Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
Przestrzenie tabel fizycznie są katalogami. Zakłada się je na przykład, by trzymać część danych na osobnym dysku. Robi się tak, - kiedy chcemy rozłożyć obciążenie I/O na kilka dysków i dzięki temu poprawić wydajność. Możemy też wykorzystać osobne przestrzenie tabel, gdy kończy się miejsce na dysku zawierającym PGDATA. W przestrzeniach tabel możemy umieszczać pojedyncze obiekty (tabele, indeksy etc.), ale też całe bazy danych. Tutaj to nie przestrzenie tabel są związane z tabelami i nie baza zawiera przestrzenie tabel, a bazy są przywiązane do przestrzeni tabel i to dla baz ustawiamy domyślną przestrzeń tabel, w której mają znajdować się dane bazy. - Domyślnie istnieją dwie przestrzenie tabel:
select * from pg_tablespace;

Przestrzeń tabel "pg_default" odnosi się do katalogu "base" w PGDATA. Cokolwiek znajduje się w przestrzeni pg_default, mieści się - w podkatalogu "base". Tam właśnie będą domyślnie znajdować się wszystkie tworzone bazy danych i inne obiekty, jeśli przy ich tworzeniu nie wskażemy innej przestrzeni tabel. Przestrzeń "pg_global" odnosi się do katalogu "global"w PGDATA. Tutaj mieszczą się wszystkie słowniki systemowe o zasięgu globalnym.
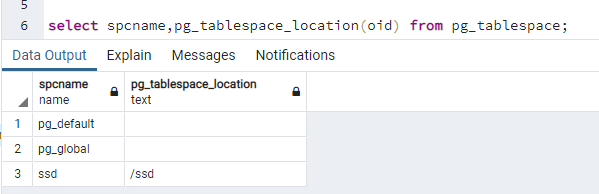
Możemy sprawdzić przestrzenie tabel wraz z ich położeniem na dysku. Położenie poszczególnych przestrzeni tabel sprawdzamy za pomocą funkcji "pg_tablespace_location", korzystając z zapytania:
select spcname,pg_tablespace_location(oid) from pg_tablespace;
Dla przestrzeni pg_default i pg_global położenie będzie zawsze nullem, ponieważ mieszczą się one w stałych opisanych wcześniej lokalizacjach. Widzimy tu też dodatkową przestrzeń tabel ssd, która została utworzona na potrzeby przykładu:
Możemy łatwo sprawdzić, jakie bazy danych mieszczą się w danej przestrzeni tabel, łącząc ze sobą słowniki "pg_database" i "pg_tablespace":
select datname,spcname,pg_tablespace_location(t.oid) from pg_database d join pg_tablespace t on d.dattablespace=t.oid;
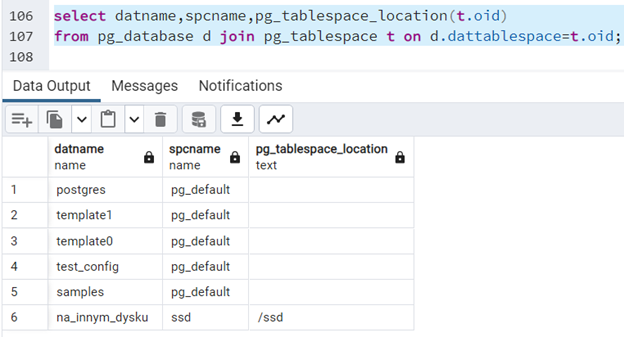
Widzimy tu między innymi bazę “na_innym_dysku” mieszczącą się w przestrzeni tabel “ssd”, która leży pod “/ssd”. Zarówno ta baza jak i przestrzeń tabel zostały - utworzone na potrzeby przykładu.
Możemy - sprawdzić, jakie obiekty mieszczą się w jakich przestrzeniach tabel. Dotyczyć to będzie zarówno tabel jak i np. indeksów czy sekwencji.
select relname,spcname,pg_tablespace_location(t.oid) from pg_class c join pg_tablespace t on c.reltablespace=t.oid;

