Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
Z tego artykułu dowiesz się:
/context/clear a /compact oraz jak działa auto-kompaktowanie/usage), dobierać model i prowadzić długie, tanie sesjePraca z agentem AI kosztuje - każde zapytanie to tokeny, a tokeny to pieniądze. Naturalny odruch to martwić się, że długie sesje i duży kontekst muszą być drogie. Dobra wiadomość jest taka, że Claude Code ma wbudowany mechanizm, który sprawia, że jest dużo taniej, niż się wydaje: prompt caching. Co lepsze - działa automatycznie i nie musisz nic konfigurować. Warto tylko zrozumieć, dlaczego działa, żeby świadomie obniżać koszty.

Każde zapytanie do modelu niesie ze sobą sporo stałego kontekstu: instrukcję systemową, opisy wszystkich narzędzi, pliki pamięci (CLAUDE.md). To się prawie nie zmienia między wiadomościami, a mimo to normalnie trzeba by to przeliczać za każdym razem. Prompt caching to zmienia: ten powtarzalny kontekst trafia do cache przy pierwszym zapytaniu (to droższy, jednorazowy zapis), a przy kolejnych jest z niego czytany - wielokrotnie taniej niż liczenie od nowa. Im dłużej trwa sesja, tym bardziej się to opłaca.
Uwaga: prompt caching w Claude Code jest w pełni automatyczny. Niczego nie włączasz, nie ustawiasz żadnej flagi ani opcji w konfiguracji. Claude Code sam decyduje, który fragment zapytania zapisać do cache i sam czyta go z powrotem przy kolejnych turach. (Gdybyś pisał własną integrację na surowym API, musiałbyś zaznaczać to ręcznie parametrem cache_control. W Claude Code masz to za darmo, od pierwszego uruchomienia.)
To nie teoria: caching widać wprost w danych zużycia, i najlepiej sprawdzić go samodzielnie. Wystarczy uruchomić to samo zapytanie dwa razy w tym samym katalogu i porównać koszt. Klucz to tryb wsadowy (flaga -p, tzw. tryb headless) z wynikiem w formacie JSON - pokazuje surowe liczby tokenów, w tym te dotyczące cache. Sam koszt i pola cache wygodnie wyłuskać przez jq:
# 1. bieg - część kontekstu jeszcze dochodzi do cache (zapis_cache > 0)
claude -p "streść, co robi ten katalog" --output-format json | jq '{koszt: .total_cost_usd, zapis_cache: .usage.cache_creation_input_tokens, odczyt_cache: .usage.cache_read_input_tokens}'
# 2. bieg - to samo pytanie w ciągu ~5 min: nic nie tworzymy, wszystko z cache
claude -p "streść, co robi ten katalog" --output-format json | jq '{koszt: .total_cost_usd, zapis_cache: .usage.cache_creation_input_tokens, odczyt_cache: .usage.cache_read_input_tokens}'Uwaga (Windows): samo claude --output-format json działa tak samo na każdym systemie, ale jq nie jest wbudowane w Windows - najpierw je zainstaluj (winget install jqlang.jq). Dalej to samo wywołanie różni się tylko cudzysłowami wokół filtra - w PowerShell pojedyncze (jak na Linux/macOS), w cmd.exe podwójne:
# PowerShell - pojedyncze cudzysłowy wokół filtra (jak na Linux/macOS)
claude -p "streść, co robi ten katalog" --output-format json | jq '{koszt: .total_cost_usd, zapis_cache: .usage.cache_creation_input_tokens, odczyt_cache: .usage.cache_read_input_tokens}'
# cmd.exe - ten sam filtr w podwójnych cudzysłowach
claude -p "streść, co robi ten katalog" --output-format json | jq "{koszt: .total_cost_usd, zapis_cache: .usage.cache_creation_input_tokens, odczyt_cache: .usage.cache_read_input_tokens}"Nie chcesz instalować jq? Pomiń potok | jq … i odczytaj wprost z surowego JSON-a pola total_cost_usd, cache_creation_input_tokens oraz cache_read_input_tokens - to działa wszędzie bez dodatkowych narzędzi.
