Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!

[ Do realizacji przykładów z tego rozdziału potrzebujemy hostów 1 i 5. Przygotujmy je według instrukcji ]
To obecnie najpopularniejsze i najintensywniej rozwijane narzędzie do kopii zapasowych baz PostgreSQL. Celem projektu było stworzenie niezawodnego, skalowalnego i łatwego w użyciu narzędzia rozwijanego przez społeczność. Największym współtwórcą projektu jest Crunchy Data.
PgBackRest umożliwia stworzenie scentralizowanego serwera kopii zapasowych oraz archiwum dla plików WAL, dla wielu serwerów PostgreSQL jednocześnie. Każdy serwer posiada swoją "stanzę", najprościej mówiąc, własną konfigurację dla kopii zapasowych oraz własny katalog na zarchiwizowane WAL i - backupy. Pliki możemy zapisywać do kilku "repozytoriów" jednocześnie, na przykład backup serwer i magazyn danych w chmurze. Połączenie do serwera kopii zapasowych oraz pliki w repozytoriach mogą być zaszyfrowane.
Kopie zapasowe możemy wykonywać jako pełne, przyrostowe i różnicowe. Backup w opcji przyrostowej (incremental incr) wykonuje kopie tylko tych plików, które zostały zmienione od ostatniego backupu dowolonego typu, pełny, przyrostowy czy różnicowy. Kopia różnicowa - wykonuje kopię wszystkich plików, które zostały zmienione od ostatniej pełnej kopii zapasowej. Operacje na plikach WAL możemy ustawić jako asynchroniczne, co umożliwia dużo szybsze archiwizowanie i odzyskiwanie dzięki jednoczesnemu przetwarzaniu więcej niż jednego pliku WAL w tym samym momencie.
Pgbackrest może wykonywać kopie zapasowe z serwera standby. Przy odpowiedniej konfiguracji potrafi wykryć serwer standby i skopiować z niego większość plików, pobierając tylko te zmienione w czasie wykonywania kopii zapasowej z instancji primary, co dość znacznie może obniżyć obciążenie generowane przez kopie zapasowe na serwerze głównym.

Przed konfiguracją pgBackResta przygotujmy serwery, na których będziemy wykonywać przykłady zgodnie z instrukcją w rozdziale "Przygotowanie serwerów - Instalacja oprogramowania" na wybranym przez siebie systemie operacyjnym, Ubuntu 22.04 lub CentOS Stream 9. Serwery 1 i 5.
Upewnijmy się także, iż na wszystkich serwerach mamy tę samą wersję pgbackresta. Powinna być wszędzie taka sama, inaczej pgbackrest zwróci błąd o niekompatybilnej wersji przy próbie uruchomienia.
postgres@ubuntu:~$ pgbackrest version pgBackRest 2.48
Musimy też zmienić kilka parametrów w postgresie i zrestartować klaster, ponieważ niektóre ze zmienionych parametrów wymagają restartu postgresa (wykonujemy jako użytkownik systemowy postgres):
vi /data_pg/postgresql.conf
Ustawiamy parametry jak poniżej:
# adres IP na którym nasłuchuje postgres listen_addresses = '*' # włączenie archiwizacji plików WAL archive_mode = on # polecenie wykorzystywane do archiwizacji archive_command = '/usr/bin/pgbackrest --config=/etc/pgbackrest.conf --stanza=test archive-push %p' # polecenie umożliwiające pobranie plików WAL z archiwum przez replikę lub podczas # odtwarzania bazy z kopii zapasowej restore_command = '/usr/bin/pgbackrest --config=/etc/pgbackrest.conf --stanza=test --pg1-path=/data_pg archive-get %f %p' # limit procesów WAL sender, w tym przypadku nie są obowiązkowe, ale warto je dodać # jeżeli rozważamy w przyszłości replikację ponieważ ich zmiana wymaga restartu # klastra max_wal_senders = 5 # podobnie jak powyżej, nieobowiązkowo, ale warto dodać, zmiana wymaga restartu max_replication_slots = 5 # poziom logowania: minimal, replica, logical. Aby umożliwić odtwarzanie do # wybranego punktu w czasie, musimy wybrać replica lub logical. Minimal pozwala # tylko na przywrócenie danych do spójnego stanu po niespodziewanym zakończeniu # procesu postgresa wal_level = replica # wymuszenie archiwizacji plików WAL archive_timeout = 60 # przekierowanie wyjścia dla procesu postgresa do logu, zamiast do konsoli # na ubuntu jest domyślnie wyłączony, na centos włączony logging_collector = on
Po zmianie parametrów pamiętajmy o restarcie (wykonujemy jako użytkownik systemowy postgres)!