Na screenie widzimy tabelę “na_ssd” mieszczącą się w przestrzeni tabel “ssd”, która leży na “/ssd”. Ta tabela i przestrzeń tabel zostały utworzone tylko na potrzeby przykładu.
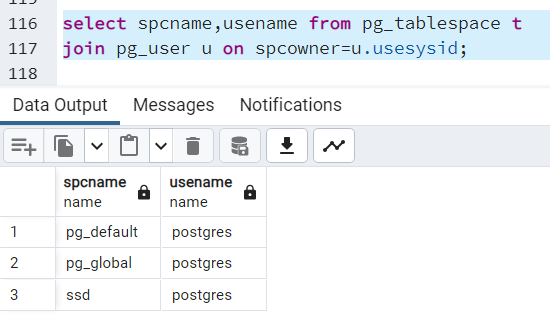
Możemy sprawdzić, kto jest właścicielem przestrzeni tabel (a zatem może z nią zrobić wszystko), - łącząc słowniki "pg_tablespace" i "pg_user":
select spcname,usename from pg_tablespace t join pg_user u on spcowner=u.usesysid;
Istnieje możliwość definiowania parametrów na poziomie przestrzeni tabel. Parametry te przechowywane są w słowniku "pg_tablespace" w kolumnie "spcoptions":
select * from pg_tablespace where spcname='ssd';

Na potrzeby przykładu został - ustawiony parametr dla przestrzeni tabel ssd. Widzimy to ustawienie w tabeli wynikowej dla przestrzeni ssd.
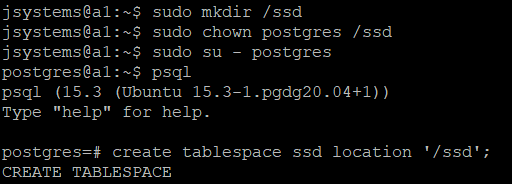
Aby stworzyć nową przestrzeń tabel, musimy wykonać poniższe kroki. Wykonujemy je, zaczynając od zalogowania się na użytkownika systemowego z prawami do sudo.
sudo mkdir /ssd sudo chown postgres /ssd sudo su - postgres psql create tablespace ssd location '/ssd';
Przy tworzeniu przestrzeni tabel system sprawdza, czy wskazany katalog istnieje. W przypadku jego braku- dostaniemy odpowiedni komunikat:

Musimy pamiętać, że rozmieszczanie danych w kilku przestrzeniach tabel utrudni później niektóre czynności - w tym backup i odtwarzanie klastra.
Tworząc przestrzeń tabel, możemy też ustalić od razu jej właściciela i ewentualne dodatkowe parametry (oczywiście katalog /kolejna musi istnieć i być własnością postgresa):
create tablespace kolejna - owner mapet location '/kolejna' with (seq_page_cost=2, random_page_cost=1);
Istotna - jest kolejność. Najpierw podajemy właściciela, następnie lokalizację, - a na końcu inne parametry.
W przestrzeniach tabel możemy umieszczać całe bazy danych lub pojedyncze obiekty. Tak wygląda tworzenie bazy danych we wskazanej przestrzeni i - sprawdzenie, czy się - tam - znajduje:
create database nowa tablespace=ssd;
Sprawdzamy, czy wszystko się zgadza:
select datname,spcname,pg_tablespace_location(t.oid) from pg_database d join pg_tablespace t on d.dattablespace=t.oid;
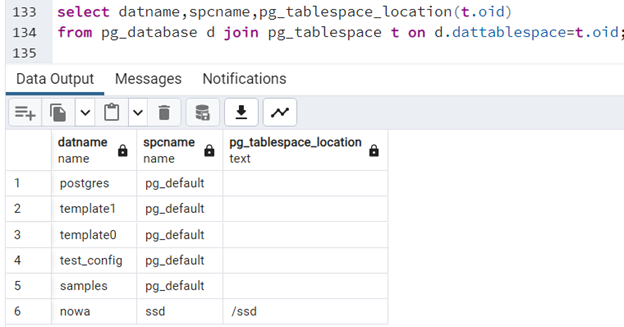
Jak widać, tabela “nowa” została umieszczona w przestrzeni tabel ssd mieszczącej się pod “/ssd”.
Wszystkie nowo tworzone obiekty w tej bazie danych będą domyślnie umieszczane w tej przestrzeni tabel, w której znajduje się baza.
Tworzenie tabel we wskazanym tablespace i sprawdzenie, czy się tam znajdują:
create table tabelka (x integer) tablespace ssd;
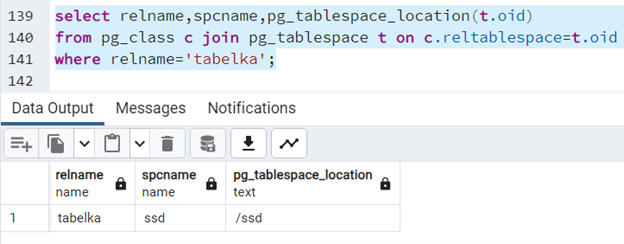
Sprawdzimy teraz, czy tabela jest we właściwej przestrzeni tabel:
select relname,spcname,pg_tablespace_location(t.oid) from pg_class c join pg_tablespace t on c.reltablespace=t.oid where relname='tabelka';
Jeśli utworzymy indeks na tabeli znajdującej się w przestrzeni innej niż domyślna, nie będzie on przechowywany w tej samej przestrzeni tabel co tabela, której ten indeks dotyczy, a właśnie w domyślnej. Sprawdzamy:
create index indeksik on tabelka(x); select * from pg_indexes where indexname='indeksik';
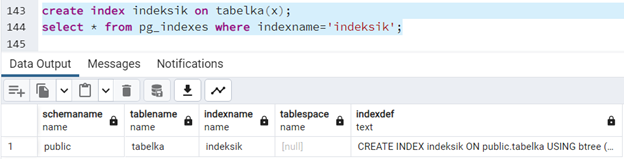
Jak widzimy, w kolumnie "tablespace" mamy null, - a więc obiekt ten znajduje się w domyślnej przestrzeni. Aby indeks znalazł się w tej samej przestrzeni tabel co tabelka, - na której ten indeks leży, trzeba to wskazać. W tym celu kasujemy indeks i tworzymy go jeszcze raz ze wskazaniem przestrzeni tabel:
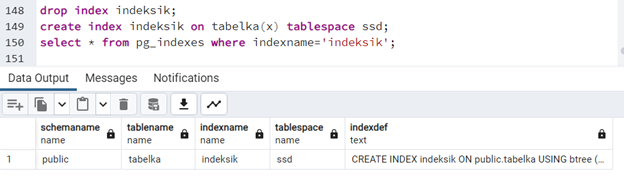
drop index indeksik; create index indeksik on tabelka(x) tablespace ssd; select * from pg_indexes where indexname='indeksik';
Oczywiście można też przenieść istniejący indeks:
alter index indeksik set tablespace ssd;
Parametr "default_tablespace" pozwala ustawić domyślną przestrzeń tabel dla tworzonych obiektów. Dzięki niemu tworząc obiekty przy każdym obiekcie, nie musimy wskazywać przestrzeni tabel dla tego obiektu. Domyślnie parametr ten jest pusty, co będzie oznaczało, że domyślną przestrzenią tabel będzie "pg_default" związany z katalogiem "base" w PGDATA. Tworzymy nowy tablespace, konfigurujemy parametr "default_tablespace" tak, by na niego wskazywał, tworzymy tabelkę i sprawdzamy, gdzie się znajduje:
set default_tablespace='ssd'; create table yyy (y integer); select relname,spcname from pg_class c join pg_tablespace t on c.reltablespace=t.oid where relname='yyy';
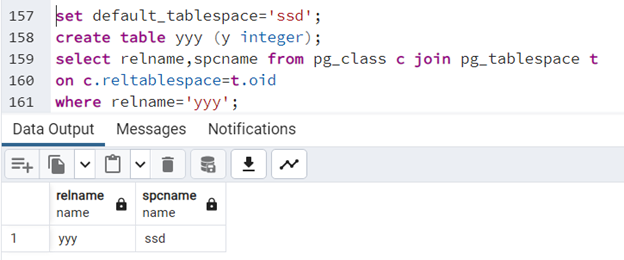
UWAGA! Parametr ten nie będzie wpływał na przestrzeń, w której znajdą się nowo tworzone bazy danych. Możemy się o tym przekonać, ustawiając "default_tablespace", tworząc bazę danych i sprawdzając, - gdzie się znajduje:
set default_tablespace='ssd'; create database osobna; select datname,spcname from pg_database d join pg_tablespace t on t.oid=d.dattablespace where datname='osobna';

Jeśli więc chcemy umieścić bazę w konkretnej przestrzeni tabel, - trzeba będzie przy tworzeniu bazy wskazać ją - przełącznikiem "tablespace".
Parametr "default_tablespace" można zmieniać również dla całego systemu. Zmieniamy domyślną przestrzeń tabel dla klastra i przeładowujemy konfigurację:
alter system set default_tablespace=ssd; select pg_reload_conf();
Następnie tworzymy tabelę i sprawdzamy, w której przestrzeni tabel się znalazła:
create table nowa(x integer); select relname,spcname from pg_class c join pg_tablespace t on c.reltablespace=t.oid where relname='nowa';

