Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!

Po przeczytaniu tego artykułu zbudujesz działający system RAG (Retrieval-Augmented Generation) w Pythonie z LangChain. Kompletny kod, 7 kroków, ok 30 minut pracy. Bazą wiedzy będzie PDF Twojej firmowej dokumentacji - system będzie odpowiadał na pytania bazując wyłącznie na tym dokumencie.
Architektura: PDF --> wczytanie dokumentu (Document Loader) --> podział na fragmenty (Text Splitter) --> zamiana na wektory (OpenAI Embeddings) --> baza wektorowa Chroma --> wyszukiwarka (Retriever) --> model GPT --> odpowiedź z cytowaniem źródeł. Wszystkie te komponenty — i co dokładnie robią — omawiamy szczegółowo w artykule o architekturze RAG.
Z tego artykułu dowiesz się:
regulamin.pdf, polityka_zwrotow.pdf)pip install langchain langchain-community langchain-openai \
langchain-chroma chromadb pypdf python-dotenvStwórz plik .env z kluczem API:
OPENAI_API_KEY=sk-proj-...Pierwszy etap - PyPDFLoader z LangChain pobiera tekst z PDF strona po stronie, zachowując metadata o numerze strony.
from dotenv import load_dotenv
from langchain_community.document_loaders import PyPDFLoader
load_dotenv()
loader = PyPDFLoader("regulamin.pdf")
documents = loader.load()
print(f"Załadowano {len(documents)} stron")
print(f"Pierwsza strona ({len(documents[0].page_content)} znaków):")
print(documents[0].page_content[:300])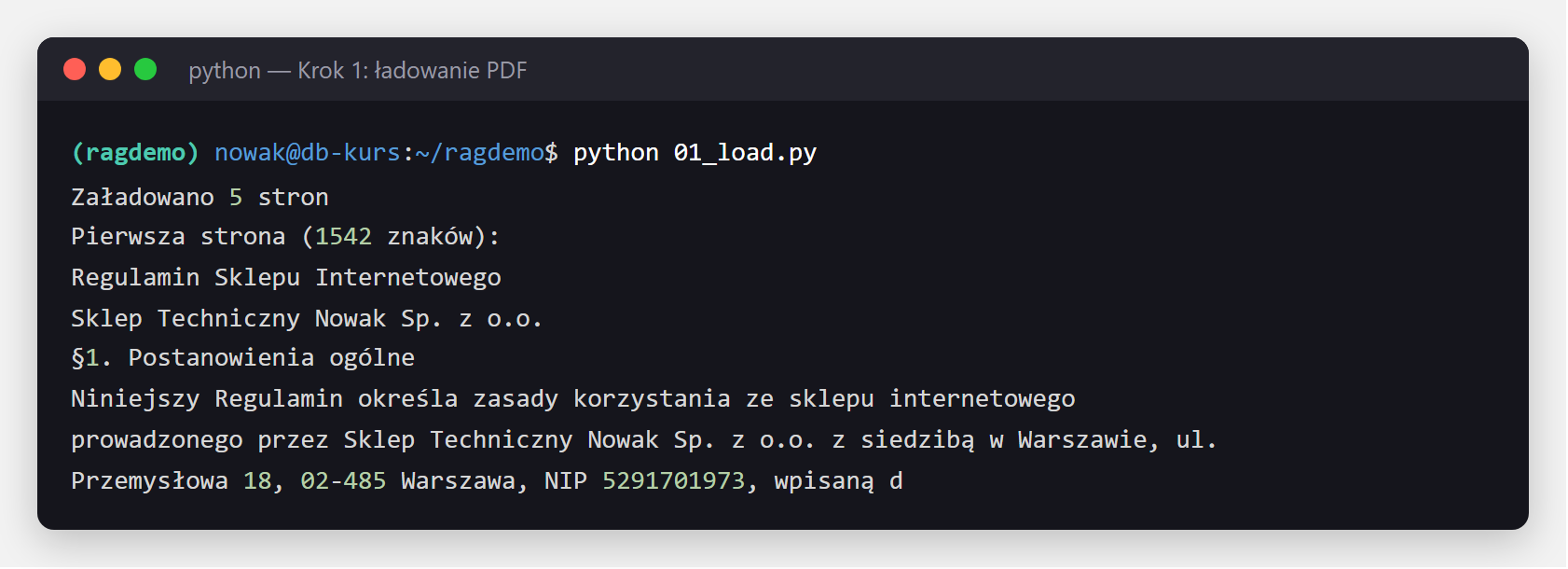
Document z tekstem i metadanymi (numer strony, źródło).Wynik: każda strona PDF = jeden Document z page_content (tekst) i metadata (źródło, nr strony).