Różnica między biegami jest sednem mechanizmu: w drugim nic nie trzeba tworzyć od nowa (zapis_cache: 0), a cały stały kontekst czytany jest z cache za ułamek ceny:
# wynik 1. biegu
{ "koszt": 0.043006, "zapis_cache": 2247, "odczyt_cache": 14162 }
# wynik 2. biegu
{ "koszt": 0.022054, "zapis_cache": 0, "odczyt_cache": 16409 }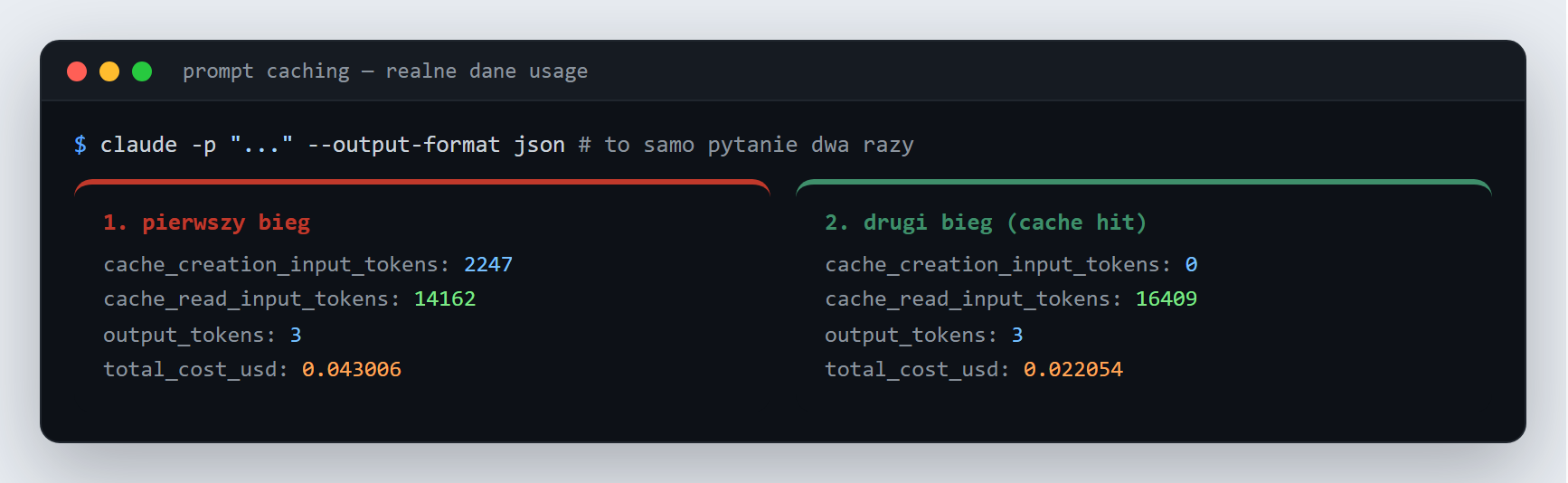
usage z naszego biegu: w pierwszym część kontekstu trafiła do cache (cache_creation), w drugim nic nie trzeba było tworzyć (cache_creation: 0), a kontekst odczytano z cache - i koszt spadł niemal o połowęLiczby mówią wszystko: pierwszy bieg kosztował około 0,043 USD, drugi - niemal identyczny - już tylko 0,022 USD. To samo pytanie, ta sama odpowiedź, a koszt o połowę niższy, bo stały kontekst został odczytany z cache zamiast liczony od zera. Pola cache_creation_input_tokens i cache_read_input_tokens (oraz total_cost_usd) znajdziesz zawsze w wyniku claude -p --output-format json. Jeden warunek powtórzenia: prompt w obu biegach musi być identyczny co do znaku, a drugi bieg paść w ciągu mniej więcej pięciu minut - tyle żyje domyślny cache.