Nowo stworzona tabela "nowa" znajduje się w przestrzeni, - którą ustawiliśmy jako domyślną, tj. "ssd".
Przywrócić domyślne ustawienie dla systemu możemy - w następujący - sposób:
alter system set default_tablespace=pg_default; select pg_reload_conf();
Parametr "default_tablespace" można skonfigurować również dla wybranej bazy danych:
alter database samples set default_tablespace=ssd;
Należy zwrócić - uwagę, że baza danych może mieścić w jednej przestrzeni tabel, ale nowo tworzone w niej obiekty mogą znajdować się w innej przestrzeni - wynikającej z ustawienia "default_tablespace" na dowolnym poziomie (sesja, baza danych, klaster).
Przestrzeń tabel można skasować komendą:
drop tablespace nazwa_przestrzeni_tabel;
Warunek jest jednak taki, że dana przestrzeń tabel musi być pusta. Dla przykładu stworzymy - przestrzeń tabel “do_usuniecia” leżącą na /do_usuniecia (pamiętając o stworzeniu katalogu i nadaniu odpowiedniego chowna ofc) i utworzymy w niej tabelę “abc”, a następnie spróbujemy - usunąć tę przestrzeń tabel:
create tablespace do_usuniecia location '/do_usuniecia'; create table abc(x integer) tablespace do_usuniecia; drop tablespace do_usuniecia;

PostgreSQL informuje nas, że nie możemy - usunąć tej przestrzeni tabel, ponieważ znajduje się w niej obiekt. Aby móc skasować tę przestrzeń, należy uprzednio skasować lub przenieść obiekt znajdujący się w niej. Czeka więc nas mała inwestygacja. Jaki obiekt znajduje się w tablespace “do_usuniecia”? Sprawdźmy to za pomocą zapytania:
select relname,spcname from pg_class c join pg_tablespace t on c.reltablespace=t.oid where spcname='do_usuniecia';
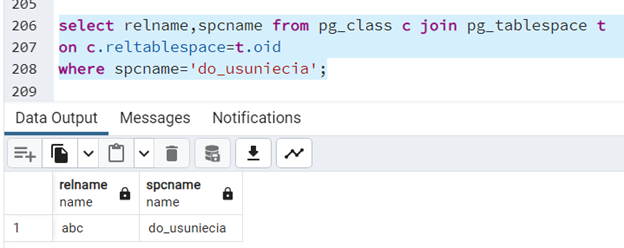
W tym przypadku przenosimy tę tabelę do przestrzeni domyślnej i ponownie, tym razem z sukcesem, kasujemy przestrzeń tabel:
alter table abc set tablespace pg_default; drop tablespace do_usuniecia;
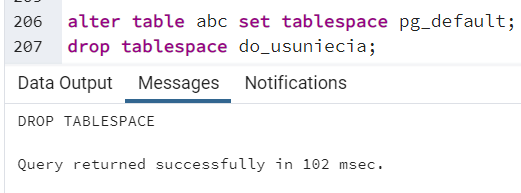
Co się stanie, jeśli spróbujemy skasować przestrzeń tabel, w której znajduje się baza danych? Sprawdźmy to. Tworzymy - ponownie przestrzeń tabel “do_usuniecia” i umieszczamy w niej bazę danych “skasuj_mnie”. Następnie próbujemy skasować przestrzeń tabel:
create tablespace do_usuniecia location '/do_usuniecia'; create database skasuj_mnie tablespace do_usuniecia; drop tablespace do_usuniecia;

Efekt jest identyczny. Taki komunikat niekoniecznie oznacza, - że w tej przestrzeni tabel znajduje się tabelka lub indeks, może to być też baza danych. Znajdźmy więc bazy danych leżące w tej przestrzeni tabel:
select datname,spcname from pg_database d join pg_tablespace t on t.oid=d.dattablespace where spcname='do_usuniecia';
Mamy przyczynę:

Możemy teraz przenieść bazę danych do innej przestrzeni tabel i skasować przestrzeń tabel:
alter database skasuj_mnie set tablespace pg_default; drop tablespace do_usuniecia;

Warto wiedzieć, że wraz z przenoszeniem obiektów (zarówno tabel i indeksów jak i baz danych) przenoszone są fizycznie pliki danych. Wynika z tego czasowa niedostępność obiektów podczas przenoszenia. Wiąże się - to z niezbędną blokadą ekskluzywną zakładaną na te pliki w trakcie przenoszenia.
Katalog związany z przestrzenią tabel nie zostanie usunięty, trzeba go będzie usunąć ręcznie.
Jeśli przenosimy obiekty pomiędzy przestrzeniami tabel, - to w tle przenoszone są pliki danego obiektu do katalogu związanego z docelową przestrzenią tabel. W związku z tym, by zapewnić spójność danych, tabela (lub inny obiekt) w trakcie przenoszenia jest niedostępna.
Tworzymy tabelę "xyz", która znajdzie się w domyślnej przestrzeni tabel "pg_default" i - sprawdzamy, czy rzeczywiście tam się znajduje:
create table xyz (x integer); select c.oid,pg_relation_filepath(c.oid) ,relname,spcname from pg_class c left join pg_tablespace t on c.reltablespace=t.oid where relname='xyz';

