
[ Do realizacji przykładów z tego rozdziału potrzebujemy hostów 1,2 i 5. Należy je przygotować według instrukcji, uwzględniając poniższe zalecenia. Howto znajdziemy w instrukcji instalacji hostów i artykule na temat pgbackrest ]
Serwer 1:
Serwer 2:
Serwer 5:
Replilkacja WAL-shipping standby, inaczej ciągłe odtwarzanie, opiera się na nieprzerwanym pobieraniu i odtwarzaniu plików WAL z archiwum.
Aby móc z niego skorzystać, musimy najpierw skonfigurować archiwizację (archive_mode oraz archive_command) na serwerze głównym, primary. Postgres na serwerze standby będzie monitorował archiwum w poszukiwaniu nowych plików WAL. Po wykryciu nowego logu będzie on automatycznie pobierany i odtwarzany.
Z tego względu taka replikacja zawsze jest trochę z tyłu, ponieważ do archiwum wysyłane są tylko pełne pliki WAL (16MB), lub kiedy zostanie wymuszona ich rotacja.
Aby ograniczyć liczbę utraconych danych w wyniku wypadku, możemy wymusić częstszą archiwizację, a tym samym zmniejszyć liczbę potencjalnie utraconych danych, ale kosztem zwiększonej generacji plików WAL. Odpowiada za to parametr archive_timeout, który powoduje wymuszenie archiwizacji, jeżeli postgres nie zarchiwizował żadnego logu przez X sekund. Warto przy tym pamiętać, że postgres w momencie archiwizacji wymuszonej timeoutem, zakończy aktualny plik WAL uniemożliwiając dalszy zapis do niego, ale z zachowaniem jego wielkości, czyli domyślnie 16MB, pomimo tego, że wpisów WAL jest znacznie mniej.
Przykładowo, generując 2 MB wpisów do WAL na minutę, będziemy archiwizować 1 plik WAL (16MB) co 8 minut, czyli w najgorszym wypadku możemy stracić do 8 minut danych. Ustawiając archive_timeout na 120, zmniejszymy możliwą utratę danych do 2 minut, ale zaczniemy generować 64MB plików WAL na 8 minut, (4 x 16MB). Czyli czterokrotnie więcej. Warto wziąć to pod uwagę, planując ustawienie parametru archive_timeout.
[ Przykład poglądowy, instrukcje do wykonania repliki będą poniżej ]
Na instancji primary musimy skonfigurować archiwizację plików WAL, np:
archive_mode = on
archive_command = 'rsync -a %p postgres@<adres_backup_serwera>:/mnt/server/archivedir/%f'
a na instancji standby ustawić parametr odzyskiwania Write Ahead Logów, przykładowo:
restore_command = 'rsync -a postgres@<adres_backup_serwera>:/mnt/server/archivedir/%f %p'
Potem musimy utworzyć pusty plik standby.signal w katalogu głównym klastra (PGDATA = /data_pg). Plik standby.singnal, to jak można wywnioskować z nazwy, sygnał dla postgresa, aby wystartował instancję w trybie standby i rozpoczął odtwarzanie zmian. Jeżeli mamy ustawiony restore_command, a nie ustawiliśmy żadnego punktu docelowego dla odtwarzania, postgres będzie kopiował z archiwum i odtwarzał wszystkie pliki WAL tak szybko, jak to możliwe.
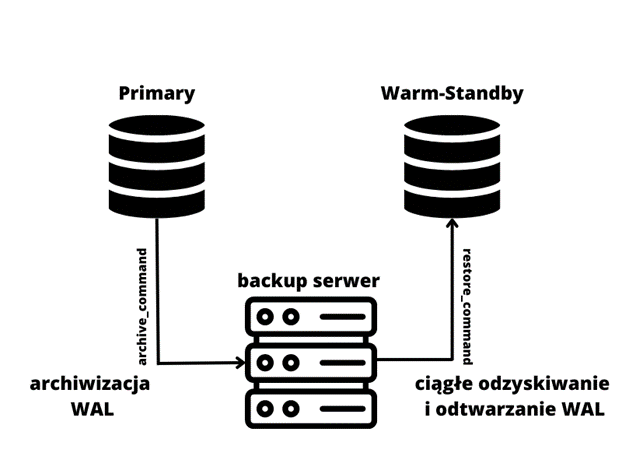
Zainicjalizować wal shipping replikę możemy na dwa sposoby: za pomocą pg_basebackup lub kopii zapasowej wykonanej w dowolny sposób, np. pgbackrest lub barman, pod warunkiem, że posiadamy wszystkie pliki WAL od czasu stworzenia kopii do stanu bieżącego klastra.