Caching obniża cenę stałej części zapytania, ale jest jeszcze część zmienna: sama rozmowa i pliki, które agent czyta po drodze. Ta część rośnie z każdą turą i za nią płacisz normalnie. Dlatego drugi filar niskich kosztów to trzymanie w oknie tylko tego, co naprawdę potrzebne. Najpierw warto zrozumieć, co w tym oknie w ogóle siedzi.
Okno kontekstu to pamięć robocza modelu - ilość tekstu, którą Claude „widzi" naraz. Mieści się w nim więcej, niż się wydaje: instrukcja systemowa, opisy wszystkich narzędzi, pliki pamięci (CLAUDE.md), cała historia rozmowy oraz każdy plik, który agent po drodze przeczytał. Wszystko liczone w tokenach (token to kawałek słowa - fragment, na jaki modele dzielą tekst, z grubsza kilka znaków). Okno kontekstu jest pojemne, ale skończone: gdy się zapełnia, model zaczyna gubić najstarsze ustalenia, a każde zapytanie robi się droższe.
Zanim cokolwiek wyczyścisz, sprawdź, jak wygląda sytuacja. Komenda /context rysuje zużycie jako kolorową siatkę i rozbija je na kategorie: ile tokenów zajmuje prompt systemowy, ile opisy narzędzi, ile pliki pamięci, ile dostępne skille, ile sama rozmowa, a ile zostało wolnego miejsca.
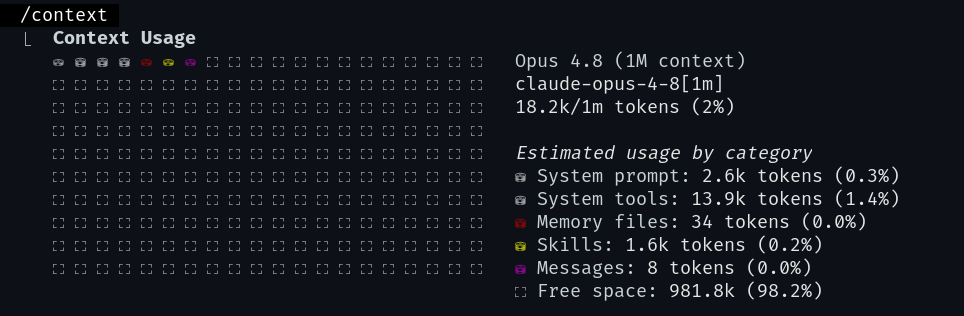
/context z prawdziwej sesji: siatka zużycia i rozbicie na kategorie. Tu rozmowa dopiero się zaczęła, więc wolne jest jeszcze 98% oknaTa jedna komenda odpowiada na najważniejsze pytanie: mam jeszcze zapas czy zbliżam się do ściany. Jeśli wolnego miejsca zostało niewiele, to sygnał, że pora coś z tym zrobić - i tu wchodzą dwie komendy, które najczęściej się myli.
To najczęstsze nieporozumienie wśród osób uczących się Claude Code. Obie komendy „robią miejsce" w oknie, ale w zupełnie inny sposób, a pomylenie ich kosztuje albo utratą potrzebnych ustaleń, albo niepotrzebnym balastem, za który płacisz w każdej kolejnej turze.