Pole "spcname" jest puste - czyli tabela znajduje się w przestrzeni "pg_default".
Przenosimy - tabelę do innej przestrzeni tabel i ponawiamy test:
alter table xyz set tablespace postgres_01; select c.oid,pg_relation_filepath(c.oid) ,relname,spcname, pg_tablespace_location(t.oid) from pg_class c left join pg_tablespace t on c.reltablespace=t.oid where relname='xyz';
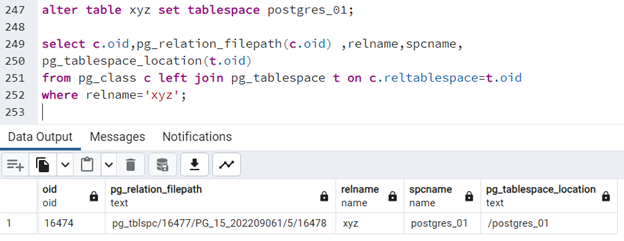
Tym razem widzimy, - że tabela leży już w przestrzeni "postgres_01". Pamiętamy, że przenosząc tabele pomiędzy przestrzeniami tabel, nie przenosimy - indeksów! Zostaną one tam, gdzie były i jeśli chcemy, - by znalazły się w innej przestrzeni, trzeba je będzie osobno przenieść. Przenoszenie indeksów możemy zrealizować poleceniem:
alter index ind_abc set tablespace postgres_01;
Istnieje - możliwość masowego przenoszenia obiektów z jednej przestrzeni do drugiej. Tworzymy - trzy tabele mieszczące się w przestrzeni - tabel "postgres_01":
create table abc (x integer) tablespace postgres_01; create table def (x integer) tablespace postgres_01; create table ghi (x integer) tablespace postgres_01;
Sprawdzamy ich położenie:
select c.oid,pg_relation_filepath(c.oid) ,relname,spcname,
pg_tablespace_location(t.oid)
from pg_class c left join pg_tablespace t on c.reltablespace=t.oid
where relname in ('abc','def','ghi');
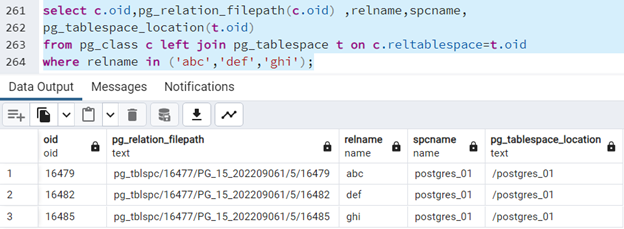
Tworzymy - przestrzeń o nazwie "postgres_02". Przenosimy do niej wszystkie tabele znajdujące się w przestrzeni "postgres_01":
alter table all in tablespace postgres_01 set tablespace postgres_02;
Po przeniesieniu sprawdzamy ponownie, - gdzie leżą tabele:
select c.oid,pg_relation_filepath(c.oid) ,relname,spcname,
pg_tablespace_location(t.oid)
from pg_class c left join pg_tablespace t on c.reltablespace=t.oid
where relname in ('abc','def','ghi');
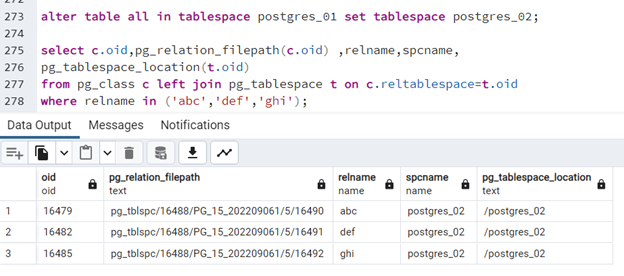
Jak widać, wszystkie trzy tabele zostały przeniesione do przestrzeni tabel postgres_02.
W podobny sposób możemy masowo przenosić indeksy. Tworzymy - trzy indeksy, po jednym dla każdej z tabel “abc”, “def”, ghi”:
create index ind_abc on abc(x); create index ind_def on def(x); create index ind_ghi on ghi(x);
Następnie - sprawdzamy ich położenie:
select c.oid,pg_relation_filepath(c.oid) ,relname,spcname,
pg_tablespace_location(t.oid)
from pg_class c left join pg_tablespace t on c.reltablespace=t.oid
where relname in ('ind_abc','ind_def','ind_ghi');
Okazuje się, że - indeksy znajdują się w przestrzeni tabel pg_default:
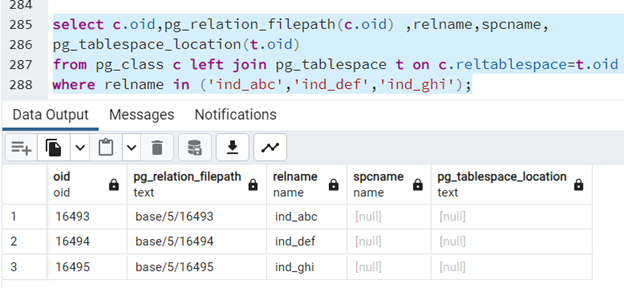
Chcemy więc umieścić te indeksy w tej samej przestrzeni tabel co tabele, - których dotyczą. Możemy przenosić je pojedynczo:
alter index ind_abc set tablespace postgres_02;
Ale możemy też masowo przenieść wszystkie indeksy z określonej przestrzeni tabel do innej:
alter index all in tablespace pg_default set tablespace postgres_02;
Po obu alterach widzimy już, - że wszystkie nasze indeksy leżą tam, gdzie powinny.
select c.oid,pg_relation_filepath(c.oid) ,relname,spcname,
pg_tablespace_location(t.oid)
from pg_class c left join pg_tablespace t on c.reltablespace=t.oid
where relname in ('ind_abc','ind_def','ind_ghi');

