Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
Przez lata świat dużych zbiorów danych dzielił się prosto: albo hurtownia danych (uporządkowana, droga, świetna do raportów), albo „jezioro danych" (data lake — tanie składowisko plików, ale bez ładu). W 2026 roku ta granica się zatarła. Powstał spójny zestaw narzędzi, w którym tanie składowanie obiektowe, rozproszone przetwarzanie, transakcyjne tabele i jeden wspólny język SQL grają w jednej drużynie.
W tym artykule przechodzimy przez ten stos warstwa po warstwie i pokazujemy każdy element na żywo: zrzuty pochodzą z prawdziwego klastra Apache Spark, prawdziwego magazynu obiektowego MinIO, działającego brokera Apache Kafka i silnika zapytań Trino, które postawiliśmy na potrzeby tego tekstu. Bez slajdów poglądowych tam, gdzie da się pokazać realne wyjście.
Zacznijmy od lotu ptaka. Dane wpływają ze źródeł operacyjnych (aplikacje, urządzenia, logi, bazy transakcyjne), trafiają do taniego składowania obiektowego, są przetwarzane wsadowo (czyli porcjami, ang. batch) i strumieniowo (na bieżąco), zapisywane w transakcyjnym formacie tabel, a na końcu udostępniane przez wspólny SQL do raportów i modeli uczenia maszynowego.
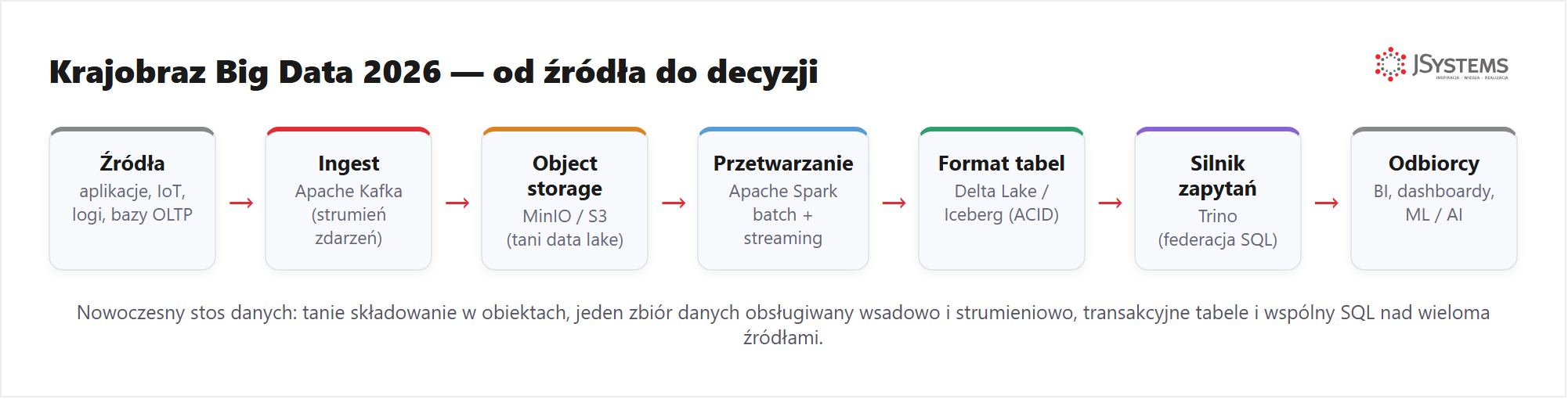