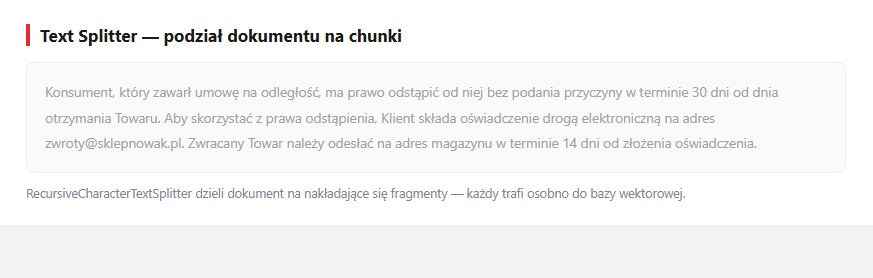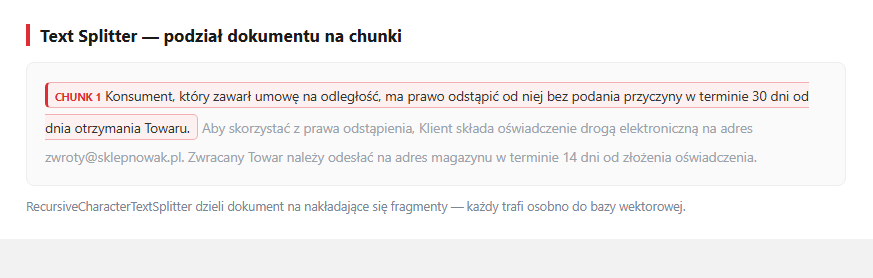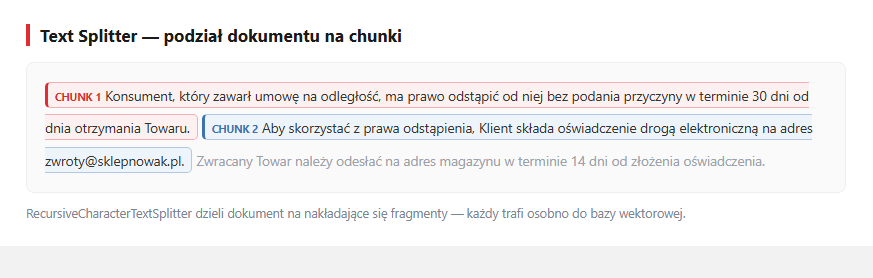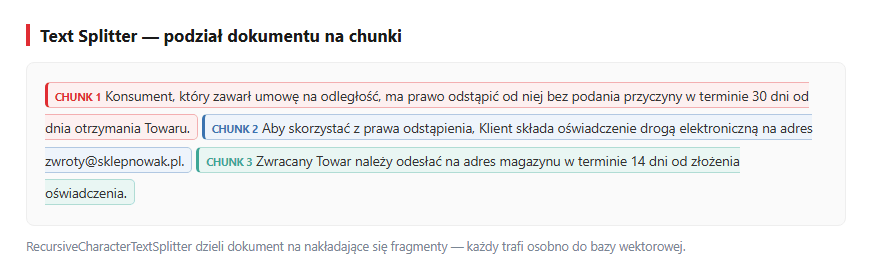
Strony bywają długie - dzielimy je na chunki (krótkie fragmenty tekstu) po ~1000 znaków, z 200-znakową zakładką (overlap — sąsiednie fragmenty częściowo się nakładają, żeby nie urwać zdania w pół na granicy cięcia). Splitter stara się ciąć na granicach akapitów i zdań, żeby każdy fragment był spójny znaczeniowo.
