Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
W jaki sposób działa transakcyjność w PostgreSQL? Jak to jest możliwe, że dwie sesje widzą zupełnie różne rzeczy w sytuacji, gdy jedna z nich zmieni dane w ramach transakcji, ale nie zatwierdzi ich?
Gdy zmieniamy jakiś wiersz, PostgreSQL tworzy nową kopię wiersza, na którym jako zmieniający operujemy. Dzieje się to w ramach pliku związanego ze zmienianą tabelą (można łatwo sprawdzić położenie pliku związanego z tabelą za pomocą funkcji pg_relation_filepath). Dla zapytań odpytujących tę tabelę dostępne są stare wiersze do czasu, aż transakcja zmieniająca wiersze nie zostanie zatwierdzona. Po zakończeniu transakcji - zapytania wszystkich transakcji korzystają już z nowych wierszy. Taki sposób działania sprawia, że w plikach związanych z tabelami z czasem powstaje ogromna liczba "martwych" - wierszy, do których już nawet nie ma dostępu. To z kolei powoduje rozrost plików danych. Miejsce zajmowane przez takie "martwe" wiersze może zostać reużyte, w miejsce kolejnego zwiększania pliku. Warunkiem jest, by PostgreSQL wiedział, które wiersze są martwe i można je nadpisać. W tym celu stosuje się właśnie vacuum. Może on służyć również do zwalniania miejsca zajmowanego przez "martwe" wiersze i w konsekwencji zmniejszania wielkości plików tabel.
Polecenie to poza odzyskiwaniem miejsca zajmowanego przez "martwe" wiersze - odświeża też statystyki - ale nie jest to tematem tego rozdziału.
Polecenie "vacuum" działa dla bazy, w ramach której zostało uruchomione!
Sprawdźmy - działanie vacuum.Należy wykonać sekwencję poniższych komend (z PgAdmina, psql albo dowolnego klienta PostgreSQL), aby stworzyć przykładową tabelę i zapełnić ją danymi:
create table wielka (x integer,y varchar); do $$ begin for x in 1..1000000 loop INSERT INTO WIELKA VALUES (X,'X='||X); end loop; end; $$;
Poza komendą tworzącą tabelę mamy tu jeszcze część - kodu w języku PL/pgSQL, który zapełnia nam tę tabelę milionem wierszy.
Sprawdźmy wielkość tabeli:
select relname,pg_size_pretty(pg_total_relation_size(oid)), pg_relation_filepath(oid) from pg_class where relname='wielka';
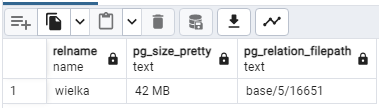
Tabela zajmuje 42MB. W tej chwili w tabeli nie ma żadnych martwych wierszy. Sprawdźmy to zwykłym vacuumem. Przełącznik “verbose” jest opcjonalny - daje nam raportowanie wyników:
vacuum verbose wielka;
Vacuum mówi, że nie ma żadnych martwych wierszy, co wynika z tego, że nie wykonaliśmy jeszcze żadnego update czy delete na tej tabeli:
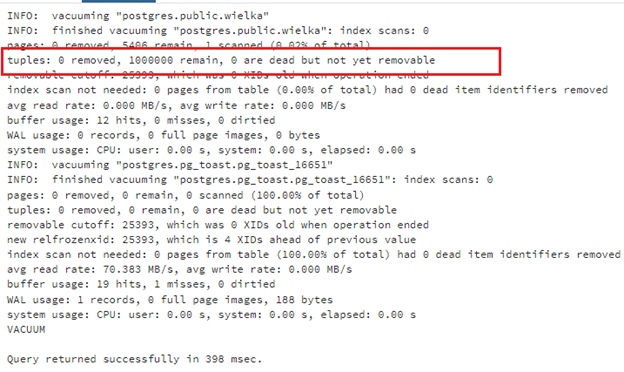
Wykrył milion nieusuwalnych wierszy. Zmieńmy więc dane tak, - by martwe wiersze powstały i sprawdźmy wielkość tabeli:
update wielka set y='coś takiego'; select relname,pg_size_pretty(pg_total_relation_size(oid)), pg_relation_filepath(oid) from pg_class where relname='wielka';