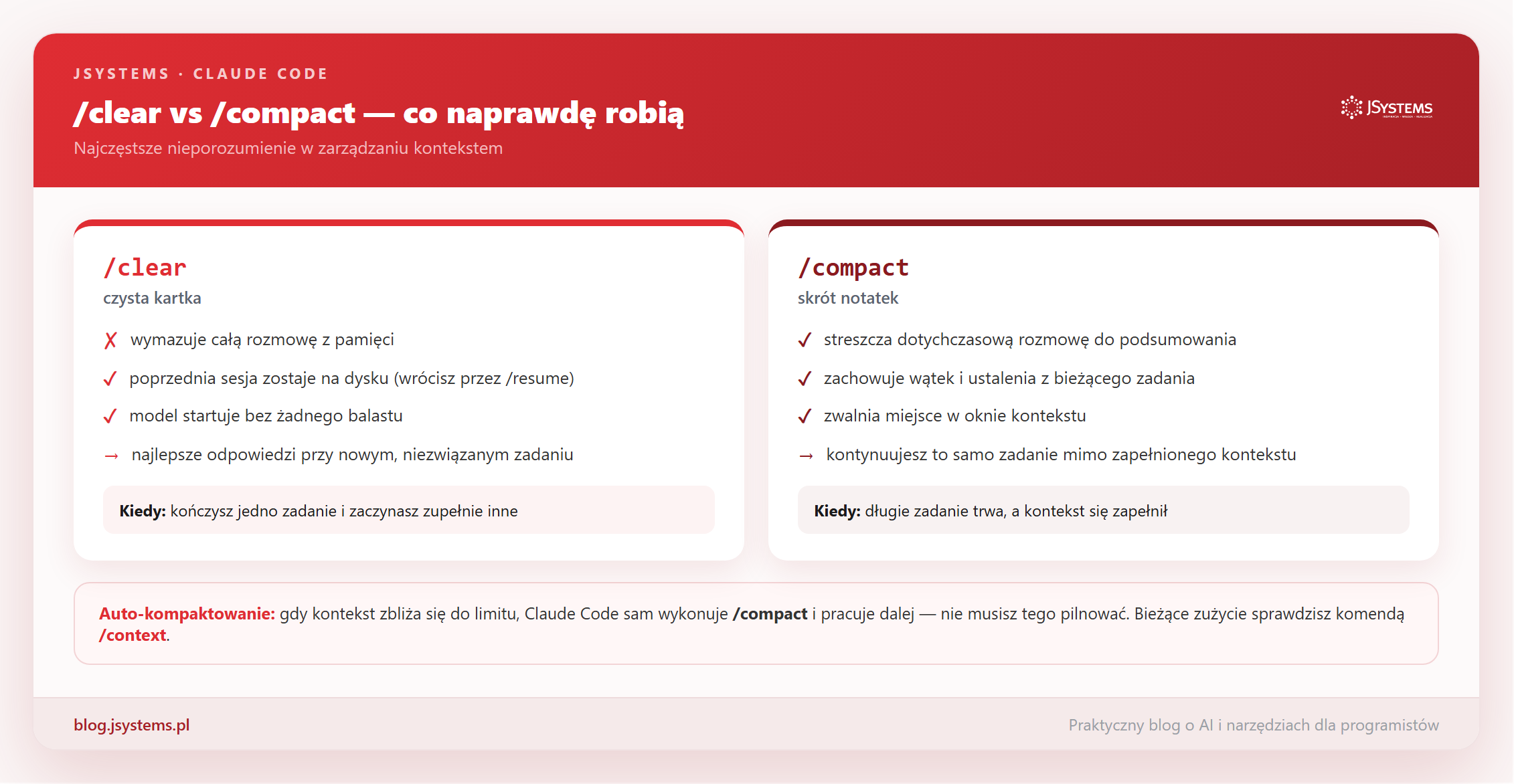
/clear wymazuje pamięć, /compact ją streszcza/clear to czysta kartka. Startuje nową sesję z pustym kontekstem - Claude zapomina całą dotychczasową rozmowę. Co ważne, poprzednia sesja nie znika bezpowrotnie: zostaje zapisana na dysku i wrócisz do niej w każdej chwili przez /resume. Po /clear model pracuje bez obciążenia, więc jego odpowiedzi są najtrafniejsze, a każda tura najtańsza - okno jest puste. Używasz go, gdy kończysz jedno zadanie i zaczynasz zupełnie inne.
