Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
Trzy techniki dawania modelowi AI wiedzy specyficznej dla Twojej firmy: prompt engineering, RAG, fine-tuning. Wybór złego podejścia kosztuje tygodnie pracy i często setki tysięcy złotych. Wybór dobrego daje rozwiązanie które działa w tydzień.
W tym artykule rozkładamy na czynniki pierwsze: kiedy używać samego LLM-a (bez RAG), kiedy włączyć RAG, a kiedy iść w fine-tuning. Decyzja powinna trwać 5 minut po przeczytaniu.
Z artykułu dowiesz się:
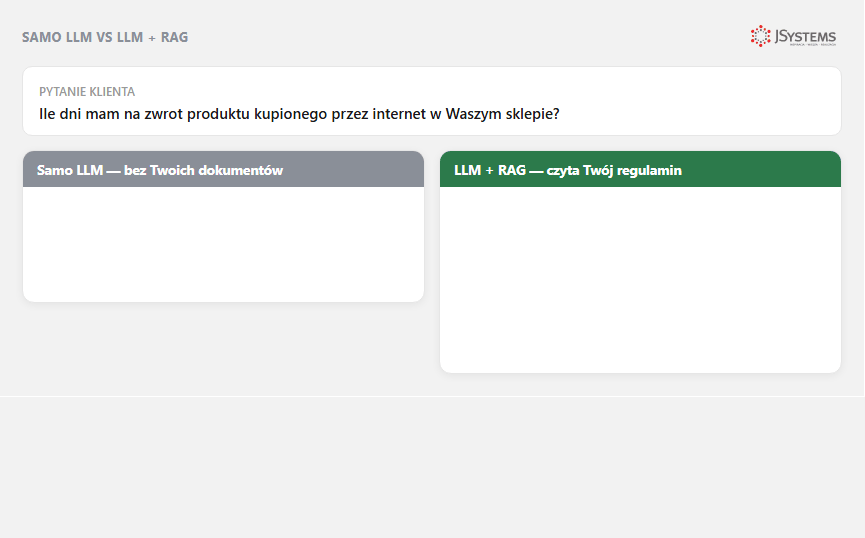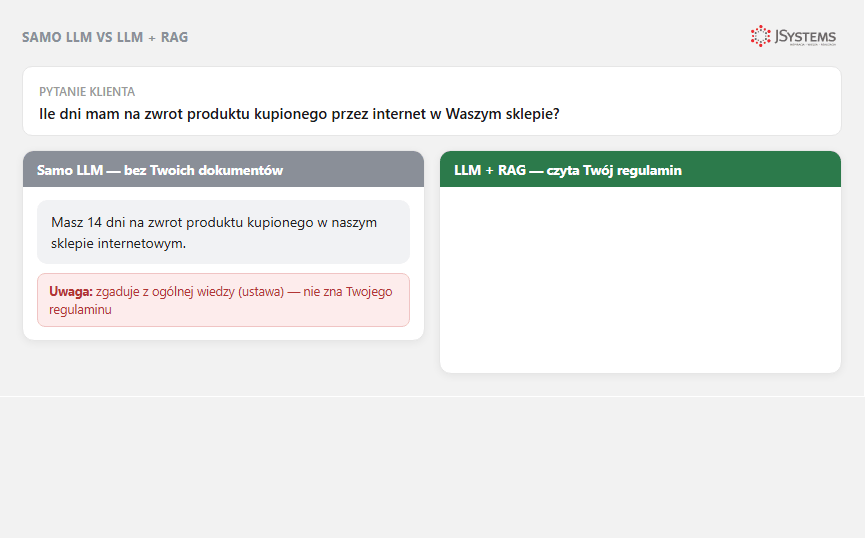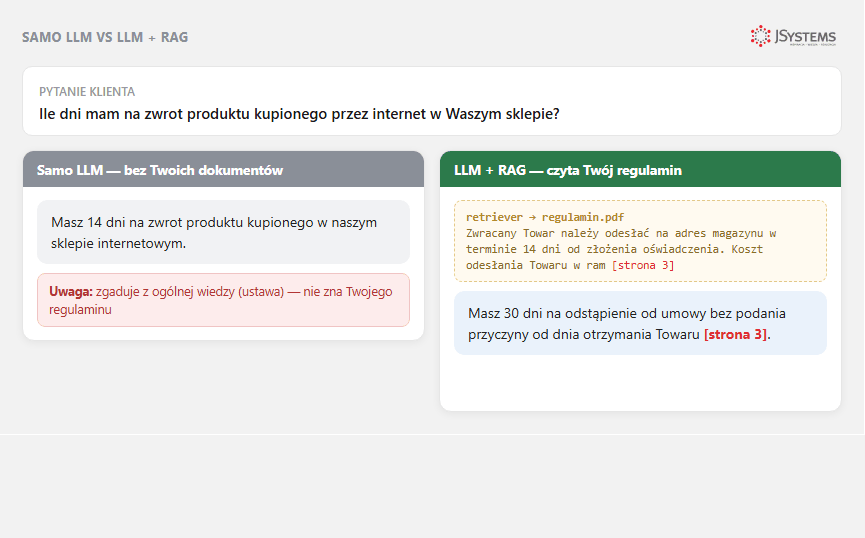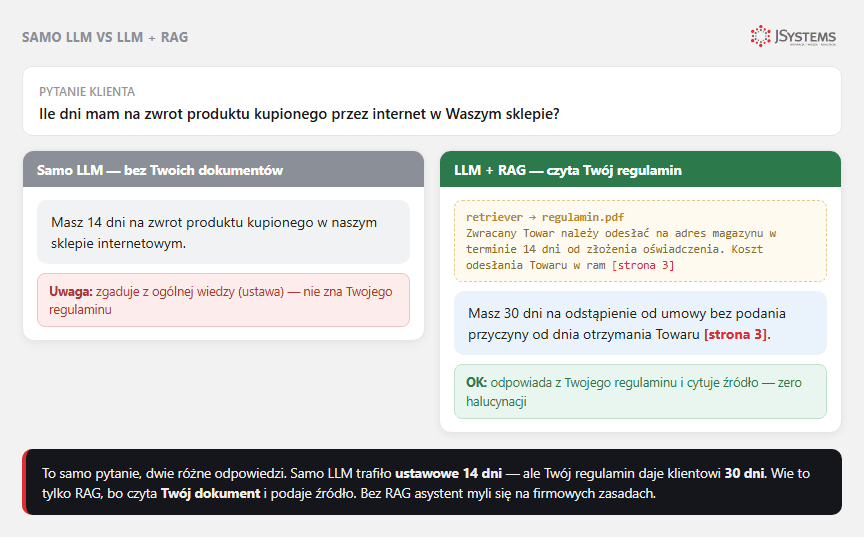
