Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!

RAG (Retrieval-Augmented Generation) to dziś najpopularniejsza architektura systemów AI dla firm. Zrozumienie jej 7 komponentów daje Ci kontrolę nad jakością, kosztem i utrzymaniem systemu. Bez tego zrozumienia będziesz traktować RAG jako czarną skrzynkę (black box) - i nie będziesz wiedział dlaczego Twój chatbot kłamie albo zwraca błędne dokumenty.
W tym artykule rozłożymy architekturę RAG na czynniki pierwsze: każdy komponent, co robi, jak go skonfigurować, jakie są typowe pułapki. Dla każdego dam przykład kodu w Pythonie z LangChain - możesz wziąć i uruchomić.
Spis komponentów:
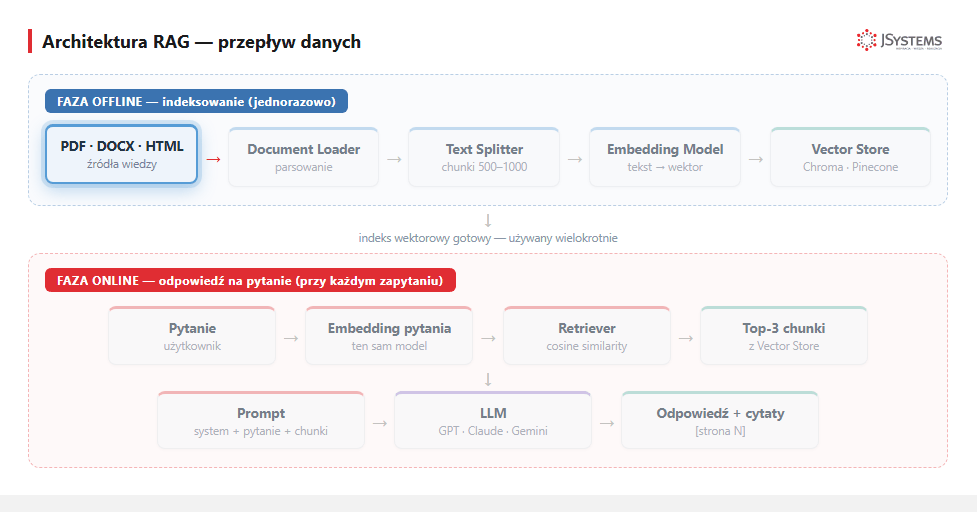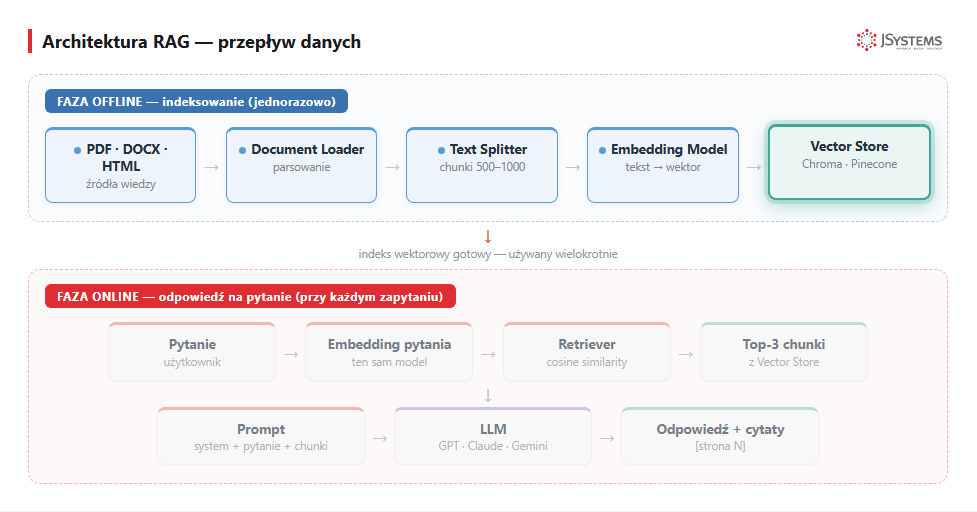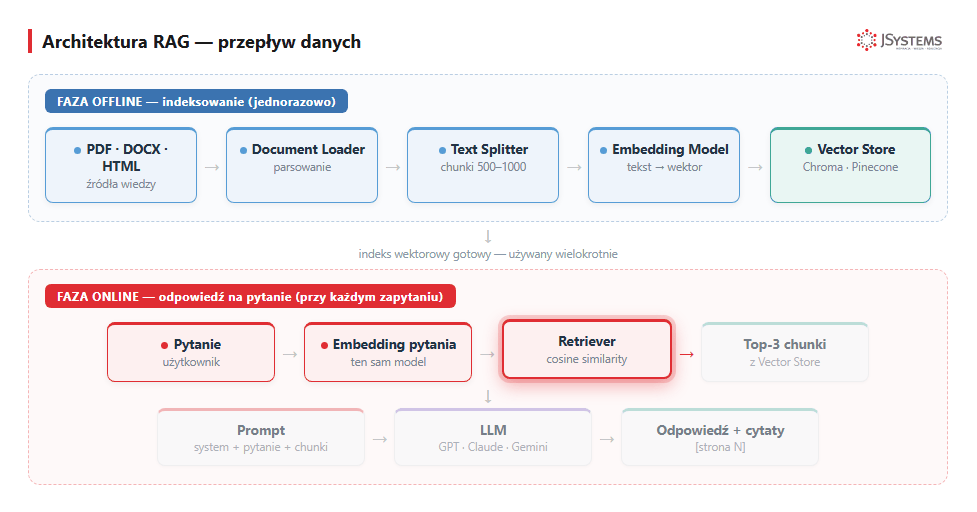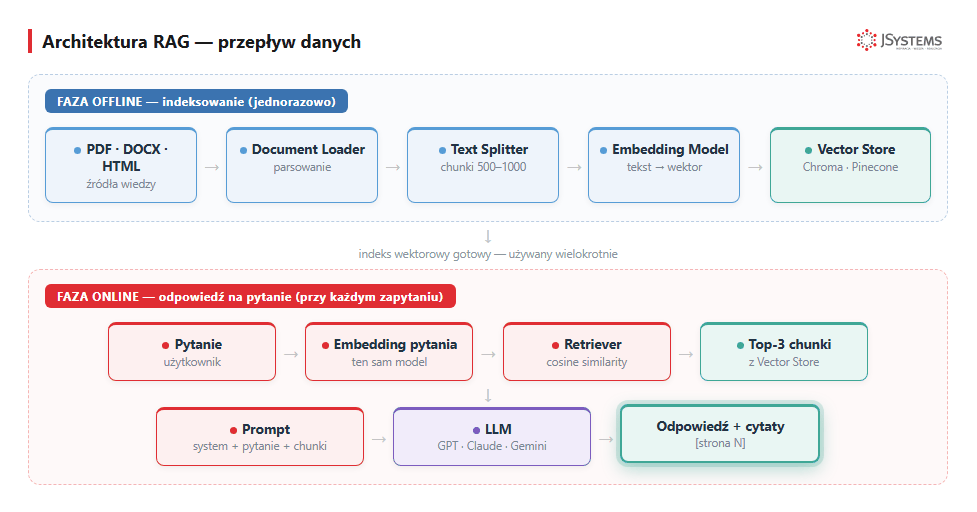
Loader pobiera surowe dokumenty z różnych źródeł i zamienia na strukturę {text, metadata}. Metadata zawiera np. źródło (filename, URL), datę, autora - przydaje się potem do cytowania.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("dokumentacja_produktu.pdf")
documents = loader.load()
# documents[0] = {"page_content": "...", "metadata": {"source": "...", "page": 1}}Typowe pułapki: (1) PDF ze skanami - potrzebujesz OCR (Tesseract, AWS Textract), (2) duże tabele - PyPDF gubi strukturę, użyj Unstructured lub Camelot, (3) wielojęzyczne dokumenty - sprawdź czy loader poprawnie obsługuje polskie znaki.
