
[ Do realizacji przykładów z tego rozdziału potrzebujemy hostów 1 i 2. Należy je przygotować według tej instrukcji ]
W replikacji strumieniowej, hot standby, wszystkie wpisy WAL zostają najpierw zapisane w pamięci "WAL buffers", następnie wywoływany jest fsync, który utrwala je lokalnie na dysku w plikach WAL. Pliki WAL zawierają informacje o wszystkich zmianach zachodzących w bazie danych oraz podzielone są na 16 MB segmenty. Następnie postgres za pomocą procesu "walsender" wysyła te wpisy do klastra standby, która za pomocą procesu "wal receiver" odbiera je i zapisuje do plików WAL na serwerze standby i natychmiast odtwarza zmiany z odebranego wpisu, dzięki czemu dane są dostępne do odczytu niemal w tym samym momencie, najczęściej w ciągu kilku milisekund na klastrze standby w przypadku replikacji asynchronicznej lub w tym samym momencie w przypadku replikacji synchronicznej.
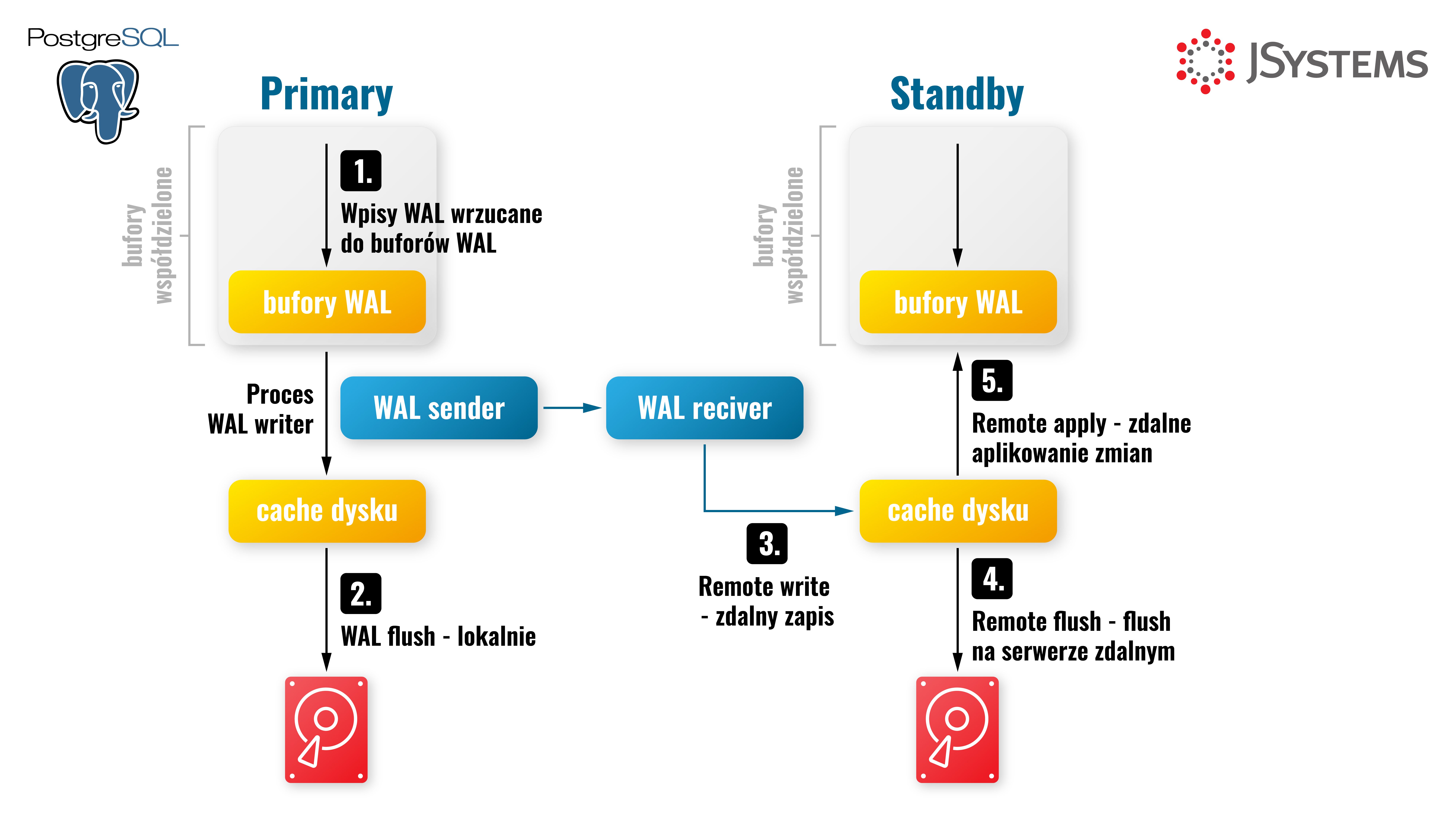
Sposób, w jaki dane są przesyłane i odtwarzane, sprawia, że instancja primary i wszystkie repliki są dokładnymi kopiami, 1 do 1. Mają dokładnie taki sam rozmiar i w każdym bloku danych przechowywane są dokładnie te same wiersze.
