
Bazy danych zawierają jeden lub więcej schematów, w których znajdują się obiekty bazodanowe. Podział na schematy nie wiąże się z podziałem fizycznym, jest to tylko podział logiczny. Umożliwiają posiadanie kilku tabel o tej samej nazwie, ale w różnych schematach. Pozwalają też łatwiej zarządzać obiektami bazy danych dzięki zorganizowaniu w podgrupy, a takze zbiorowe nadawanie i odbieranie uprawnień do obiektów. Aby sprawdzić, jakie schematy mamy w bazie, do której jesteśmy podłączeni, oraz kto jest ich właścicielem, wystarczy wywołać:
select * from information_schema.schemata;
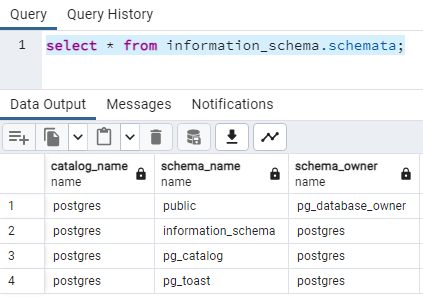
Każda nowo tworzona baza będzie posiadała 4 domyślne schematy. Schematy "information_schema" i "pg_catalog" to schematy na słowniki systemowe. Słownik "schemata" znajduje się w "information_schema", ale już "pg_database" i inne zaczynające się od "pg_" mieszczą się w schemacie "pg_catalog". Schemat "pg_toast" to schemat wykorzystywany przez mechanizm przechowywania wierszy większych niż jeden blok danych (8kB). Więcej na ten temat można się dowiedzieć tutaj: https://wiki.postgresql.org/wiki/TOAST
Schemat "public" to domyślny schemat przeznaczony na obiekty użytkowników. Do wersji 14 włącznie każdy użytkownik mógł tworzyć w nim swoje obiekty, miał też dostęp tylko do swoich obiektów. Od wersji 15 trzeba nadać dodatkowe uprawnienie, by było jak w poprzednich wersjach.
Sprawdźmy to. Stworzyłem dwóch użytkowników:
create user andrzej with password 'jsystems';
create user rafal with password 'jsystems';
Następnie próbuję zalogować się na użytkownika andrzej i stworzyć tabelę. Użyłem tu konsoli psql, którą miałem zainstalowaną na komputerze (w związku z tym, że na komputerze mam zainstalowanego PostgreSQL), ale równie dobrze można stworzyć nowe połączenie w PgAdmin4, Dbeaver czy innym cliencie baz PostgreSQL. Próba stworzenia tabeli (w domyślnym schemacie public) nie powiodła się:
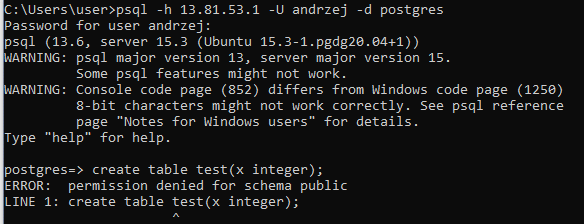
Wynika to z tego, że serwer jest w wersji 15, więc aby nowi użytkownicy mogli tworzyć swoje obiekty, muszę jako użytkownik postgres nadać im takie uprawnienia:
grant create on schema public to andrzej;
Po nadaniu uprawnień ponownie tworzę tabelę jako użytkownik andrzej. Nie muszę się przelogowywać, zmiana uprawnień następuje od razu. Tym razem udaje mi się stworzyć tabelę:

Jako użytkownik, który stworzył tę tabelę, mam dostęp do jej zawartości. Sprawdźmy teraz, czy drugi użytkownik będzie miał uprawnienia do tabeli “test” utworzonej przez użytkownika “andrzej”. Dodam uprawnienie do schematu “public” użytkownikowi “rafal” tak, by dostęp do schematu nie blokował nas:
grant create on schema public to rafal ;
Następnie łączę się do serwera jako użytkownik “rafał” i usiłuję zajrzeć do tabelki “test”:

Użytkownik “rafal” widzi tabelkę “test”, ale nie może się do niej dostać, co widzimy w dolnej części screena.