Dzieli długie dokumenty na chunki — krótkie, samodzielne fragmenty tekstu (~500-1000 tokenów, czyli mniej więcej jeden-dwa akapity). Token to dla modelu najmniejsza porcja tekstu — w przybliżeniu 4 znaki albo 3/4 słowa, więc 1000 tokenów to około 750 słów. Po co w ogóle dzielić? (1) model embeddingu ma limit długości wejścia (rzędu 8 tys. tokenów), (2) chcesz znaleźć konkretny fragment, nie cały dokument, (3) prompt modelu też ma limit i nie zmieści się w nim cała książka.
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # ~750 słów
chunk_overlap=200, # 20% overlap = utrzymujemy kontekst
separators=["\n\n", "\n", ". ", " "]
)
chunks = splitter.split_documents(documents)Najważniejsza decyzja: chunk_size, czyli rozmiar fragmentu. Za małe fragmenty - tracisz kontekst. Za duże - wyszukiwarka zwraca za dużo nieistotnego tekstu. Wartość optymalna dla większości przypadków: 800-1200 znaków z 15-20% zakładki (overlap — sąsiednie fragmenty częściowo się nakładają, żeby nie urwać zdania czy myśli w pół na granicy cięcia). Dla dokumentów technicznych ze schematami - dziel po sekcji/podsekcji, wg granic znaczeniowych (tzw. semantic chunking).
Model embeddingu zamienia tekst na wektor — po prostu długą listę liczb (np. 1536 liczb dla modelu OpenAI text-embedding-3-small). Możesz myśleć o tym jak o współrzędnych tekstu w wielowymiarowej „przestrzeni znaczeń". Taki wektor jest semantycznym „odciskiem" tekstu: fragmenty o podobnym znaczeniu mają podobne wektory (leżą blisko siebie), nawet jeśli używają zupełnie innych słów. Samo embedding (po polsku: osadzenie) to właśnie ta operacja zamiany tekstu na wektor.
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Embedding całego chunka:
vector = embeddings.embed_query("Polityka zwrotów produktów elektroniki")
