
Czym są transakcje? Obrazuje to prosty przykład przelewów w banku. Wyobraźmy sobie taką sytuację. Jeden klient przelewa pewną kwotę drugiemu. System już zdążył pobrać kwotę z konta przelewającego, po czym następuje awaria. Kwota nie pojawia się na koncie beneficjenta. Czy może to tak działać? Obie operacje – pomniejszenia stanu konta jednego klienta i powiększenia innego muszą wykonać się razem albo żadna z nich nie powinna się wykonać. Do tego celu potrzebujemy właśnie transakcji.
"Transakcje to zbiór operacji na bazie danych, które stanowią w istocie pewną całość i jako takie powinny być wykonane wszystkie lub żadna z nich" - za Wikipedią.
Domyślnie w PostgreSQL każda operacja DML (insert, update, delete, merge) i DDL (create table etc.) jest automatycznie zatwierdzana. Gdyby więc w opisywanej wyżej sytuacji z przelewem wykonać przelew jako dwie operacje update, każda z nich byłaby natychmiast zatwierdzana. Jeśli więc po pierwszym update doszłoby do awarii i drugi nie zostałby wykonany, uzyskalibyśmy opisaną niepożądaną sytuację. Jeśli chcielibyśmy, żeby zostały wykonane obie operacje albo żadna z nich, musielibyśmy umieścić je we wspólnej transakcji. Transakcją mogą zostać objęte zarówno polecenia DML jak i DDL. Transakcję rozpoczynamy komendą "begin" bądź "begin work". Zatwierdzamy za pomocą "commit" bądź "commit work". Wycofujemy za pomocą "rollback" lub "rollback work". We wszystkich przypadkach słowo "work" jest fakultatywne i niepowiązane z wcześniejszym użyciem bądź nie danego słowa. Zmiany niezatwierdzone (jawnie bądź nie) "commitem" nie będą widoczne dla innych sesji.
Chcąc wykonać wiele operacji w ramach jednej transakcji, musimy rozpocząć od "begin" lub "begin work", wykonać te operacje, a następnie zatwierdzić operację za pomocą "commit" albo "commit work":
begin;
update konta set stan_konta=stan_konta-100 where id_konta=123;
update konta set stan_konta=stan_konta+100 where id_konta=456;
commit;
W przypadku gdybyśmy chcieli wycofać jakąś operację, stosujemy komendę "rollback" lub "rollback work". Pamiętać należy, że komenda ta wycofuje tylko niezatwierdzone jeszcze "commitem" zmiany. Gdybyśmy więc wykonali taki kod:
begin
insert into .....;
commit;
update ....;
rollback;
to rollback wycofałby tylko update, ponieważ insert został już zatwierdzony. Gdybyśmy wykonali taki kod (zwróć uwagę na brak begin na początku):
insert into ....;
update ....;
rollback;
to rollback nie wycofałby nic, ponieważ nie rozpoczęliśmy transakcji i każda operacja była automatycznie zatwierdzana!
Istnieją dwa tryby blokad:
Domyślnie w PostgreSQL działa blokada współdzielona. Jeśli jakaś sesja rozpocznie transakcję i zmieni dane, inne sesje do czasu zatwierdzenia owej transakcji będą mogły odczytywać oryginalną postać danych, ale nie będą mogły tych danych zmieniać.
Wiersze i tabele mogą być blokowane tylko w ramach transakcji. Po jej zakończeniu są natychmiast odblokowywane. Blokada może być nakładana niejawnie za pomocą komend "update" lub "delete" na wiersze, których dotyczyć będzie operacja, lub jawnie za pomocą komend "lock" lub "for update". W przypadku "update", "delete" i "for update" blokada będzie dotyczyć tylko tych wierszy, których dotyczy operacja. Blokowany jest zawsze cały wiersz.
Może dojść do sytuacji zakleszczenia. Na przykład sesje A i B rozpoczynają transakcję. Sesja A zmienia wiersze w tabeli X, sesja B zmienia wiersze w tabeli Y. Następnie sesja A usiłuje zmieniać wiersze zablokowane przez sesję B w tabeli Y, a sesja B usiłuje zmieniać wiersze zablokowane przez sesję A w tabeli X. Taki pat nazywamy zakleszczeniem. Obie sesje blokują się wzajemnie. Po pewnym czasie w jednej z sesji dostaniemy komunikat: „Deadlock detected”.
W celu uniknięcia zakleszczeń lub aby w międzyczasie ktoś nam nie zablokował wierszy, możemy jawnie zablokować wiersze lub tabelę. Dzięki temu będziemy mieli pewność, że zmiany wprowadzane przez inne sesje nie będą kolidowały z naszymi. Wiersze możemy zablokować komendą np.:
begin work;
select * from produkty where cena>500 for update;
Zadziała to jednak tylko wtedy, jeśli będziemy mieli rozpoczętą transakcję! Wiersze pozostaną zablokowane do czasu zakończenia naszej transakcji.
Możemy też zablokować całą tabelę:
begin work;
lock table produkty;
Tutaj mamy jednak aż dwa obostrzenia (Koronawirus lubi to). Po pierwsze, działa to tylko w ramach transakcji. Po drugie, blokuje wszelki dostęp do tabeli w tym odczyt, gdyż jest to blokada wyłączna (ekskluzywna)!
W systemach transakcyjnych często dochodzi do sytuacji, w której jakaś sesja usiłuje dokonać zmiany na wierszach zablokowanych przez transakcję innej sesji i w związku z tym czeka na zwolnienie blokady. Ta sesja mogła wcześniej zablokować inne zasoby, które usiłują zmieniać inne sesje itd. Tym sposobem blokady nam się nawarstwiają, aż w skrajnej sytuacji "zawiśnie" cały system korzystający z tej bazy danych. Skąd możemy wiedzieć, jakie blokady występują i kto je nakłada jakim zapytaniem? Możemy się tego dowiedzieć ze słownika "pg_locks". Zanim tam zajrzymy, musimy najpierw spowodować jakąś blokadę, byśmy mieli co analizować ;). W związku z tym tworzymy tabelę i umieszczamy w niej dane:
create table blokada(x integer, y numeric);
insert into blokada values (1,10);
Teraz logujemy się osobną sesją i spowodujemy założenie blokady na wstawiony do tej tabeli wiersz. W tym celu musimy rozpocząć transakcję:
begin;
update blokada set y=30;
Operacji umyślnie nie zatwierdzamy, by pozostawić trwającą blokadę. Rozpoczynamy też kolejną sesję i usiłujemy za jej pomocą zmodyfikować zablokowane przez pierwszą sesję wiersze:
update blokada set y=99;
Ta druga sesja oczywiście nie może zablokować wierszy, ponieważ zostały one zablokowane przez pierwszą sesję. W związku z tym sesja zawisa, oczekując na zdjęcie blokady:

Informację o blokadach znajdziemy w słowniku "pg_locks". Znajdują się tu zarówno sesje blokujące jakiś zasób, jak i te oczekujące na możliwość założenia blokady, a nie tylko sesje blokujące. W samym słowniku pg_locks nie zobaczymy zbyt dużo przydatnych informacji:
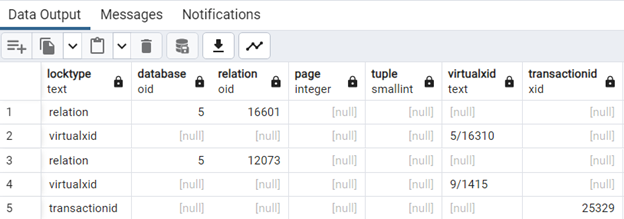
Mamy tu trochę kluczy obcych do słowników z listą obiektów, listą sesji, listą schematów. Przejrzyste informacje uzyskamy dopiero wtedy, kiedy przyozdobimy zapytanie do pg_locks o kilka joinów (należy zwrócić uwagę, że jest where na końcu ograniczający wynik do informacji o tabeli “blokada”):
select a.pid,pg_blocking_pids(a.pid),mode,nspname ,relname,application_name, usename,client_addr,backend_start,query_start,a.state,query
from pg_locks l join pg_class c on l.relation=c.oid join pg_stat_activity a on l.pid=a.pid
join pg_catalog.pg_namespace n on c.relnamespace=n.oid
where relname='blokada';
Tym razem dokładnie widać blokadę na tabeli “blokada”. W tym słowniku znajdziemy też nazwę używanej przez clienta aplikacji, a także jego adres IP (który w tym przypadku jest pusty, ponieważ łączyliśmy się z localhosta z psql):