Domyślnie replikacja strumieniowa działa w trybie asynchronicznym, ale możemy to w bardzo łatwy sposób zmienić, przyjrzymy się temu nieco później.
Jednym z ważniejszych parametrów dla replikacji strumieniowej, szczególnie tej synchronicznej, ale nie tylko, jest "synchronous_commit". Określa on, kiedy transakcja zwróci informację o udanym commicie do klienta. Za jego pomocą możemy "sterować" szybkością commitów oraz trwałością danych, im niższa trwałość, tym większa przepustowość transakcji na sekundę.
Poziomy synchronous_commit:
Parametr synchronous_commit możemy ustawić na poziomie transakcji, sesji, dla użytkownika lub całej instancji. Ustawienie go na "off" jest przydatne w sytuacji, kiedy planujemy ładowanie dużej liczby danych lub w trakcie migracji danych między systemami. Wyłączony commit synchroniczny może bardzo obniżyć generowane obciążenie na serwerze oraz przyspieszyć całą operację, ponieważ fsync jest wywoływany tylko raz na 200ms, przy domyślnych ustawieniach, a nie dla każdego wpisu z osobna.
W replikacji strumieniowej parametrem "synchronous_standby_names" określamy wymagania co do replikacji synchronicznej. Które serwery powinny być replikowane synchroniczne, jakie oczekiwania mamy względem replik. Które i ile z nich będzie odtwarzało synchronicznie transakcje z instancją primary i kiedy możemy zwrócić informację o zakończeniu transakcji z repliki do primary. Domyślnie parametr jest pusty, co oznacza, że replikacja będzie działała jako asynchroniczna.
Parametr przyjmuje wartości:
Wartości "application_nameX" to nazwy replik, które możemy znaleźć w widoku pg_stat_replication w kolumnie application_name, a które możemy ustawić na replice, aktualizując parametr "primary_conninfo".
Przykładowo: primary_conninfo = 'application_name=pg2 user=replicator password=tajnehaslo host=192.168.33.10 port=5432'.
Chcąc korzystać z replikacji synchronicznej, musimy zagwarantować bardzo szybkie połączenie z jak najniższymi opóźnieniami pomiędzy serwerami postgresa. Najlepiej jeżeli oba serwery byłyby w tej samej serwerowni, ponieważ każde opóźnienie w odtwarzaniu na replice nie pozwoli zakończyć transakcji na instancji głównej. Konfigurując replikację synchroniczną, musimy liczyć się z tym, że każda transakcja będzie trwała minimalnie dłużej o "roundtrip time", czyli czas potrzebny na wysłanie pakietu z primary na replikę i z powrotem, ponieważ każda pojedyncza transakcja będzie musiała być zatwierdzona przez oba serwery przed poinformowaniem aplikacji o sukcesie lub błędzie w wykonywaniu transakcji.
Przed stworzeniem repliki strumieniowej na instancji głównej musimy upewnić się, że mamy ustawione wszystkie potrzebne parametry i stworzyć użytkownika z prawem replikacji oraz dodatkowymi uprawnieniami wymaganymi przez pg_rewind, czyli narzędzie służące do synchronizacji katalogów PGDATA w celu ponownego podłączenia do replikacji. Na przykład po wykonaniu awansowaniu repliki na instancję primary możemy wykonać pg_rewind w celu synchronizacji katalogów z danymi i ponownego podłączenia starego serwera primary jako replika do nowego serwera głównego. Jako użytkownik systemowy postgres edytujemy plik /data_pg/postgresql.conf i zmieniamy poniższe parametry:
vi /data_pg/postgresql.conf
listen_addresses = '*'
wal_level = replica
wal_log_hints = on
max_wal_senders = 5
max_replication_slots = 5
logging_collector = on
Ustawione powyżej parametry to:
Ostatnim parametrem jest wal_log_hints. Odpowiada on za zapisywanie pełnych bloków danych do plików WAL po pierwszej modyfikacji każdego bloku po checkpoincie. Włączając to ustawienie, możemy też sprawdzić, o ile więcej plików WAL postgres wygeneruje po włączeniu sum kontrolnych. Do jego zmiany musimy zrestartować postgresa. Jest to jedno z wymagań pg_rewind. Następnie z poziomu użytkownika systemowego postgres logujemy się do psql. Tworzymy użytkownika replicator, który powinien mieć uprawnienia superusera lub możliwość czytania plików w katalogu z danymi z poziomu postgresa. Ze względów bezpieczeństwa polecam nadać tylko wymagane uprawnienia, lista potrzebnych funkcji poniżej:
# restart klastra
# dla Ubuntu
postgres@ubuntu:~$ /usr/lib/postgresql/15/bin/pg_ctl -D /data_pg restart# dla CentOS
[postgres@centos ~]$ /usr/pgsql-15/bin/pg_ctl -D /data_pg restartpostgres@ubuntu:~$ psql
create user replicator with replication password 'tajnehaslo';
GRANT EXECUTE ON function pg_catalog.pg_ls_dir(text, boolean, boolean) TO replicator;
GRANT EXECUTE ON function pg_catalog.pg_stat_file(text, boolean) TO replicator;
GRANT EXECUTE ON function pg_catalog.pg_read_binary_file(text) TO replicator;
GRANT EXECUTE ON function pg_catalog.pg_read_binary_file(text, bigint, bigint, boolean) TO replicator;
Następnie musimy dodać wpis do /data_pg/pg_hba.conf umożliwiający połączenie dla replikacji oraz przeładować konfigurację.