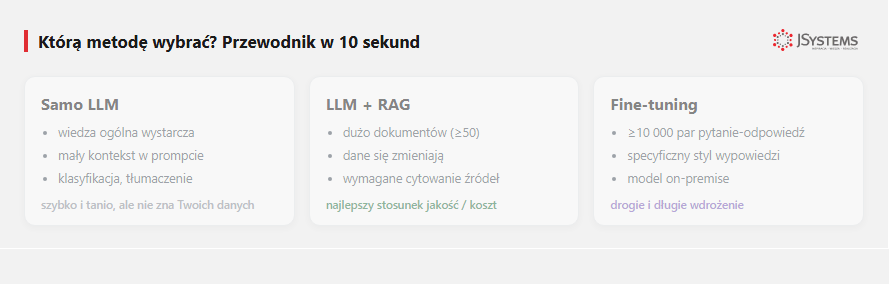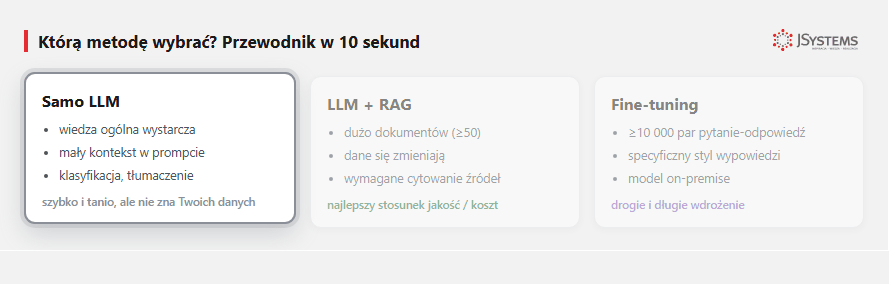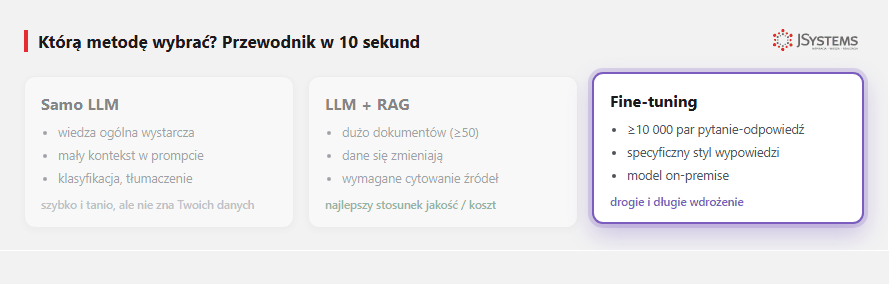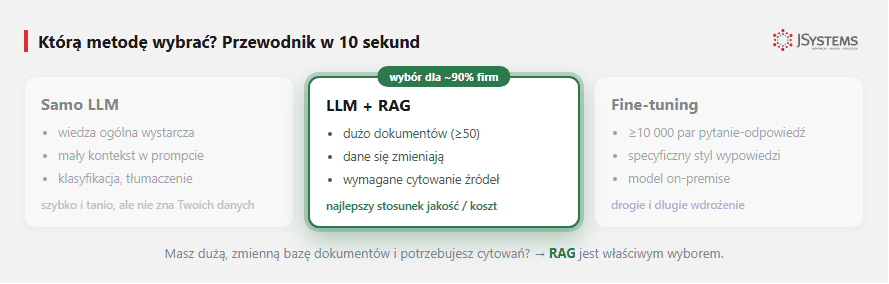
„Samodzielne LLM" (po angielsku zero-shot - model dostaje samo pytanie, bez przykładów i bez dodatków) - to wywołanie modelu (GPT, Claude, Gemini) z samym pytaniem, bez dodatkowej wiedzy. Model odpowiada wyłącznie na podstawie tego, co zapamiętał podczas treningu. Wiedza modelu jest zamrożona w momencie tzw. cut-off date (daty końca danych treningowych).
Przykład samodzielnego LLM: pytasz ChatGPT "co to jest TypeScript?" - odpowiada. Pytasz "ile masz na koncie magazynowym SKU-12345?" - nie wie, bo nie ma dostępu do Twojej bazy.
RAG (Retrieval-Augmented Generation) - przed wywołaniem LLM system najpierw wyszukuje pasujące do pytania fragmenty z Twojej bazy wiedzy (np. dokumentacja produktu, procedury, polityki), wkleja je do promptu, dopiero potem prosi LLM o odpowiedź. Model odpowiada bazując na Twoich dokumentach.
Pełną architekturę RAG omawiamy w osobnym artykule. Tutaj wystarczy że wiesz: retrieval = wyszukiwanie z Twojej bazy, augmented = wzbogacanie promptu, generation = LLM generuje odpowiedź.
Fine-tuning - dodatkowy etap treningu modelu na Twoich danych (przykładowo: 10 000 par "pytanie - odpowiedź" specyficznych dla Twojej domeny). Po fine-tuningu model natywnie rozumie Twoje słownictwo, styl odpowiedzi, specyficzne reguły. Wiedza jest "wszyta" w wagi modelu.