Po update wielkość tabeli wzrosła za sprawą martwych wierszy z 42 do 92MB:
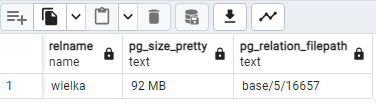
Możemy teraz zrobić zwykły vacuum:
vacuum verbose wielka;
Vacuum wykrył milion martwych wierszy:
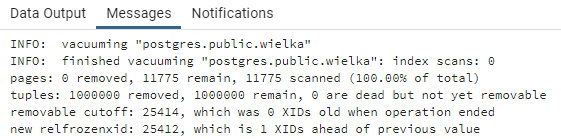
Zwykły vacuum nie zmniejsza jednak wielkości tabeli:
select relname,pg_size_pretty(pg_total_relation_size(oid)), pg_relation_filepath(oid) from pg_class where relname='wielka';
Wielkość tabeli cały czas wynosi 92MB:
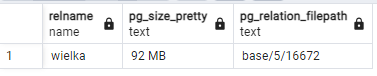
Sama operacja "vacuum" bez przełącznika "FULL" nie powoduje usunięcia - martwych wierszy. Proces vacuum skanuje tabele i indeksy w poszukiwaniu wpisów, które już nie są widoczne. Informacja o nowo zwolnionym miejscu jest zapisywana w mapie wolnego miejsca FSM. Jeśli nastąpi jakaś operacja wymagająca wolnego miejsca - na przykład aktualizacja danych- PostgreSQL w pierwszej kolejności będzie wykorzystywał miejsce oznaczone w FSM jako wolne, a więc przestrzeń odzyskaną. Zwykły proces vacuum sam w sobie nie powoduje zmniejszenia plików danych! Używanie vacuum pozwala zaoszczędzić miejsce w tym sensie, że nie jest alokowana dodatkowa przestrzeń, gdy istnieją dane, które można by nadpisać.
Istnieje też możliwość wykonania vacuum dla całej bazy danych:
vacuum verbose;
Jeśli chcielibyśmy zmniejszyć wielkość plików danych, musielibyśmy użyć polecenia VACUUM FULL. Działa ono w ten sposób, że poza czynnościami wykonywanymi przez zwykły vacuum przepisuje on cały plik tabeli, pomijając martwe wiersze. Tym sposobem wielkość pliku danych tabeli ulega zmniejszeniu.
VACUUM FULL oczywiście nie jest rozwiązaniem idealnym i ma swoje wady. Przede wszystkim jest bardzo obciążające dla serwera i powoduje przy dużych tabelach ogromne liczby I/O. Ponadto VACUUM FULL w związku z przepisywaniem pliku zakłada blokadę na wyłączność (ekskluzywną). Z tych powodów operację tę powinniśmy przeprowadzać, kiedy baza nie jest zbyt obciążona i kiedy jest najmniejsze ryzyko zablokowania blokowanego przez VACUUM FULL zasobu.
Wykorzystamy teraz stworzoną i zaktualizowaną - tabelę "wielka" do zaprezentowania działania VACUUM FULL. W wyniku wykonanego na niej "update" mamy - 1000000 martwych wierszy, o czym zostaliśmy poinformowani przy wywoływaniu zwykłego vacuum na tej tabeli. Aktualna wielkość tabeli cały czas wynosi 92MB:
select relname,pg_size_pretty(pg_total_relation_size(oid)), pg_relation_filepath(oid) from pg_class where relname='wielka';
Wielkość tabeli cały czas wynosi 92MB. Zwróćmy uwagę na nazwę pliku pokazaną w ostatniej kolumnie. Tabela mieści się w pliku o nazwie 16672:
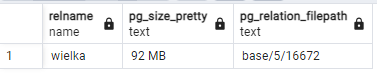
Wykonamy teraz na niej VACUUM FULL:
vacuum full verbose wielka;
Ponowimy zapytanie i porównamy wielkość i położenie pliku:
select relname,pg_size_pretty(pg_total_relation_size(oid)), pg_relation_filepath(oid) from pg_class where relname='wielka';

