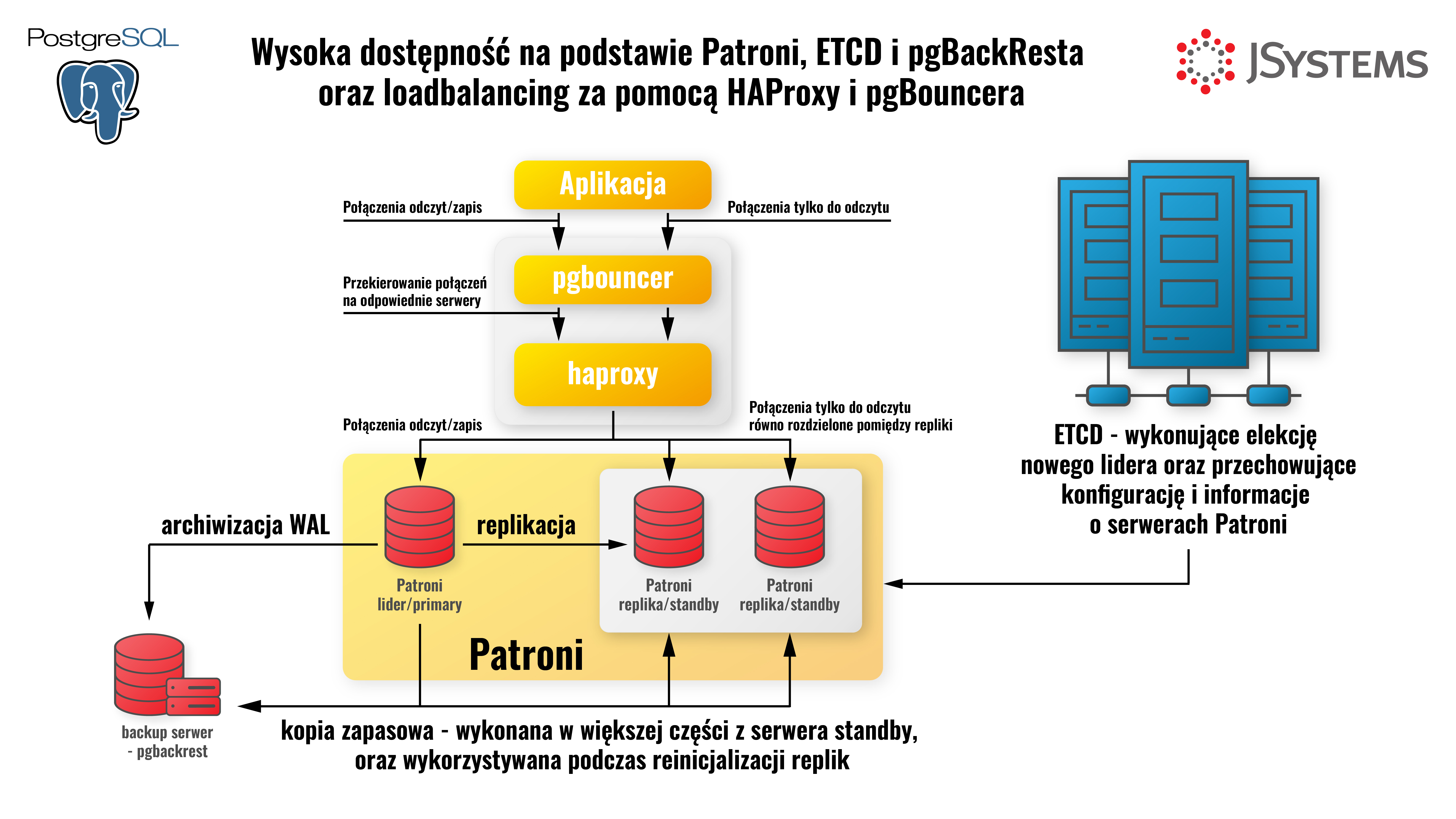
To zestaw technik wykorzystywanych w celu zapewnienia nieprzerwanego dostępu do aplikacji, w tym przypadku bazy danych Postgresql, nawet podczas awarii niektórych komponentów.
Dla baz danych, mechanizmy wysokiej dostępności zazwyczaj sprowadzają się do monitoringu statusu postgresa oraz w przypadku problemów z dostępnością wykonywania awaryjnego przerzucenia roli "primary", czyli serwera obsługującego operacje zapisu i odczytu, na replikę która do tej pory obsługiwała jedynie odczyt. Często stosuje się dodatkowy mechanizm "witness", czyli świadka, który jest niezależny od pozostałych serwerów bazodanowych, i może pomóc podjąć decyzję, czy aktualny serwer główny rzeczywiście przestał odpowiadać, czy to tylko tymczasowa przerwa w działaniu sieci pomiędzy serwerem głównym i repliką.
Popularnymi narzędziami stosowanymi w Postgresie do osiągnięcia wysokiej dostępności są np. Patroni oraz REPMGR.
A jeżeli już korzystamy z wysokiej dostępności, warto dodać też loadbalancing, czyli automatyczne rozrzucanie połączeń pomiędzy serwerami w klastrze HA w celu ogólnej poprawy wydajności klastra i przyspieszenia odpowiedzi z bazy. Drugim wartym dodania komponentem jest connection pooling, czyli mechanizm pozwalający na poprawę wydajności przy nawiązywaniu i zamykaniu połączeń poprzez utrzymywanie puli stałych otwartych połączeń, które mogą być naprzemiennie wykorzystywane przez różne połączenia z aplikacji. Oba te mechanizmy bardzo często implementuje się po stronie aplikacji, a jeżeli nie jest to możliwe, lub jest trudne do wykonania, dodaje się zewnętrzne narzędzia, takie jak HAProxy dla loadbalancingu oraz pgBouncer dla kolejkowania połączeń.


Komentarze (0)
Brak komentarzy...