vi /data_pg/pg_hba.conf
host replication replicator <X.X.X.X IP adres serwera standby>/32 scram-sha-256psql -c "select pg_reload_conf()"
Teraz możemy rozpocząć stawianie nowej repliki na jednym z hostów za pomocą narzędzia pg_basebackup. Parametry to kolejno: -h adres serwera, -U użytkownik, -C stwórz slot replikacyjny, -S nazwa slota replikacyjnego, -R dopisz konfigurację umożliwiającą strumieniowanie, -D docelowy katalog z danymi, -X strumieniowanie wpisów WAL, -P wyświetlanie postępu prac nad kopią. Wykonujemy to z poziomu użytkownika systemowego postgres:
pg_basebackup -h <X.X.X.X IP adres serwera primary> -U replicator -C -S pg2 -R -D /data_pg -X stream -P
Zostaniemy zapytani o hasło użytkownika "replicator". Jeżeli wszystko było wykonane według przykładów, to hasłem tutaj będzie "tajnehaslo". Jeżeli nie chcielibyśmy podawać hasła przy tworzeniu repliki, możemy
stworzyć sobie plik .pgpass:
postgers@pg2:~$ cat <<EOF > ~postgres/.pgpass
<X.X.X.X>:5432:*:replicator:tajnehaslo
EOF
Aby ułatwić sobie identyfikację replik, dodajemy w pliku /data_pg/postgresql.auto.conf "application_name=pg2" w parametrze "primary_conninfo", np.
primary_conninfo = 'application_name=pg2 user=replicator password=tajnehaslo channel_binding=prefer host=192.168.33.10 port=5432 sslmode=prefer sslcompression=0 sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any'
primary_slot_name = 'pg2'
Application name,może przyjmować dowolną wartość. Najważniejsze, żeby ułatwiała identyfikację serwera, na którym dana replika działa.
Na koniec uruchamiamy serwer slave:
pg_ctl -D /data_pg/ start
Status replikacji możemy sprawdzić na instancji primary za pomocą widoku pg_stat_replication.
Wyświetla on informacje o id procesu walsender dla każdej repliki, użytkownika, który jest wykorzystywany do replikacji, nazwę aplikacji, którą ustawiliśmy w "primary_conninfo" na replice, serwer, na który dane są replikowane oraz informacje o stanie replikacji.
Kolumna state może przyjmować wartości "streaming", jeżeli aktualnie przesyła wpisy WAL do procesu walreceiver, catchup, jeżeli standby aktualnie odtwarza logi transakcyjne z archiwum, startup w momencie startu replikacji, backup jeżeli wykonujemy kopię klastra za pomocą pg_basebackup, oraz stopping, kiedy proces jest zatrzymywany.
Kolejnymi wartościami są sent_lsn, write_lsn, flush_lsn, replay_lsn oraz write_lag, flush_lag, replay_lag. Sent_lsn to ostatnia lokacja wpisu w pliku WAL wysłanego na replikę, write_lsn to ostatni wpis zapisany w pliku WAL na dysku repliki, flush_lsn to ostatnia lokacja w pliku WAL, która została przeczytana i zapisana w plikach danych. Ale to, że została tam zapisana, nie oznacza, iż dane są dostępne do odczytu. Ten następuje po "odtworzeniu" wpisu oraz udostępnieniu do odczytu, czyli wartość replay_lsn.