Widzimy, że po tej operacji wielkość pliku uległa zmniejszeniu z 92 do 50MB, ale też zmianie uległa ścieżka do pliku - to konsekwencja wiążącego się z VACUUM FULL przepisania pliku danych.
Przy okazji ciekawa kwerenda pokazująca największe tabele w bazie danych (znaleziona na https://wiki.postgresql.org/wiki/Disk_Usage):
SELECT nspname || '.' || relname AS "relation",
pg_size_pretty(pg_relation_size(C.oid)) AS "size"
- FROM pg_class C
- LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
- WHERE nspname NOT IN ('pg_catalog', 'information_schema')
- ORDER BY pg_relation_size(C.oid) DESC
- LIMIT 20;
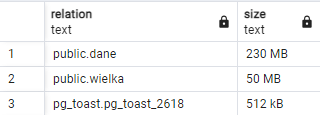
W ten sposób możemy zlokalizować - potencjalnych kandydatów do VACUUM FULL. Można też wykonać VACUUM FULL dla całej bazy:
vacuum full verbose;
Od wersji 8.1 PostgreSQL wprowadzono nowy mechanizm - demona autovacuum. - Mechanizm ten wykonuje te same czynności co vacuum, z tą różnicą, - że nie musimy go wywoływać ręcznie. Autovacuum działa dla wszystkich baz danych. Domyślnie jest on włączony. Możemy się o tym przekonać, wywołując komendę:
show autovacuum;
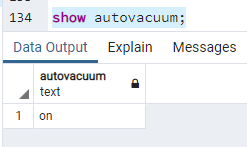
Jest to automatyczny odpowiednik VACUUM, a nie VACUUM FULL. Autovacuum nie usuwa martwych wierszy, a jedynie tworzy mapę ich położenia. Autovacuum uruchamia się sam co czas określony w autovacuum_naptime domyślnie ustawionym na minutę:
show autovacuum_naptime;
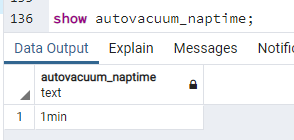
Autovacuum poszukuje tabel, dla których została zmieniona, dodana lub skasowana znacząca liczba wierszy i przeszukuje je w poszukiwaniu martwych wierszy, - które następnie rejestruje w plikach FSM. Operacja wykonywana jest z użyciem takiej liczby procesów, jaka jest ustawiona przez parametr autovacuum_max_workers. Ponieważ autovacuum jest procesem obejmującym wszystkie bazy danych, właściwe ustawienie tego parametru jest dosyć istotne. Na przykład, jeśli będziemy - mieć trzy bazy danych, to na każdą będzie przypadał jeden proces "autovacuum" i analiza wykona się równolegle dla każdej z baz danych. Jeśli będziemy mieli cztery bazy, to ta czwarta będzie musiała poczekać na zwolnienie się któregoś z "workerów":
show autovacuum_max_workers;
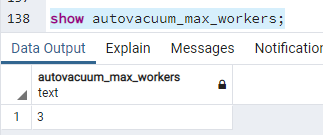
Ktoś dociekliwy mógłby zapytać, ile to jest „znacząca liczba wierszy” ? Liczba ta jest określana na podstawie wartości parametrów "autovacuum_vacuum_scale_factor" i "autovacuum_vacuum_threshold". Wzór wygląda tak:
liczba wierszy, których zmiana spowoduje uruchomienie autovacuum = liczba wierszy w tabeli * autovacuum_vacuum_scale_factor+autovacuum_vacuum_threshold
Czyli jeśli ustawimy "autovacuum_vacuum_scale_factor" na 0.5, a "autovacuum_vacuum_threshold" na 10, to autovacuum uruchomi się po zmianie/skasowaniu/dodaniu liczby wierszy stanowiącej połowę tabeli + 10.
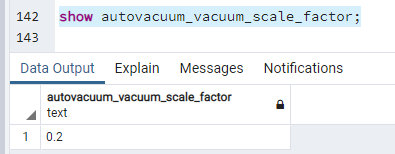
Domyślną wartością dla - "autovacuum_vacuum_scale_factor" jest 0.2:
show - autovacuum_vacuum_scale_factor;
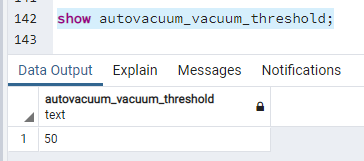
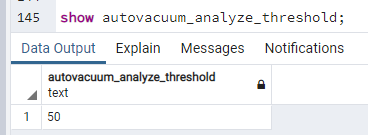
Domyślną wartością dla "autovacuum_vacuum_threshold" jest 50.
show autovacuum_vacuum_threshold;
Warto wiedzieć, że autovacuum odświeża też statystyki tabel na potrzeby lepszego wybierania planów wykonania. Robi to dla tych tabel, dla których liczba zmienionych/dodanych/skasowanych wierszy przekroczy wartość wynikającą ze wzoru:
liczba wierszy, których zmiana spowoduje uruchomienie odświeżania statystyk = liczba wierszy w tabeli * autovacuum_analyze_scale_factor+autovacuum_analyze_threshold
Czyli jeśli ustawimy "autovacuum_analyze_scale_factor" na 0.2, a "autovacuum_vacuum_threshold" na 10, to autovacuum odświeży statystyki dla tej tabeli po - zmianie/skasowaniu/dodaniu liczby - wierszy stanowiącej 20% tabeli + 10.
Domyślną wartością dla - "autovacuum_analyze_scale_factor" jest 0.1:
show autovacuum_analyze_scale_factor;
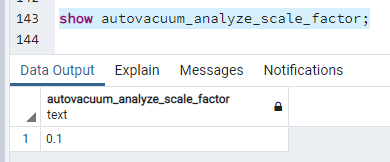
Domyślną wartością dla "autovacuum_analyze_threshold" jest 50:
show autovacuum_analyze_threshold;
Może zaistnieć taka potrzeba, że zechcemy mieć indywidualne ustawienia parametrów procesu autovacuum dla tabeli. Możliwość taka istnieje dla parametrów "autovacuum_vacuum_scale_factor","autovacuum_vacuum_threshold","autovacuum_analyze_scale_factor" i "autovacuum_analyze_threshold". Aby ustawić te parametry indywidualnie dla wybranego obiektu, - wywołujemy:
alter table wielka set (autovacuum_vacuum_scale_factor=0.1, autovacuum_vacuum_threshold=0);
Możemy sprawdzić nadane w ten sposób indywidualne ustawienia za pomocą słownika "pg_class", a konkretniej jego kolumny "reloptions":
select relname,reloptions from pg_class where relname='wielka';