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ". ", " ", ""]
)
chunks = splitter.split_documents(documents)
print(f"Podzielono na {len(chunks)} chunków")
print(f"Średnia długość: {sum(len(c.page_content) for c in chunks) // len(chunks)} znaków")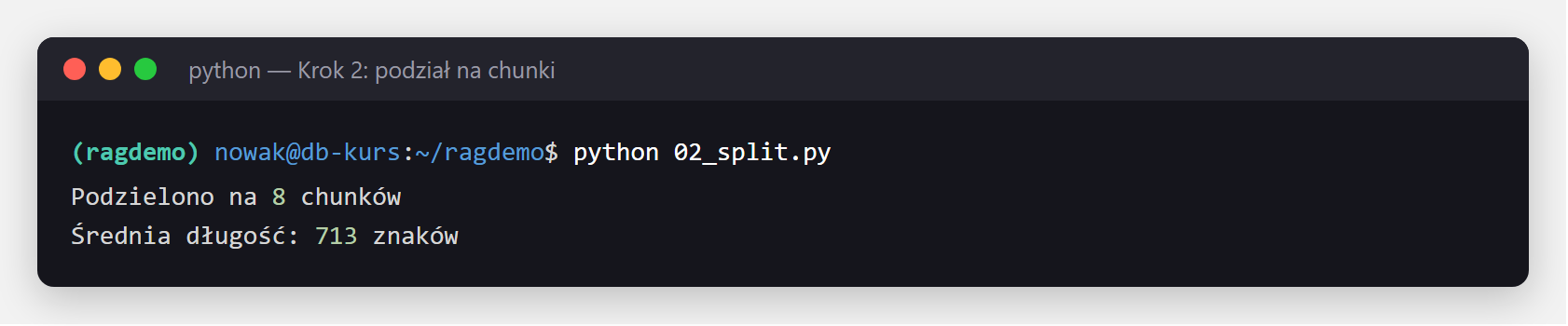
Embeddingi (osadzenia) - liczbowa reprezentacja znaczenia każdego fragmentu: wektor, czyli lista liczb (tu 1536). Fragmenty o podobnym sensie dostają podobne wektory - i dzięki temu można je wyszukiwać po znaczeniu, a nie po dokładnych słowach. Używamy modelu text-embedding-3-small (1536 wymiarów, 0,02 $ za milion tokenów - bardzo tanio).
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Test - zamień jeden chunk na wektor
sample_vector = embeddings.embed_query(chunks[0].page_content)
print(f"Wektor ma {len(sample_vector)} wymiarów")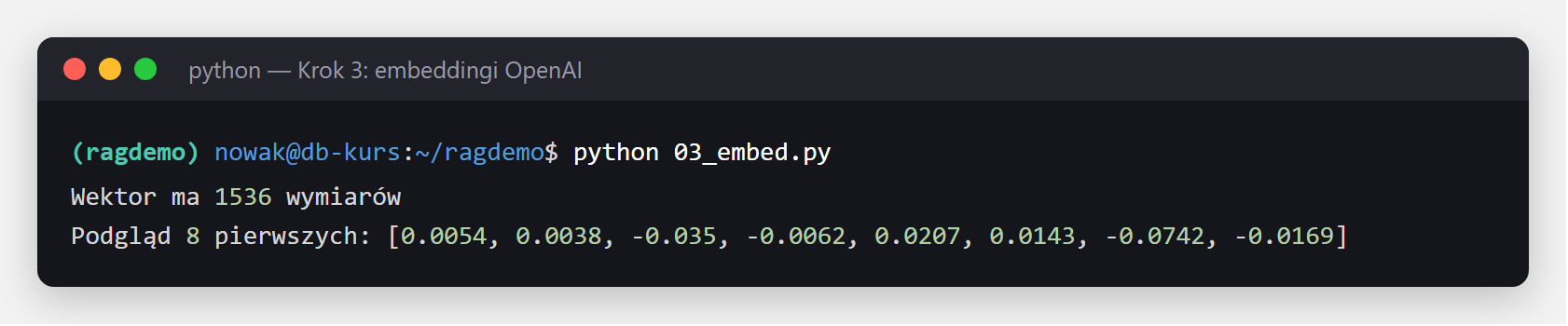
text-embedding-3-small zamienił chunk na wektor 1536 liczb. To semantyczny „odcisk" tekstu — fragmenty o podobnym znaczeniu mają podobne wektory.