/compact to skrót notatek. Zachowuje wątek bieżącego zadania, ale streszcza dotychczasową rozmowę do zwięzłego podsumowania, dzięki czemu zwalnia miejsce w oknie. Używasz go, gdy chcesz kontynuować to samo zadanie, ale rozmowa zrobiła się tak długa, że kontekst się zapełnił. Po kompaktowaniu Claude wciąż „wie", nad czym pracujecie, tylko w skróconej formie.
Wskazówka: jeśli masz wątpliwość, której komendy użyć, zadaj sobie jedno pytanie - czy to, co dotąd ustaliliśmy, jest mi jeszcze potrzebne? Jeśli tak, /compact. Jeśli zaczynasz coś niezwiązanego, /clear.
Nie musisz przy tym pilnować wszystkiego ręcznie. Claude Code ma auto-kompaktowanie: gdy kontekst zbliża się do limitu, agent sam wykonuje /compact, streszcza rozmowę i pracuje dalej, bez przerywania zadania. Ręcznie sięgasz po /compact wtedy, gdy chcesz świadomie zwolnić miejsce wcześniej - na przykład tuż przed dużym, wymagającym fragmentem. Auto-kompaktowanie to siatka bezpieczeństwa, ręczne kompaktowanie to świadome planowanie.
Skoro część kosztu jest zmienna, warto ją widzieć na bieżąco. Komenda /usage pokazuje koszt bieżącej sesji oraz zużycie planu (na kontach Pro/Max także limity tygodniowe). Dzięki temu wiesz, ile realnie wydajesz, zanim rachunek Cię zaskoczy.
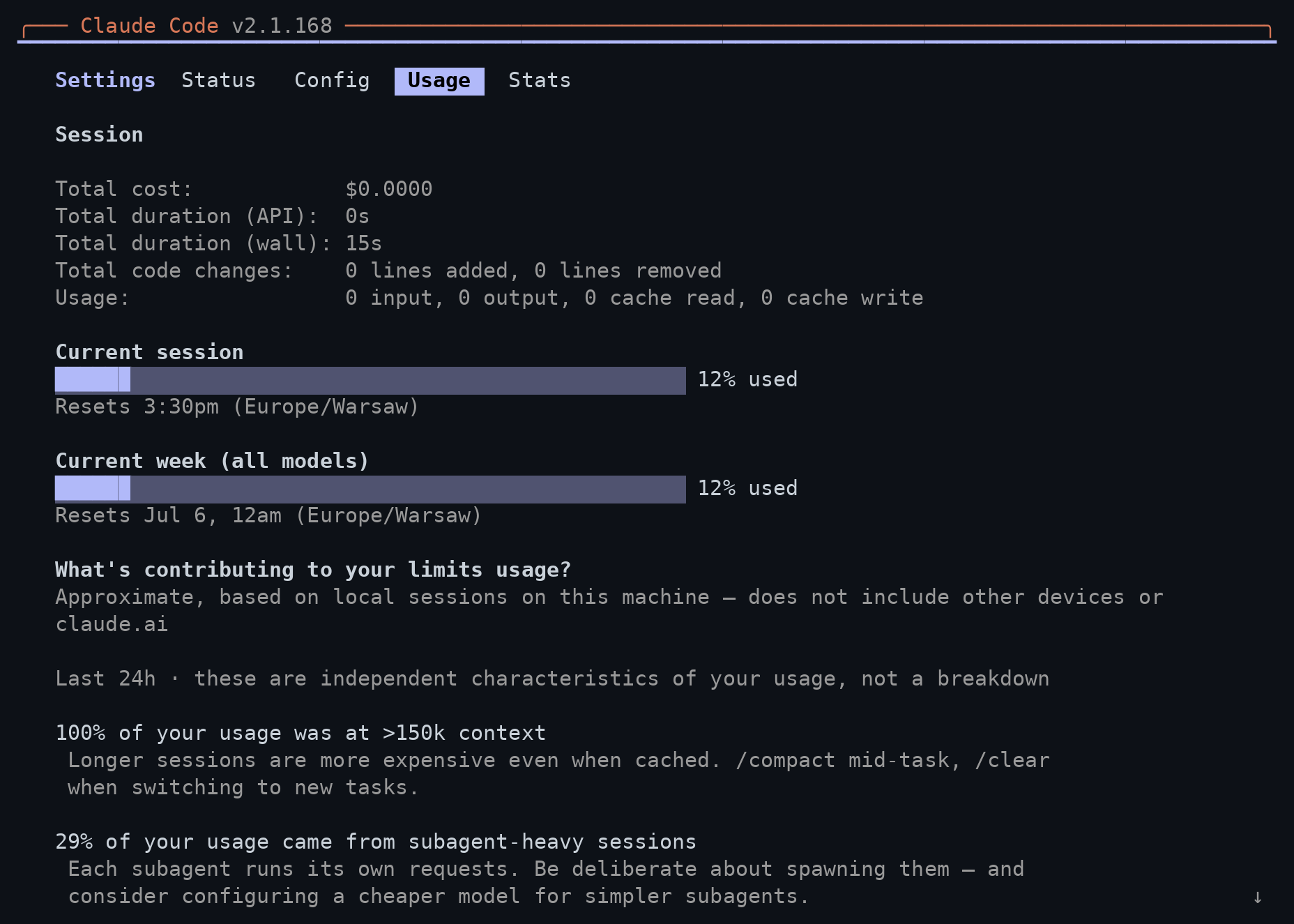
/usage (interfejs po angielsku): koszt bieżącej sesji, zużycie planu w sesji i w tygodniu oraz podpowiedzi o wzorcach użycia. Zwróć uwagę na wskazówkę na dole - sam Claude Code radzi tu /compact w trakcie zadania i /clear przy przejściu do nowegoDruga dźwignia to dobór modelu do zadania. Do rutynowych, mechanicznych zmian lżejszy i szybszy model najczęściej wystarcza i kosztuje wyraźnie mniej; mocny zostaw na trudne rzeczy - projektowanie, zawiłe debugowanie, pracę na dużym kontekście. Model przełączysz w trakcie sesji komendą /model, a to, który wybrać (Opus, Sonnet, Haiku czy tryb szybki), rozłożyliśmy w osobnym artykule o wyborze modelu w Claude Code.
Wskazówka: nie optymalizuj na siłę. Caching i tak załatwia większość oszczędności automatycznie, a sztuczne skracanie kontekstu potrafi obniżyć jakość odpowiedzi. Lepiej trzymać w oknie to, co naprawdę potrzebne (i kompaktować, gdy puchnie), niż w kółko walczyć o każdy token.