Możemy też wyszukać tabele, dla których jakiś konkretny parametr jest ustawiony. Kolumna "reloptions" jest typu array, więc przed porównaniem z poszukiwanym ciągiem trzeba będzie jeszcze rzutować jej zawartość na - typ "text":
select relname,reloptions from pg_class where reloptions::text like '%autovacuum%';
Możemy również wyłączyć autovacuum dla wybranej tabeli:
alter table wielka set (autovacuum_enabled=false);
Jeśli chcemy sprawdzić, kiedy dla wybranych tabel była ostatnio wykonana operacja vacuum lub autovacuum, możemy odwołać się do słownika "pg_stat_all_tables":
select relname,last_vacuum,last_autovacuum, last_autoanalyze,last_analyze from pg_stat_all_tables where relname='wielka';

Została wyświetlona tu tylko tabela “wielka”. Jeśli chcemy zobaczyć wszystkie tabele, należy - usunąć warunek "where". W tym samym słowniku jest też kilka innych ciekawych informacji, - które pozwolą nam na najlepsze dobranie parametrów dla AUTOVACUUM. Dokonamy jeszcze jednego "update", zanim do niego zajrzymy:
update wielka set x=x+100; SELECT relname,n_tup_ins,n_tup_upd,n_tup_del, n_live_tup, n_dead_tup,n_mod_since_analyze FROM pg_stat_user_tables where relname='wielka';