Przykłady poleceń do stworzenia repliki za pomocą: pg_basebackup, pgbackrest i barmana (wykonujemy jako użytkownik systemowy postgres).
pg_basebackup -h <X.X.X.X> -U replicator -D /data_pg -X stream -Ppgbackrest --stanza test --log-level-console=detail --type=standby --pg1-path=/data_pg restore
barman recover rsync-pg-5432 20230706T221234 /data_pg --remote-ssh-command "ssh postgres@<IP adres docelowego serwera>" --standby-mode
Na potrzeby demonstracji stworzymy replikę za pomocą kopii zapasowej wykonanej pgbackrestem. Korzystając z barmana lub pg_basebackupa, kroki są prawie identyczne. Zmieniamy tylko archive_command i restore_command oraz używamy odpowiedniego polecenia do odtwarzania i wymuszenia zmiany pliku WAL.
Instrukcje konfiguracji pgbackresta znajdziemy <tu jakiś odnośnik do artykułu>. Artykuł ten pokazuje, w jaki sposób skonfigurować kopie zapasowe dla jednego serwera. Po instalacji i konfiguracji serwera primary wykonajmy pierwszą kopię zapasową, którą później wykorzystamy do stworzenia repliki.
Należy wyedytować plik konfiguracyjny i prowadzić w nim zmiany (jako użytkownik systemowy postgres):
vi /data_pg/postgresql.conf
Parametry, które powinna mieć ustawiona instancja primary to:
listen_addresses = '*'
wal_level = replica
logging_collector = on
log_directory = log
wal_log_hints = on
archive_mode = on
archive_command = '/usr/bin/pgbackrest --stanza=test archive-push %p'
restore_command = '/usr/bin/pgbackrest --stanza=test --pg1-path=/data_pg archive-get %f %p'
archive_timeout = 60
Część z tych parametrów będziemy mieć już ustawione w związku z konfiguracją pgbackresta. Różnica pojawi się tylko w archive_command i restore_command i sprowadza się do tego, że w już posiadanej wartości jest dodatkowy argument "--config=/etc/pgbackrest.conf". Argument ten wskazuje plik konfiguracyjny, który domyślnie i tak jest w tej lokalizacji. Tak więc możemy tych dwóch parametrów nie zmieniać, jeśli wcześniej konfigurowaliśmy pgbackrest na tym serwerze.
Ustawione powyżej parametry to:
Konfiguracja serwera z repliką wygląda bardzo podobnie. W instrukcji przygotowania hostów instalujemy pakiety z Postgresem oraz pgbackrestem. Podążając za instrukcjami, zatrzymujemy domyślny klaster, tworzymy katalogi, ale nie inicjalizujemy nowego PGDATA. Następnie tworzymy plik /etc/pgbackrest.conf, którego zawartość możemy skopiować z serwera głównego, primary. Zawartość pgdata, pliki konfiguracyjne oraz ich wartości zostaną dodane automatycznie po odtworzeniu klastra z kopii zapasowej.
W analogiczny sposób możemy skonfigurować wal-shipping replikę również za pomocą barmana. Instrukcję do konfiguracji barmana znajdziemy <link do barmana> oraz pg_basebackupa, który wymaga największego nakładu pracy, ponieważ trzeba ręcznie skonfigurować serwer wykorzystany na archiwum plików WAL, skonfigurować samodzielnie archiwizację (archive_command) i odzyskiwanie (restore_command), zadbać o usuwanie najstarszych plików WAL, idealnie też zaplanować kopie zapasowe za pomocą pg_basebackup, a usuwanie logów transakcyjnych połączyć z usuwaniem najstarszych kopii zapasowych, co wymaga dodatkowego skryptowania, żeby wszystko działało jak należy.