Kluczowa zmiana ostatnich lat: te warstwy przestały być osobnymi światami. Ten sam zbiór danych obsługujemy wsadowo i strumieniowo, trzymamy go tanio w obiektach, a mimo to mamy nad nim transakcje i jeden język zapytań. Zobaczmy każdą warstwę z osobna.
Podstawą jest składowanie obiektowe (object storage) — sposób przechowywania danych jako „obiektów" w pojemnikach zwanych kubełkami (ang. bucket), dostępny przez proste API zgodne z Amazon S3. Jest tanie, praktycznie nieograniczone i oddziela miejsce przechowywania danych od mocy obliczeniowej. W chmurze to Amazon S3, Google Cloud Storage czy Azure Blob; lokalnie i prywatnie — MinIO, które jest zgodne z tym samym API S3.
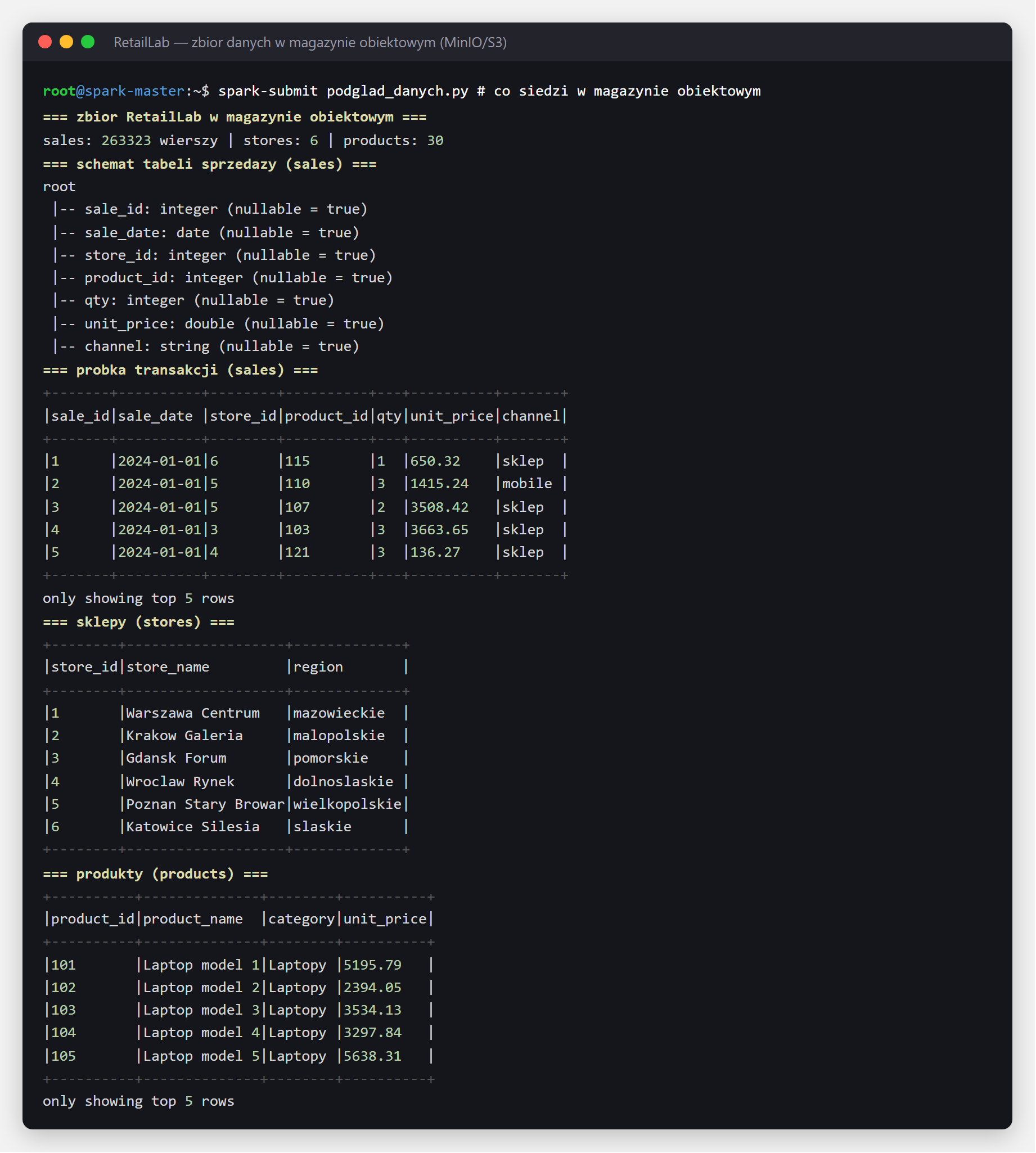
Co konkretnie tu leży? Na potrzeby artykułu posłużył nam zbiór RetailLab — dane fikcyjnej sieci handlowej, które będziemy przetwarzać w dalszych sekcjach. To ponad ćwierć miliona transakcji sprzedaży (z datą, sklepem, produktem, ilością, ceną i kanałem), słownik 6 sklepów w polskich regionach oraz katalog 30 produktów z kategoriami. Tak wygląda ten zbiór wczytany przez Spark wprost z magazynu obiektowego:
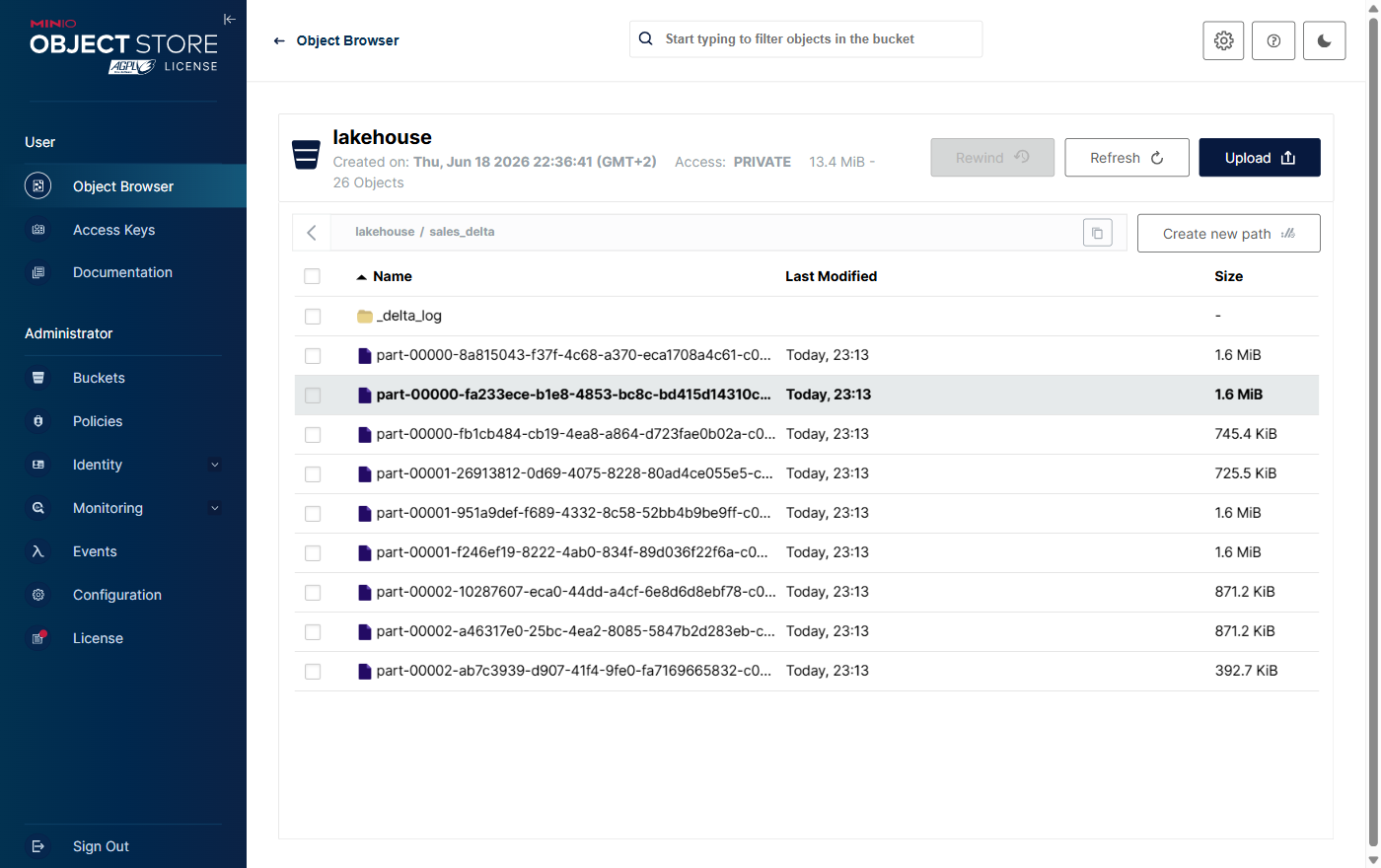
Na potrzeby artykułu Spark zapisał tu komplet danych w formacie kolumnowym Parquet (skompresowany,
zoptymalizowany pod analitykę). Poniżej konsola MinIO z plikami tabeli oraz katalogiem dziennika
transakcji _delta_log — czyli cały lakehouse leży wprost na zwykłym magazynie obiektowym:
Apache Spark to silnik rozproszonego przetwarzania danych — dzieli pracę na wiele maszyn (węzłów) i liczy je równolegle. W trybie klastra mamy węzeł zarządzający (master) i węzły robocze (workery), które wykonują zadania na swoich rdzeniach. Postawiliśmy mały klaster: jeden master i dwa workery, razem cztery rdzenie. Tak wygląda jego panel w trakcie pracy zadania:
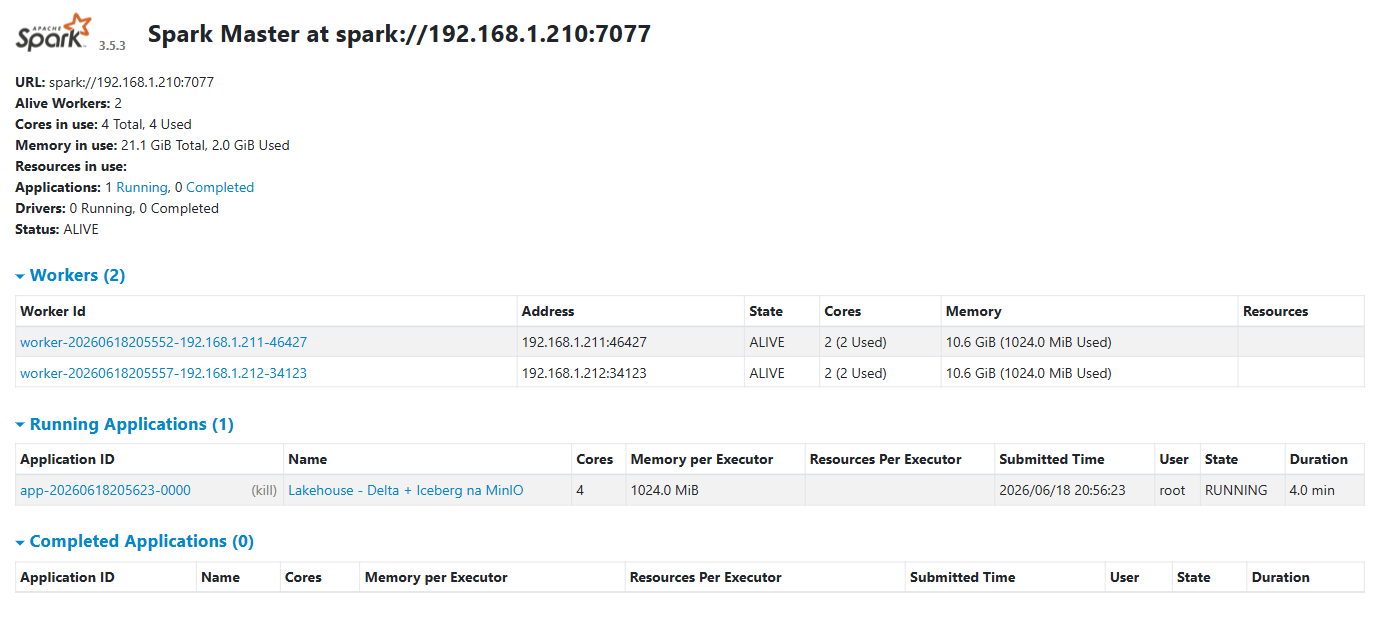
Na tym klastrze policzyliśmy rozproszoną agregację na zbiorze ponad ćwierć miliona transakcji: liczbę
wierszy oraz przychód i średni koszyk w podziale na regiony. Cały skrypt analiza.py jest krótki —
łączy się z klastrem, wczytuje sprzedaż i sklepy, liczy transakcje rozproszonym count()
i agreguje wynik w podziale na regiony:
from pyspark.sql import SparkSession, functions as F
# połączenie z klastrem standalone (master + 2 workery)
spark = (SparkSession.builder
.appName("RetailLab - rozproszona analiza sprzedaży")
.master("spark://192.168.1.210:7077")
.config("spark.cores.max", "4")
.getOrCreate())
# wczytanie danych wprost z magazynu obiektowego
sales = spark.read.option("header", True).option("inferSchema", True).csv("/opt/data/sales.csv")
stores = spark.read.option("header", True).option("inferSchema", True).csv("/opt/data/stores.csv")
# rozproszony count - Spark liczy go na wszystkich workerach naraz
print("sales.count() =", sales.count())