# vector = [0.0124, -0.0345, 0.872, ...] # 1536 liczb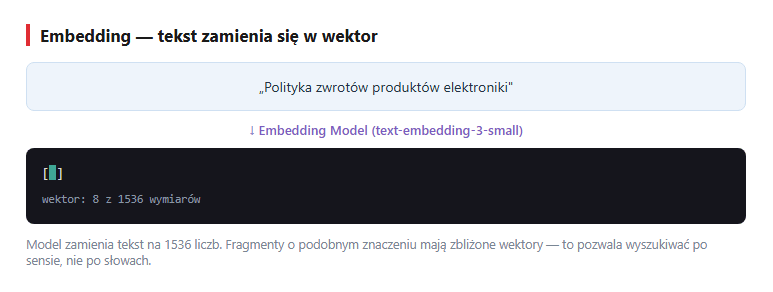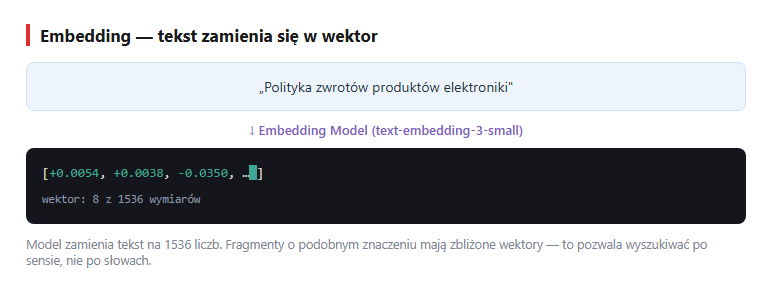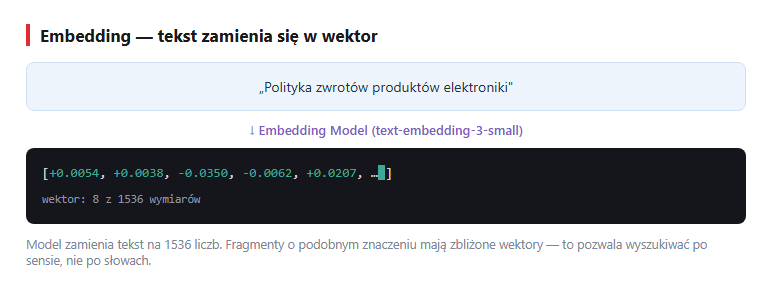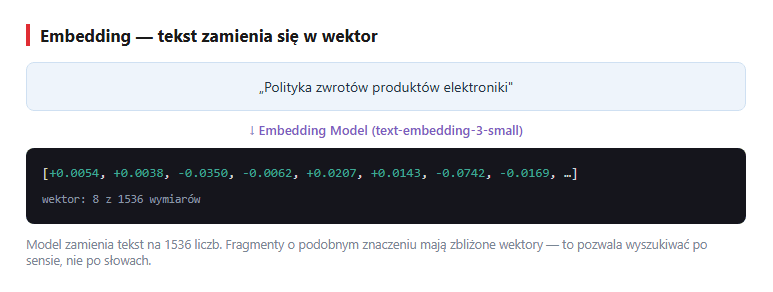
text-embedding-3-small zwraca dla każdego fragmentu wektor 1536 liczb. Animacja: tekst zamienia się w wektor 1536 liczb (realne wartości z modelu).Wybór modelu embedding: dla polskiego najlepiej text-embedding-3-large (3072 wymiary, drogie) lub text-embedding-3-small (1536 wymiarów, 5× tańsze). Lokalne alternatywy: multilingual-e5-large, bge-m3. Embedding model musi być TEN SAM podczas indeksowania i wyszukiwania - inaczej wektory są nieporównywalne.
Vector store, czyli baza wektorowa — wyspecjalizowana baza danych, która przechowuje wektory razem z tekstem i metadanymi (dodatkowymi informacjami o fragmencie: źródło, numer strony, data) i potrafi błyskawicznie znaleźć wektory najbardziej „podobne" do zadanego. Zwykła baza SQL tego nie potrafi — szukanie po podobieństwie znaczeń to właśnie zadanie bazy wektorowej. Podstawowe operacje: add(wektor, tekst, metadane) i search(wektor_pytania, top_k=3).
| Vector Store | Kiedy używać | Koszt |
|---|---|---|
| Chroma | Lokalnie, ≤100k chunks, prototyp | Darmowe (lokalne) |
| Pinecone | Cloud, ≤1M chunks, produkcja | ~70$/mies. start |
| Qdrant | Self-hosted lub cloud, produkcja | Lokalnie darmowe, cloud od ~50$ |
| PostgreSQL pgvector | Już masz Postgres, chcesz wszystko w 1 bazie | Darmowe (rozszerzenie) |
| Weaviate | Hybrydowe wyszukiwanie (semantic + keyword) | Lokalnie darmowe |
from langchain_chroma import Chroma
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db"
)Retriever (po polsku: wyszukiwacz) to warstwa nad bazą wektorową: dostaje pytanie w postaci tekstu i zwraca K najtrafniejszych fragmentów (top-K, np. 3 najlepsze). Wewnętrznie robi trzy rzeczy: (1) zamienia pytanie na wektor (embedding), (2) szuka w bazie wektorów najbliższych wektorowi pytania metodą cosine similarity — to podobieństwo cosinusowe, miara zgodności dwóch wektorów oparta na kącie między nimi: im mniejszy kąt, tym bliższe znaczenie (wartość od 0 = brak związku do 1 = identyczne), (3) zwraca fragmenty posortowane od najtrafniejszego.
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 3} # top-3 chunks
)
docs = retriever.get_relevant_documents("Jaka polityka zwrotów dla elektroniki?")
