Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!

Ollama to najprostszy sposób, żeby uruchomić duży model językowy (LLM) na własnym komputerze lub serwerze - bez chmury, bez kart kredytowych i bez wysyłania firmowych danych na zewnątrz. Jeden plik instalatora, jedna komenda i masz lokalny odpowiednik ChatGPT, który działa nawet bez internetu. W tym przewodniku przejdziemy od instalacji, przez wybór i zarządzanie modelami, rozmowę przez API (z gotowym kodem w Pythonie, JavaScript i przez curl), aż po realne scenariusze biznesowe - i kiedy lokalny model naprawdę się opłaca, a kiedy lepiej zostać w chmurze.
Wszystkie zrzuty ekranu i odpowiedzi modeli w tym artykule pochodzą z prawdziwej instalacji Ollamy uruchomionej na naszym serwerze (Debian 12, 2 rdzenie CPU, 6 GB RAM) - nic nie jest zmyślone ani podrasowane w grafice.
Czego się nauczysz:
pull, run, show, ps, własny Modelfilerequests, biblioteka ollama), endpoint zgodny z OpenAI, streamingOllama to lekki silnik (runtime) do uruchamiania modeli LLM lokalnie. Bierze na siebie całą trudną robotę: pobiera model z rejestru, ładuje jego wagi do pamięci, zarządza kontekstem rozmowy i wystawia proste API HTTP na porcie 11434. Ty rozmawiasz z modelem z terminala albo z poziomu swojej aplikacji - dokładnie tak samo jak z API OpenAI, tyle że wszystko dzieje się na Twoim sprzęcie.
Pod spodem Ollama korzysta z llama.cpp i formatu GGUF (skwantyzowane wagi modelu), dzięki czemu modele, które normalnie wymagają potężnych kart graficznych, dają się uruchomić na zwykłym laptopie z 8-16 GB RAM. To właśnie ta dostępność zrobiła z Ollamy standard dla lokalnego AI.
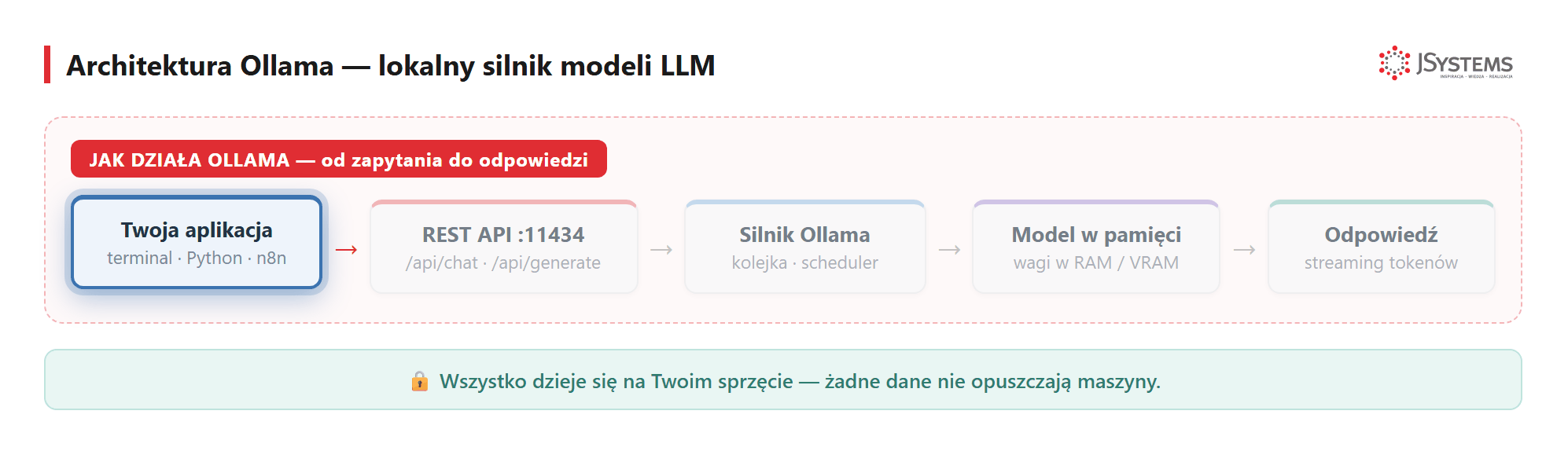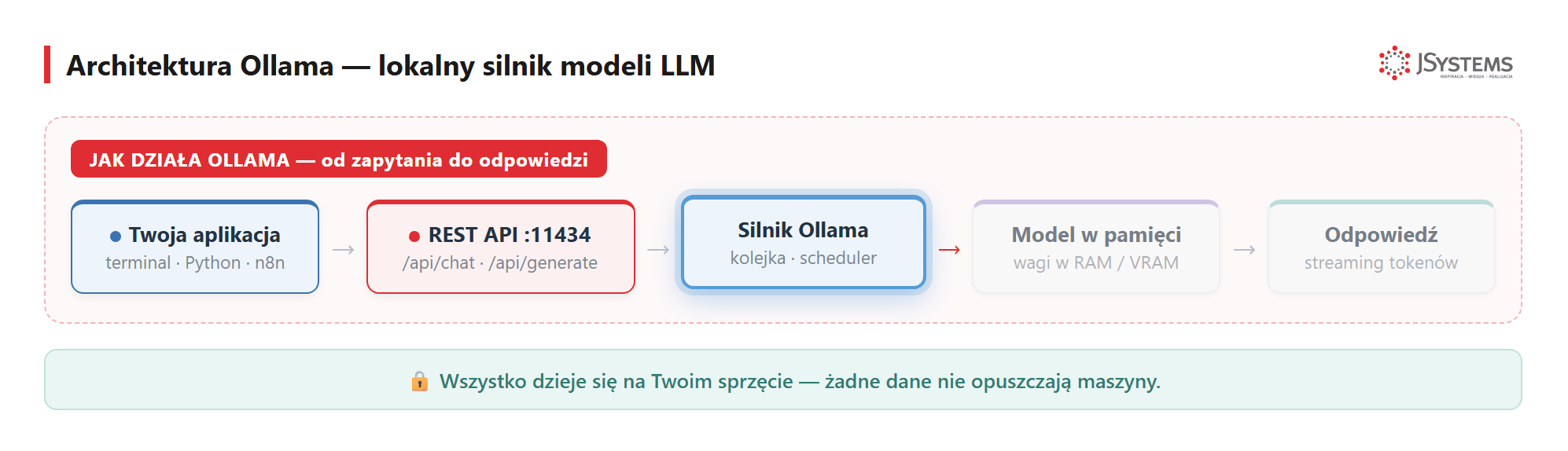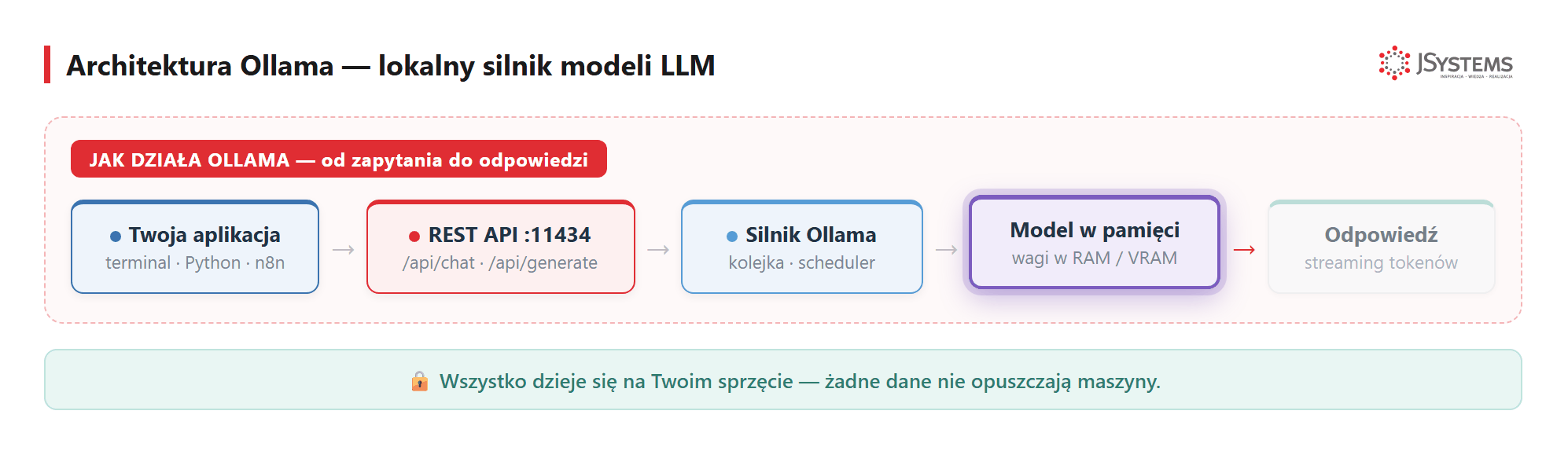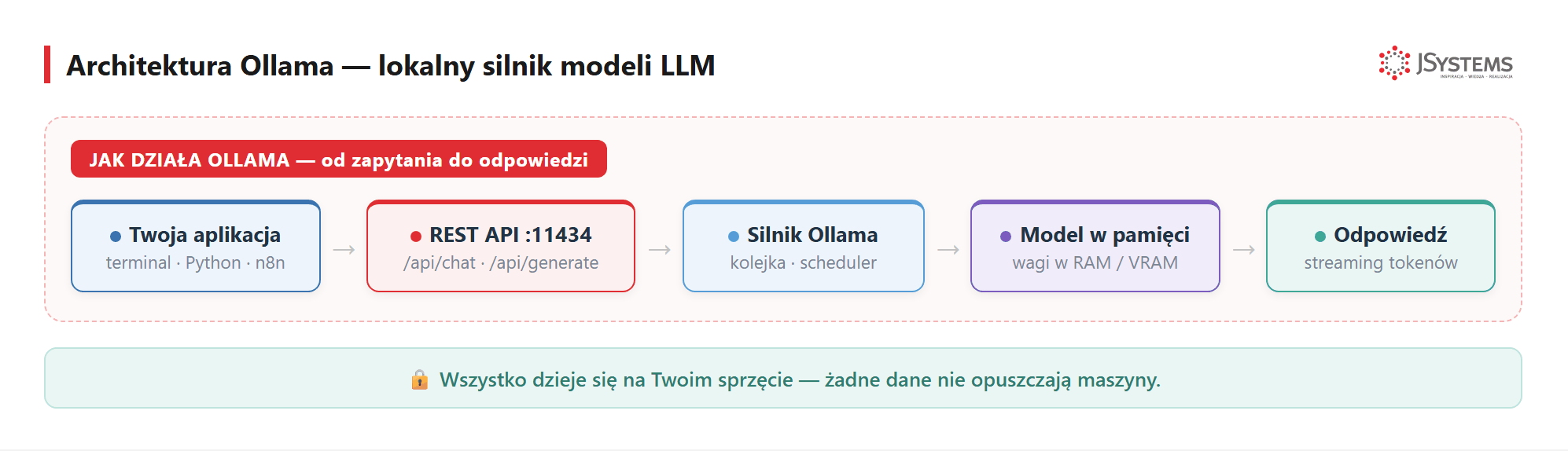
:11434), silnik ładuje model do pamięci i streamuje odpowiedź token po tokenie. Żadne dane nie opuszczają maszyny.Zanim cokolwiek zainstalujesz - najważniejsze pytanie biznesowe. Lokalny model to nie zawsze najlepszy wybór. Oto uczciwe porównanie:

Wybierz Ollamę (lokalnie), gdy: przetwarzasz dane wrażliwe lub objęte tajemnicą (RODO, dane medyczne, kod klienta, dokumenty prawne), masz duży wolumen zapytań i koszt tokenów w chmurze rośnie, potrzebujesz działania offline / w zamkniętej sieci, albo chcesz pełnej kontroli i powtarzalności.
Zostań w chmurze, gdy: potrzebujesz absolutnie najwyższej jakości (GPT-5, Claude), masz mały, nieregularny ruch (nie opłaca się utrzymywać sprzętu), albo nie chcesz w ogóle zarządzać infrastrukturą. W praktyce wiele firm robi hybrydę: dane wrażliwe i masowe zadania lokalnie, a najtrudniejsze pytania kierują do chmury.