# przychod, liczba transakcji i sredni koszyk w podziale na regiony
enr = sales.withColumn("amount", F.round(F.col("qty") * F.col("unit_price"), 2))
raport = (enr.join(stores, "store_id")
.groupBy("region")
.agg(F.round(F.sum("amount"), 2).alias("przychod"),
F.count("*").alias("transakcje"),
F.round(F.avg("amount"), 2).alias("sr_koszyk"))
.orderBy(F.desc("przychod")))
raport.show(truncate=False)Uruchamiamy go na klastrze poleceniem spark-submit, a Spark sam rozsyła obliczenia
na workery i zbiera wynik:
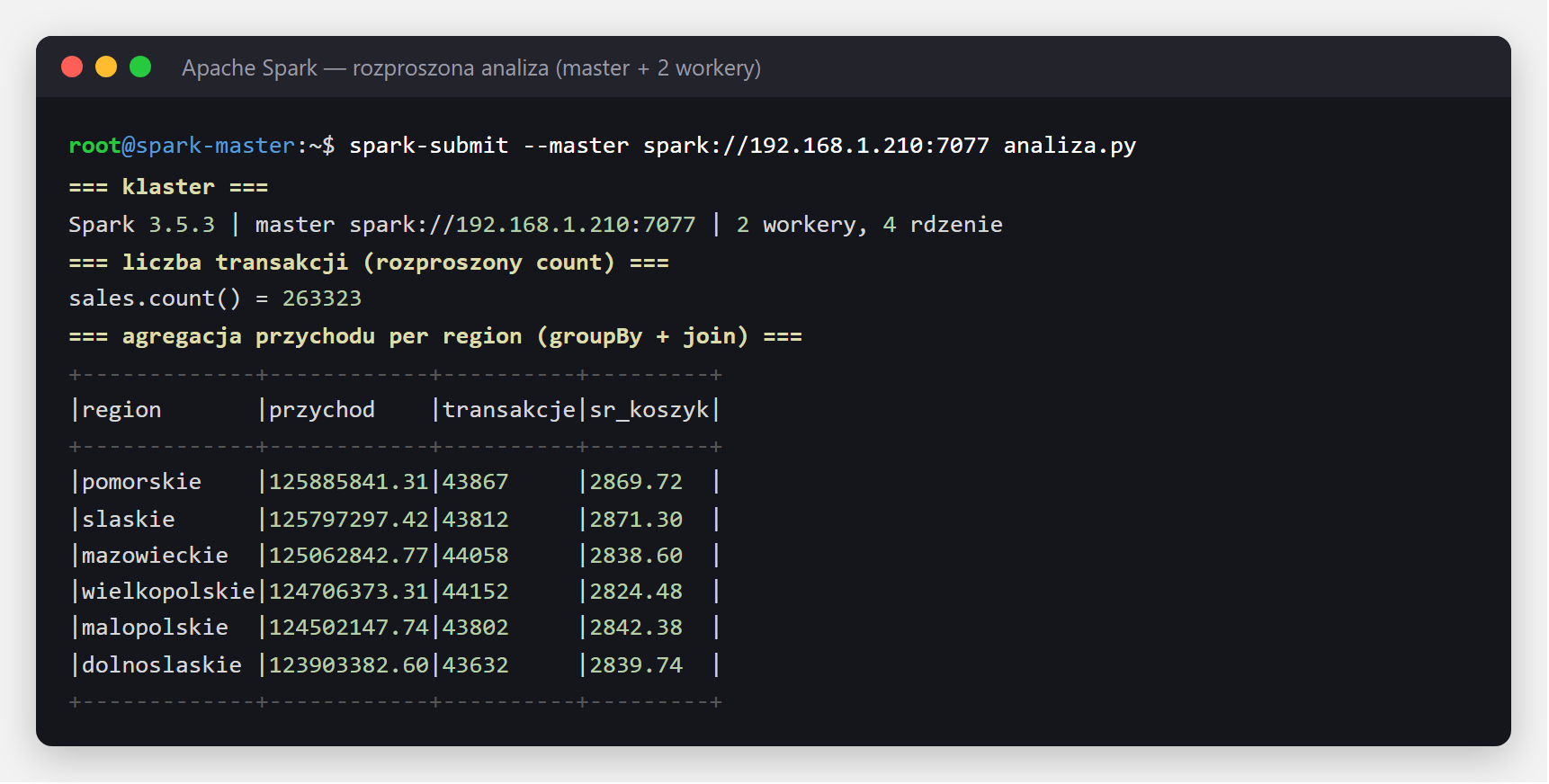
count() na 263 323 transakcjach i agregacja przychodu per region.Samo wrzucenie plików do magazynu obiektowego daje jezioro danych — tanie, ale bez gwarancji spójności: brak transakcji, łatwo o bałagan (tzw. „data swamp", czyli bagno danych). Hurtownia daje porządek i szybki SQL, ale jest droga i słabo radzi sobie z plikami oraz uczeniem maszynowym. Lakehouse łączy zalety obu: transakcyjne tabele wprost na tanim składowaniu obiektowym.

Magię lakehouse robią otwarte formaty tabel: Delta Lake i Apache Iceberg. To one dokładają do zwykłych plików Parquet dziennik transakcji, dzięki któremu dostajemy ACID (gwarancję, że operacja zapisu albo wykona się w całości, albo wcale — bez połowicznych, uszkodzonych stanów), wersjonowanie i ewolucję schematu.