# dla Ubuntu /usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ restart # dla CentOS /usr/pgsql-15/bin/pg_ctl -D /data_pg/ restart
Wymagane parametry to archive_mode, archive_command, wal_level oraz archive_timeout. Pozostałe są wymagane tylko w przypadku, - jeśli chcielibyśmy w przyszłości dodać replikę bez potrzeby restartowania primary.
Archive_timeout ustawiamy na 60 (wartość określana w sekundach), ponieważ jest to domyślna wartość archive-timeouta w pgBackRescie. Dzięki temu wymusimy zmianę oraz archiwizację pliku WAL, jednocześnie poprawiając RPO do 60 sekund. Wynika to z tego, że w razie wypadku i nieplanowanego wyłączenia postgresa, czy nawet całego serwera, jeżeli nastąpiło to po 59 sekundach i 999 milisekundach do ostatniego zarchiwizowanego pliku WAL, lub w trakcie archiwizacji, będziemy cały ten czas stratni, a zaokrąglając, będzie to właśnie 60 sekund.
Następnie skonfigurujemy SSH bez hasła pomiędzy hostami.
Na wszystkich serwerach, które chcemy backupować, generujemy klucz rsa w celu konfiguracji automatycznej autoryzacji połączeń ssh z serwerów bazodanowych na serwer kopii zapasowych i odwrotnie. Na wszystkich hostach wykonujemy poniższe polecenia. Wszystko zostawiamy na domyślnych wartościach, a zapytani o hasło "Enter passphrase (empty for no passphrase)" pole zostawiamy puste i klikamy dwukrotnie Enter, aby zatwierdzić brak hasła (wykonujemy jako użytkownik systemowy postgres):
ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub
Następnie zawartość ~/.ssh/id_rsa.pub z serwera z bazą danych (host 1) (i ewentualnie hostów 2 i 3 w przypadku konfiguracji pod replikację) kopiujemy do ~/.ssh/authorized_keys na serwerze kopii zapasowych (host 5) i odwrotnie (czyli z 5 do pozostałych hostów). Pamiętajmy, - by wykonywać to, będąc zalogowanym jako użytkownik postgres po obu stronach:
vi ~/.ssh/authorized_keys
Następnie powinniśmy przetestować, czy połączenie działa i przy okazji dodać wpis do pliku ~/.ssh/known_hosts. Tutaj powinniśmy się zdecydować, w jaki sposób będziemy definiować serwery: w pliku konfiguracyjnym czy za pomocą nazwy hosta, czy adresu IP. Wpis w pliku "known_hosts" jest dodawany dla adresu, który podamy podczas połączenia, lub adresu IP, jeżeli łączyliśmy się za pomocą adresu IP. Możemy też dodać obie opcje. Pgbackrest podczas logowania bez hasła oczekuje, że wpis w known_hosts będzie już dodany - i może nie działać poprawnie, jeżeli będzie go brakowało.
# z serwera bazodanowego ssh postgres@<hostname lub adres IP serwera kopii zapasowych> # z serwera kopii zapasowych ssh postgres@<hostname lub adres IP serwera bazodanowego>
Konfiguracja po stronie serwera kopii zapasowych
Na serwerze backupów edytujemy plik /etc/pgbackrest.conf (jako użytkownik z uprawnieniami do sudo, nie jako postgres):
sudo vi /etc/pgbackrest.conf
Kopiujemy do niego poniższą konfigurację.