Jeśli chcesz odebrać możliwość tworzenia obiektów przez użytkowników w schemacie public, możesz odebrać uprawnienie "create" grupie "public", do której przypisani są wszyscy użytkownicy i z której uprawnień wynika możliwość tworzenia obiektów w schemacie "public":
revoke create on schema public from public;
W schemacie mogą znajdować się różne obiekty - tabele, indeksy, sekwencje itp. Dla każdego z rodzajów obiektów istnieje osobny słownik. W każdym takim słowniku zawarta jest informacja o schemacie, w którym znajduje się dany obiekt. Dla tabel będzie to:
select * from pg_tables;
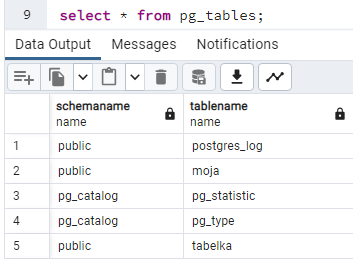
Dla indeksów będzie to:
select * from pg_indexes;
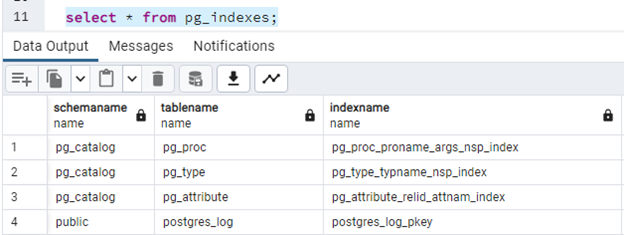
Najprostszy sposób tworzenia schematu:
create schema nazwa_schematu;
W takiej sytuacji właścicielem schematu będzie użytkownik, który go tworzy. Można też stworzyć schemat tak, by inny użytkownik był jego właścicielem:
create schema andrew authorization andrzej;
Sprawdźmy teraz, kto jest właścicielem tego schematu:
select schema_name, schema_owner from information_schema.schemata where schema_name='andrew';
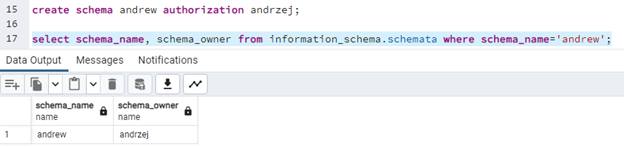
Właściciel schematu będzie mógł skasować cały schemat, a także pojedynczo tabele w nim zawarte. Należy zwrócić uwagę na różnicę w uprawnieniach właściciela przestrzeni tabel, bazy danych i schematów.
Jeśli nie zmieniłeś zmiennej "search_path", to każdy nowo tworzony obiekt będzie umieszczany w schemacie "public". Jeśli chcesz stworzyć obiekt w określonym schemacie, musisz podać przed jego nazwą nazwę schematu:
create table dane.produkty(
id_produktu serial primary key,
nazwa_produktu text
);
Domyślnie, gdy odniesiesz się do jakiejś tabeli PostgreSQL, będzie poszukiwał jej najpierw w schemacie o nazwie takiej, jak nazwa użytkownika (o ile taki istnieje), następnie schemat "public". Wynika to z domyślnego ustawienia zmiennej "search_path". Jeśli więc w którymś z tych schematów istnieje tabela, to odnosimy się do niej bezpośrednio po nazwie, nie podając nazwy schematu:
select * from tabela;
Jeśli natomiast chcesz odwołać się do tabeli znajdującej się w innym schemacie niż te pojawiające się w "search_path", musisz poprzedzić nazwę tabeli nazwą schematu:
select * from schemat.tabela;
Parametr "search_path" określa nazwy schematów, które są przeszukiwane, gdy odniesiesz się do tabeli bez podawania schematu. Domyślna zawartość tego parametru wygląda następująco:

Taka wartość oznacza, że przeszukiwane będą: schemat o nazwie tej samej co nazwa użytkownika (o ile taki istnieje) oraz schemat public. Nie będą zatem przeszukiwane inne schematy. By dostać się do obiektu znajdującego się w innym schemacie, trzeba nazwę obiektu poprzedzić nazwą schematu. Parametrem tym możemy sterować, co będzie wpływać na to, gdzie PostgreSQL poszuka tabel. Pokażę to na przykładzie. Tworzę dwa schematy i umieszczam w nich po jednej tabeli. Obie tabele będą miały tę samą nazwę, choć znajdą się w różnych schematach. Do każdej z tabel wstawiam po wierszu, po zawartości którego będzie łatwo rozpoznać rodzaje tabel:
create schema schemat_a;
create schema schemat_b;
create table schemat_a.data(x text);
create table schemat_b.data(x text);
insert into schemat_a.data values ('w schemacie a');
insert into schemat_b.data values ('w schemacie b');
W tej chwili mam cały czas domyślnie ustawiony "search_path", więc próba dostępu do tabeli "data" skończy się niepowodzeniem, ponieważ nie mam schematu o takiej nazwie jak użytkownik, a w schemacie "public" nie mam tabeli o takiej nazwie:
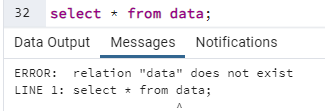
Ustawiam "search_path" tak, by PostgreSQL najpierw szukał w schemacie "schemat_a", a po nim w schemacie "schemat_b". Zaglądam do tabeli:
set search_path=schemat_a,schemat_b;
select * from data;
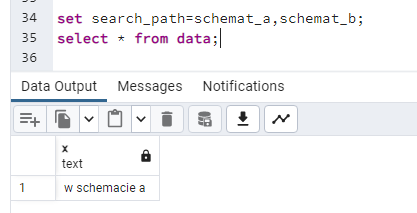
Ustawienie tego parametru poprzez “SET” ustawia go tylko w ramach aktualnej sesji! Wyświetla się zawartość tabeli znajdującej się w schemacie "schemat_a". Ten schemat jest wymieniony jako pierwszy w "search_path". Zamieniam schematy kolejnością i sprawdzam ponownie:
set search_path=schemat_b,schemat_a;
select * from data;
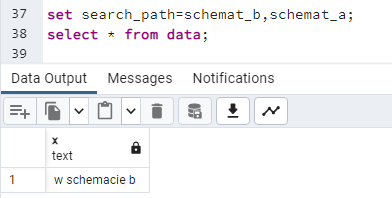
Tym razem otrzymałem dane z tabeli znajdującej się w schemacie "schemat_b".
W rzeczywistości przeszukiwany jest jeszcze jeden schemat - "pg_catalog", czyli schemat zawierający słowniki systemowe. Dzięki temu, odwołując się do słowników, można odwołać się na przykład:
select * from pg_database;
zamiast:
select * from pg_catalog.pg_database;
Wprawdzie schemat pg_catalog jest przeszukiwany, ale dzieje się to na końcu.
Tworzę prostą tabelę i sprawdzam, w jakim schemacie się znajduje:
create table do_przeniesienia(x integer);
select schemaname from pg_tables where tablename='do_przeniesienia';
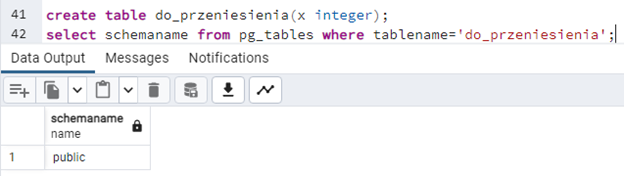
Tworzę dodatkowy schemat i zamierzam przenieść tabelę "do_przeniesienia" do niego. Przenieść pojedynczy obiekt do innego schematu możemy w ten sposób:
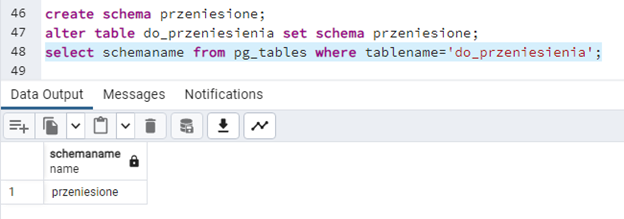
create schema przeniesione;
alter table do_przeniesienia set schema przeniesione;
select schemaname from pg_tables where tablename='do_przeniesienia';
Po tej operacji tabela znajduje się już w nowym schemacie:
Indeksy tworzone na tabelach będą zawsze lądowały w tym samym schemacie, w którym znajdzie się tabela. Nie ma możliwości rozdzielenia ich położenia. Tworzę nowy schemat, umieszczam w nim tabelę, zakładam na niej indeks i sprawdzam, gdzie ten indeks się znajduje:
create schema schema_a;
create table schema_a.my_table(x integer);
create index my_index on schema_a.my_table(x);
select * from pg_indexes where indexname='my_index';
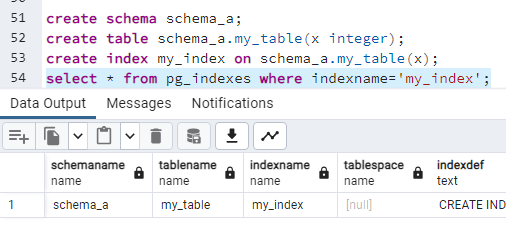
Indeks znalazł się w schemacie "schema_a", a więc tam, gdzie znajduje się tabela, na którą założyliśmy indeks.