Na tej samej tabeli wykonaliśmy zapis, a potem operacje UPDATE i DELETE — coś,
czego na surowych plikach w jeziorze zrobić się nie da bezpiecznie. Delta zapisała każdą zmianę jako kolejną
wersję, a dzięki temu możliwa jest „podróż w czasie" (time travel) — odczyt tabeli w stanie sprzed zmian
przez VERSION AS OF. Cały zapis i operacje to zwykły SQL na tabeli leżącej na MinIO:
# zapis tabeli sprzedaży w formacie Delta wprost na MinIO (S3)
sales.write.format("delta").mode("overwrite").save("s3a://lakehouse/sales_delta")
spark.sql("CREATE TABLE IF NOT EXISTS sales_delta "
"USING delta LOCATION 's3a://lakehouse/sales_delta'")
# operacje ACID na plikach w jeziorze - na surowym Parquecie niemozliwe
spark.sql("UPDATE sales_delta SET amount = ROUND(amount*1.10, 2) WHERE product_id = 101")
spark.sql("DELETE FROM sales_delta WHERE qty = 1")
# historia: kazda zmiana to osobna wersja tabeli
spark.sql("DESCRIBE HISTORY sales_delta").show()
# podroz w czasie - odczyt stanu sprzed zmian (wersja 0)
spark.sql("SELECT COUNT(*) FROM sales_delta VERSION AS OF 0").show()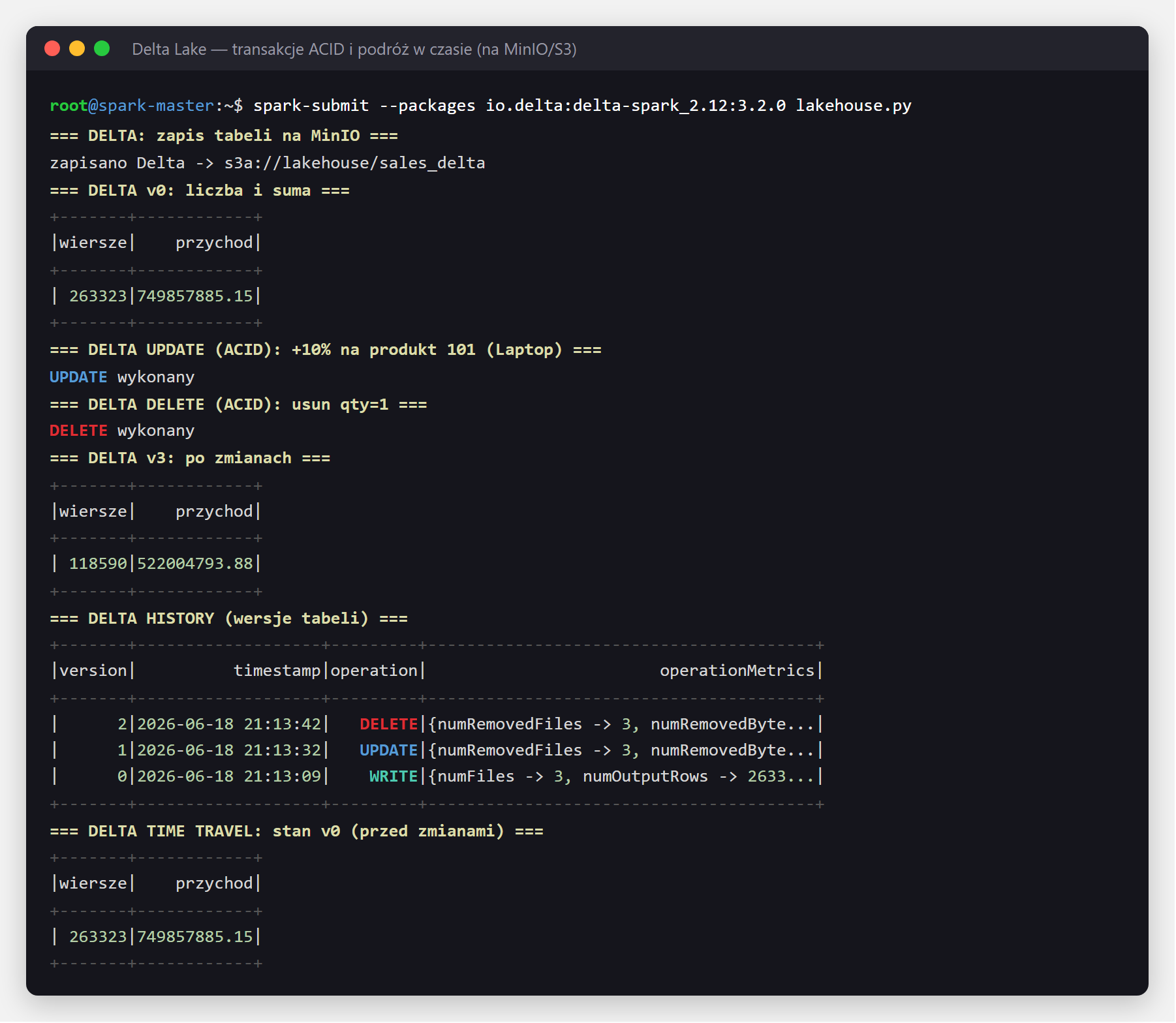
Zwróć uwagę: po DELETE tabela ma 118 590 wierszy, ale odczyt VERSION AS OF 0
nadal pokazuje pełne 263 323 — historia jest zachowana i audytowalna.