Chroma to lokalna baza wektorowa (vector store) - przechowuje wektory i błyskawicznie znajduje najbardziej podobne. Przy pierwszym uruchomieniu indeksujemy fragmenty. Przy kolejnych - tylko czytamy gotowy indeks z dysku (5-10× szybciej).
from langchain_chroma import Chroma
import os
PERSIST_DIR = "./chroma_db"
if os.path.exists(PERSIST_DIR):
print("Wczytuję istniejący vector store...")
vectorstore = Chroma(
persist_directory=PERSIST_DIR,
embedding_function=embeddings
)
else:
print("Indeksuję dokumenty (jednorazowo)...")
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=PERSIST_DIR
)
print(f"Zindeksowano {len(chunks)} chunków")
./chroma_db). Przy kolejnych uruchomieniach wczytujemy gotowy indeks zamiast liczyć embeddingi od nowa.
Retriever (wyszukiwacz) to warstwa nad bazą wektorową: dostaje pytanie i zwraca kilka najtrafniejszych fragmentów. Tutaj prosimy o 3 najlepsze (k=3) — to one za chwilę trafią do promptu modelu.
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 3} # top-3 najlepiej dopasowane chunki
)
# Test retrievera
test_docs = retriever.invoke("Jaki jest termin reklamacji?")
for i, doc in enumerate(test_docs, 1):
print(f"\n=== Wynik {i} (str. {doc.metadata.get('page', 0) + 1}) ===")
print(doc.page_content[:200])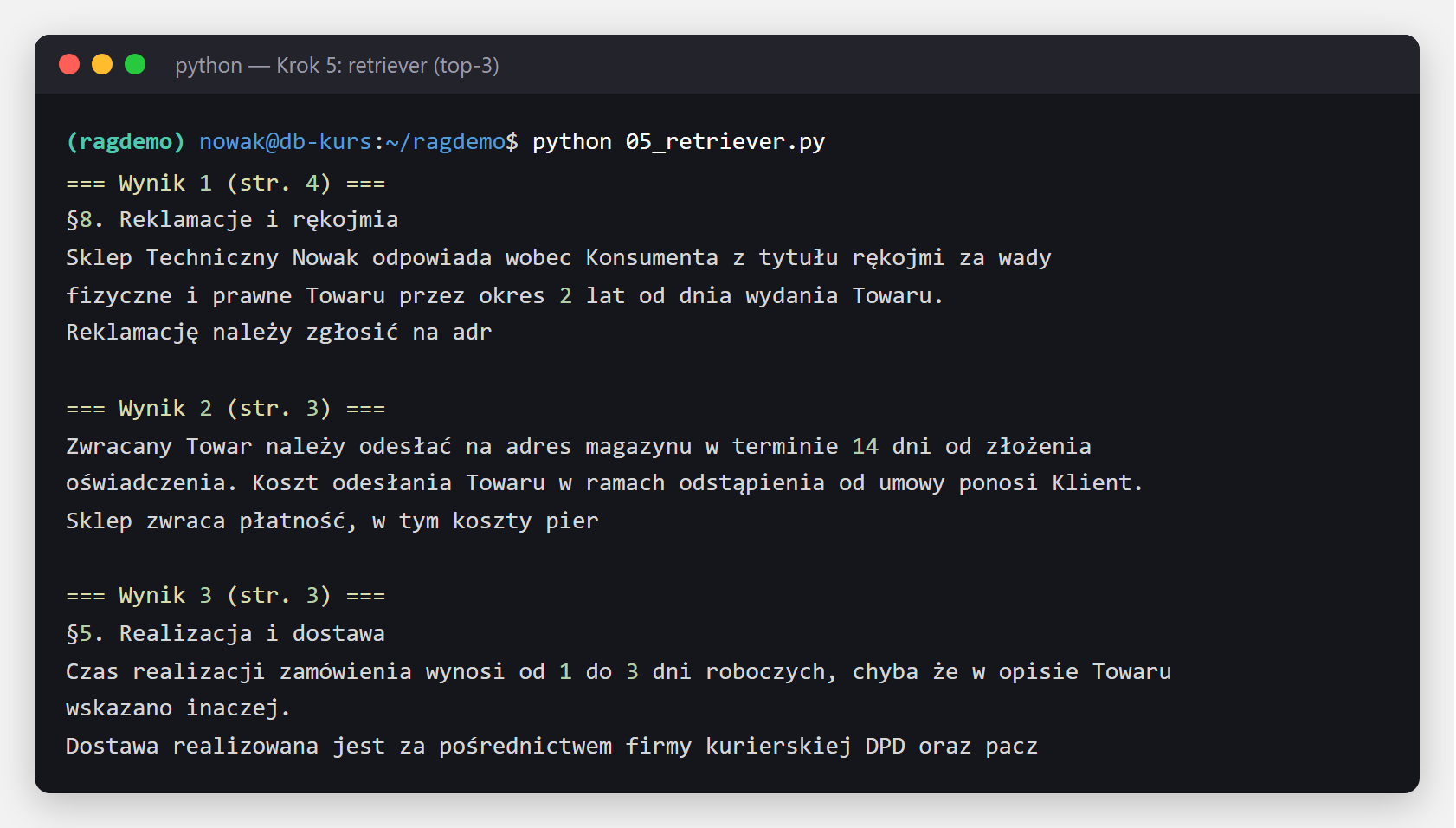