W przypadku próby przeniesienia obiektu zablokowanego przez jakąś transakcję, PostgreSQL będzie czekał na zdjęcie blokady bez zwracania błędu.
Zaczynamy od sprawdzenia, - jakie mamy przestrzenie tabel:
select * from pg_tablespace;

Chcemy zmienić nazwę przestrzeni “ssd” na “second_drive”, więc wywołujemy komendę:
alter tablespace ssd rename to second_drive;
Ponownie sprawdzamy istniejące przestrzenie:
select * from pg_tablespace;
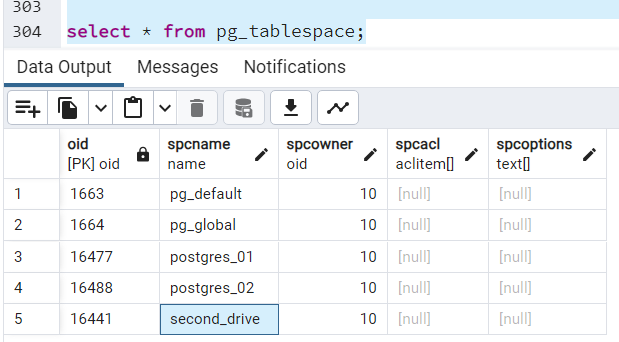
Widzimy, że nasza przestrzeń tabel “ssd” ma już zmienioną nazwę na “second_drive”.
Aby sprawdzić, kto jest właścicielem poszczególnych przestrzeni tabel, możemy wykonać poniższe zapytanie:
select spcname,usename from pg_tablespace t join pg_user u on spcowner=u.usesysid;
Wynik działania tego zapytania:
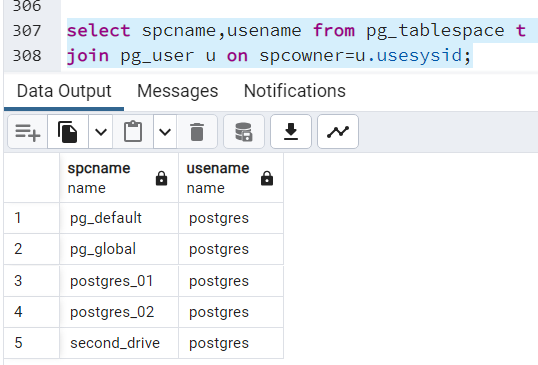
By zmienić właściciela przestrzeni tabel, wydajemy komendę (użytkownik “mapet” już istnieje w bazie):
alter tablespace second_drive owner to mapet;
Sprawdzamy, do kogo należy przestrzeń “second_drive”:
select spcname,usename from pg_tablespace t join pg_user u on spcowner=u.usesysid where spcname='second_drive';
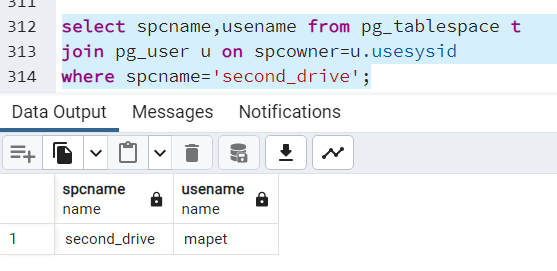
Jak widać, przestrzeń “second_drive” zmieniła właściciela na użytkownika “mapet”.
Użytkownik będący właścicielem przestrzeni tabel będzie mógł zmieniać jej parametry lub ją usunąć (ale tylko jeśli dana przestrzeń będzie pusta). Bycie właścicielem przestrzeni nie determinuje uprawnień na obiektach w niej zawartych. Właściciel przestrzeni tabel nie będzie mógł np. kasować obiektów znajdujących się w tej przestrzeni tabel. Żeby się o tym upewnić, - tworzymy tabelę w przestrzeni "second_drive", której właścicielem jest użytkownik "mapet":
create table moja(x integer) tablespace second_drive;
Upewniamy się jeszcze, że leży ona we właściwej przestrzeni tabel:
select relname,spcname from pg_class c join pg_tablespace t on c.reltablespace=t.oid where relname='moja';