Apache Iceberg rozwiązuje ten sam problem nieco inaczej: każda zmiana tworzy migawkę (snapshot) — spójny obraz tabeli w danym momencie. Tu zapisaliśmy tabelę, dopisaliśmy partię danych (append) i odczytaliśmy listę migawek wprost z metadanych tabeli:
# utworzenie tabeli Iceberg i zapis (katalog 'ice' wskazuje na s3a://lakehouse/iceberg)
sales.writeTo("ice.db.sales_ice").using("iceberg").createOrReplace()
# dopisanie kolejnej partii danych = nowa migawka (snapshot)
sales.where("qty >= 3").writeTo("ice.db.sales_ice").append()
# lista migawek wprost z metadanych tabeli
spark.sql("SELECT committed_at, snapshot_id, operation, "
"summary['added-records'] AS added "
"FROM ice.db.sales_ice.snapshots").show()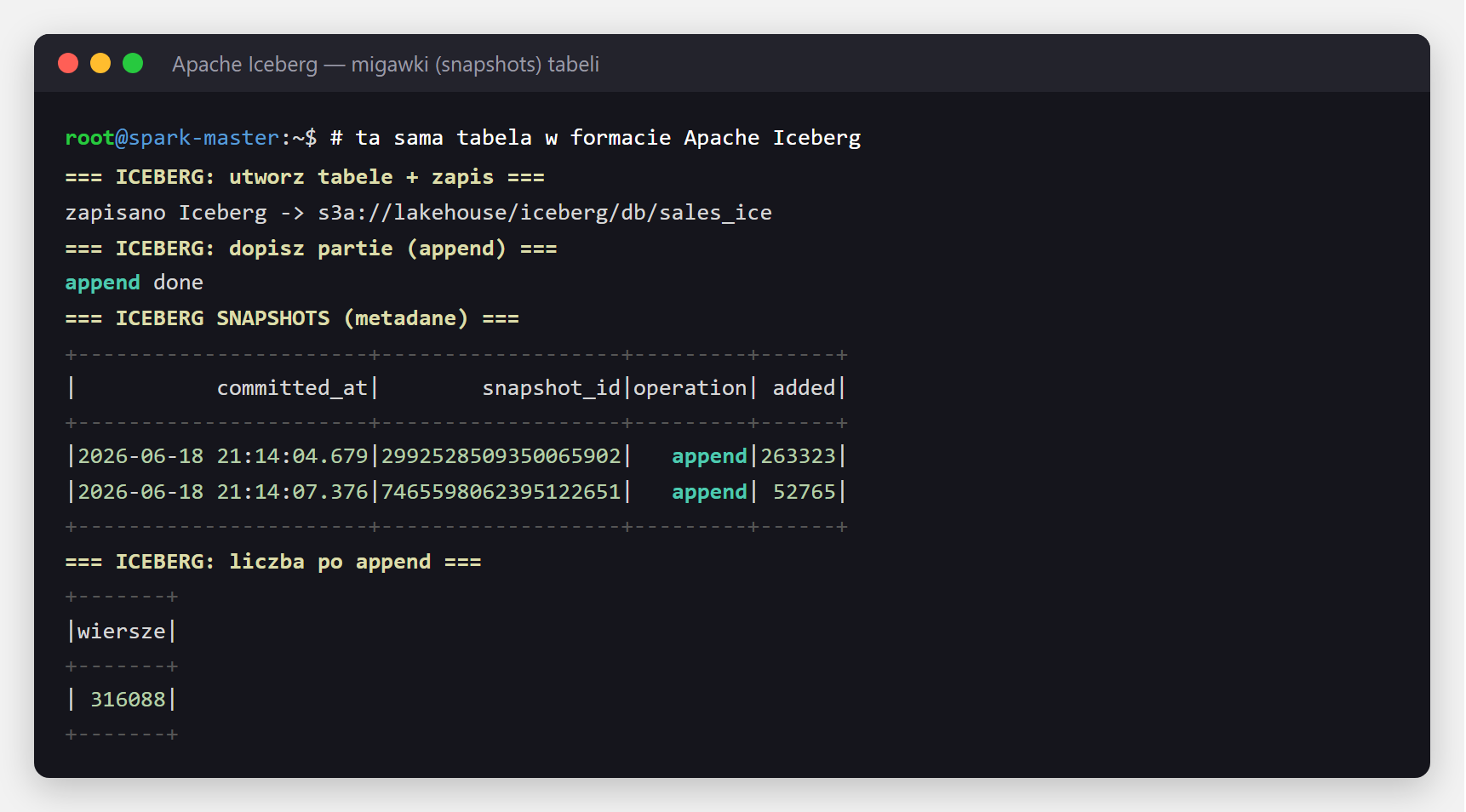
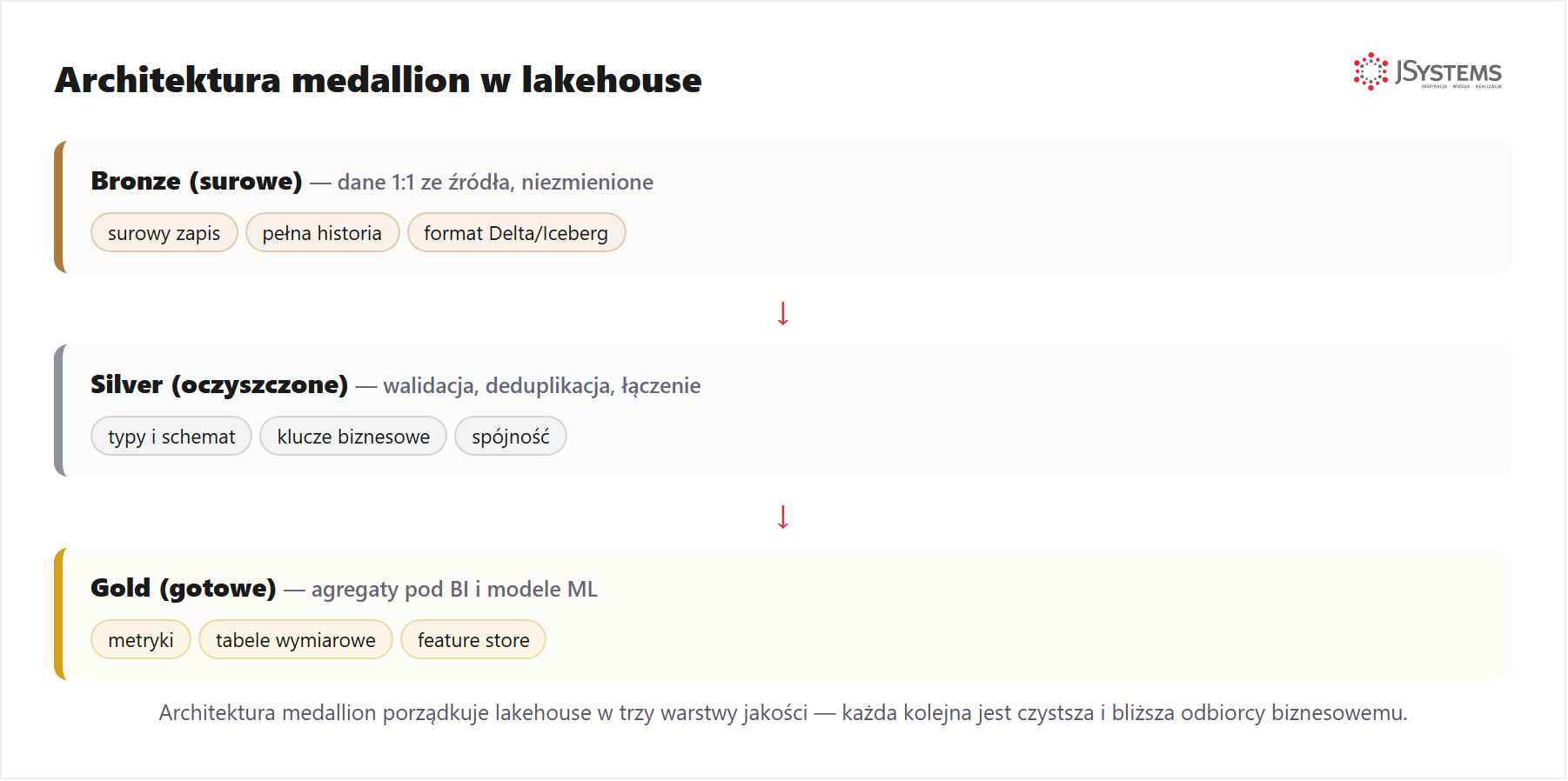
Żeby lakehouse nie zamienił się w bałagan, dane porządkuje się w trzy warstwy jakości — to tzw. architektura medallion. Surowe dane (bronze) lądują 1:1 ze źródła, warstwa silver je czyści i łączy, a warstwa gold zawiera gotowe agregaty i tabele pod raporty oraz modele:
Nie wszystko da się liczyć raz na dobę. Gdy dane mają wartość „teraz" (zamówienia, zdarzenia z aplikacji, telemetria), potrzebujemy przetwarzania strumieniowego — reagowania na zdarzenia w miarę, jak napływają. Sercem takich rozwiązań jest Apache Kafka — rozproszony dziennik zdarzeń, do którego producenci dopisują komunikaty, a konsumenci je odczytują.