Tym razem mamy znacznie więcej informacji. Co oznaczają poszczególne kolumny?
"pg_blocking_pids" to efekt działania tak samo nazywającej się funkcji (wprowadzonej w wersji 9.6 PostgreSQL). Znajduje się w tej kolumnie lista PIDów sesji, które blokują tę sesję. Dzięki temu można rozróżnić, czy dana sesja jest blokująca czy blokowana.
"pid"- identyfikator sesji - za jego pomocą możemy ubić blokującą sesję, stosując funkcję "pg_terminate_backend(pid)"
"mode" - rodzaj blokady
"nspname" - nazwa schematu, w którym znajduje się blokowany obiekt
"relname" - nazwa blokowanego obiektu
"application_name" - nazwa aplikacji, której używa sesja
"usename" -nazwa użytkownika
"client_addr" - adres ip sesji
"backend_start" - data i czas rozpoczęcia sesji
"query_start" - data i czas rozpoczęcia ostatniego zapytania w tej sesji
"state" - stan sesji
"query"- ostatnie zapytanie w ramach sesji - niekoniecznie to blokujące zapytanie, a dowolne ostatnie zapytanie w tej sesji

Dodając warunek where, możemy wyciągnąć tylko sesje oczekujące na zdjęcie blokady (czyli prawdopodobnie wiszące na próbie założenia blokady):
select a.pid,pg_blocking_pids(a.pid),mode,nspname ,relname,application_name, usename,client_addr,backend_start,query_start,a.state,query
from pg_locks l join pg_class c on l.relation=c.oid join pg_stat_activity a on l.pid=a.pid
join pg_catalog.pg_namespace n on c.relnamespace=n.oid
where cardinality(pg_blocking_pids(a.pid)) > 0;

W artykule na stronie http://big-elephants.com/2013-09/exploring-query-locks-in-postgres/ można znaleźć ciekawą kwerendę pokazującą, jaka sesja i jakim zapytaniem blokuje jakie zapytanie innej sesji:
SELECT
COALESCE(blockingl.relation::regclass::text,blockingl.locktype) as locked_item,
now() - blockeda.query_start AS waiting_duration, blockeda.pid AS blocked_pid,
blockeda.query as blocked_query, blockedl.mode as blocked_mode,
blockinga.pid AS blocking_pid, blockinga.query as blocking_query,
blockingl.mode as blocking_mode
FROM pg_catalog.pg_locks blockedl
JOIN pg_stat_activity blockeda ON blockedl.pid = blockeda.pid
JOIN pg_catalog.pg_locks blockingl ON(
( (blockingl.transactionid=blockedl.transactionid) OR
(blockingl.relation=blockedl.relation AND blockingl.locktype=blockedl.locktype)
) AND blockedl.pid != blockingl.pid)
JOIN pg_stat_activity blockinga ON blockingl.pid = blockinga.pid
AND blockinga.datid = blockeda.datid
WHERE NOT blockedl.granted
AND blockinga.datname = current_database();
W wyniku widzimy, jaki sql blokuje, a jaki oczekuje. Mamy też pid’y na potrzeby ubicia sesji:

Przy bardziej złożonych kaskadowych blokadach może się jeszcze przydać raport zbudowany w formie drzewa:
WITH RECURSIVE l AS (
SELECT pid, locktype, mode, granted,
ROW(locktype,database,relation,page,tuple,virtualxid,transactionid,classid,objid,objsubid) obj
FROM pg_locks
), pairs AS (
SELECT w.pid waiter, l.pid locker, l.obj, l.mode
FROM l w
JOIN l ON l.obj IS NOT DISTINCT FROM w.obj AND l.locktype=w.locktype AND NOT l.pid=w.pid AND l.granted
WHERE NOT w.granted
), tree AS (
SELECT l.locker pid, l.locker root, NULL::record obj, NULL AS mode, 0 lvl, locker::text path, array_agg(l.locker) OVER () all_pids
FROM ( SELECT DISTINCT locker FROM pairs l WHERE NOT EXISTS (SELECT 1 FROM pairs WHERE waiter=l.locker) ) l
UNION ALL
SELECT w.waiter pid, tree.root, w.obj, w.mode, tree.lvl+1, tree.path||'.'||w.waiter, all_pids || array_agg(w.waiter) OVER ()
FROM tree JOIN pairs w ON tree.pid=w.locker AND NOT w.waiter = ANY ( all_pids )
)
SELECT (clock_timestamp() - a.xact_start)::interval(3) AS ts_age,
replace(a.state, 'idle in transaction', 'idletx') state,
(clock_timestamp() - state_change)::interval(3) AS change_age,
a.datname,tree.pid,a.usename,a.client_addr,lvl,
(SELECT count(*) FROM tree p WHERE p.path ~ ('^'||tree.path) AND NOT p.path=tree.path) blocked,
repeat(' .', lvl)||' '||left(regexp_replace(query, 's+', ' ', 'g'),100) query
FROM tree
JOIN pg_stat_activity a USING (pid)
ORDER BY path;
Pokaże on nam również poziomy zagnieżdżenia w drzewie wzajemnych blokad, co nie jest bez znaczenia przy rozwiązywaniu złożonych blokad:

Nie zawsze zdążymy wychwycić blokadę w chwili, gdy ona trwa, dlatego warto też wiedzieć, w jaki sposób rejestrować takie zdarzenia do logów. Istotne tu są dwa parametry - "log_lock_waits" i "deadlock_timeout". Parametr "log_lock_waits" jest typu boolean i określa, czy mają być rejestrowane blokady, które trwają dłużej niż czas określony w "deadlock_timeout". Czas ten wynosi domyślnie sekundę. Zmieniając ten parametr, musimy pamiętać. że domyślną jednostką czasu są milisekundy, jeśli nie podamy jednostki. Aby zacząć rejestrowanie blokady, w logach musimy wykonać poniższe polecenia:
alter system set log_lock_waits=on;
select pg_reload_conf();
Jeśli chcemy, możemy również określić czas, po jakim blokada ma zostać zarejestrowana. Robimy to, zmieniając wartość parametru "deadlock_timeout". Parametr ten przy wyłączonym "log_lock_waits" określa tylko czas, po jakim PostgreSQL sprawdza, czy dana blokada to deadlock. W przypadku włączenia "log_lock_waits" określa także czas, po jakim zwykła blokada zostanie zarejestrowana. Aby go zmienić, wydajemy polecenie (domyślna jednostka to milisekundy):
alter system set deadlock_timeout=100;
select pg_reload_conf();
lub podając z jednostką:
alter system set deadlock_timeout='1s';
select pg_reload_conf();
Po włączeniu "log_lock_waits" sprawdzimy, czy system rejestruje blokady. W tym celu uruchamiamy dwie sesje. W pierwszej wykonujemy:
begin;
update blokada set y=99;
W drugiej usiłujemy zmienić te same dane, dlatego druga sesja będzie oczekiwać na zdjęcie blokady na wierszach założonej przez pierwszą sesję:
update blokada set y=100;
Po upływie sekundy w logach pojawia się całkiem sporo informacji na temat blokady. Mamy informację o tym, która sesja (numer procesu) oczekuje na zwolnienie blokady, która sesja utrzymuje tę blokadę, treść zapytania, które oczekuje na zdjęcie blokady:

Najbardziej interesuje nas prawa strona:

Widzimy pid sesji, która blokuje operację i jaką operację:

Teraz po tym pid możemy wyłapać sesję w pg_stat_activity i określić, skąd i jak się podłącza sesja blokująca lub od razu zastosować funkcję pg_terminate_backend i ubić sesję blokującą:

PostgreSQL umożliwia automatyczne zrywanie sesji po określonym czasie bezczynności w transakcji. Służy do tego wprowadzony w wersji 9.6 parametr "idle_in_transaction_session_timeout". Działa to w ten sposób, że jeśli jakaś sesja rozpocznie transakcję i pozostanie bezczynna przez czas dłuższy niż określony w tym parametrze, zostanie automatycznie zerwana. Może to być użyteczne do wycinania blokujących zasoby sesji.
Domyślnie ten parametr jest ustawiony na "0", co oznacza, że nie ma żadnego ograniczenia na czas trwania sesji. Domyślną jednostką dla tego parametru (jeśli nie podano jednostki) jest milisekunda. Parametr ten można ustawić dla całego klastra, bazy danych, użytkownika, użytkownika w bazie danych i sesji.
Sprawdźmy działanie tego parametru w akcji. Ustawiamy dla swojej sesji wartość tego parametru na 1000 milisekund i rozpoczynamy transakcję. Następnie odczekujemy czas dłuższy niż określony w "idle_in_transaction_session_timeout" i usiłujemy sprawdzić aktualny czas:
set idle_in_transaction_session_timeout=1000;
begin;
select current_timestamp;
PgAdmin4 wykrył rozłączenie sesji i pyta nas, czy nawiązać kolejne:

Pamiętajmy, że parametr “transaction_session_timeout” można też ustawić na innych poziomach, np. przez “ALTER SYSTEM” czy “ALTER DATABASE”.


Komentarze (0)
Brak komentarzy...