# docs = [Document(page_content="...", metadata={"source": "...", "page": 12}), ...]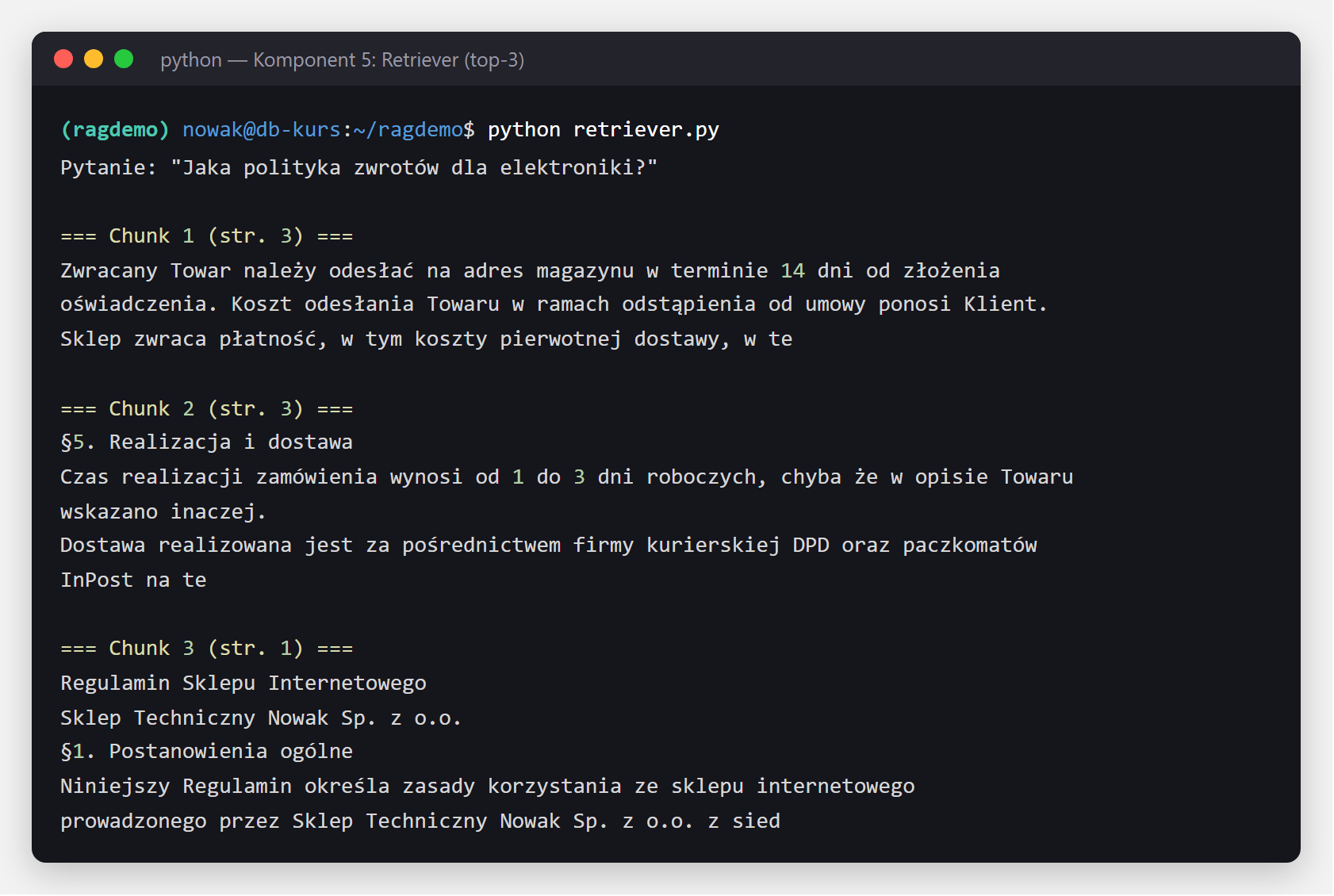
Zaawansowane techniki wyszukiwania (omawiamy na szkoleniu RAG): MMR (Maximum Marginal Relevance) — dba o różnorodność wyników, żeby nie zwracać 3× tego samego; wyszukiwanie hybrydowe (hybrid search — łączy dopasowanie znaczeniowe z dopasowaniem po słowach kluczowych metodą BM25); re-ranking (drugi model przegląda 20 wstępnych wyników i wybiera 3 najtrafniejsze); parent document retrieval (do wyszukiwania używa małych fragmentów, ale do modelu wkleja cały nadrzędny akapit, żeby nie zgubić kontekstu).