Z tego też powodu konfiguracja pgbackresta wydaje się najłatwiejszym wyborem i dlatego przykłady zostały wykonane właśnie na tym narzędziu.
Aby wszystko zadziałało poprawnie, musimy skonfigurować połączenie SSH autoryzowane za pomocą klucza RSA. UWAGA, część z generowaniem klucza powinniśmy pominąć, jeżeli posiadamy już na serwerze plik "~/.ssh/id_rsa.pub", nadal musimy jednak skopiować jego zawartość na serwer kopii zapasowych i wykonać pozostałe kroki. Aby wygenerować klucz ssh po stronie serwera repliki (u nas host 2), należy wykonać polecenie ssh-keygen, a następnie umieścić go w pliku .ssh/authorized_keys po stronie serwera repozytorium backupów. W tym celu po stronie serwera repliki (host 2) wywołujemy polecenia (jako użytkownik systemowy postgres). ssh-keygen nie wykonujemy, jeśli mamy już plik ~/.ssh/id_rsa.pub:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub
Następnie to, co zostanie wyrzucone po instrukcji "cat", umieszczamy po stronie serwera repozytorium backupów (u nas host 5) w pliku ~/.ssh/authorized_keys jako użytkownik systemowy postgres:
vi ~/.ssh/authorized_keys
Po tej operacji sprawdzamy jeszcze, czy uda nam się zalogować na serwer backupów bez podawania hasła:
ssh postgres@pg5
Logowanie powinno przejść bez podawania hasła.
Połączenie ssh między pg1 a pg5 powinniśmy już mieć zrobioną podczas konfiguracji na potrzeby pgbackresta.
Serwery powinny być przygotowane według instrukcji powyżej. Czyli posiadamy instancję Postgresa, która będzie pełniła rolę "primary", oraz mamy skonfigurowaną archiwizację i pgbackrest.
Przed rozpoczęciem odtwarzania backupu musimy skopiować też plik konfiguracyjny pgbackresta z serwera pg1 na pg2.
# na serwerze pg1
cat /etc/pgbackrest.conf# na serwerze pg2 otwieramy konfig, komentujemy zawartość i wklejamy konfigurację z pg1
vi /etc/pgbackrest.conf
Poniższe polecenie wykonujemy na pg2 (serwer replika) jako użytkownik postgres. Do polecenia "pgbackrest restore" dodajemy --type=standby, aby automatycznie dodać wymagane parametry do pliku postgresql.auto.conf oraz stworzyć standby.signal.
pgbackrest --stanza test --log-level-console=detail --type=standby --pg1-path=/data_pg restore
Następnie musimy się upewnić, że restore_command jest skonfigurowany poprawnie w postgresql.conf lub postgresql.auto.conf oraz sprawdzić, czy pgbackrest stworzył plik standby.signal.
grep restore_command /data_pg/postgresql.*

postgres@ubuntu:/data_pg$ ls /data_pg/standby.signal
/data_pg/standby.signal
Jeżeli plik nie istnieje, musimy go stworzyć. Po spełnieniu wszystkich wymagań jesteśmy gotowi do wystartowania klastra.
touch /data_pg/standby.signal/usr/lib/postgresql/15/bin/pg_ctl -D /data_pg/ start
Plik standby.signal to sygnał dla postgresa, że powinien wystartować jako instancja standby, tylko do odczytu. Jeżeli w konfiguracji mielibyśmy primary_conn_info, postgres próbowałby rozpocząć strumieniowanie zmian. Jeżeli parametr nie istnieje lub jest pusty, postgres spróbuje odtworzyć wszystkie dostępne pliki WAL z archiwum i będzie je monitorował w poszukiwaniu nowych.