Aktualną zawartość pliku pgbackrest.conf podmień na poniższą (albo wykomentuj to co już się w nim znajduje). Przy wprowadzaniu danych do configa pamiętajmy o ustawieniu adresu IP serwera bazodanowego w parametrze pg1-host:
[test] pg1-path=/data_pg pg1-host=<IP lub nazwa hosta serwera bazy PostgreSQL> [global] repo1-path=/backups repo1-host-user=postgres repo1-retention-full=3 archive-timeout=60 start-fast=y spool-path=/var/spool/pgbackrest process-max=2 archive-async=y archive-get-queue-max=1GiB archive-push-queue-max=100GiB [global:backup] process-max=2 [global:restore] process-max=2 [global:archive-get] process-max=2 [global:archive-push] process-max=2
Wyjaśnienie do parametrów:
[test] to nazwa naszej jeszcze nieistniejącej stanzy.
pg1-path to ścieżka do katalogu z PGDATA, pg1-host to adres serwera z bazą danych. Analogicznie możemy dodać więcej serwerów, pg2-path, pg2-host, pg-3… itd.
pg1-host to adres serwera, na którym działa postgres. Analogicznie możemy dodać więcej serwerów, pg2-path, pg2-host, pg-3… itd.
[global] to ustawienia globalne, które dotyczą wszystkich stanz, możemy mieć więcej niż jedną stanzę na tym samym serwerze repozytorium.
repo1-path to ścieżka, gdzie przechowywane będą kopie zapasowe,
spool-path to katalog, w którym przechowywane są pliki wykorzystywane do archiwizacji oraz odzyskiwania asynchronicznego plików WAL.
Parametry process-max to maksymalna ilość współbieżnych procesów, które będą pracowały przy wykonywaniu kopii zapasowej, archiwizacji, itd.
Archive-get-queue-max określa, ile plików WAL zostanie pobranych do katalogu spool na serwerze bazodanowym przy odzyskiwaniu danych, przyspiesza to odzyskiwanie o tyle, że postgres normalnie pobiera log, odtwarza zmiany, pobiera kolejny, itd. Korzystając z opcji odzyskiwania asynchronicznego, możemy pobrać od razu większą liczbę plików WAL. Domyślnie postgres pobiera jeden WAL, odtwarza go, po czym pobiera kolejny, wszystko dzieje się za pomocą jednego wątku. Dzięki opcji odzyskiwania asynchronicznego możemy przygotować sobie kolejkę plików WAL na serwerze z bazą danych, a postgres będzie je tylko odtwarzał, posiadając je już na serwerze.
Parametr archive-push-queue-max określa górny limit plików w kolejce do archiwizacji, z ustawieniem jego wartości trzeba jednak uważać. Po osiągnięciu określonego limitu postgres próbujący zarchiwizować plik WAL, dostanie od pgBackResta informację, że plik został zarchiwizowany, po czym zostanie automatycznie usunięty, co uniemożliwi nam odzyskiwanie do punktu w czasie po osiągnięciu tego limitu. Z drugiej strony, zabezpieczy to nas przed zatrzymaniem postgresa w momencie zapełnienia dysku z plikami WAL.
Start-fast to parametr wymuszający wykonanie checkpointa w momencie rozpoczęcia backupu. Wymuszony checkpoint stara się zakończyć całą pracę tak szybko, jak to możliwe, podczas gdy zwykły stara się go rozłożyć w czasie (checkpoint_timeout * checkpoint_completion_target) w celu obniżenia obciążenia spowodowanego zapisywaniem wielu plików, jeżeli nie możemy sobie pozwolić na wymuszony checkpoint. Możemy ten parametr wyłączyć, wtedy pgBackRest po wywołaniu polecenia "backup" poczeka z rozpoczęciem kopii zapasowej na następny checkpoint wywołany przez timeout lub przekroczony max_wal_size i rozpocznie wykonywanie kopii zapasowej zaraz po nim.
Konfiguracja po stronie serwera bazodanowego
Konfigurację musimy wykonać również na każdym serwerze postgresa, który będziemy wykorzystywać do wykonywania kopii zapasowej lub który może archiwizować pliki WAL, np. serwery standby, na który możemy wykonać failover w przypadku problemów z primary.