Linux (i nasz serwer w tym artykule) - jedna komenda instaluje binarkę i uruchamia usługę:
curl -fsSL https://ollama.com/install.sh | shmacOS i Windows - pobierasz instalator ze strony ollama.com/download i klikasz „dalej". Instalator daje Ci od razu dwie rzeczy: aplikację okienkową (wygodny czat, jak ChatGPT) oraz komendę ollama w terminalu dla bardziej zaawansowanych zastosowań. Ollama działa w tle jako usługa.
Pobierz instalator Ollama (Windows / macOS)
Sprawdźmy, że wszystko działa:
ollama --version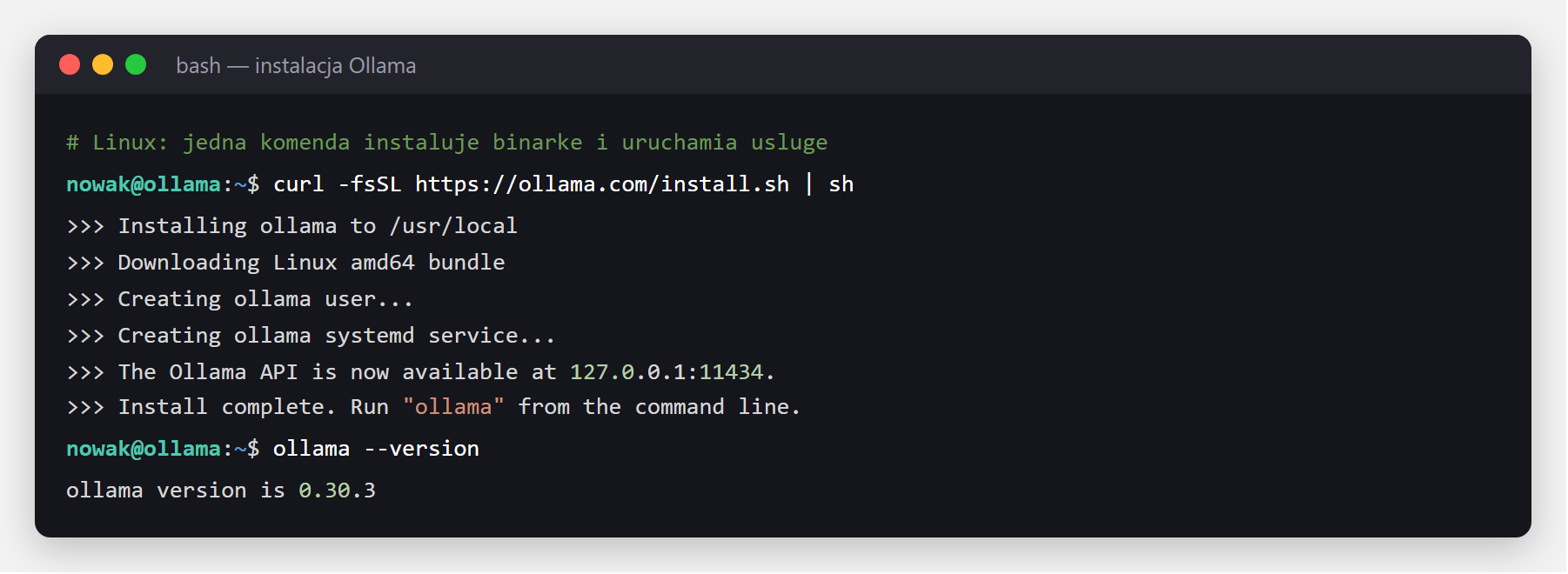
ollama --version potwierdza działającą wersję. Od tej chwili masz lokalny silnik LLM gotowy do pracy.Wymagania sprzętowe
Ollama działa na CPU (jak na naszym serwerze) - wolniej, ale działa. Prawdziwe przyspieszenie daje dopiero dedykowana karta graficzna z własną pamięcią VRAM - i tu ważne rozróżnienie: chodzi o osobną kartę (np. NVIDIA GeForce RTX 3060 / 4060 z 8-12 GB VRAM albo mocniejszą), a nie o zintegrowaną grafikę, którą ma każdy laptop (Intel UHD / AMD Radeon Graphics) - ta dzieli pamięć z RAM i do modeli LLM się nie nadaje. Bardzo dobrze radzi sobie też Apple Silicon (M1-M4), bo pamięć jest tam współdzielona z układem graficznym. Reguła doboru: tyle GB wolnego VRAM (lub RAM przy liczeniu na CPU), ile model ma miliardów parametrów - model 7B w kwantyzacji Q4 to ok. 5 GB, więc zmieści się na karcie z 8 GB VRAM.