Co oznaczają poszczególne kolumny?
"relname"- nazwa tabeli
"n_tup_ins"- informacja, ile wierszy wstawiono do danej tabeli od początku jej istnienia
"n_tup_upd"- liczba wierszy, która została w tej tabeli zaktualizowana od początku jej istnienia
"n_tup_del"- liczba wierszy skasowanych z tabeli od początku jej istnienia
"n_live_tup"- liczba - "żywych" wierszy, czyli takich, które nie są martwymi wierszami pozostałymi po transakcjach ( w skrócie - ile jest wierszy w tabeli)
"n_dead_tup" informacja, ile mamy martwych, pozostałych po transakcjach wierszy - niezarejestrowanych jeszcze w FSM od ostatniego (ręcznego lub automatycznego) VACUUM. Po wykonaniu vacuum wartości w tej kolumnie się zerują.
"n_mod_since_analyze"- informacja o liczbie wierszy zmodyfikowanych/dodanych/skasowanych od ostatniego VACUUM - automatycznego bądź wywołanego ręcznie
Po "update" należy odczekać ponad minutę (żeby autovacuum zdążył zadziałać) i ponownie wykonać to samo zapytanie do słownika "pg_stat_user_tables":
SELECT relname,n_tup_ins,n_tup_upd,n_tup_del, n_live_tup, n_dead_tup,n_mod_since_analyze FROM pg_stat_user_tables where relname='wielka';

Po zadziałaniu "autovacuum" zmieniła się wartość kolumn "n_dead_tup" i "n_mod_since_analyze". Stało się tak za sprawą działania autovacuum, który uruchamia się domyślnie co minutę. - Fakt rejestrowania liczby zmienionych, skasowanych, dodanych, martwych i żywych wierszy wynika z ustawienia parametru "track_counts", który domyślnie jest włączony.
Przede wszystkim należy wziąć pod uwagę, że vacuum jest operacją generującą stosunkowo dużo operacji I/O. Vacuum każdorazowo musi przeanalizować pliki danych związane z tabelą i odnaleźć martwe wiersze. W przypadku vacuum full dochodzi jeszcze proces przepisywania do nowego pliku. Trzeba brać poprawkę na to, że choć proces ten jest - niezbędny do optymalnego wykorzystania przestrzeni dyskowej, to jednak generuje pewien narzut obciążenia. Dotyczy to zarówno vacuum uruchamianego ręcznie jak i autovacuum.
Z drugiej strony sprawdźmy, czy fakt, że - tabelę czyścimy z martwych wierszy, ma wpływ na szybkość odczytu danych z tej tabeli, Sprawdźmy to empirycznie. Usuńmy tabelę “wielka” i stwórzmy ją jeszcze raz ze znacznie większą liczbą wierszy. Chodzi o to, by zmniejszyć wpływ wielkości "shared_buffers" na czas odczytu. W naszym przypadku "shared_buffers" pozostaje ustawione na wartość domyślną i wynosi 128MB. Możemy to łatwo sprawdzić:
show shared_buffers;
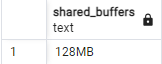
Jeśli powtarzamy ten proces, zadbajmy o odpowiednio niskie ustawienie tego parametru (ale nie należy tego robić na produkcji). Nasza tabela powinna być znacznie większa niż dostępne "shared_buffers" na potrzeby tego doświadczenia. Po stworzeniu tabeli wykonamy też "checkpoint", żeby utrwalić wszystkie nowe dane w plikach.
drop table wielka; create table wielka(x integer,y text); do $$ begin for x in 1..20000000 loop insert into wielka values (x,'element numer '||x); end loop; end $$; checkpoint;
W tabeli mamy 20 milionów wierszy. Sprawdźmy, ile miejsca zajmuje tabela "wielka":
select relname,pg_size_pretty(pg_total_relation_size(oid)), pg_relation_filepath(oid) from pg_class where relname='wielka';