Istnieje możliwość zmiany właściciela schematu. Właściciel schematu może nadawać uprawnienia np. USAGE i CREATE na schemacie, ale bycie właścicielem schematu nie determinuje jakichkolwiek praw do obiektów w tym schemacie. Takie uprawnienia trzeba nadać osobno! W mojej bazie istnieje schemat o nazwie "schema_a". Sprawdźmy, kto jest jego właścicielem:
select schema_name,schema_owner
from information_schema.schemata
where schema_name='schema_a';
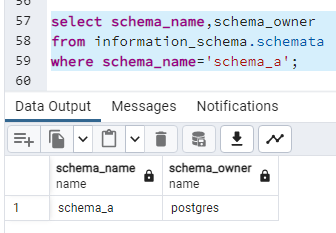
W tej chwili właścicielem jest użytkownik "postgres". Zmieniam właściciela schematu i ponownie sprawdzam, kto jest jego właścicielem:
alter schema schema_a owner to mapet;select schema_name,schema_owner
from information_schema.schemata
where schema_name='schema_a';
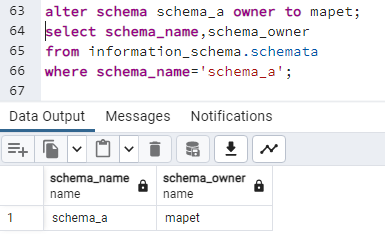
Po tej zmianie właścicielem schematu "schema_a" jest użytkownik "mapet".
Domyślnie użytkownicy nie mają uprawnień do schematów, których nie są właścicielami. Do wersji 14 włącznie nie dotyczyło to schematu "public", w którym każdy użytkownik mógł tworzyć swoje obiekty i zarządzać nimi. Od wersji 15 należy nadać osobno uprawnienie, by to było możliwe. Przetestujmy. Tworzę użytkownika “kapitan_bomba”:
create user kapitan_bomba with password 'k****noksy';
Loguję się na tego użytkownika za pomocą konsoli psql i próbuję utworzyć tabelę:
create table qwe(x integer);
Tabeli nie udaje mi się stworzyć:

Dodaję więc temu użytkownikowi uprawnienie do tworzenia obiektów w schemacie public:
grant create on schema public to kapitan_bomba;
Ponowna próba stworzenia tabeli jako użytkownik kończy się powodzeniem:

Podobnie jest z innymi schematami. Do wersji 14 do tworzenia obiektów w schemacie public nie trzeba było dawać osobno uprawnień. Użytkownik mógł tworzyć obiekty w schemacie public. Dla innych schematów trzeba było dodawać uprawnienia, a public był wyjątkiem. Od wersji 15 uprawnienia nadajemy zarówno do publica jak i każdego innego schematu. Niezależnie od tego, że możemy tworzyć i zaglądać do obiektów, które stworzyliśmy w schemacie “public”, nie możemy zajrzeć do obiektów innych użytkowników.