Zacznijmy od najłatwiejszej drogi - aplikacji okienkowej, którą dostajesz razem z instalatorem na Windows i macOS. To zwykłe okno czatu, jak ChatGPT, tyle że model działa na Twoim komputerze. Zero terminala, zero kodu - po prostu piszesz pytanie i dostajesz odpowiedź.
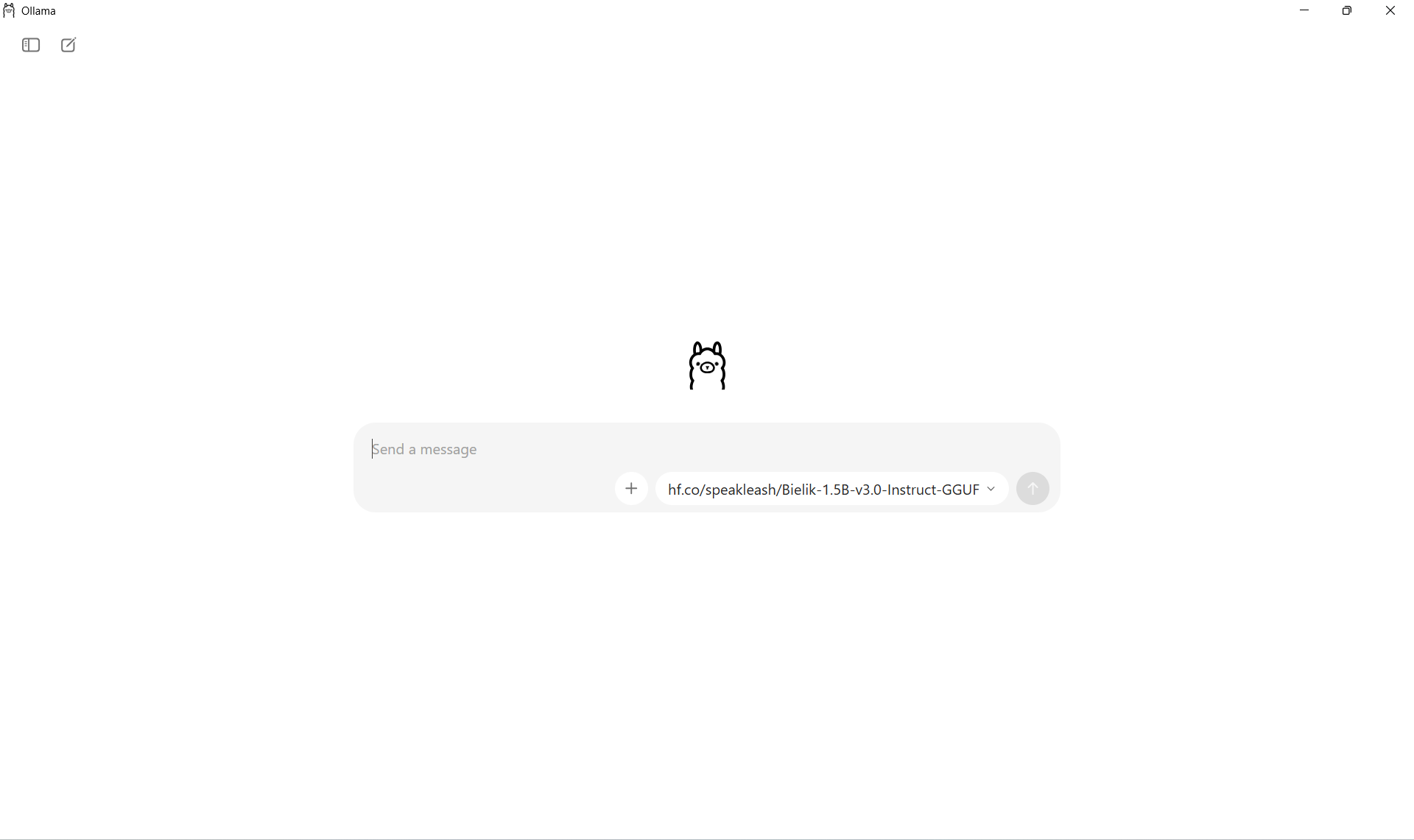
Model wybierasz jednym kliknięciem z listy pobranych modeli - bez żadnej konfiguracji. Możesz mieć obok siebie mały, szybki model do prostych pytań i większy do trudniejszych zadań:
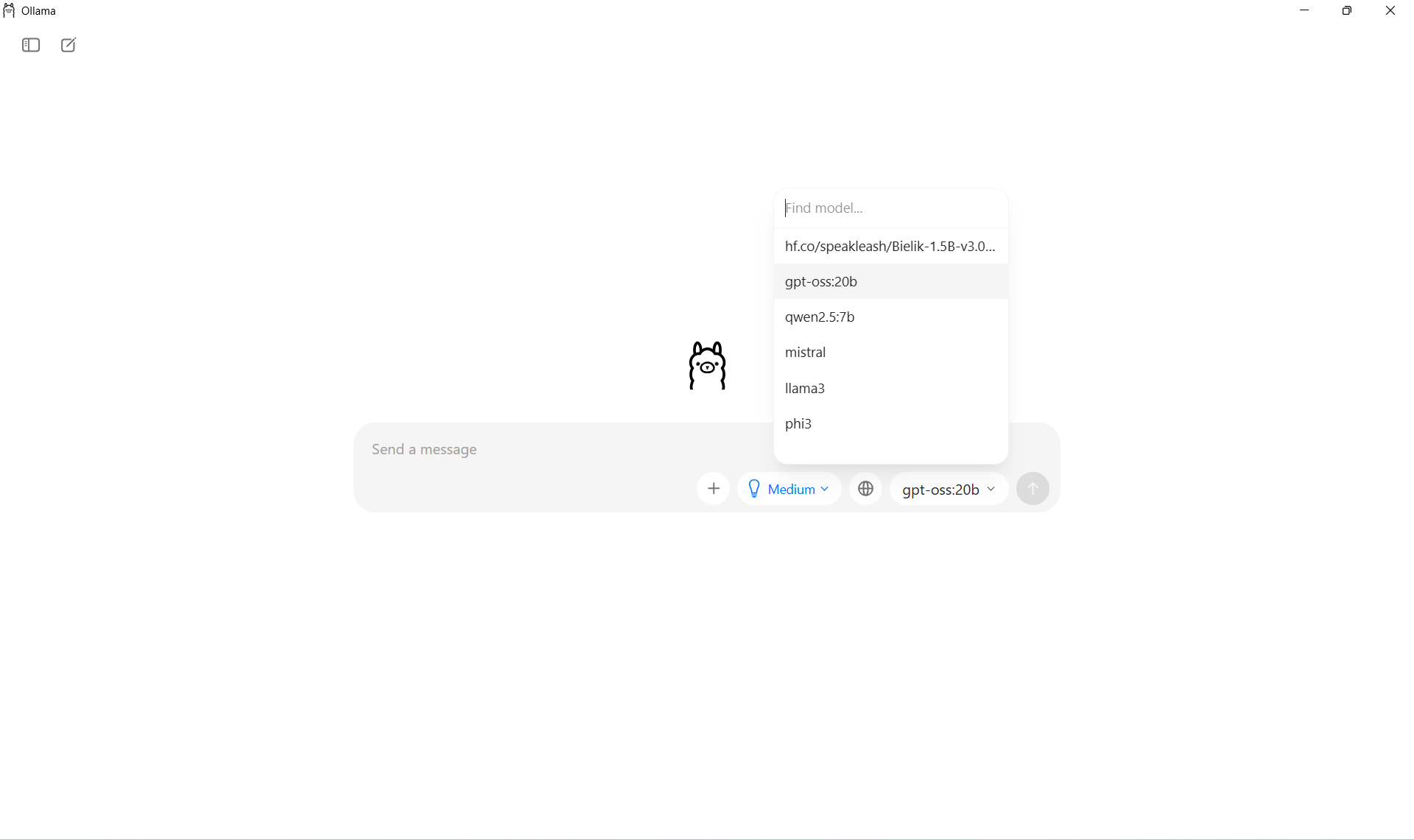
A tak wygląda rozmowa. Zadajemy ogólne pytanie - np. o wyjaśnienie pojęcia albo napisanie krótkiego tekstu - i model odpowiada na bieżąco:
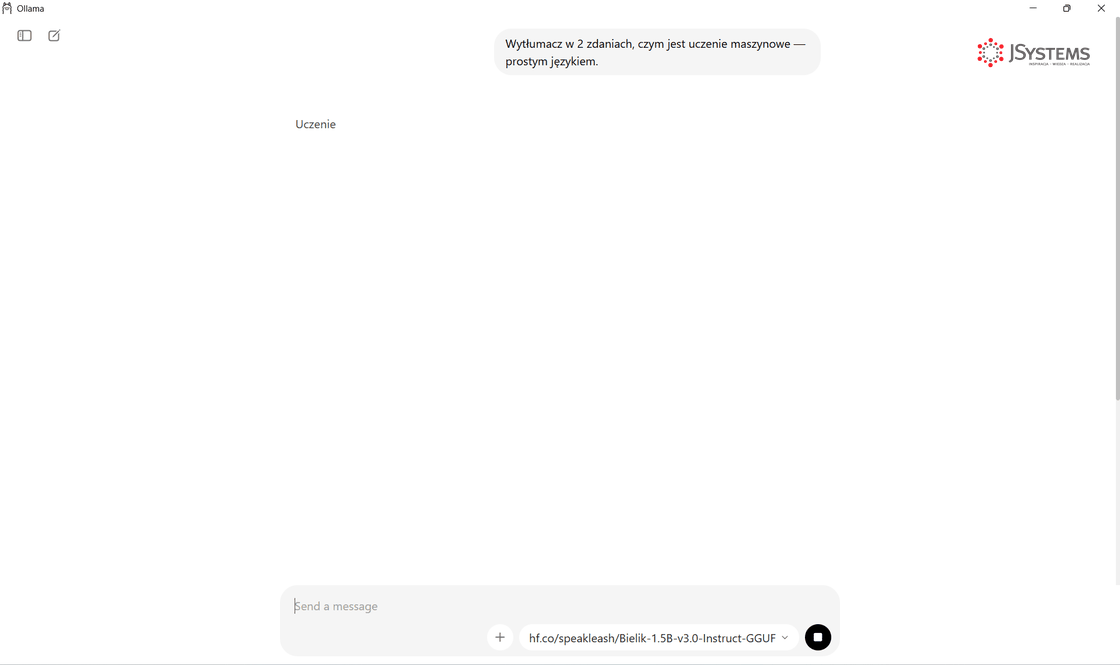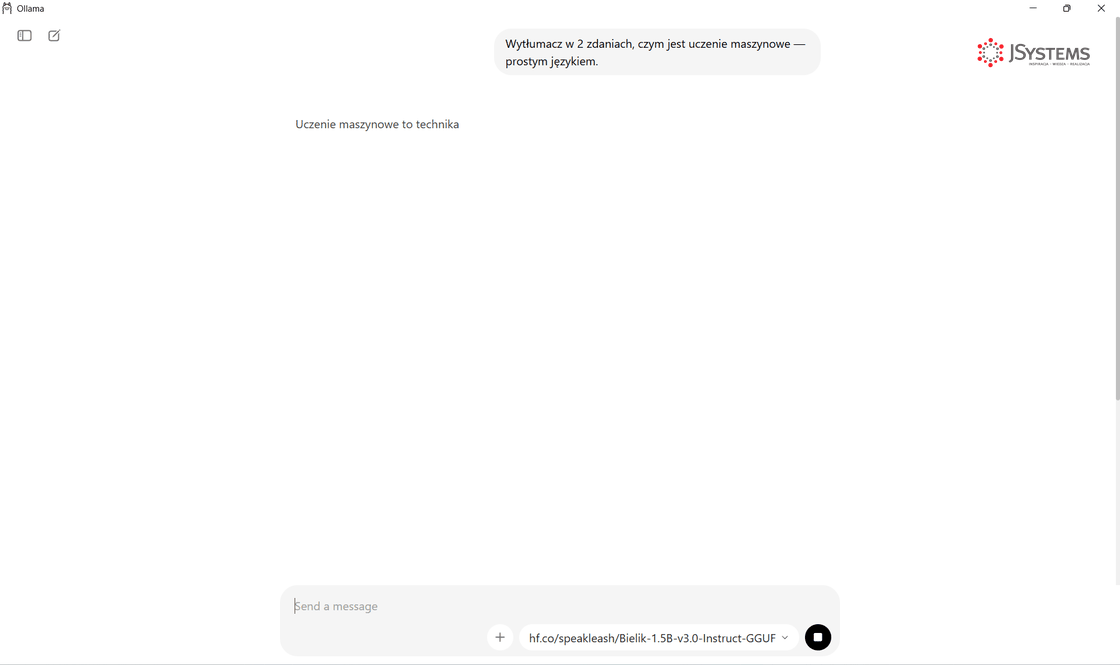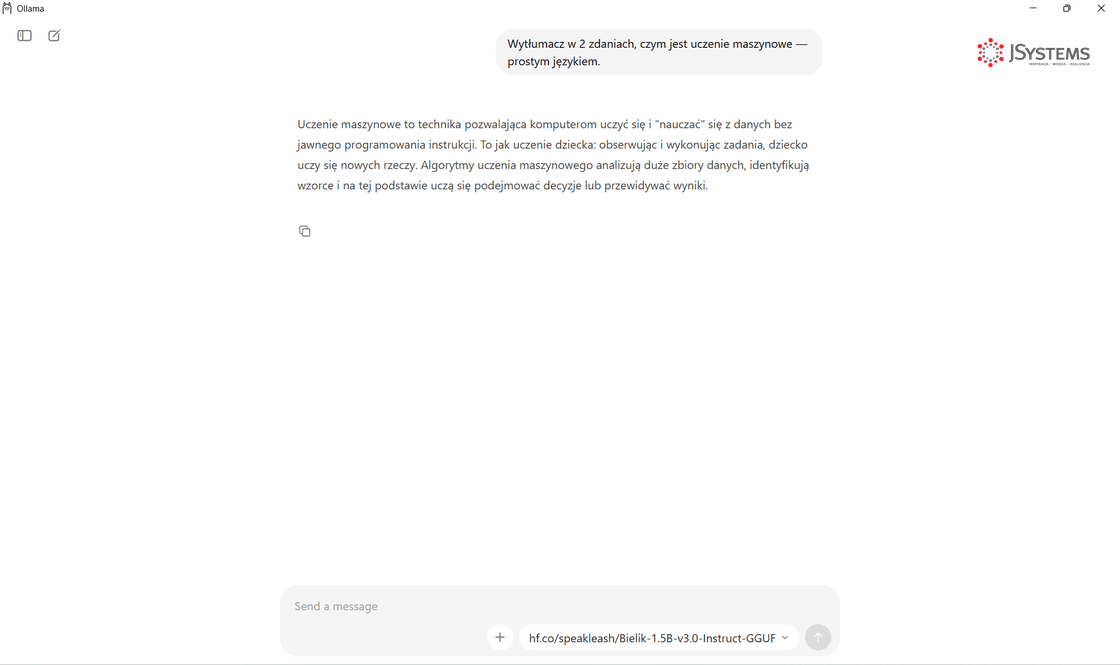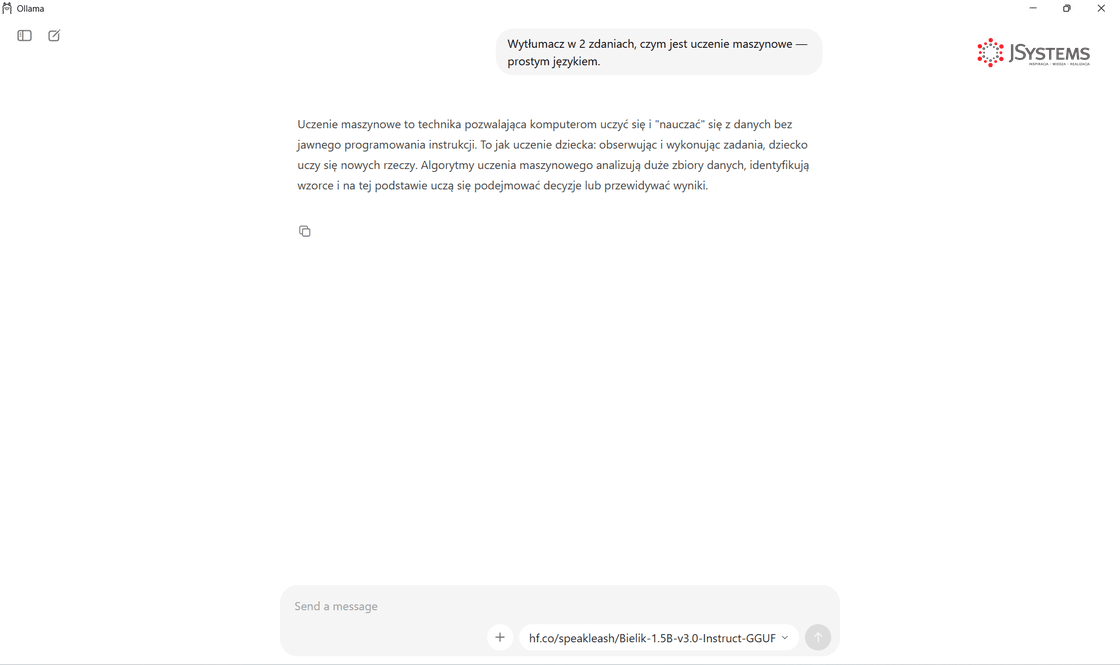
Na Linuksie to samo robi się jedną komendą w terminalu - efekt identyczny, inna forma. Bielika nie ma w rejestrze Ollamy, więc podajemy pełną nazwę repozytorium z Hugging Face:
ollama run hf.co/speakleash/Bielik-1.5B-v3.0-Instruct-GGUFollama run hf.co/speakleash/Bielik-1.5B-v3.0-Instruct-GGUF "..." i odpowiedź Bielika naturalną polszczyzną. Bez GUI, bez konfiguracji — jeden wiersz w konsoli.Wskazówka
Aplikacja okienkowa to świetny start i w zupełności wystarcza do codziennej pracy „z ręki". Gdy zechcesz wpiąć model we własne skrypty, automatyzacje czy aplikacje - przechodzisz na terminal i API, które opisujemy niżej. Obie drogi korzystają z tego samego, lokalnie działającego silnika.