Jako użytkownik z uprawnieniami sudo bądź root (jako użytkownik z uprawnieniami do sudo, nie jako postgres):
sudo vi /etc/pgbackrest.conf
Gdzie repo1-host to adres serwera repozytorium, repo1-host-user to użytkownik, który będzie wykorzystywany do połączenia ssh na serwer repo i który będzie właścicielem plików z backupami. repo1-path to z kolei miejsce przechowywania backupów.
[test] pg1-path=/data_pg [global] repo1-host=<IP serwera backupów lub nazwa hosta> repo1-host-user=postgres repo1-path=/backups archive-timeout=60 start-fast=y spool-path=/var/spool/pgbackrest process-max=2 [global:backup] process-max=2 [global:restore] process-max=2 [global:archive-get] process-max=2 [global:archive-push] process-max=2
Po konfiguracji pgBackResta musimy stworzyć katalogi wykorzystywane do przechowywania kopii zapasowych oraz archiwizacji asynchronicznej.
Na wszystkich serwerach z bazą danych tworzymy katalog "spool" dla pgbackresta (jako użytkownik z uprawnieniami do sudo, nie jako postgres). Katalog ten będzie wykorzystywany przy asynchronicznej archiwizacji i odtwarzaniu plików WAL. Zarówno podczas archiwizacji jak i odtwarzania - postgres korzysta tylko z jednego procesu, dlatego może kopiować tylko jeden plik naraz. Korzystając z archiwizacji asynchronicznej w pgbackrest, tworzymy pomocniczy katalog, w którym pgbackrest przechowuje informacje, jakie pliki WAL musi pobrać/zarchiwizować, które są aktualnie pobierane lub archiwizowane i które są już gotowe. Dzięki temu może pracować wielowątkowo na kilku plikach WAL jednocześnie, co znacznie zwiększa możliwości archiwizacji oraz przyspiesza odtwarzanie (wykonujemy jako użytkownik systemowy z prawami do sudo).
sudo mkdir -p /var/spool/pgbackrest sudo chown postgres: /var/spool/pgbackrest
A na serwerze repozytorium - (jako użytkownik z uprawnieniami do sudo, nie jako postgres):
sudo mkdir -p /backups && sudo chown postgres: /backups
W tym momencie powinniśmy być gotowi na stworzenie naszej stanzy. Na serwerze pgbackresta przełączamy się na użytkownika postgres i tworzymy stanzę:
sudo su - postgres pgbackrest --stanza test --log-level-console=detail stanza-create

Polecenie utworzyło strukturę katalogów w repo1-path na pliki WAL oraz kopie zapasowe dla stanzy "test", a także pliki archive.info i backup.info, w których znajdziemy informacje istotne dla pgBackResta dotyczące backupowanego klastra.
Po stworzeniu stanzy możemy sprawdzić, czy archiwizacja plików WAL działa poprawnie. Archive command już wcześniej ustawiliśmy w postgresie, więc wszystko powinno już być gotowe. Sprawdźmy to poniższym poleceniem. Wykonujemy je oczywiście po stronie repozytorium backupów (jako użytkownik postgres):
pgbackrest --stanza test --log-level-console=detail check
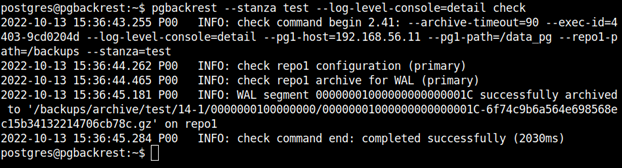
Archiwizacja przebiegła pomyślnie, a - konfiguracja stanzy jest poprawna. W tym momencie możemy wykonać pierwszą pełną kopię zapasową.