Najczęściej niedoceniany komponent. Tu definiujesz: jak LLM ma rozumieć kontekst, czy ma cytować źródła, co robić gdy nie zna odpowiedzi, jakim tonem odpowiadać.
from langchain.prompts import ChatPromptTemplate
template = """Jesteś asystentem obsługi klienta firmy XYZ.
Odpowiadaj WYŁĄCZNIE na podstawie dostarczonego kontekstu.
Jeśli kontekst nie zawiera odpowiedzi - powiedz "Nie znam odpowiedzi, skieruj zapytanie do biura@xyz.pl".
Zawsze cytuj numer strony źródła.
KONTEKST:
{context}
PYTANIE: {question}
ODPOWIEDŹ:"""
prompt = ChatPromptTemplate.from_template(template)Dobre prompty RAG zawsze: (1) jasno mówią "tylko z kontekstu", (2) instrukcję co robić gdy nie wie, (3) wymóg cytowania, (4) format odpowiedzi (lista? akapit?), (5) ograniczenia (max długość, ton).
Wreszcie - sam model językowy generujący ostateczną odpowiedź. Wybór: flagowe modele (GPT, Claude, Gemini) dla najwyższej jakości odpowiedzi; ich lżejsze, tańsze warianty (mini/haiku) dla masowego, tańszego ruchu.
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def format_docs(docs):
return "\n\n".join(f"[{d.metadata.get('page', 'N/A')}] {d.page_content}" for d in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
odpowiedz = rag_chain.invoke("Jaka polityka zwrotów dla elektroniki?")Temperature = 0 dla systemów RAG - chcemy deterministycznych odpowiedzi opartych na kontekście, nie kreatywnych zmyśleń.
{source, page} z oryginalnego dokumentu.Tak. LangChain to tylko wygodna nakładka - możesz wszystko zrobić „ręcznie" na bibliotekach niskiego poziomu (openai, chromadb, pypdf). Plus: pełna kontrola. Minus: 3-4× więcej kodu. Alternatywy dla LangChain: LlamaIndex (zoptymalizowany pod RAG), Haystack (gotowy do produkcji), DSPy (podejście deklaratywne).
Top-3 (trzy fragmenty) to dobra wartość domyślna. Top-5 jeśli pytania złożone. Powyżej top-10 - tracisz jakość (model się rozprasza), rosną koszty tokenów. Zaawansowane: zwróć z wyszukiwarki top-20, a potem osobnym modelem oceniającym (re-rankerem, np. Cohere Rerank) wybierz 3 najlepsze.
Tak. Polski jest dobrze wspierany przez OpenAI embeddings i multilingual modele jak multilingual-e5-large. Pamiętaj o normalizacji: usuwanie polskich znaków diakrytycznych jest błędem (gubi się znaczenie). Zostaw je.
Tak, jeśli używasz lokalnego LLM (Llama, Qwen) + lokalnego modelu embeddingu (BGE, e5) + lokalnej bazy wektorowej (Chroma). Cały zestaw działa wtedy na własnym serwerze (self-hosted). Wymaga karty GPU dla modelu 7B+. Idealny tam, gdzie dane nie mogą opuścić serwerowni (wymogi compliance).
Szkolenie: Tworzenie systemu RAG (LangChain + LLM OpenAI)
3 dni intensywnych warsztatów. Każdy z 7 komponentów RAG - implementacja, optymalizacja, troubleshooting. Wracasz z gotowym produkcyjnym RAG dla swojej firmy. Cena: 2 700 zł netto. Terminy gwarantowane.
Powiązane artykuły: LangChain RAG tutorial krok po kroku, RAG vs LLM - kiedy używać, co to jest agent AI.
Komentarze (0)
Brak komentarzy...