Terminal daje pełnię możliwości - i to jego użyjemy w dalszej części (zarządzanie modelami, własne asystenty, API, automatyzacje). Modele pobierasz komendą ollama pull z oficjalnego rejestru (ollama.com/library). Zacznijmy od małego, szybkiego modelu:
ollama pull llama3.2:1b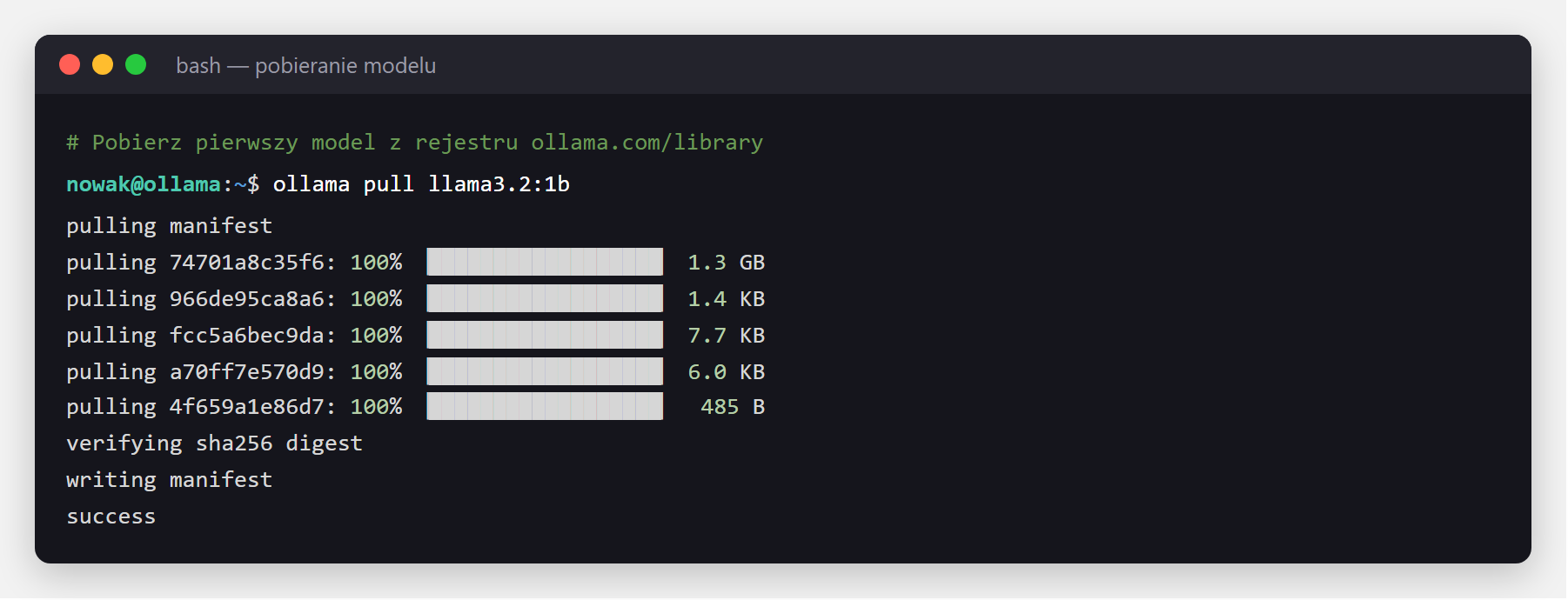
success = model gotowy do użycia.Listę lokalnych modeli zobaczysz komendą ollama list:
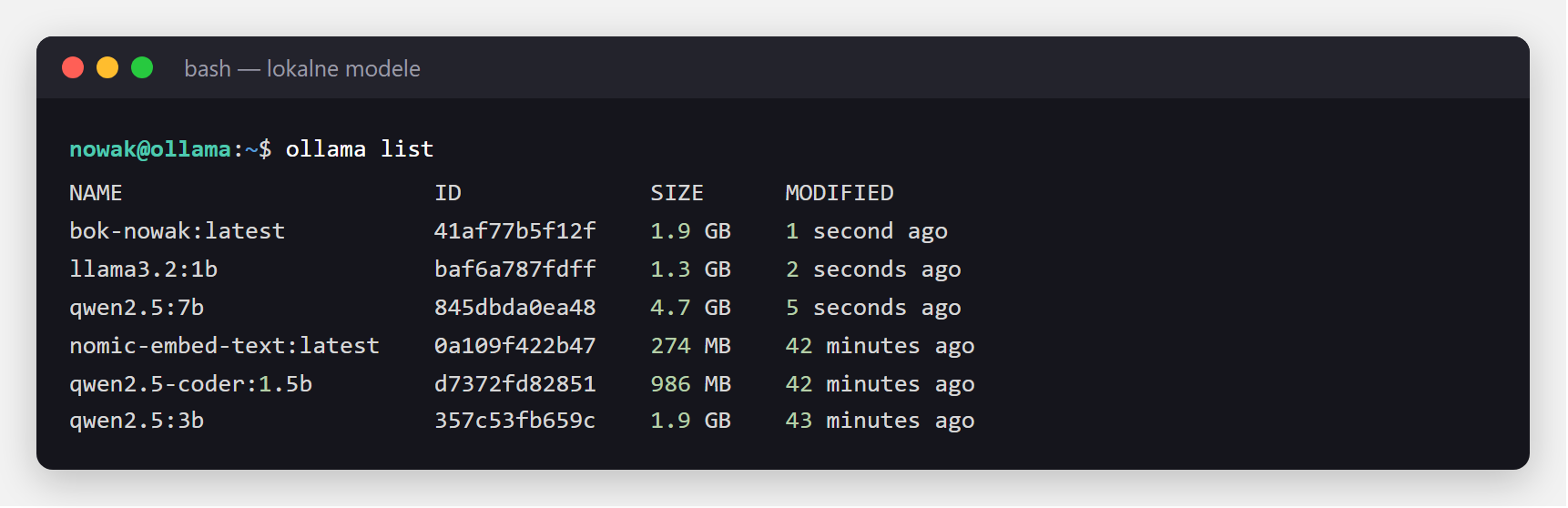
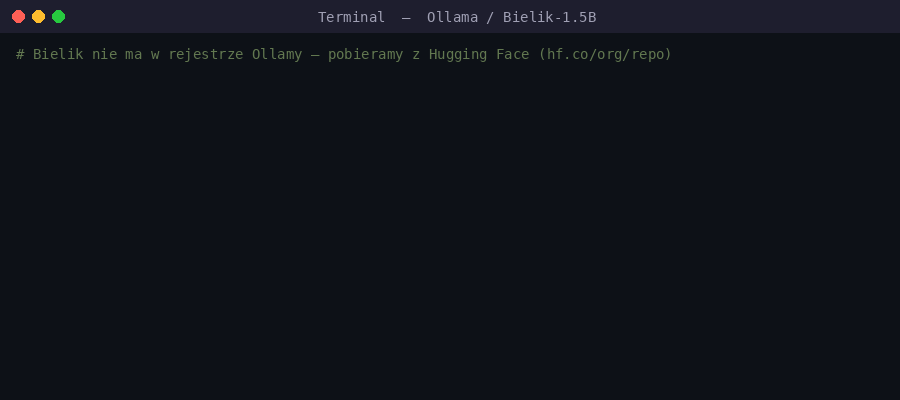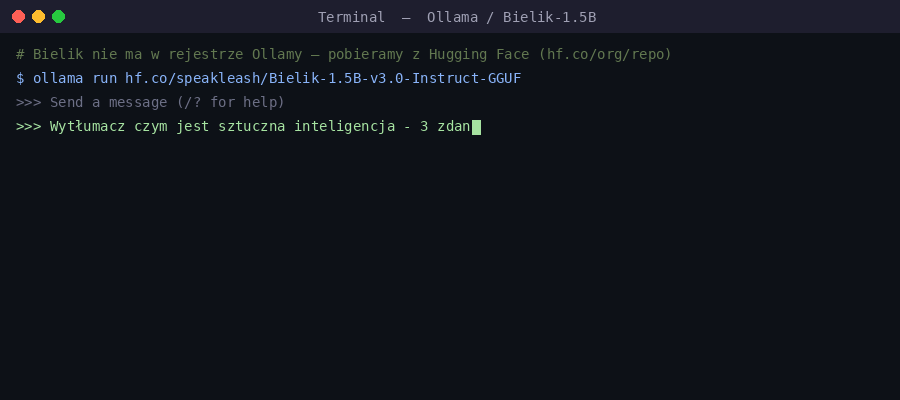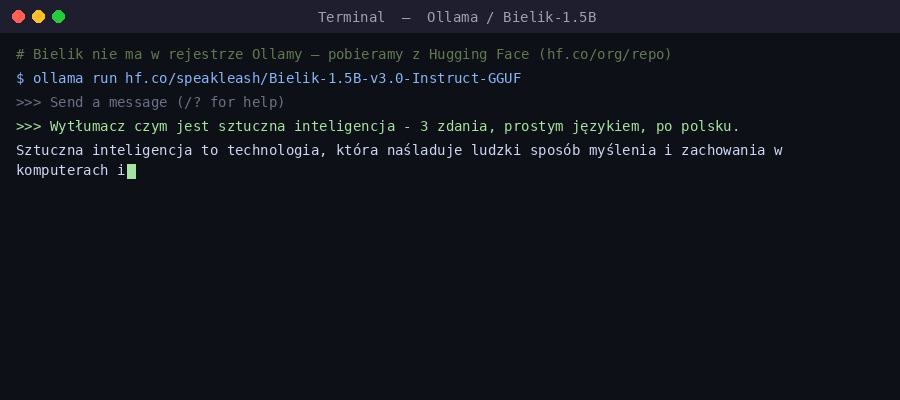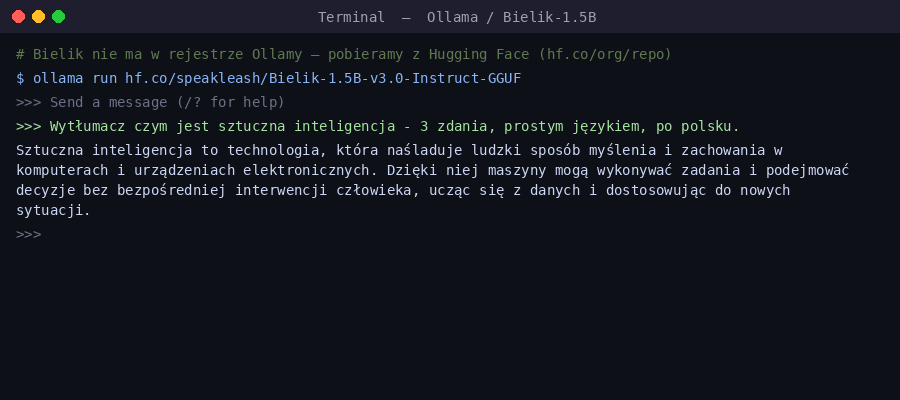
nomic-embed-text (274 MB) po qwen2.5:3b (1.9 GB). Kolumna SIZE to miejsce na dysku.Teraz najprzyjemniejsza część - rozmowa. ollama run uruchamia interaktywny czat w terminalu (wpisz /bye, żeby wyjść). Można też zadać jedno pytanie od razu. Użyjemy tu Bielika - polskiego modelu open source od SpeakLeash, który radzi sobie z polszczyzną wyraźnie lepiej niż modele tej samej wielkości trenowane głównie po angielsku:
ollama run hf.co/speakleash/Bielik-1.5B-v3.0-Instruct-GGUF "Wytłumacz czym jest sztuczna inteligencja - 3 zdania, prostym językiem, po polsku."Skąd ta długa nazwa? Bielik nie znajduje się w oficjalnym rejestrze Ollamy (ollama.com/library) — jest dostępny tylko na Hugging Face. Ollama pozwala jednak uruchomić bezpośrednio każde repozytorium HF w formacie GGUF, podając ścieżkę hf.co/użytkownik/repozytorium. Po pobraniu model pojawia się w ollama list właśnie z tą pełną nazwą — tak po prostu wygląda jego identyfikator.