pgbackrest --stanza test --log-level-console=detail backup --type=full
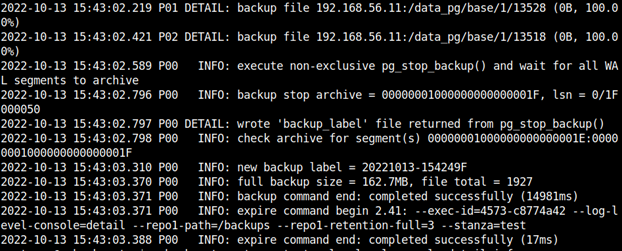
Kolejnym typem kopii zapasowej, którą możemy wykonać, jest - kopia przyrostowa:
pgbackrest --stanza test --log-level-console=detail backup --type=incr
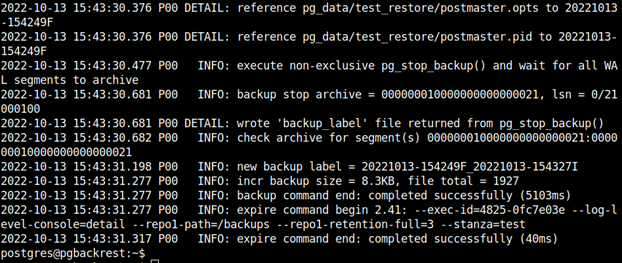
oraz kopia różnicowa:
pgbackrest --stanza test --log-level-console=detail backup --type=diff
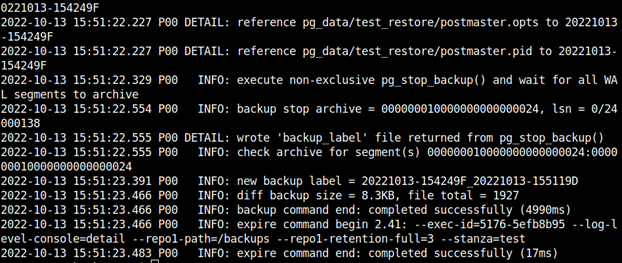
Obie kopie, przyrostowa i różnicowa, potrzebują poprawnie wykonanej pełnej kopii zapasowej, - na której bazują.
Podsumowując, kopie różnicowe trwają dłużej i zajmują więcej miejsca, ponieważ muszą za każdym razem skopiować wszystkie pliki, które zmieniły się od ostatniej pełnej kopii zapasowej, podczas gdy kopie przyrostowe kopiują tylko pliki od ostatniej kopii, pełnej, przyrostowej lub różnicowej.
Odbija się to jednak później na czasie odzyskiwania. Odzyskując bazę z kopii różnicowej, kopiujemy ostatnią kopię różnicową w całości oraz wszystkie pliki, które się nie zmieniły z pełnej kopii zapasowej. Zaś przy odzyskiwaniu z kopii przyrostowej musimy odzyskać pełny backup, różnicowy backup jeżeli takowy istnieje, a później kolejno każdą kopię przyrostową.
PgBackRes po każdej kopii zapasowej wykonuje polecenie expire, które usuwa z repozytoriów wszystkie backupy oraz powiązane z nimi pliki WAL przekraczające próg retencji zdefiniowany w pliku konfiguracyjnym /etc/pgbackrest.conf. Retencję dla pełnych backupów możemy ustawić wg liczby prawidłowych kopii zapasowych lub czasu. Parametr ustawiamy po stronie serwera backupów, skąd wywoływane są kopie zapasowe.
repo1-retention-full-type=count repo1-retention-full-type=time
Przy wyborze typu retencji count, czyli domyślnej opcji, która jest aktywna, nawet jeżeli parametru nie dodaliśmy do pliku konfiguracyjnego, expire wykona się automatycznie po poprawnym zrobieniu jednej kopii zapasowej więcej niż ilość wartość określona parametrem repo1-retention-full.
Również kopie różnicowe posiadają swoją retencję, ale tylko w opcji "count", czyli liczbie poprawnie wykonanych kopii zapasowych. Przykładowo repo1-retention-diff=1.Ustawienie takie spowoduje usunięcie starej kopii różnicowej - po poprawnym wykonaniu nowej. Również wszystkie kopie przyrostowe odnoszące się do usuwanej kopii różnicowej zostaną usunięte. Dzięki temu możemy zaoszczędzić miejsce na dysku, zachowując możliwość szybkiego odtworzenia bazy do dowolnego momentu w czasie od ostatniej kopii różnicowej. A korzystając z pełnej kopii zapasowej i plików WAL, możemy odtworzyć klaster do dowolnego miejsca w czasie pomiędzy backupem pełnym a różnicowym. Jest to raczej rzadko stosowana metoda, ale - warto - ją znać.