Kontekst zużywa się też przy zwykłej, produktywnej pracy: każdy przeczytany plik i każda odpowiedź coś zajmują. Poniżej prawdziwa sesja, w której Claude przeczytał jeden plik projektu i wyjaśnił jego działanie:
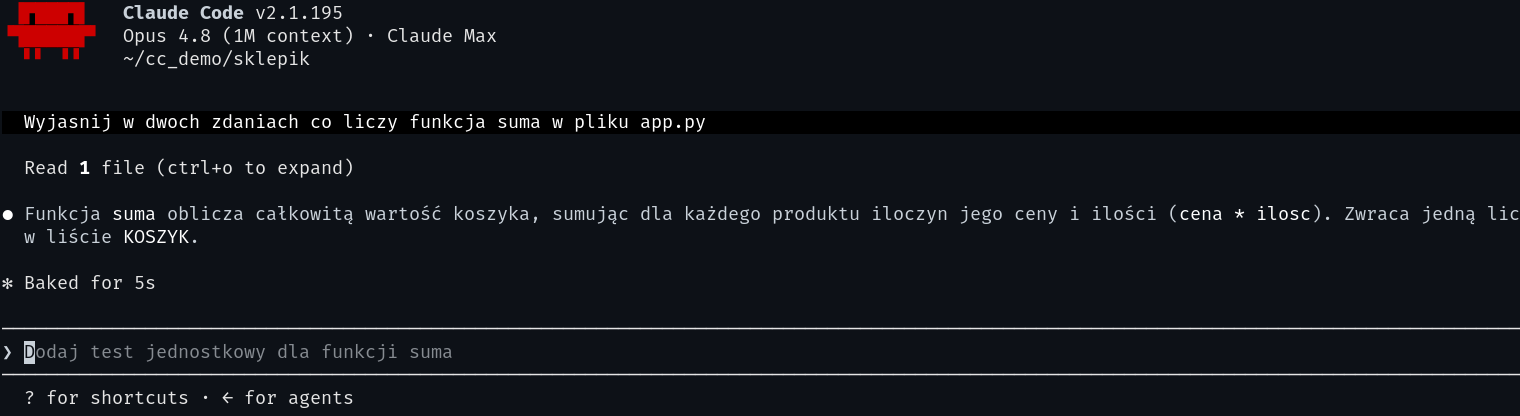
Żeby długa sesja została tania i nie zamieniła się w walkę z zanikającą pamięcią, trzymaj się kilku zasad:
| Nawyk | Dlaczego pomaga |
|---|---|
| Jedna sesja = jedno zadanie | Przy zmianie tematu zrób /clear. Mieszanie zadań w jednym oknie to najszybszy sposób na bałagan w kontekście i wyższy koszt każdej tury. |
Kompaktuj, zanim okno się zapcha (/compact) | Streszczenie długiej rozmowy zmniejsza kontekst, a więc i koszt kolejnych tur - bez utraty wątku. |
Trwałe ustalenia zapisuj do CLAUDE.md | Plik pamięci przetrwa kompaktowanie i wraca w każdej sesji. Luźna wzmianka w rozmowie może zniknąć przy streszczaniu. |
Wracaj przez /resume, nie od zera | Zamiast odtwarzać wczorajszy kontekst ręcznie, wznów zapisaną sesję - wraca z całą pamięcią. |
Sprawdzaj koszt (/usage) i dobór modelu | Widzisz, ile wydajesz, i możesz zejść na lżejszy model tam, gdzie mocny nie jest potrzebny. |
Najważniejszy wniosek jest uspokajający: długie, produktywne sesje są tańsze, niż się wydaje. Mechanizm, który najbardziej martwi początkujących - „skoro kontekst rośnie, to koszty muszą galopować" - jest w dużej mierze rozbrojony przez caching: stały kontekst płacisz raz, a potem korzystasz z niego po taniości. Reszta jest w Twoich rękach i sprowadza się do prostych nawyków: pilnuj okna kontekstu (/context), streszczaj albo czyść, gdy trzeba (/compact, /clear), trwałe rzeczy trzymaj w CLAUDE.md i dobieraj model do wagi zadania. Resztą zajmuje się Claude Code pod spodem - a Ty pracujesz spokojnie, nie licząc nerwowo każdego zapytania.

Prompt caching i koszty, zarządzanie kontekstem, wybór modelu, tryb headless i systemy multi-agent - wszystko na żywym kodzie podczas trzydniowego szkolenia. Prowadzi Łukasz Matuszewski. Szkolenie ma termin gwarantowany - odbędzie się niezależnie od liczby zgłoszeń.
Sprawdź szkolenie Claude Code -->
Komentarze (0)
Brak komentarzy...