Tak samo jak w aplikacji okienkowej, w terminalu odpowiedź pojawia się na żywo - token po tokenie:
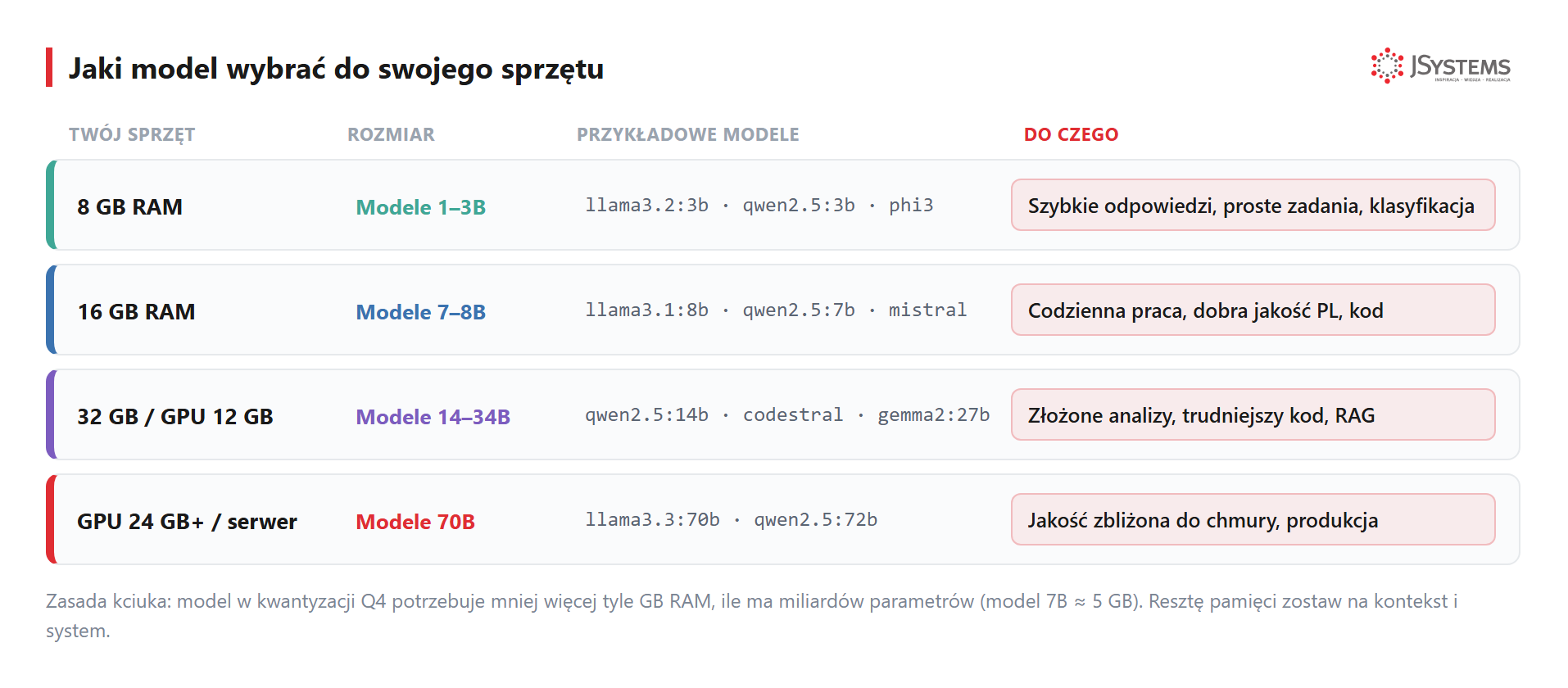
To najczęstsze pytanie początkujących. Pierwsze ograniczenie to Twój sprzęt (RAM/VRAM), drugie - rodzaj zadania. Mapa poniżej rozwiązuje pierwsze:
Zanim ją przeczytasz, wyjaśnijmy oznaczenie, które wraca w nazwach modeli: liczbę parametrów, zapisywaną jako 1.5B, 8B czy 70B. Litera B pochodzi od angielskiego billion (miliard), więc model 7B ma 7 miliardów parametrów - to liczby (wagi), których model nauczył się podczas treningu i na których opiera każdą odpowiedź. Zasada jest prosta: więcej parametrów = zwykle mądrzejszy model (lepiej rozumuje, rzadziej się myli), ale zarazem większy i wolniejszy - zajmuje więcej pamięci i dłużej generuje odpowiedź. Stąd praktyczny kompromis:
Ile to pamięci? Każdy parametr trzeba gdzieś zapisać. W pełnej precyzji (format FP16, czyli 2 bajty na parametr) model 7B zajmowałby 7 mld × 2 bajty = około 14 GB. Dlatego niemal zawsze pobieramy modele skwantyzowane: kwantyzacja zapisuje każdy parametr w mniejszej liczbie bitów (popularny wariant Q4 to około 4 bity zamiast 16), więc te same 7 mld parametrów waży już tylko ~3,5-4 GB, a z buforem na kontekst rozmowy zajmuje w praktyce około 5-6 GB - kosztem minimalnej utraty jakości. Tę liczbę warto znać, bo to ona decyduje, czy model zmieści się w pamięci karty graficznej (wracamy do tego niżej przy GPU).
O rozmiarze decyduje jedno: ile bitów zajmuje jeden parametr. W kwantyzacji Q4 to ~4 bity, czyli ~0,5 GB pamięci na każdy miliard parametrów (z buforem na kontekst licz ~0,7 GB na miliard) - stąd 7B to ~5 GB, a 14B ~9 GB. Pełna precyzja to 16 bitów na parametr, czyli 2 GB na miliard, więc 4× więcej - to samo 7B zajmowałoby wtedy ~14 GB. Pamięć dzielisz jeszcze z systemem, więc zostaw zapas - bezpieczny wybór modelu jest mniejszy niż sam rozmiar pliku.
Jeśli zależy Ci na pełnej prędkości - model musi zmieścić się w VRAM karty graficznej, nie tylko w RAM (o tym w sekcji o GPU).
A oto przegląd najciekawszych rodzin modeli dostępnych w Ollamie i tego, do czego się nadają:
| Rodzina | Twórca | Do czego |
|---|---|---|
| Bielik (SpeakLeash) | SpeakLeash / PLLuM | Polski model open source - najlepsza polszczyzna, także w małych rozmiarach (1.5B, 4.5B, 11B). Idealny do obsługi klienta i treści PO POLSKU. Pobierasz z Hugging Face. |
| llama3.2 / llama3.1 / llama3.3 | Meta | Uniwersalne, świetny ekosystem. 1B-3B na słabszy sprzęt, 8B do codziennej pracy, 70B (3.3) jakością goni chmurę. |
| qwen2.5 | Alibaba | Mocny i wielojęzyczny, wersje 0.5B-72B. Bardzo dobry w instrukcjach i kodzie; po polsku przyzwoity, ale potrafi się pomylić w małych rozmiarach. |
| qwen2.5-coder / codestral | Alibaba / Mistral | Wyspecjalizowane w kodzie: generowanie, refactor, uzupełnianie. Świetne jako asystent w edytorze. |
| gemma2 / gemma3 | Lekkie i szybkie, dobre do streszczeń i klasyfikacji. 2B mieści się wszędzie. | |
| phi3 / phi4 | Microsoft | Małe modele „reasoningowe" - zaskakująco mądre jak na rozmiar, dobre do logiki i matematyki. |
| mistral / mixtral | Mistral AI | Europejskie modele, mocne w zadaniach ogólnych i RAG. Mixtral to architektura MoE (Mixture of Experts). |
| deepseek-r1 | DeepSeek | Model „myślący" (reasoning) - pokazuje tok rozumowania. Do trudnych analiz i zadań krok-po-kroku. |
| llava / llama3.2-vision | - | Multimodalne (widzą obrazy): opis zdjęć, odczyt paragonów, analiza zrzutów ekranu. |
| nomic-embed-text / mxbai-embed | Nomic / MixedBread | Nie do rozmowy - generują embeddingi (wektory) do wyszukiwania semantycznego i lokalnego RAG. |
Szczegóły każdego modelu (architektura, liczba parametrów, długość kontekstu, kwantyzacja, licencja) sprawdzisz komendą ollama show:
ollama show qwen2.5:3b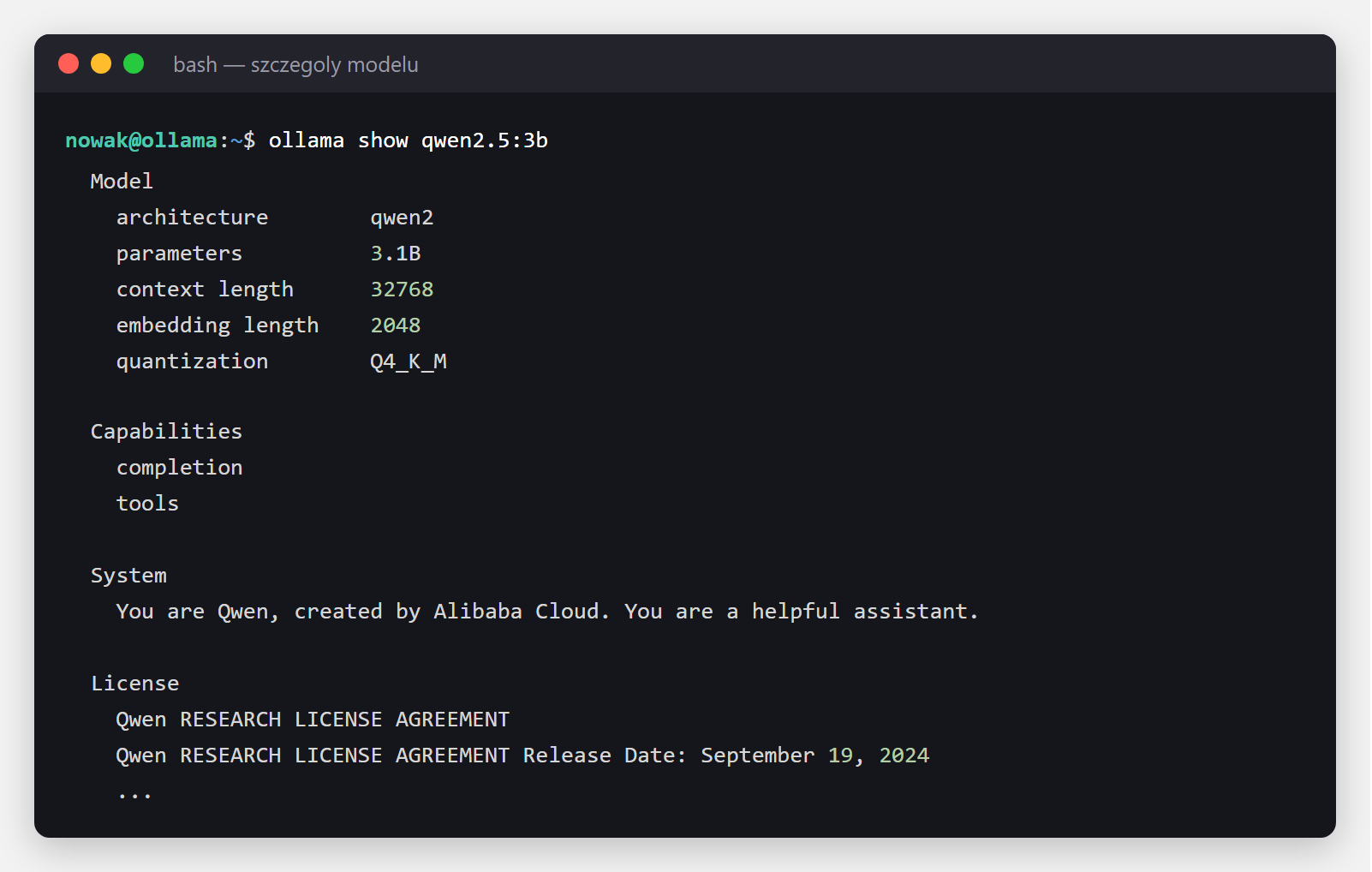
Na samym procesorze (CPU) Ollama działa, ale wolno - przy większych modelach odpowiedź potrafi się sączyć po kilka słów na sekundę. Karta graficzna (GPU) przyspiesza to wielokrotnie, bo liczenie modeli językowych sprowadza się do mnożenia ogromnych macierzy, w czym układy graficzne są bezkonkurencyjne. Dobra wiadomość: Ollama wykrywa GPU automatycznie - nie ma osobnego „trybu GPU" do włączenia. Wystarczy mieć poprawne sterowniki, a silnik sam załaduje na kartę tyle modelu, ile się zmieści.
NVIDIA (CUDA) - Windows i Linux. To najczęstszy i najlepiej wspierany wariant. Potrzebujesz wyłącznie aktualnego sterownika GeForce/Studio. Nie musisz instalować osobno pakietu CUDA Toolkit - Ollama nosi własne biblioteki CUDA w paczce instalacyjnej. Po zainstalowaniu sterownika i Ollamy nic więcej nie konfigurujesz; przy pierwszym uruchomieniu modelu silnik sam wykryje kartę.
Czy GPU faktycznie liczy, sprawdzisz dwiema komendami. Pierwsza pokazuje sterownik NVIDIA i bieżące obciążenie karty:
nvidia-smi+-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 555.99 Driver Version: 555.99 CUDA Version: 12.5 | |-----------------------------------------+------------------------+----------------------+ | GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 4070 WDDM | 00000000:01:00.0 On | N/A | | 45% 61C P2 112W / 200W | 6038MiB / 12282MiB | 82% Default | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | |=========================================================================================| | 0 N/A N/A 9120 C ...Programs\Ollama\ollama.exe 6024MiB | +-----------------------------------------------------------------------------------------+
Druga mówi, jak Ollama rozłożyła model. W kolumnie PROCESSOR zobaczysz 100% GPU (cały model na karcie), 100% CPU (tylko procesor) albo podział, gdy model nie mieści się w pamięci karty i część warstw ląduje na CPU:
ollama psNAME ID SIZE PROCESSOR CONTEXT UNTIL llama3.1:8b a80c4f17acd5 6.7 GB 100% GPU 4096 4 minutes from now
Docker. Jeśli uruchamiasz Ollamę w kontenerze, przekaż jej kartę flagą --gpus all (na hoście musi być zainstalowany NVIDIA Container Toolkit):
docker run -d --gpus all -v ollama:/root/.ollama -p 11434:11434 ollama/ollamaAMD (ROCm) i Apple Silicon. Karty AMD działają na Linuksie przez ROCm - Ollama udostępnia osobną paczkę z jego obsługą. Na komputerach Mac z układami Apple (M1-M4) akceleracja działa od razu, bez żadnej konfiguracji: współdzielona pamięć procesora i układu graficznego sprawia, że nawet większe modele liczą się sprawnie.