Spark potrafi czytać Kafkę przez Structured Streaming — ten sam interfejs co do danych
wsadowych, tyle że źródłem jest nieskończony strumień. Najpierw producent wysyła do tematu
(topic) transakcje 300 zdarzeń sprzedażowych — każde to mały JSON z regionem, produktem,
ilością i kwotą:
# producent: 300 zdarzeń sprzedażowych JSON -> temat "transakcje"
import json, random
from kafka import KafkaProducer # pip install kafka-python
producer = KafkaProducer(bootstrap_servers="192.168.1.213:9092",
value_serializer=lambda v: json.dumps(v).encode())
regiony = ["Mazowieckie", "Slaskie", "Malopolskie", "Pomorskie", "Dolnoslaskie"]
produkty = ["Laptop", "Monitor", "Klawiatura", "Dysk SSD", "Router"]
for _ in range(300):
ilosc = random.randint(1, 5)
cena = random.choice([199, 299, 499, 899, 2999])
producer.send("transakcje", {"region": random.choice(regiony),
"produkt": random.choice(produkty),
"ilosc": ilosc,
"kwota": round(ilosc * cena, 2)})
producer.flush()Po stronie Sparka czytamy ten strumień jako źródło kafka, parsujemy JSON wg schematu
i agregujemy zdarzenia na bieżąco w podziale na regiony — tym samym kodem, którym liczylibyśmy dane wsadowe:
from pyspark.sql import SparkSession, functions as F
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType
spark = SparkSession.builder.appName("Streaming - Kafka + Spark").getOrCreate()
schema = StructType([StructField("region", StringType()),
StructField("produkt", StringType()),
StructField("ilosc", IntegerType()),
StructField("kwota", DoubleType())])
# źródło: nieskończony strumień rekordów z tematu Kafka
raw = (spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "192.168.1.213:9092")
.option("subscribe", "transakcje")
.option("startingOffsets", "earliest").load())
# wartość rekordu Kafka to JSON - parsujemy go wg schematu
parsed = raw.select(F.from_json(F.col("value").cast("string"), schema).alias("d")).select("d.*")
# agregacja strumienia: liczba transakcji i przychód per region
agg = parsed.groupBy("region").agg(F.count("*").alias("transakcje"),
F.round(F.sum("kwota"), 2).alias("przychod"))
query = agg.writeStream.outputMode("complete").format("console").start()
query.awaitTermination()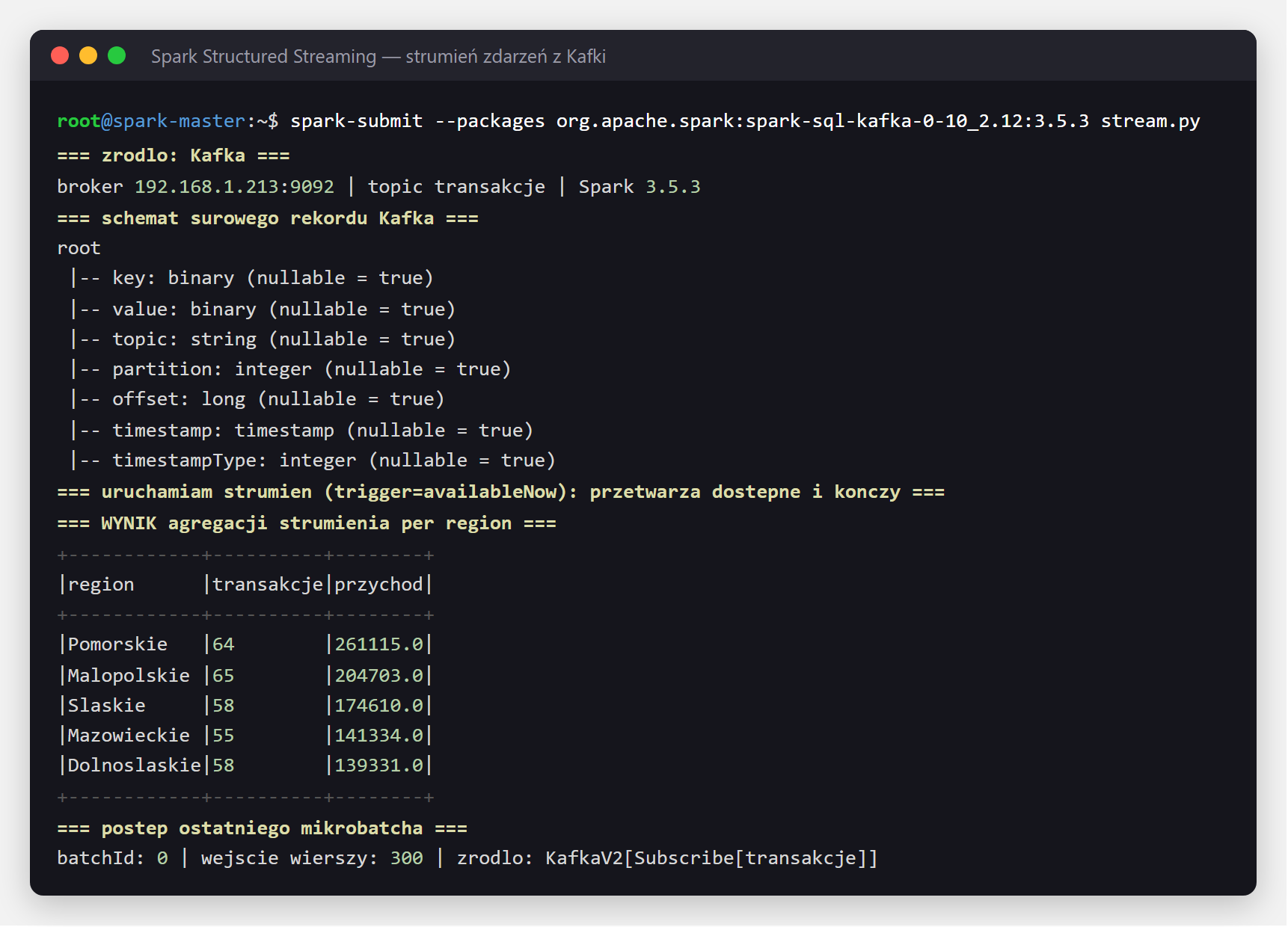
Ten sam kod, drobna zmiana ustawień i z trybu „przetwórz dostępne i zakończ" przechodzimy w tryb ciągły, który dolicza wyniki przy każdej nowej porcji zdarzeń. To właśnie zaciera granicę między analizą wsadową a strumieniową.
Ostatnia warstwa to silnik zapytań. Trino (dawniej PrestoSQL) pozwala zadać jedno zapytanie SQL nad wieloma źródłami naraz — to tzw. federacja (federation): łączenie danych z różnych systemów bez ich wcześniejszego kopiowania w jedno miejsce. Każde źródło to osobny „katalog" (catalog).
Podłączyliśmy do Trino bazę operacyjną PostgreSQL oraz wbudowany generator danych testowych TPC-H.