| Kryterium | Samodzielne LLM | LLM + RAG | Fine-tuning |
|---|---|---|---|
| Czas wdrożenia | Godziny (samo wywołanie API) | 5-15 dni | 4-12 tygodni |
| Koszt wdrożenia | Pomijalny (tylko integracja) | Średni (pipeline + baza wektorowa) | Wysoki (dane + trening + infrastruktura) |
| Koszt zapytań (tokeny) | Najniższy | Wyższy (więcej tokenów w kontekście) | Niższy (krótsze prompty) |
| Aktualność danych | Zamrożona na cut-off date | Na bieżąco (zależy od bazy) | Zamrożona na moment treningu |
| Halucynacje | Wysokie ryzyko | Niskie (cytuje źródła) | Średnie |
| Aktualizacja wiedzy | Niemożliwa | Dodaj dokument do bazy (sekundy) | Re-trening (tygodnie + $$$$) |
| Cytowanie źródeł | Nie | Tak (z RAG retrieve) | Nie |
| Wymagana wielkość danych | 0 | ≥50 dokumentów | ≥10 000 par Q&A |
Samo LLM wystarcza w 3 typowych sytuacjach:
RAG to optymalny wybór gdy:
Najczęstsze zastosowania: chatbot wsparcia klienta (FAQ), wyszukiwanie w dokumentacji wewnętrznej, asystent prawny, asystent HR (regulaminy), pomoc dla pracowników (procedury).
Fine-tuning to opcja niszowa. Wybierz ją tylko gdy:
| Use case | Wybór | Dlaczego |
|---|---|---|
| Asystent dla obsługi klienta z 200 stron dokumentacji | RAG | Duża baza, zmienia się, cytowanie |
| Klasyfikacja maili (sprzedaż / wsparcie / reklamacja) | Samo LLM | Brak wiedzy specyficznej |
| Generowanie maili sprzedażowych w stylu firmy | Fine-tuning lub RAG | FT jeśli ≥10 tys. przykładów, inaczej RAG z 50 wzorcami |
| Asystent prawny - przeszukiwanie umów | RAG | Wymagane cytowanie, brak halucynacji |
| Tłumaczenie technicznych dokumentów | Samo LLM + glosariusz w prompcie | Glosariusz mieści się w 2 tys. tokenów |
W praktyce większość systemów AI dla firm to hybryda RAG + prompt engineering. RAG dostarcza wiedzę specyficzną, prompt engineering definiuje styl odpowiedzi, ton, format. Fine-tuning to zwykle przerost formy nad treścią (overkill).
Przykład hybrydy: chatbot do obsługi klienta. RAG dostarcza informacje o produktach i polityce zwrotów. Prompt engineering definiuje: "odpowiadasz po polsku, używasz formy Pan/Pani, nigdy nie obiecujesz zwrotu większego niż 30 dni, zawsze pytasz o numer zamówienia gdy klient prosi o status." Razem dają jakość zbliżoną do fine-tuningu, a kosztują i zajmują znacznie mniej.
W większości biznesowych przypadków - tak. RAG jest szybszy do wdrożenia, tańszy, łatwiejszy w utrzymaniu, pokazuje źródła. Fine-tuning ma sens tylko jeśli (1) masz dużo wysokiej jakości danych treningowych (≥10 tys.), (2) potrzebujesz specyficznego stylu którego nie da się osiągnąć przez prompt, (3) zarząd domaga się lokalnej instalacji modelu i danych.
Tak, to zaawansowane podejście. Fine-tunujesz model na "jak odpowiadać" (styl, format), a RAG dostarcza "na co odpowiadać" (faktyczne dane). Stosowane przez duże korporacje. Dla MŚP to przesada - RAG + prompt engineering wystarczy.
Zależy od priorytetów: najtaniej - lekki model (Claude lub mały wariant GPT, kilkadziesiąt razy tańszy od flagowych). Najlepsza jakość - Claude lub flagowy GPT. Lokalnie / na własnym serwerze (on-premise) - modele open source jak Llama lub Qwen. Dla większości firm: zacznij od Claude, potem optymalizuj. Pomożemy wybrać na szkoleniu RAG.
Minimum praktyczne to 20-50 dokumentów (200-500 chunks po podzieleniu). Poniżej tego prompt engineering może być lepszy. Górna granica praktycznie nie istnieje - RAG działa nawet na 50 000+ dokumentach (na przykład pełna dokumentacja techniczna producenta sprzętu).

Szkolenie: Tworzenie systemu RAG (LangChain + LLM OpenAI)
3 dni intensywnych warsztatów. Budujesz pełen system RAG od zera - od loaderów dokumentów przez vector store po orchestrację LangChain. Terminy gwarantowane.
Powiązane artykuły: architektura RAG - komponenty, LangChain RAG tutorial, co to jest agent AI.

Komentarze (0)
Brak komentarzy...