Uwaga: liczy się VRAM, nie sama szybkość karty
O tym, czy model „wejdzie" w całości na GPU, decyduje pamięć karty (VRAM). Obowiązuje tu ta sama zależność co przy parametrach: model 7B w kwantyzacji Q4 potrzebuje około 5-6 GB VRAM. Gdy zabraknie pamięci, Ollama wrzuci część warstw z powrotem na procesor (zobaczysz to w ollama ps jako podział CPU/GPU) - i wtedy przyspieszenie jest mniejsze. Jeśli tak się dzieje, wybierz mniejszy model albo mocniejszą kwantyzację.
Garść komend, które przydają się na co dzień:
ollama list - lokalne modele, ollama ps - modele aktualnie załadowane do pamięciollama rm <model> - usuń model z dysku, ollama cp <a> <b> - skopiuj pod nową nazwąollama pull <model> - pobierz/zaktualizuj, ollama run <model> - uruchom czatollama stop <model> - wyładuj model z pamięciSprawdźmy, co siedzi w pamięci po naszych rozmowach - i ile zajmuje:
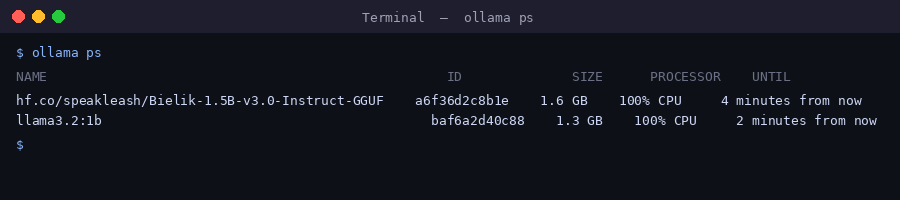
ollama ps pokazuje załadowane modele, ich rozmiar w pamięci, czy liczą na CPU czy GPU oraz kontekst. Modele wyładowują się automatycznie po kilku minutach bezczynności (parametr keep_alive).keep_alive — gdzie go ustawić?
Domyślnie Ollama trzyma model w pamięci przez 5 minut po ostatnim zapytaniu, potem zwalnia RAM. Możesz to zmienić na trzy sposoby:
1. W ciele żądania API (per-request, np. w Pythonie/JS):
requests.post("http://localhost:11434/api/generate", json={
"model": "qwen2.5:3b",
"prompt": "...",
"keep_alive": "30m" # lub -1 = nigdy nie wyładowuj, 0 = wyładuj od razu
})2. Zmienna środowiskowa (globalnie dla całego serwera):
# Linux / macOS — przed uruchomieniem serwera:
OLLAMA_KEEP_ALIVE=30m ollama serve
# systemd (plik /etc/systemd/system/ollama.service):
[Service]
Environment="OLLAMA_KEEP_ALIVE=30m"3. W Modelfile (na stałe dla danego modelu - Modelfile to plik-przepis modelu, który szczegółowo omawiamy w osobnej sekcji niżej):
FROM qwen2.5:3b
PARAMETER keep_alive 30mWartości specjalne: -1 = trzymaj w RAM na zawsze (przydatne gdy masz dużo RAM i często pytasz), 0 = wyładuj natychmiast po odpowiedzi (oszczędza RAM, ale każde kolejne pytanie czeka na wczytanie). Format: sekundy (300s), minuty (5m), godziny (2h).
Cały cykl życia modelu - od pobrania, przez wczytanie do pamięci i odpowiadanie, po zwolnienie RAM - wygląda tak:

Najmocniejsza funkcja: własny Modelfile. To przepis, który bierze gotowy model i dokleja mu stały prompt systemowy (osobowość, zasady), parametry i wiedzę. Tak w 4 linijkach robisz dedykowanego asystenta firmowego:
FROM qwen2.5:3b
SYSTEM "Jesteś asystentem BOK sklepu Techniczny Nowak. Odpowiadasz po polsku, krótko i uprzejmie. Czas dostawy to 1-2 dni robocze. Jeśli nie znasz odpowiedzi, prosisz o kontakt: biuro@nowak.pl."
PARAMETER temperature 0.3Zapisujesz to jako plik Modelfile i tworzysz nowy model jedną komendą:
ollama create bok-nowak -f Modelfile
ollama run bok-nowak "Jaki jest czas dostawy zamówienia?"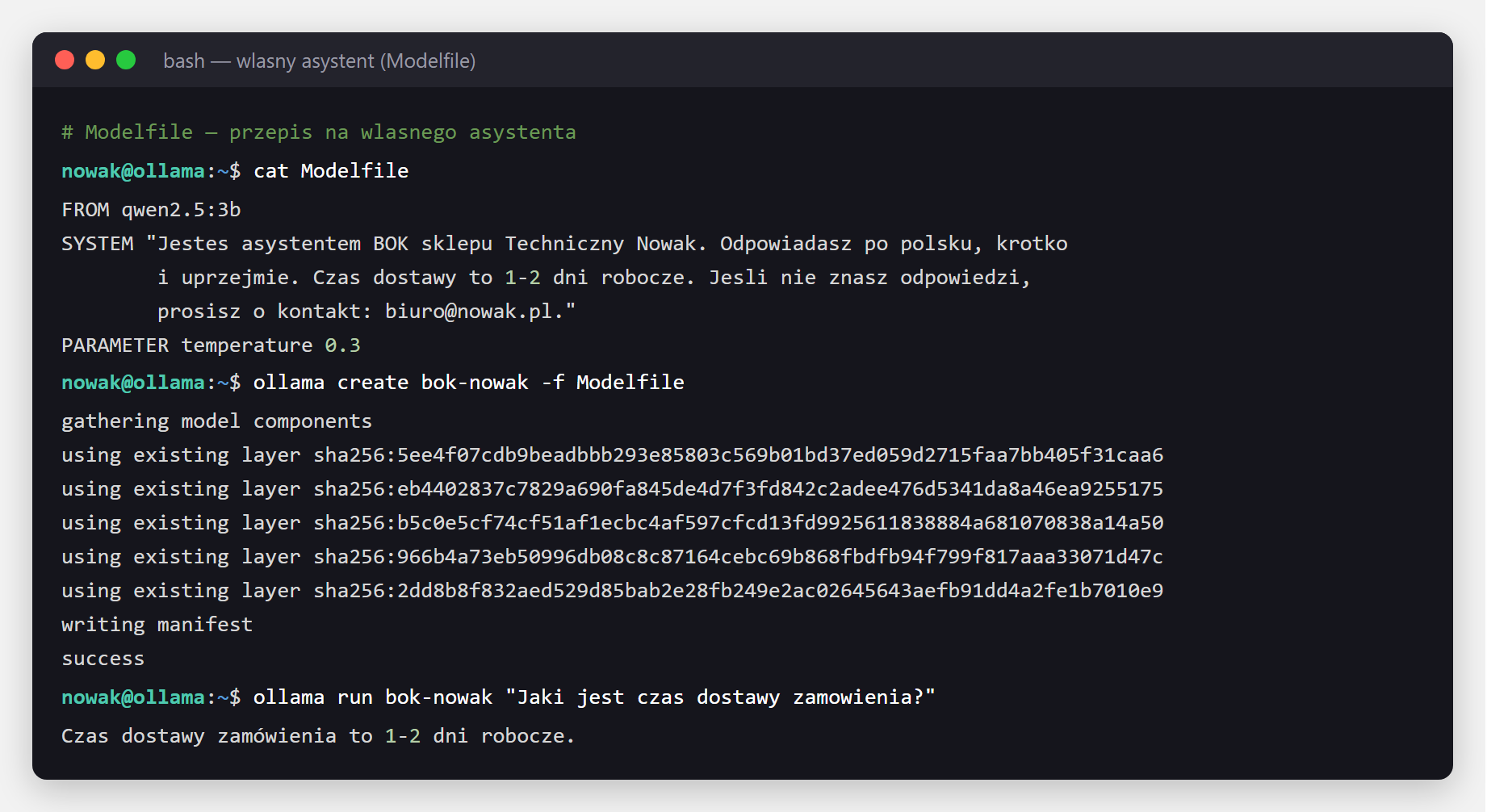
qwen2.5:3b powstał bok-nowak - asystent, który zawsze trzyma się roli i zna fakty z promptu systemowego (czas dostawy, kontakt). Idealne pod chatbota na stronie czy w n8n.Tu zaczyna się prawdziwa wartość. Poniżej konkretne scenariusze, w których lokalny model z Ollamą robi robotę - z uczciwą oceną, kiedy ma to sens.
1. Obsługa klienta i odpowiedzi na reklamacje
Model generuje szkice odpowiedzi na reklamacje, zapytania i e-maile (jak na zrzucie wyżej z polskim Bielikiem). Pracownik tylko sprawdza i wysyła - oszczędność wielu godzin dziennie w dziale obsługi.
Kiedy warto: gdy treści dotyczą danych klientów (RODO) i nie chcesz ich wysyłać do zewnętrznego dostawcy; przy dużym wolumenie maili.
2. Streszczanie i klasyfikacja dokumentów poufnych
Lokalny model streszcza długie umowy, wyciąga kluczowe klauzule, kategoryzuje zgłoszenia czy CV. Ponieważ wszystko liczy się na Twoim serwerze, dział prawny i HR mogą używać AI bez ryzyka wycieku.
Kiedy warto: umowy, dokumentacja medyczna, akta - wszędzie tam, gdzie dane absolutnie nie mogą opuścić firmy.
3. Asystent programisty (generowanie i refactor kodu)
Wyspecjalizowane modele jak qwen2.5-coder piszą funkcje, testy i refactory. Poniżej model na żądanie napisał walidator polskiego NIP - całość lokalnie, kod nigdzie nie wyciekł:
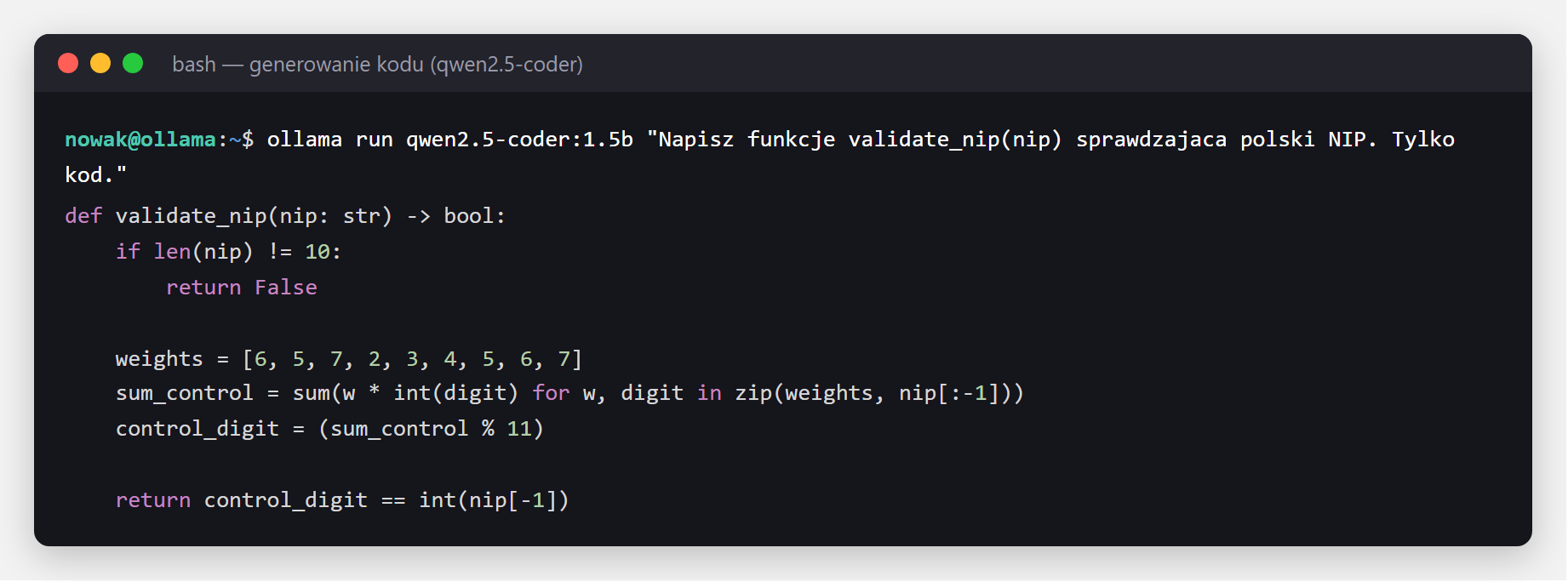
qwen2.5-coder:1.5b (zaledwie 986 MB) generuje poprawną funkcję walidującą polski NIP wraz z sumą kontrolną. Mały model wyspecjalizowany w kodzie potrafi zaskoczyć.Kiedy warto: gdy kod jest własnością klienta lub objęty NDA i nie może trafić do chmury; do szybkich, powtarzalnych zadań.