W naszym przypadku jest to prawie dziesięciokrotność dostępnego "shared_buffer", czyli nie ma szans, by tabela zmieściła się w cache w całości i jej większość będzie musiała zostać odczytana z dysku - o to nam właśnie chodzi. Sprawdźmy, ile czasu zajmuje odczyt tej tabeli w całości:
explain analyze select * from wielka;

Badanie to powtórzone kilkakrotnie za każdym razem dawało zbliżony czas ok. 2 sekund. Dokonamy teraz aktualizacji danych w tej tabeli, tak by dzięki temu powstało sporo martwych wierszy. Zanim to jednak zrobimy, najpierw należy włączyć "autovacuum" dla tej tabeli, żeby ten proces nie zaburzył nam wyników badania:
alter table wielka set (autovacuum_enabled=false);
Upewnijmy się, że parametr ten jest ustawiony:
select relname,reloptions from pg_class where relname='wielka';
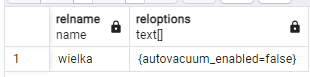
Sprawdzamy jeszcze, - o której został wykonany "autovacuum". Będzie nam to potrzebne, żeby później zauważyć, czy w trakcie badania nie został wykonany "autovacuum":
select relname, last_vacuum,last_autovacuum from pg_stat_all_tables where relname='wielka';
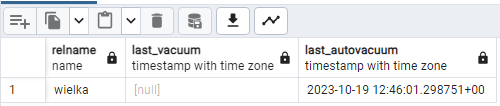
Dokonamy teraz aktualizacji danych. Dzięki temu powstaną martwe wiersze w plikach tabeli. Aby zmiany były utrwalone na dysku, należy wykonać jeszcze checkpoint:
update wielka set x=x+100; checkpoint;
Porównamy teraz czas odczytu całej tabeli po powstaniu martwych wierszy. Za pierwszym razem trwało to około 64 sekund (kwestia cache), jednak po kilkakrotnym - powtórzeniu analizy - i poza pierwszym razem czas utrzymywał się na poziomie 2.5-3 sekund:
explain analyze select * from wielka;

Sprawdzamy teraz,, czy zwykły "vacuum" wpłynie na czas odczytu:
vacuum wielka; explain analyze select * from wielka;

Tu również powtarzamy operację kilkakrotnie. Za każdym razem otrzymujemy ok 2.5-3 sekund, czyli nic się nie zmieniło. Zwykły "vacuum" nie wpływa najwyraźniej na szybkość odczytu danych z tabeli. Sprawdźmy zatem, - czy "vacuum full" coś zmieni. "Vacuum full" powoduje przepisanie plików danych z pominięciem martwych wierszy, które później nie muszą być odczytywane przy skanie sekwencyjnym po tabeli:
vacuum full wielka; explain analyze select * from wielka;

Tym razem też powtarzamy operację wielokrotnie i czas utrzymuje się na poziomie 2-2.2 sekundy. Wniosek z tego płynie taki, że zwykły "vacuum" (a więc i "autovacuum") nie powoduje skrócenia czasu odczytu na tabeli. Operacja "vacuum full" wpływa korzystnie na wydajność odczytu z tabeli, ponieważ eliminuje konieczność czytania martwych wierszy, które są w trakcie tej operacji usuwane.



Komentarze (0)
Brak komentarzy...