Spróbujemy - teraz zalogować się jako użytkownik "mapet" i zajrzeć do tabeli "moja", którą utworzyliśmy w przestrzeni należącej do użytkownika mapet:
psql -U mapet -d postgres select * from moja;
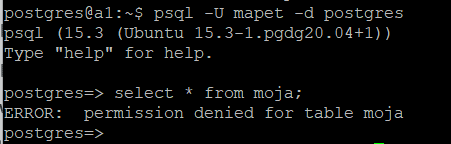
Jak widać na załączonym obrazku, własność przestrzeni tabel nie determinuje uprawnień do obiektów w niej zawartych.
Podczas niektórych operacji (np.sortowanie, joiny, grupowanie ) przestrzeń pamięci dostępna w ramach określonych przez parametr "work_mem" bywa - niewystarczająca. W takiej sytuacji PostgreSQL tworzy pliki tymczasowe, z użyciem których operacja jest wykonywana. Podobnie dzieje się w przypadku tworzenia tabel tymczasowych i indeksów na tych tabelach.
Domyślnie te pliki tymczasowe będą wytwarzane w podkatalogu "base/pgsql_tmp" naszego PGDATA. Nie zawsze jest to dobre rozwiązanie z punktu widzenia wydajności oraz stabilności działania klastra. W kontekście wydajności - tworzenie takich plików tymczasowych na dysku innym niż znajdują się dane rozłoży obciążenie związane z odczytami i zapisami odczytów oraz operacji powodujących tworzenie plików tymczasowych na osobne dyski. W kontekście stabilności działania klastra - jeśli pliki tymczasowe tworzone są na tym samym dysku co dane, może dojść do takiej sytuacji, - że pliki tymczasowe wysycą nam przestrzeń dyskową i nie będziemy mogli dodać danych do bazy. Są to wystarczające argumenty, by przynajmniej zastanowić się nad przeniesieniem miejsca tworzenia plików tymczasowych na inny dysk. Żeby sprawdzić, gdzie tworzone są pliki tymczasowe, zmieniamy parametr "log_temp_files" na wartość większą lub równą 0. Wartość ta będzie określała w kilobajtach, powyżej jakiej wielkości pliku ma zostać w logach zarejestrowany fakt jego powstania. Jeśli ustawimy na zero, rejestrowane będą wszystkie pliki tymczasowe. W logach pojawi się ścieżka do tworzonego pliku - i - to chcieliśmy osiągnąć. Aby zmienić ten parametr, wykonujemy czynności:
alter system set log_temp_files=0; select pg_reload_conf();
Przykładowa tabela z danymi:
create table dane(x integer,y integer,z text); insert into dane(x) select generate_series(1,1000000); update dane set y=x%100,z='element numer '||x;
Uruchamiamy też podgląd logów, by widzieć, gdzie tworzone są pliki tymczasowe (jako użytkownik systemowy postgres). Dostosowujemy - swoją nazwę pliku z aktualnego loga:
tail -f /data_pg/log/postgresql-2023-08-22_000000.log
Przyszedł czas na przetestowanie. Uruchamiamy zapytanie zawierające sortowanie. Na tym wolumenie (1000000 wierszy) i parametrze "work_mem" ustawionym domyślnie na 4MB powinno to spowodować wytworzenie pliku tymczasowego:
select * from dane order by y;
W podglądzie loga widzimy:

Czyli powstaje plik tymczasowy o wielkości ok 37MB. Jak widać, został utworzony plik tymczasowy w domyślnej lokalizacji - czyli w podkatalogu "base/pgsql_tmp"j PGDATA.
Zadbać należy - o to, by pliki tymczasowe tworzone były w wybranej przez nas lokalizacji. W pierwszej kolejności tworzymy katalog na odpowiednim dysku i zmieniamy jego właściciela na użytkownika systemowego "postgres". Następnie tworzymy przestrzeń tabel w tej lokalizacji. Zmieniamy parametr systemowy "temp_tablespaces" , który określa nazwę przestrzeni tabel użytej jako kontener na pliki tymczasowe i przeładować konfigurację:
create tablespace tmp_pg location '/tmp_pg'; alter system set temp_tablespaces=tmp_pg; select pg_reload_conf();
Parametr "temp_tablespaces" domyślnie jest pusty, - co oznacza, - że użyta zostanie domyślna przestrzeń tabel w PGDATA. W tym parametrze możemy podać po przecinku kilka przestrzeni tymczasowych. W takim wypadku PostgreSQL będzie wybierał przy każdej operacji wymagającej tworzenia pliku tymczasowego przestrzeń tabel w sposób losowy.
Po zmianie domyślnej tymczasowej przestrzeni tabel ponownie pytamy - i zaglądamy do loga:
select * from dane order by y;

Początek ( "pg_tblspc") oznacza, - że jest to jakaś przestrzeń tabel inna niż domyślna (pg_default). 16508 to oid tej przestrzeni tabel. Możemy to łatwo sprawdzić za pomocą zapytania:
select oid,spcname from pg_tablespace where spcname='tmp_pg';

Dalsza część ścieżki to już ścieżka względna wobec katalogu danej przestrzeni tabel. Sprawdzamy więc, gdzie znajduje się nasza przestrzeń tabel (podmień oid na swój w argumencie funkcji):
select pg_tablespace_location(16508);

Podsumowując, ścieżka z loga:
"pg_tblspc/16508/PG_15_202209061/pgsql_tmp/"
tak naprawdę oznacza ścieżkę:
"/tmp_pg/PG_15_202209061/pgsql_tmp/",
czyli przestrzeń tabel, - którą ustawiliśmy jako przeznaczoną na potrzeby plików tymczasowych. Oczywiście po zakończeniu - zapytania lub usunięciu tabeli tymczasowej plik tymczasowy zostaje usunięty.
Postgres sam w sobie nie udostępnia opcji przenoszenia przestrzeni tabel. Przeniesienie przestrzeni tabel na inną partycję czy dysk fizyczny często może być bardzo przydatne lub nawet ratujące życie, w sytuacji gdy partycja na której znajduje się przestrzeń tabel zapełni się, a będziemy mieli dostępną inną partycję z odpowiednią ilością wolnego miejsca. Wadą tego rozwiązania jest fakt, że nie możemy tego wykonać na działającym klastrze, musimy go całkowicie zatrzymać.
Aby przenieść przestrzeń tabel na inną partycję musimy zacząć od zapisania sobie numeru “oid” dla przestrzeni tabel którą chcemy przenieść:
SELECT oid, * FROM pg_tablespace; oid - | - spcname | spcowner | spcacl | spcoptions -------+------------------+----------+--------+------------ 1663 | pg_default | 10 | | 1664 | pg_global | 10 | | 17514 | do_przeniesienia | 10 | |
Następnie weryfikujemy w którym katalogu nasza przestrzeń tabel się znajduje:
psql -c "SELECT pg_tablespace_location(17514)" pg_tablespace_location ------------------------- /do_przeniesienia
Zatrzymujemy klaster:
pg_ctl -D /data_pg stop
Przenosimy fizycznie katalog:
mv /do_przeniesienia /katalog_docelowy
Przechodzimy do katalogu PGDATA i podkatalogu pg_tblspc w którym znajdują się linki symboliczne dla wszystkich przestrzeni tabel:
cd /data_pg/pg_tblspc/ ls -l lrwxrwxrwx 1 postgres postgres 20 Nov - 5 22:26 17514 > /do_przeniesienia
W końcu aktualizujemy link symboliczny:
ln -fs /katalog_docelowy 17514
Ostatnim krokiem będzie ponowne uruchomienie klastra i weryfikacja czy postgres rozpoznał nową lokację:
Pg_ctl -D /data_pg start psql -c "SELECT pg_tablespace_location(17514);" pg_tablespace_location ------------------------- /katalog_docelowy



Komentarze (0)
Brak komentarzy...