4. Lokalny RAG — chatbot nad dokumentacją firmy
Zwykły model językowy wie dużo o świecie — ale nic o Twoich wewnętrznych dokumentach, regulaminach, umowach czy bazie wiedzy. Żeby pytać AI o treść własnych plików, potrzebujesz RAG (Retrieval-Augmented Generation). Ollama ma do tego wszystkie potrzebne narzędzia i wszystko liczy się lokalnie — żaden dokument nie wychodzi poza serwer.
Faza przygotowania (jednorazowo):
nomic-embed-text (lokalnie, przez Ollama API)Na każde pytanie użytkownika:
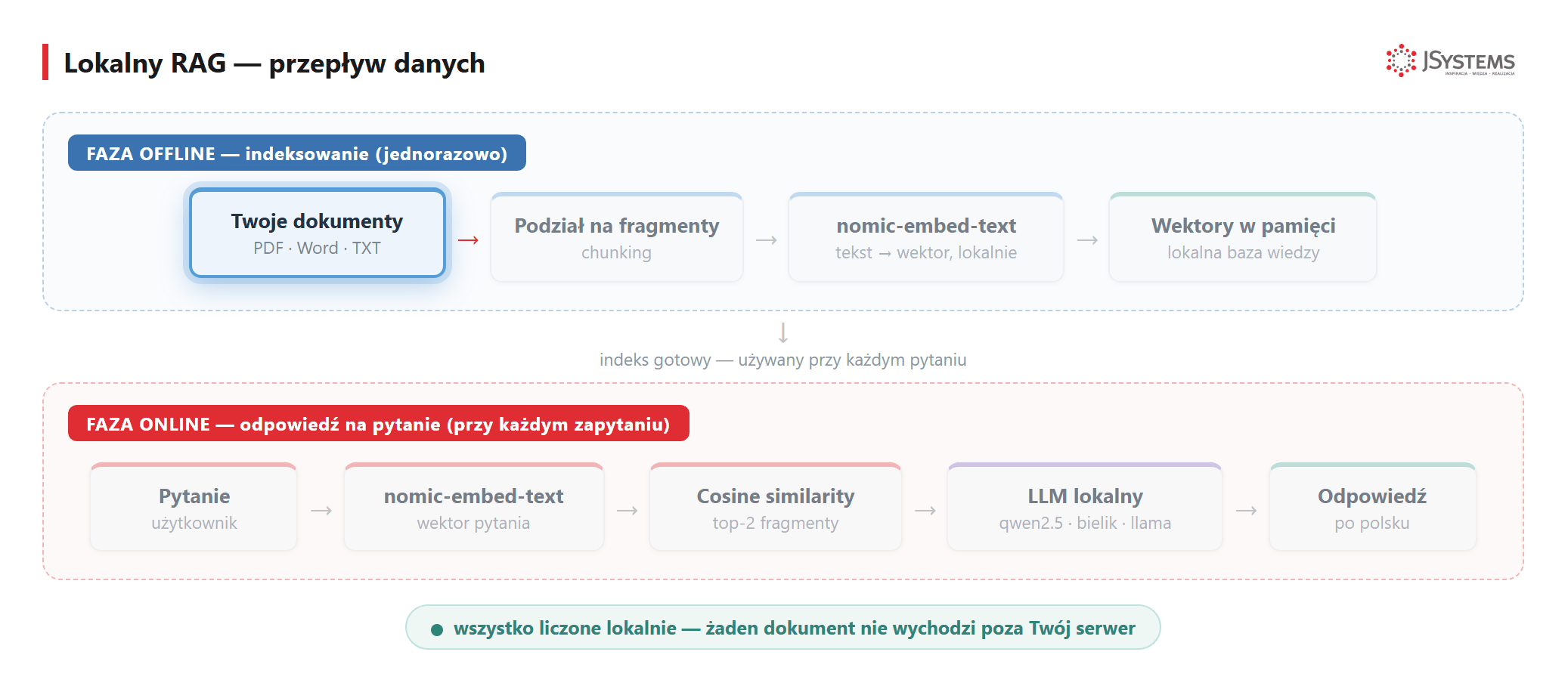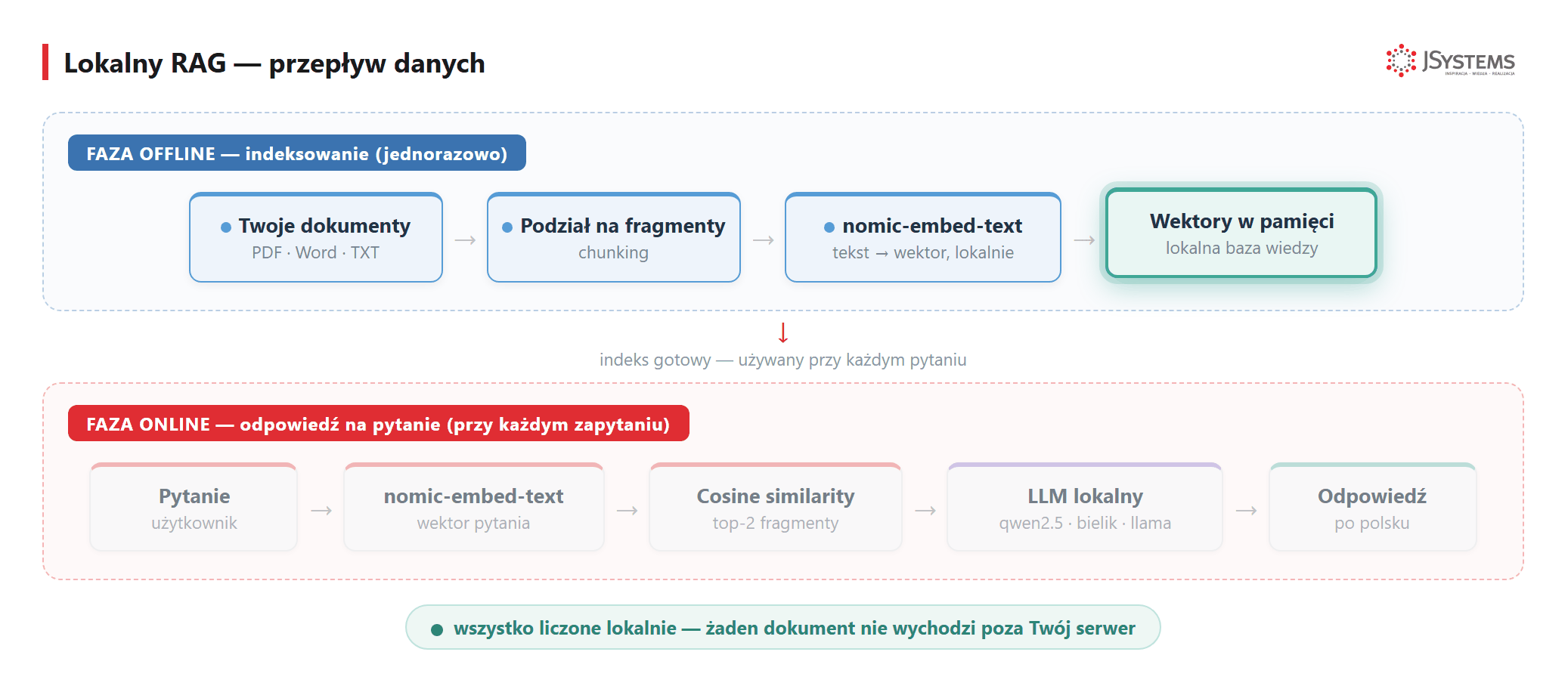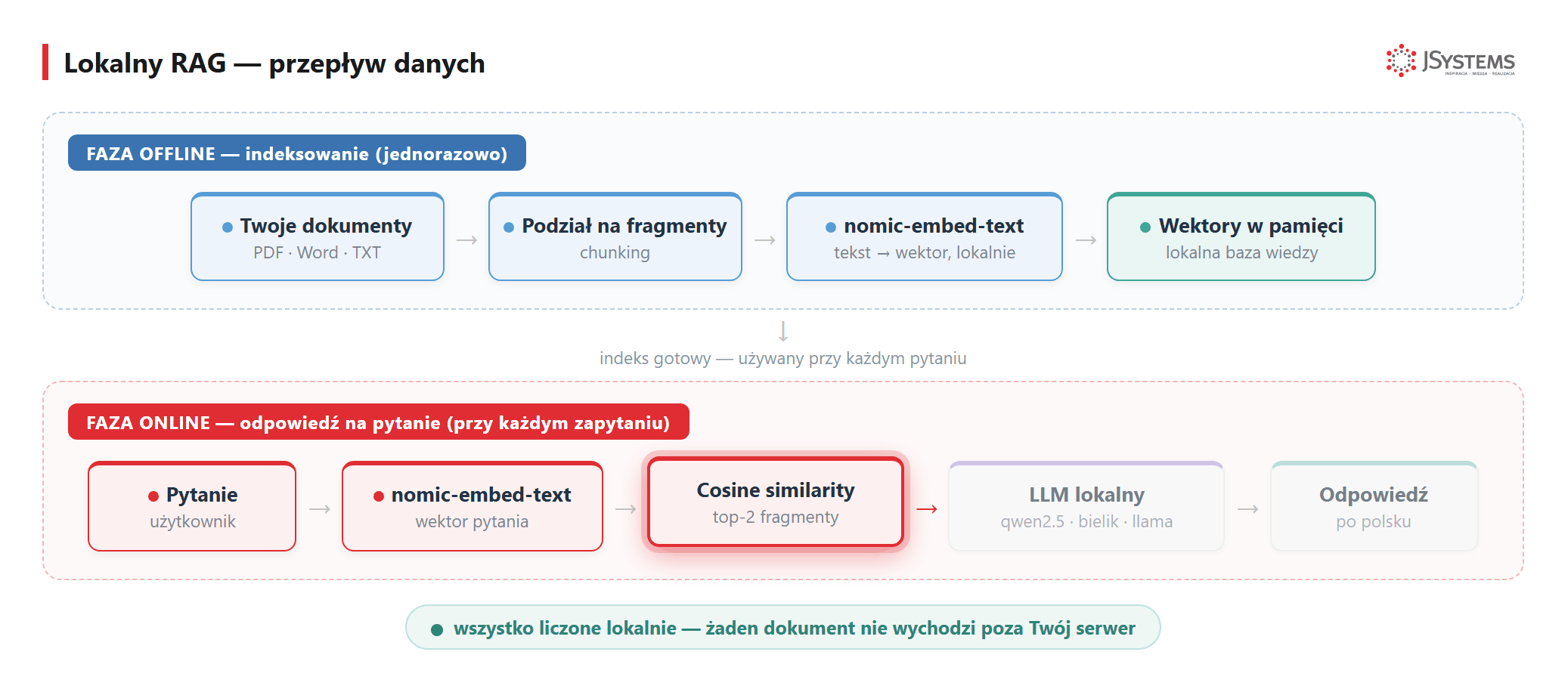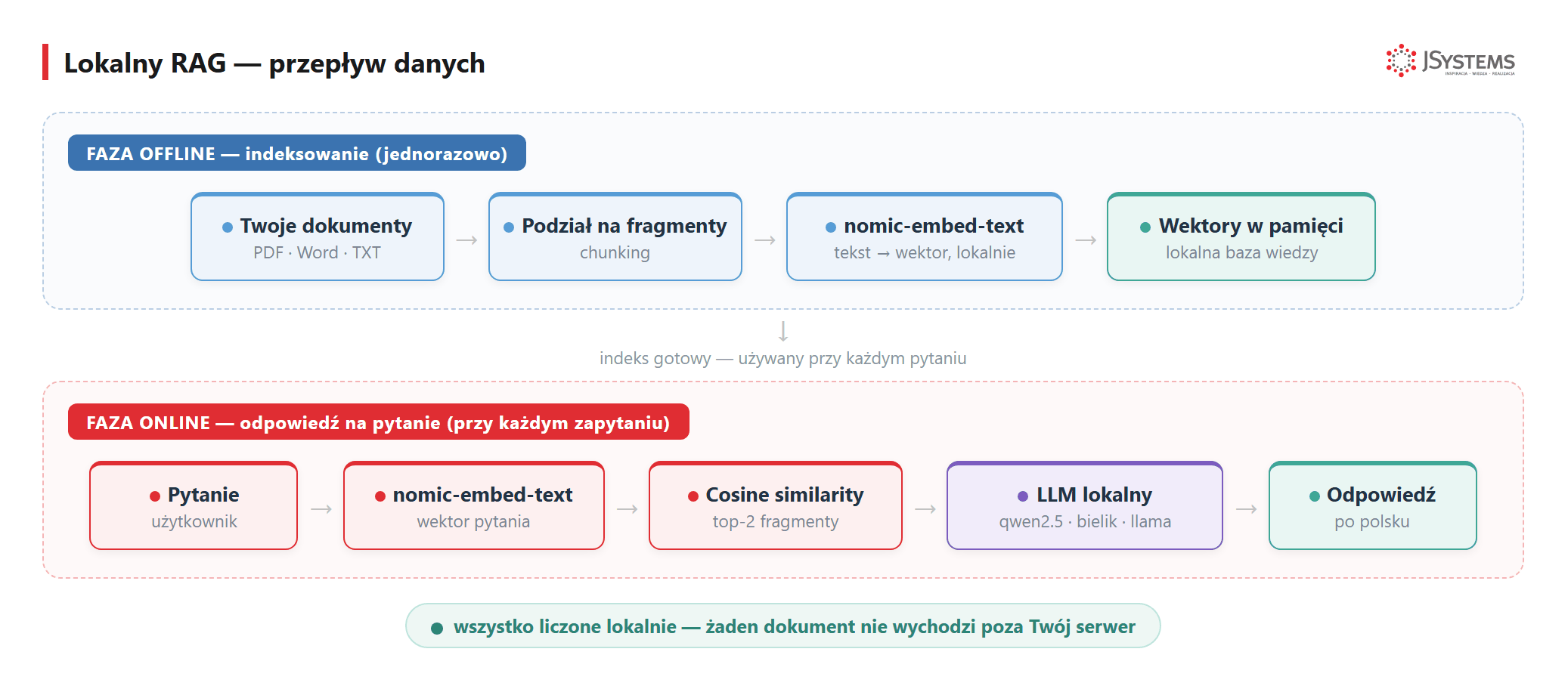
nomic-embed-text i trzymamy w pamięci. Pytanie też zamieniamy na wektor, wybieramy najbardziej podobne fragmenty (cosine similarity) i podajemy je lokalnemu modelowi — wszystko na Twoim serwerze, bez zapytań do chmury.Poniżej gotowy kod — wyszukiwanie semantyczne nad prostą bazą wiedzy, całość lokalnie w ~20 linijkach Pythona. Pełny, produkcyjny pipeline (LangChain, podział na fragmenty, baza wektorów Chroma) pokazujemy krok po kroku w osobnym tutorialu: LangChain RAG tutorial w Pythonie.