Retencję możemy ustawić też osobno dla każdego repozytorium, przykładowo traktując jedno z nich jako miejsce do przechowywania kopii długoterminowych, a drugie do kopii bieżących. Każdy z parametrów zaczynający się od repoX-, gdzie X to liczba porządkowa repozytorium, możemy ustawić indywidualnie dla każdego z nich.
repo1-retention-full=2 repo2-retention-full=4
Listę dostępnych backupów możemy sprawdzić za pomocą polecenia:
pgbackrest --stanza test --log-level-console=detail info
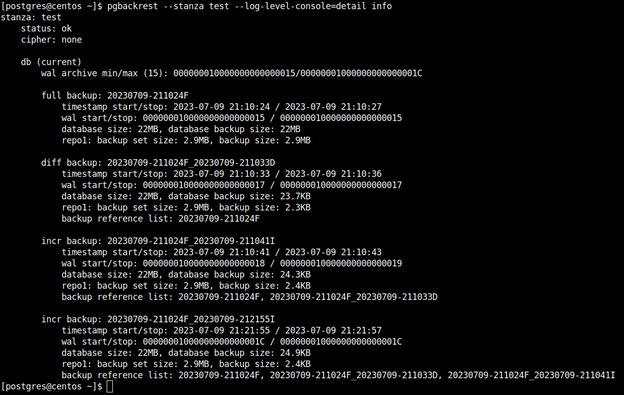
Na powyższym zrzucie ekranu widzimy informację o wykonanej pełnej kopii zapasowej - full, różnicowej - diff i przyrostowej - incr. Kopie różnicowe i przyrostowe są powiązane z innymi backupami. Informację o zależnościach między nimi możemy znaleźć w ostatniej linii opisującej każdy z nich, backup reference list. Pgbackrest wypisuje tutaj dla backupu różnicowego nazwę pełnej kopii, a dla kopii przyrostowych wszystkie poprzednie kopie, pełne, różnicowe i przyrostowe.
Kopie zapasowe są domyślnie kompresowane za pomocą gzipa. Metodą kompresji możemy sterować za pomocą parametru compress-type. Jeżeli parametru nie podaliśmy, w pliku konfiguracyjnym przyjmuje wartość gz. Przyjmowane wartości to:
Mamy również informację o czasie rozpoczęcia i zakończenia backupu, rozmiarze na dysku, w którym repozytorium dana kopia się znajduje oraz które pliki WAL obejmuje.
PgBackRest umożliwia konfigurację większej liczby repozytoriów jednocześnie oraz dla każdego z nich indywidualnie ustawiać parametry. Każde kolejne repozytorium tworzymy poprzez dodanie w konfiguracji parametrów definiujących kolejne repozytoria. Parametry dla nich rozpoczynają się od prefixu "repoX-", gdzie X to kolejny numer repozytorium.
Spróbujmy dodać zatem drugie repozytorium, tym razem używając blob storage w Azure.
Poniższe parametry powinniśmy dodać na wszystkich serwerach bazodanowych i repozytorium kopii zapasowych. Tutaj wartości przykładowe.
vi /etc/pgbackrest.conf repo2-type=azure repo2-azure-account=pgszkolenie001 repo2-azure-container=pg-backup repo2-azure-endpoint=blob.core.windows.net repo2-azure-key=z1vsEBQwyX6X9TZDo7a6fDFLlUW7WpBY8xIzs7/XAQgEBCPaxqqkkImAPUz5sMyab+8D54RRbI+AStFWdKVA==
Konfigurację zaktualizujemy na wszystkich serwerach bazodanowych, ponieważ polecenia archive-push i archive-get muszą mieć dostęp do wszystkich repozytoriów z każdego serwera z bazą danych, a repozytorium kopii zapasowych również potrzebuje informację o kolejnych repozytoriach, w których powinno przechowywać kopie zapasowe.