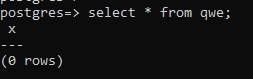
Pojawia się jednak pewna różnica między schematem public a innymi schematami. Stworzyliśmy tabelę “qwe” w schemacie public i możemy do niej zajrzeć:
Tworzę teraz schemat “boczny” i nadaję naszemu użytkownikowi “kapitan_bomba” uprawnienie “create” w tym schemacie:
create schema boczny;
grant create on schema boczny to kapitan_bomba;
Następnie jako użytkownik “kapitan_bomba” tworzę tabelę i usiłuję do niej zajrzeć:
create table boczny.xyz(x integer);
select * from boczny.xyz;
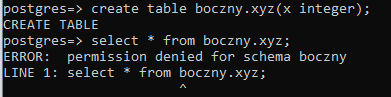
Okazuje się, że nie mogę zajrzeć do tabeli, którą przed momentem stworzyłem, co jest dosyć niespodziewane. Czemu tak się dzieje? Wynika to z faktu braku nadania uprawnienia “usage” na schemacie “boczny” nadanego temu użytkownikowi. I tu się ujawnia różnica pomiędzy schematem “public” (gdzie można było zajrzeć do stworzonej tabeli) a innymi schematami. Nadaję teraz brakujące uprawnienie użytkownikowi:
grant usage on schema boczny to kapitan_bomba;
Ponownie zaglądam do tabeli jako “kapitan_bomba”:
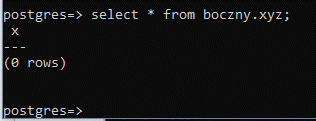
Tym razem udało się zajrzeć do tabeli. Uprawnienie “usage” nadane na schemacie “boczny” nie daje uprawnień do innych obiektów w tym schemacie. Zweryfikujmy to. Jako użytkownik “postgres” tworzę w schemacie “boczny” nową tabelę “rty”:
create table boczny.rty(x integer);
Następnie próbuję dostać się do tej tabeli jako użytkownik “kapitan_bomba”:
select * from boczny.rty;

Tworzę schemat i sprawdzam jego istnienie:
create schema pierwotna_nazwa;
select * from information_schema.schemata;
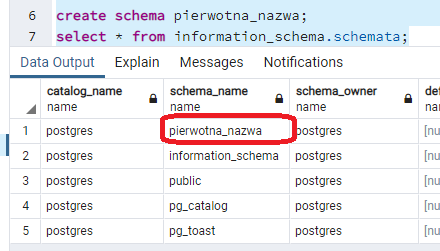
Aby zmienić nazwę schematu, wykonuję polecenie:
alter schema pierwotna_nazwa rename to zmieniona_nazwa;
Następnie ponownie sprawdzam dostępne schematy:
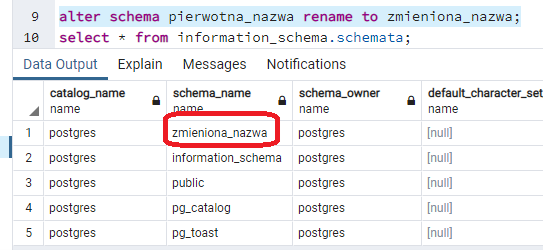
Pusty schemat możemy skasować takim poleceniem:
drop schema nazwa_schematu;
Jeśli jednak w schemacie takim znajduje się jakiś obiekt, nie uda nam się skasować tego schematu. Na potrzeby przykładu tworzę schemat i umieszczam w nim tabelę. Następnie usiłuję skasować ten schemat:
create schema do_usuniecia;
create table do_usuniecia.tabelka(x integer);
drop schema do_usuniecia;

PostgreSQL poinformował o istnieniu obiektów w tym schemacie i zapobiegł jego usunięciu. Możemy teraz sprawdzić, jakie obiekty znajdują się w tym schemacie:
select * from pg_tables where schemaname='do_usuniecia';
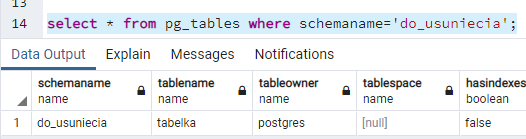
Możemy przenieść obiekty za pomocą komendy:
alter table do_usuniecia.tabelka set schema public;
albo skasować schemat wraz z zawartością:
drop schema do_usuniecia cascade;


Komentarze (0)
Brak komentarzy...