Kluczowa sztuczka to jedno zapytanie sięgające do obu źródeł naraz — zwykły UNION ALL
łączący tabelę z PostgreSQL z tabelami benchmarku TPC-H:
-- każde podłączone źródło to osobny katalog
SHOW CATALOGS; -- memory, postgresql, system, tpch
-- jedno zapytanie nad DWOMA źródłami naraz (federacja):
-- baza operacyjna PostgreSQL + benchmark TPC-H (lineitem = 6 mln wierszy)
SELECT zrodlo, wierszy FROM (
SELECT 'PostgreSQL: zamowienia (operacyjne)' AS zrodlo, count(*) AS wierszy
FROM postgresql.public.zamowienia
UNION ALL
SELECT 'TPC-H: orders (analityczne)', count(*) FROM tpch.sf1.orders
UNION ALL
SELECT 'TPC-H: lineitem (analityczne)', count(*) FROM tpch.sf1.lineitem
) ORDER BY wierszy;Trino sam sięga do PostgreSQL i do TPC-H, scala wyniki i zwraca jedną tabelę — bez kopiowania danych w jedno miejsce. Poniżej lista źródeł, zapytanie analityczne na 6 mln wierszy TPC-H oraz powyższa federacja w działaniu:
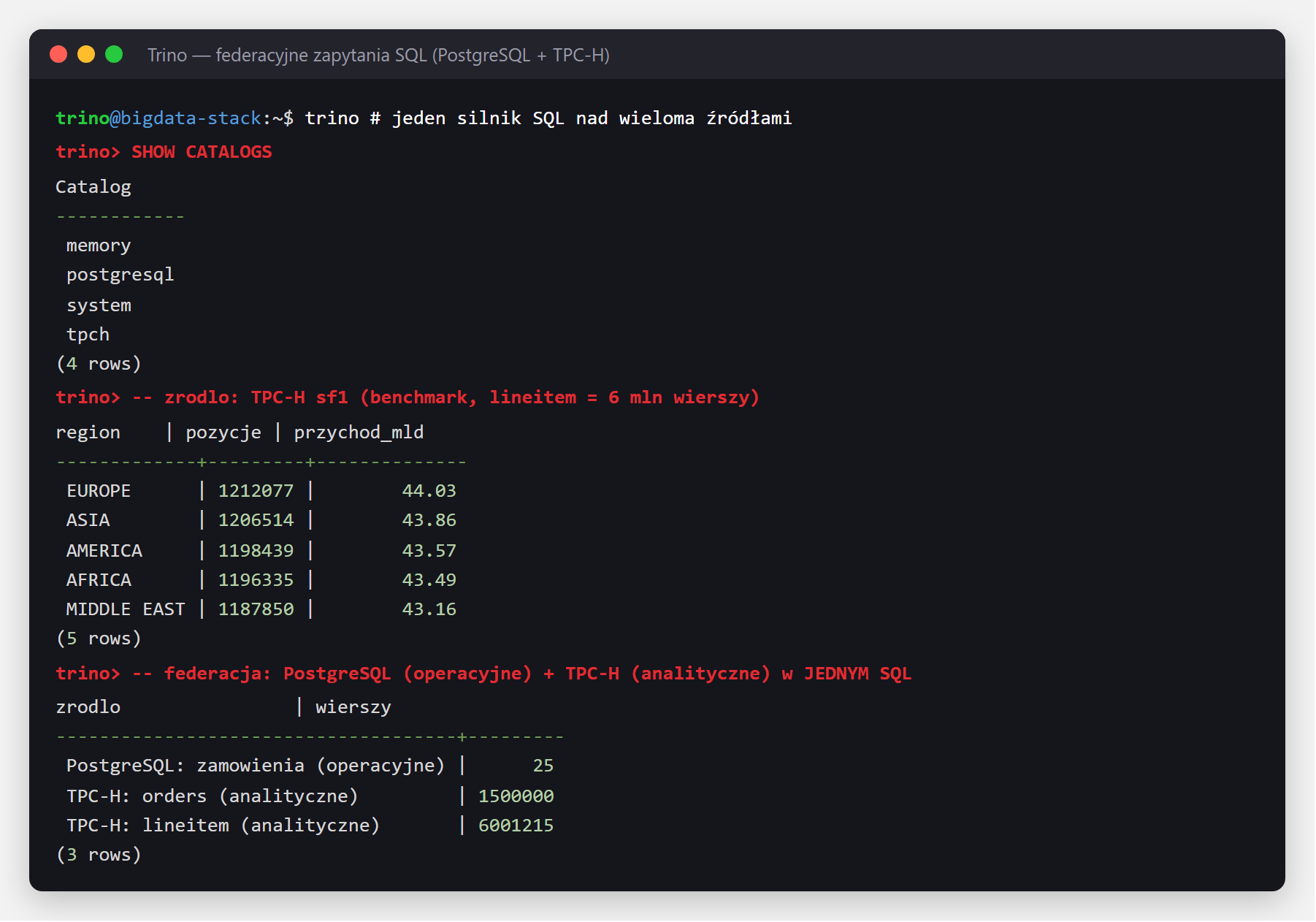
To jest siła federacji: analityk pisze zwykły SQL, a silnik sam sięga do bazy operacyjnej, do plików w magazynie obiektowym i do hurtowni — bez budowania kolejnych kopii danych.
Poszczególne klocki układają się w spójny, nowoczesny stos danych:
| Warstwa | Narzędzie (przykład) | Rola |
|---|---|---|
| Strumień zdarzeń | Apache Kafka | przyjmuje dane na bieżąco i rozdziela je do odbiorców |
| Składowanie | MinIO / S3 | tani, nieograniczony magazyn obiektowy na pliki danych |
| Przetwarzanie | Apache Spark | rozproszone obliczenia wsadowe i strumieniowe |
| Format tabel | Delta Lake / Iceberg | transakcje ACID, wersjonowanie i ewolucja schematu |
| Silnik zapytań | Trino | jeden SQL nad wieloma źródłami (federacja) |
Najważniejszy wniosek na 2026 rok: nie trzeba wybierać między tanim jeziorem a uporządkowaną hurtownią. Lakehouse na tanim składowaniu obiektowym, ten sam silnik do wsadu i strumienia oraz wspólny, federacyjny SQL — to dziś standard, do którego zmierza większość zespołów danych. A wszystkie pokazane wyżej narzędzia są otwarte (open source) i można je uruchomić u siebie, dokładnie tak jak na zrzutach powyżej.
Jeśli chcesz przejść od teorii do praktyki i samodzielnie zbudować takie przetwarzanie na Apache Spark — z realnymi danymi, transformacjami i wydajnym przetwarzaniem rozproszonym — najszybciej nauczysz się tego na szkoleniu prowadzonym przez praktyka.

Przetwarzanie danych Big Data z Apache Spark — praktyczne szkolenie z terminem gwarantowanym. Nauczysz się budować rozproszone przetwarzanie danych na realnych przykładach.
Szkolenie Big Data z Apache Spark -->
Komentarze (0)
Brak komentarzy...