Możemy się przyjrzeć temu bliżej w pliku loga znajdującym się w /data_pg/log. Przykład poniżej:
2023-09-12 20:42:22.845 UTC [4554] LOG: entering standby mode
2023-09-12 20:42:23.337 UTC [4554] LOG: restored log file "000000010000000000000005" from archive
2023-09-12 20:42:23.347 UTC [4554] LOG: redo starts at 0/5000028
2023-09-12 20:42:23.699 UTC [4554] LOG: restored log file "000000010000000000000006" from archive
2023-09-12 20:42:24.026 UTC [4554] LOG: consistent recovery state reached at 0/5000100
2023-09-12 20:42:24.027 UTC [4550] LOG: database system is ready to accept read-only connections
2023-09-12 20:42:25.345 UTC [4554] LOG: waiting for WAL to become available at 0/7000018
2023-09-12 20:42:55.291 UTC [4554] LOG: waiting for WAL to become available at 0/7000018
2023-09-12 20:42:59.973 UTC [4554] LOG: restored log file "000000010000000000000007" from archive
2023-09-12 20:43:00.929 UTC [4554] LOG: waiting for WAL to become available at 0/8000018
2023-09-12 20:44:00.212 UTC [4554] LOG: restored log file "000000010000000000000008" from archive
Możemy zobaczyć, że w pierwszej linii postgres wszedł w tryb standby, odtworzył kilka plików WAL z archiwum, odtworzył je, a następnie otworzył bazę do odczytu po osiągnięciu spójnych danych. Potem monitorował archiwum plików WAL w poszukiwaniu kolejnych logów i natychmiast pobierał je i odtwarzał.
Śledząc odtwarzane pliki WAL, warto zwrócić uwagę, że na instancji, która jest bezczynna, parametr archive_timeout nie spowoduje rotacji pliku WAL, ponieważ niczego w nim nie ma. Dlatego chcąc sprawdzić, czy odtwarzanie rzeczywiście działa, możemy wykonać "pgbackrest check", które wymusi rotację loga i spowoduje odtworzenie go na replice.
Jako użytkownik postgres wykonujemy instrukcję "pgbackrest check", aby wymusić zmianę pliku WAL oraz archiwizację starego.
pgbackrest --stanza test --log-level-console=detail check
Wróciwszy na serwer repliki, możemy w logu zobaczyć informację, że świeżo zarchiwizowany plik WAL został natychmiast pobrany i odtworzony. Sprawdzając logi znajdujące się w katalogu /data_pg/log jako użytkownik postgres, nazwę loga powinniśmy dostosować do swojego aktualnego pliku, z najnowszą datą i godziną.
ls -latr /data_pg/log
less /data_pg/log/postgresql-2023-09-12_204222.log
Opóźnienie odtwarzania w WAL shipping replice możemy sprawdzić za pomocą poniższego zapytania.
Warto zwrócić uwagę, że nie zawsze pokazuje ono rzeczywiste opóźnienie. W przypadku środowiska testowego, które stworzyliśmy, lag może być widoczny w minutach lub godzinach, ponieważ zapytanie oblicza różnicę czasu pomiędzy aktualnym czasem a ostatnią odtworzoną transakcją. Jeżeli nie wykonujemy żadnych zmian na klastrze primary, nic nie będzie się odtwarzało na replice, przez co lag będzie cały czas wzrastał. Ale wystarczy stworzyć jakiś testowy objekt, lub wykonać dowolny DML, i lag powinien spaść do minimum po zarchiwizowaniu i odtworzeniu pliku WAL zawierającego tą zmianę.
Jeżeli lag na replice pg2 jest widoczny w minutach, spróbujmy go "naprawić". Poniższe wykonujemy z poziomu psql:
postgres=# select to_char((extract(epoch from now() - pg_last_xact_replay_timestamp())|| ' second')::interval, 'HH24:MI:SS') AS apply_lag;
Stwórzmy obiekt na instancji primary (pg1) z poziomu psql:
CREATE TABLE napraw_laga(x int);
Następnie wymusimy archiwizację pliku WAL na serwerze z backupami (Host 5) jako użytkownik systemowy postgres:
pgbackrest --stanza test --log-level-console=detail check
Ponownie na replice pg2 sprawdźmy w logu postgresa, czy kolejny WAL się odtworzył:
less /data_pg/log/<najnowszy_plik_loga>.log
A w psql sprawdźmy, czy lag się zmniejszył:
postgres=# select to_char((extract(epoch from now() - pg_last_xact_replay_timestamp())|| ' second')::interval, 'HH24:MI:SS') AS apply_lag;


Komentarze (0)
Brak komentarzy...