Najważniejszy krok - łączymy wszystko w jeden łańcuch (chain - kolejne kroki przekazują sobie nawzajem wynik: wyszukiwarka --> prompt --> model --> tekst). Prompt instruuje model, żeby odpowiadał TYLKO na podstawie kontekstu i cytował źródła.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
prompt_template = """Jesteś asystentem firmy XYZ.
Odpowiadaj WYŁĄCZNIE na podstawie poniższego kontekstu.
Jeśli kontekst nie zawiera odpowiedzi - powiedz dokładnie:
"Nie znam odpowiedzi na to pytanie. Skontaktuj się z biurem: biuro@xyz.pl".
Zawsze cytuj numer strony w nawiasie kwadratowym, np. [strona 12].
KONTEKST:
{context}
PYTANIE: {question}
ODPOWIEDŹ:"""
prompt = ChatPromptTemplate.from_template(prompt_template)
def format_docs(docs):
return "\n\n".join(
f"[strona {d.metadata.get('page', 0) + 1}] {d.page_content}"
for d in docs
)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)pytania = [
"Jaki jest termin reklamacji produktu?",
"Czy mogę zwrócić produkt zakupiony online?",
"Jak skontaktować się z biurem obsługi?",
"Jaka jest stolica Francji?", # spoza kontekstu
]
for q in pytania:
print(f"\n{'='*60}\nPYTANIE: {q}")
odpowiedz = rag_chain.invoke(q)
print(f"\nODPOWIEDŹ:\n{odpowiedz}")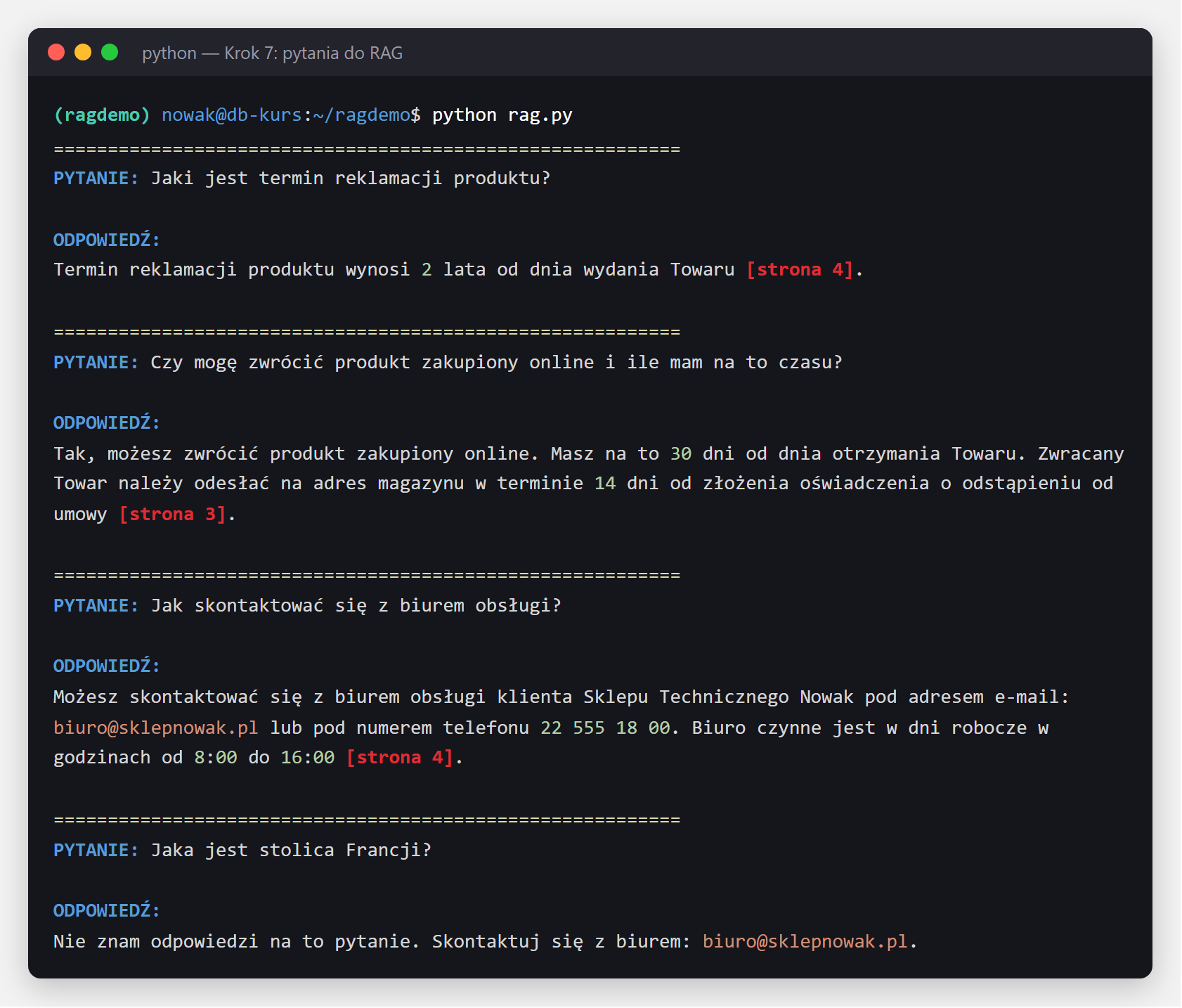
Dla pytań w zakresie dokumentu - RAG odpowie z cytatami. Dla pytania o stolicę Francji - powie "nie znam, skontaktuj się z biurem" (bo nie ma w dokumencie regulaminu).
Tokeny (kawałki słów) pojawiają się na żywo, zamiast kazać użytkownikowi czekać na całą odpowiedź - lepsze wrażenia z korzystania (UX).