Po dodaniu repo2 do wszystkich plików konfiguracyjnych - należy ponownie wykonać "stanza-create", aby stworzyć wymaganą strukturę katalogów w nowym repo na Azure. Archiwizacja plików WAL odbywa się zawsze do wszystkich repozytoriów jednocześnie, dlatego warto skorzystać z opcji archive-async, która umożliwia asynchroniczną archiwizację. Jeżeli jedno z repozytoriów przestałoby z jakiegokolwiek powodu funkcjonować i archiwizacja do niego by się nie powiodła, cała archiwizacja byłaby zablokowana na tym samym pliku WAL dla obu lokacji. Korzystając z archiwizacji asynchronicznej, pgbackrest archiwizuje WAL do działającej lokacji, a w katalogu "spool-path", zapisuje informację o zarchiwizowanych plikach. Przy kolejnym wywołaniu archive command, pgbackrest sprawdzi, że plik WAL został już zarchiwizowany w jednym z repozytoriów i przejdzie do kolejnego. Proces archiwizacji nadal będzie częściowo zablokowany i nie będzie mógł usunąć tych WALi, Plik WAL, pozostanie w katalogu pg_wal.
Sprawdźmy, czy nowe pliki WAL są archiwizowane do obu repozytoriów:
# przez azure cli az storage blob directory list -c pg-backup --account-name szkolenie001 --auth-mode key --account-key <klucz> -d var/lib/pgbackrest # przez pgbackresta pgbackrest --stanza=test --repo=2 repo-ls
Konfigurując więcej repozytoriów, musimy wziąć pod uwagę, że wykonując kopie zapasowe, podajemy, do którego repo backup zostanie skopiowany, domyślnie "repo1", więc jeżeli chcemy przechowywać kopie na kilku jednocześnie, musimy zaplanować wykonywanie dla każdego z nich osobno. Ale też dzięki temu mamy możliwość skonfigurowania polityk retencji kopii zapasowych indywidualnie dla każdego repozytorium.
pgbackrest --stanza=test --repo=2 backup --log-level-console=detail
PgBackRest oferuje podobne możliwości odtwarzania danych jak Barman, do osiągnięcia spójności danych w bazie, odtworzenie wszystkich dostępnych w archiwum plików WAL, do danego punktu w czasie (--type=time), do wybranej transakcji (--type=xid), sekwencji w logu (--type=lsn), do wybranego "restore pointa" (--type=name), do czasu wykonania kopii zapasowej (--set=20221013-154249F_20221013-155119D), automatyczne dodanie konfiguracji dla serwera standby (--type=standby). - Nie mamy jednak możliwości odzyskiwania na serwer zdalny, polecenie restore możemy wykonać jedynie lokalnie na serwerze ze skonfigurowanym pgBackRestem.
Stwórzmy testową tabelę i dodajmy do niej kilka wartości osobnymi insertami, aby móc po kolei odtworzyć bazę do wybranego czasu. Funkcja pg_sleep na końcu skryptu jest istotna, z uwagi na ustawienie parameteru "archive_timeout = 60", chcemy mieć gwarancję, że plik WAL się zarchiwizuje i będzie dostępny do odtworzenia danych. Wykonujemy poniższe jako użytkownik postgres, po zalogowaniu się do psql, po stronie serwera bazy danych:
create table test (a int, b varchar); insert into test values (1, 'wartość przed wystąpieniem problemu'); select now(); insert into test values (1, 'wartość po mniejszym problemie'); select now(); insert into test values (1, 'wartość po większym problemie'); select pg_sleep(60); select now();
Zanotujmy wszystkie wyniki funkcji "now()", aby móc je wykorzystać podczas odtwarzania.
Po wykonaniu powyższego skryptu zatrzymajmy klaster postgresa (wykonujemy jako użytkownik systemowy postgres).
postgres@ubuntu:~$ /usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ stop -m fast
Teraz możemy wykonać polecenie "restore", aby odzyskać bazę do czasu "przed wystąpieniem problemu". Skorzystam tutaj z opcji --delta, - aby z repozytorium kopii zapasowych skopiować tylko te pliki, które się zmieniły od czasu wykonania ostatniego backupu (wykonujemy jako użytkownik systemowy postgres).
pgbackrest --stanza test --log-level-console=detail --type=time --target="2022-10-13 16:15:10" restore --delta

Odzyskiwanie z kopii zapasowej powiodło się, pgBackRest automatycznie dodał do konfiguracji postgresql.auto.conf wpis, który po wystartowaniu bazy spowoduje odtworzenie zmian do czasu podanego w poleceniu restore.