# \x - widok rozszerzony - extended view. Sprawia, że każdy wiersz jest
# wyświetlany jako osobny wpis, nazwy kolumn po lewej, wartość po prawej
postgres=# \x
postgres=# select * from pg_stat_replication where application_name ='pg2';
-[ RECORD 1 ]----+------------------------------
pid | 6315
usesysid | 16384
usename | replicator
application_name | pg2
client_addr | 192.168.56.12
client_hostname |
client_port | 42572
backend_start | 2023-08-14 20:08:19.624098+00
backend_xmin |
state | streaming
sent_lsn | 0/12000000
write_lsn | 0/12000000
flush_lsn | 0/12000000
replay_lsn | 0/12000000
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2023-08-14 20:53:01.8204+00
Stworzona w ten sposób replikacja to replikacja asynchroniczna. Fakt ten możemy potwierdzić w widoku pg_stat_replication, w kolumnie sync_state.
Chcąc przełączyć replikację na synchroniczną, musimy zaktualizować parametr "synchronous_standby_names", dodając do niego nazwę repliki lub listę replik, które chcemy używać jako repliki synchroniczne.
Przykładowo z poziomu konsoli psql:
alter system set synchronous_standby_names to 'pg2';
select pg_reload_conf();postgres=# select * from pg_stat_replication where application_name ='pg2';
-[ RECORD 1 ]----+------------------------------
pid | 6315
usesysid | 16384
usename | replicator
application_name | pg2
client_addr | 192.168.56.12
client_hostname |
client_port | 42572
backend_start | 2023-08-14 20:08:19.624098+00
backend_xmin |
state | streaming
sent_lsn | 0/12000000
write_lsn | 0/12000000
flush_lsn | 0/12000000
replay_lsn | 0/12000000
write_lag |
flush_lag |
replay_lag |
sync_priority | 1
sync_state | sync
reply_time | 2023-08-14 20:53:11.852902+00
Tym sposobem zmieniliśmy typ replikacji z asynchronicznej na synchroniczną. Poziom synchronizacji w replikacji synchronicznej określamy parametrem synchronous_commit, który opisany był wcześniej. W ramach powtórki wybrać możemy opcje: remote_write - transakcja czeka na informację zwrotną z instancji standby o zapisaniu wpisu WAL na dysku, write_lsn, on - transakcja czeka na informację o zakończonym flushu danych z wpisu WAL, czyli dane są utrwalone na dysku, ale jeszcze niekoniecznie widoczne dla aplikacji, flush_lsn, lub remote_apply - transakcja na primary czeka na informację zwrotną ze standby o odtworzeniu transakcji na replice, czyli dane mogą być odczytane na replice, replay_lsn.
Status replikacji możemy też sprawdzić na replice w widoku pg_stat_wal_receiver. Możemy w nim znaleźć informacje podobne do pg_stat_replication na instancji primary, a dodatkowo informację o czasie ostatniej wymiany wiadomości, przykładowo sprawdzenie przez replikę, czy primary jest dostępny, hot standby feedback - wiadomości o aktywnych transakcjach na replice czy status replikacji z serwera standby.
postgres=# select * from pg_stat_wal_receiver;
pid | 4841
status | streaming
receive_start_lsn | 0/32000000
receive_start_tli | 2
written_lsn | 0/320000D8
flushed_lsn | 0/320000D8
received_tli | 2
last_msg_send_time | 2023-07-11 20:19:17.897255+00
last_msg_receipt_time | 2023-07-11 20:19:17.972795+00
latest_end_lsn | 0/320000D8
latest_end_time | 2023-07-11 20:19:17.972795+00
slot_name | pg2
sender_host | 192.168.33.10
sender_port | 5432
conninfo | user=replicator password=******** channel_binding=prefer dbname=replication host=192.168.33.10 port=5432 application_name=pg3 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any
Podczas wywoływania polecenia pg_basebackup użyliśmy przełączników -C -S <nazwaslota>, aby stworzyć slot replikacyjny, który zagwarantuje nam, że wszystkie pliki WAL wymagane przez replikację były przechowywane przez instancję primary do czasu wykorzystania ich przez replikę.
Wypisać wszystkie istniejące sloty możemy poleceniem:
postgres=# select * from pg_replication_slots;
Stworzenie ręczne nowego fizycznego slota replikacyjnego odbywa się za pomocą polecenia:
postgres=# select pg_create_physical_replication_slot('replika_pg2');Warto raz na jakiś czas sprawdzić, czy wszystkie sloty są aktywne i konsumują pliki WAL, ponieważ nieaktywne sloty replikacyjne mogą prowadzić do przetrzymywania plików WAL w nieskończoność i spowodować przepełnienie dysku, a w efekcie zatrzymanie postgresa. Niepotrzebne sloty replikacyjne możemy usunąć poleceniem:
postgres=# select pg_drop_replication_slot('replika_pg2');


Komentarze (0)
Brak komentarzy...