print("\nOdpowiedź na żywo:")
for chunk in rag_chain.stream("Jaki jest termin reklamacji?"):
print(chunk, end="", flush=True)
print()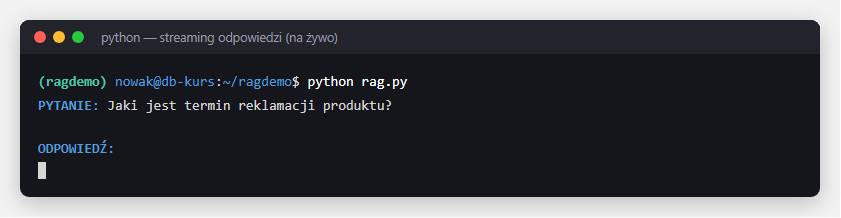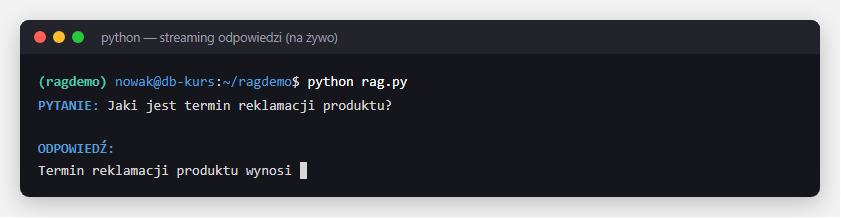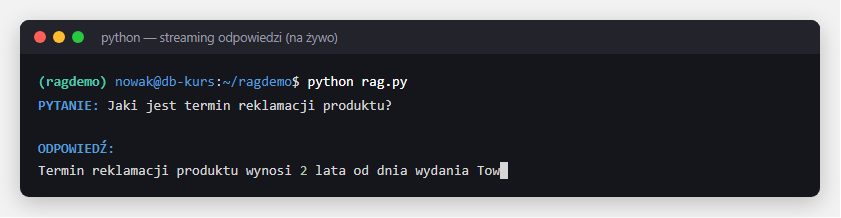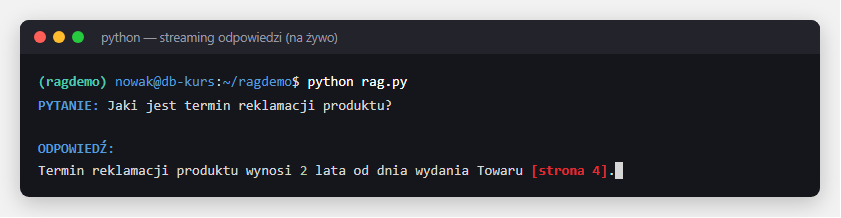
rag_chain.stream().Indeksowanie wielu dokumentów:
from pathlib import Path
PDF_DIR = Path("dokumentacja")
all_chunks = []
for pdf_path in PDF_DIR.glob("*.pdf"):
print(f"Ładuję {pdf_path.name}...")
loader = PyPDFLoader(str(pdf_path))
docs = loader.load()
# Dodaj nazwę pliku do metadata każdej strony
for d in docs:
d.metadata["source"] = pdf_path.name
chunks = splitter.split_documents(docs)
all_chunks.extend(chunks)
print(f"\nŁącznie {len(all_chunks)} chunków z {PDF_DIR}")
vectorstore = Chroma.from_documents(all_chunks, embeddings, persist_directory=PERSIST_DIR)Powyższy kod to MVP (najprostsza działająca wersja) - działa, ale do produkcji potrzeba kilku usprawnień:
Trzy przyczyny: (1) chunk_size jest zły - za małe gubią kontekst, za duże mają za dużo nieistotnego tekstu, (2) embedding model nie pasuje do języka - dla polskiego użyj text-embedding-3-large lub multilingual-e5-large, (3) brak wyszukiwania hybrydowego - przy pytaniach ze specyficznymi terminami (numer artykułu, kod produktu) samo wyszukiwanie znaczeniowe gubi się i potrzebne jest dopasowanie po słowach kluczowych (BM25).