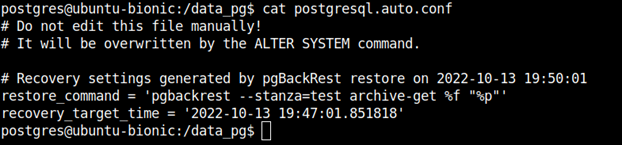
Możemy wystartować klaster:
/usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ start
Podobnie jak w przypadku odtwarzania bazy w Barmanie, postgres odtworzył dane do zadanego punktu w czasie i zatrzymał się w oczekiwaniu na dalsze instrukcje.
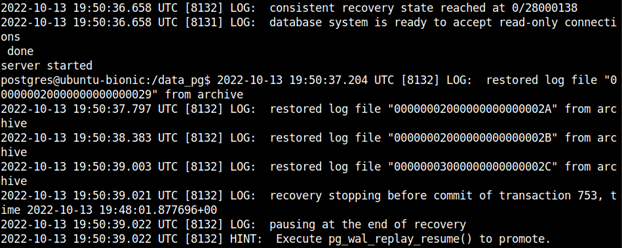
Postgres jest teraz w trybie tylko do odczytu. - Możemy podłączyć się do instancji, sprawdzić zawartość tabeli test. Jeżeli chcielibyśmy jednak odzyskać dane, to punktu po "małym fakapie" wystarczy, że zmienimy parametr recovery_target_time i zrestartujemy klaster (poniższe wykonujemy z konsoli psql).
postgres=# select * from test; a | b ---+------------------------------------- 1 | wartość przed wystąpieniem problemu (1 rows) postgres=# alter system set recovery_target_time = '2022-10-13 19:48:01.951818'; postgres@ubuntu:~$ pg_ctl -D /data_pg/ restart postgres=# select * from test; a | b ---+------------------------------------- 1 | wartość przed wystąpieniem problemu 1 | wartość po mniejszym problemie (2 rows)
Po restarcie postgres ponownie wykona odtwarzanie do uzyskania nowo zadanego czasu. Możemy teraz sprawdzić zawartość tabeli test. Powinniśmy widzieć wiersz "wartość po mniejszym problemie". - Jeżeli odzyskaliśmy bazę do momentu, który nas satysfakcjonuje, możemy wykonać funkcję pg_wal_replay_resume() w psql, aby otworzyć bazę i umożliwić zapis.
psql -c "select pg_wal_replay_resume()"
Aby odtworzyć backup i wszystkie dostępne pliki WAL z archiwum, wykonujemy bardzo podobne kroki jak w przypadku odtwarzania do wybranego punktu w czasie. Pomijamy jednak parametr wskazujący czas, do którego chcemy wykonać odtwarzanie zmian.
Przed rozpoczęciem odtwarzania zatrzymajmy postgresa, jeżeli jest uruchomiony (wykonujemy jako użytkownik systemowy postgres):
# jeżeli korzystamy z systemd, polecenia wykonujemy z poziomu użytkownika z sudo systemctl status postgres* sudo systemctl stop postgresql-15.service # lub jeśli klaster uruchomiony był za pomocą pg_ctl, jako użytkownik postgres ps -ef | grep bin/postgres /usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ stop -mf
Następnie możemy wykonać instrukcję odzyskiwania różnicowego, na serwerze bazodanowym. Pomijając parametry wskazujące, do którego momentu chcemy odzyskać dane, sprawimy, że postgres przy starcie odtworzy wszystkie pliki WAL dostępne w archiwum i otworzy bazę do zapisu.
pgbackrest --stanza test --log-level-console=detail restore --delta
Przed uruchomieniem klastra upewnijmy się, że w pliku /data_pg/postgresql.auto.conf nie mamy żadnych parametrów określających, do którego momentu postgres ma odtworzyć dane. Przykładowo recovery_target_time. Jeżeli w pliku znajduje się jakikolwiek recovery_target parametr, usuwamy go i uruchamiamy klaster.
/usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ start


Komentarze (0)
Brak komentarzy...