Tak. Zamień ChatOpenAI na ChatAnthropic (z langchain-anthropic). Do embeddingów Claude nie ma własnego modelu - możesz użyć Voyage AI (VoyageAIEmbeddings) lub zostać przy embeddingach OpenAI. Zestaw „Claude jako model + embeddingi OpenAI" to bardzo popularne połączenie.
Zbuduj zestaw 50-100 par "pytanie --> oczekiwana odpowiedź" przez kogoś z dziedziny. Sprawdzaj automatycznie trzy rzeczy: wierność (faithfulness) - czy odpowiedź faktycznie wynika z kontekstu, trafność (relevance) - czy odpowiada na zadane pytanie, precyzję kontekstu (context precision) - czy wyszukiwarka zwróciła naprawdę pasujące fragmenty. Narzędzia: ragas, deepeval.
Dla 10 000 zapytań/mies. (typowy chatbot obsługi klienta): embeddingi dla pytań ~0,10 $, wyszukiwanie (lokalny Chroma) 0 $, model językowy (lekki GPT) ~5-10 $. Razem: ~10-15 $/mies. Skala 100 000 zapytań/mies. = ~100 $. Przy 1M+ zapytań warto rozważyć fine-tuning (douczenie modelu na własnych danych), żeby oszczędzić na tokenach.
Szkolenie: Tworzenie systemu RAG (LangChain + LLM OpenAI)
3 dni intensywnych warsztatów dla programistów Python. Każdy uczestnik buduje pełen produkcyjny RAG z optymalizacją, monitoringiem i deploymentem. Wracasz z gotowym systemem dla swojej firmy. Terminy gwarantowane.
Powiązane artykuły: architektura RAG - komponenty, RAG vs LLM - kiedy używać, co to jest agent AI, Claude API w aplikacjach Python.
Komentarze (0)
Brak komentarzy...