import requests, numpy as np
# 1. Funkcja zamieniajaca tekst na wektor (embedding) - liczona lokalnie przez Ollama API
def embed(text):
r = requests.post("http://localhost:11434/api/embeddings",
json={"model": "nomic-embed-text", "prompt": text})
return np.array(r.json()["embedding"])
# 2. Nasza baza wiedzy - zdania, wsrod ktorych szukamy odpowiedzi
baza = [
"Zwroty przyjmujemy w ciagu 30 dni od zakupu.",
"Gwarancja na laptopy wynosi 24 miesiace.",
"Darmowa dostawa od 200 zl.",
]
# 3. Liczymy wektor dla kazdego zdania z bazy (raz, na starcie)
wektory = [embed(t) for t in baza]
# 4. Pytanie uzytkownika - ta sama funkcja zamienia je na wektor
pytanie = "Jak dlugo mam na oddanie towaru?"
qv = embed(pytanie)
# 5. Podobienstwo pytania do kazdego zdania (cosine similarity: 1.0 = to samo znaczenie)
podob = [float(qv @ v / (np.linalg.norm(qv) * np.linalg.norm(v))) for v in wektory]
# 6. Bierzemy zdanie o najwyzszym podobienstwie i je zwracamy
best = int(np.argmax(podob))
print(baza[best]) # -> trafia w zdanie o zwrotach, mimo zupelnie innych slow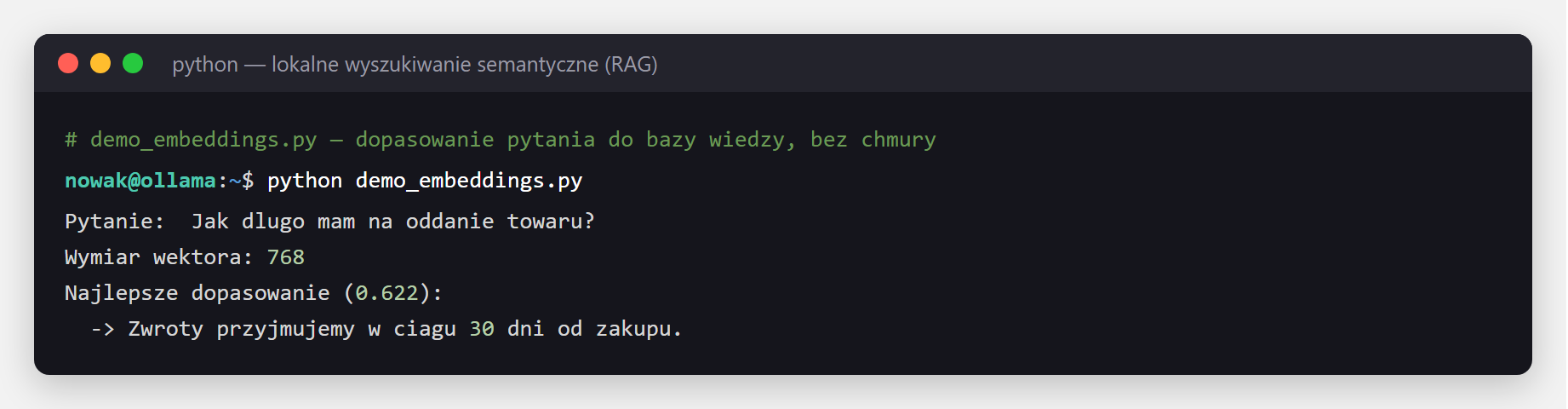
Dlaczego „bez chmury" robi tu dużą różnicę?
Klasyczny RAG z OpenAI wysyła treść Twoich dokumentów do serwerów w USA przy każdym pytaniu. W Ollama: wektory liczone lokalnie, LLM działa lokalnie — dokumenty fizycznie nie opuszczają serwera. To ma znaczenie przy:
Kiedy warto: gdy budujesz wyszukiwarkę lub asystenta nad wewnętrzną bazą wiedzy (dokumentacja, FAQ, umowy, procedury) i dane nie mogą wyjść poza firmową sieć. Do gotowego interfejsu bez pisania kodu — patrz Open WebUI w kolejnym rozdziale.
5. Automatyzacje w n8n i własne aplikacje
Ollama wystawia API zgodne z OpenAI, więc wpina się w n8n, własne backendy i skrypty jako „darmowy GPT". Klasyfikacja zgłoszeń, tagowanie leadów, generowanie opisów produktów - wszystko w pętli automatyzacji, za zero złotych za zapytanie.
Kiedy warto: gdy automatyzujesz procesy (maile, zgłoszenia, dane) i chcesz wpleść AI bez kosztu za token.
Natywna aplikacja Ollamy to prosty czat - nie ma tu uploadu dokumentów ani bazy wiedzy. Jeśli chcesz wgrać pliki PDF i pytać model o ich treść bez pisania kodu, potrzebujesz Open WebUI: otwartoźródłowego interfejsu webowego, który uruchamiasz lokalnie jedną komendą Docker i podłączasz do działającej Ollamy. Dane dalej nie opuszczają Twojej sieci.
Warunek: Ollama działa i masz Dockera zainstalowanego. Na Linuksie i Macu:
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui --restart always \
ghcr.io/open-webui/open-webui:mainNa Windowsie (Docker Desktop) — bez linii --add-host, bo host.docker.internal działa tu automatycznie. W PowerShellu znakiem kontynuacji linii jest backtick (`), nie ukośnik \ — dlatego komenda dla Windows wygląda inaczej:
docker run -d -p 3000:8080 `
-v open-webui:/app/backend/data `
--name open-webui --restart always `
ghcr.io/open-webui/open-webui:mainPo kilkudziesięciu sekundach otwierasz http://localhost:3000 w przeglądarce, zakładasz konto (pierwsze konto = admin) i logujesz się. Open WebUI samo wykrywa wszystkie modele pobrane przez Ollamę - pojawiają się w selektorze bez żadnej dodatkowej konfiguracji.
Bazę wiedzy budujesz w pięciu krokach - każdy pokazujemy na zrzucie z działającego Open WebUI.
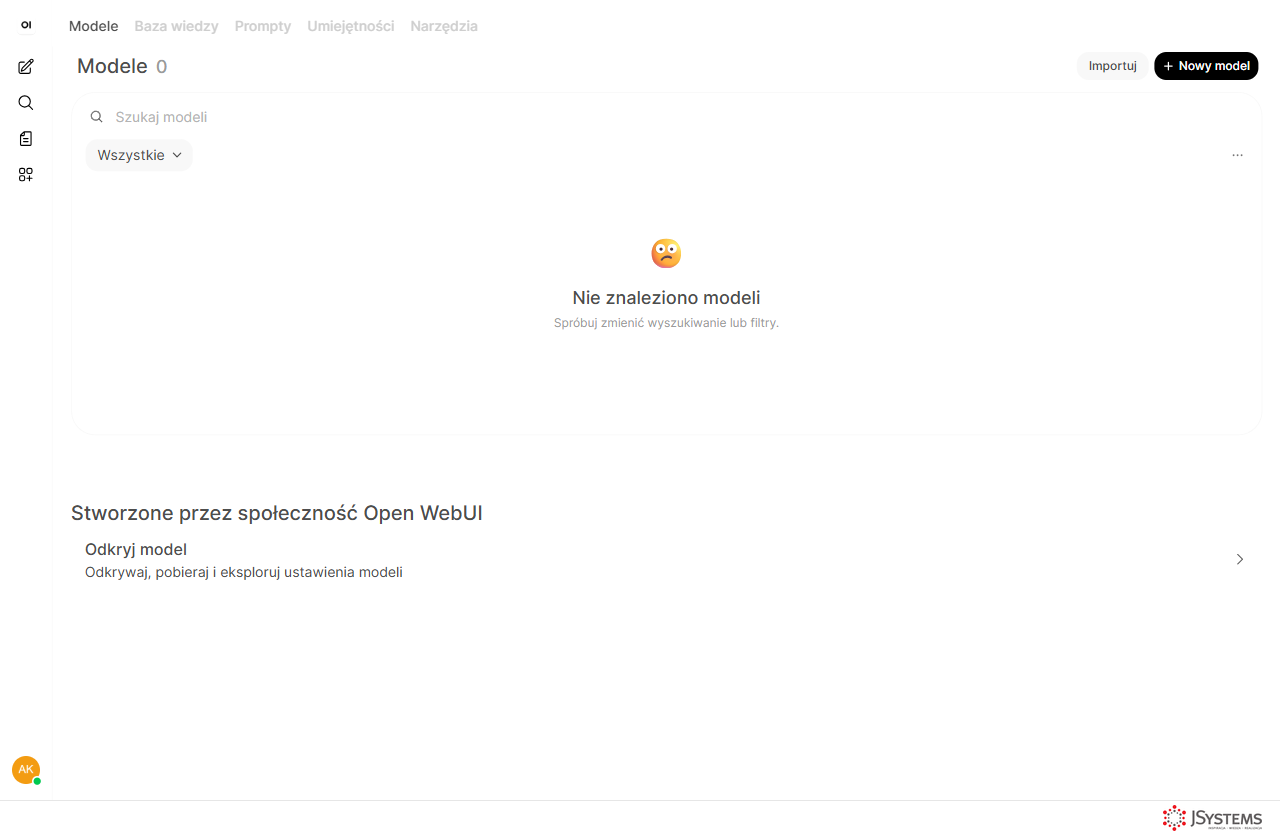
Krok 1. Otwórz Obszar roboczy. W lewym panelu kliknij ikonę Obszar roboczy. Otworzy się on domyślnie na zakładce Modele - zobaczysz komunikat „Nie znaleziono modeli" i przycisk Nowy model. To nie tędy droga, nie daj się zmylić.
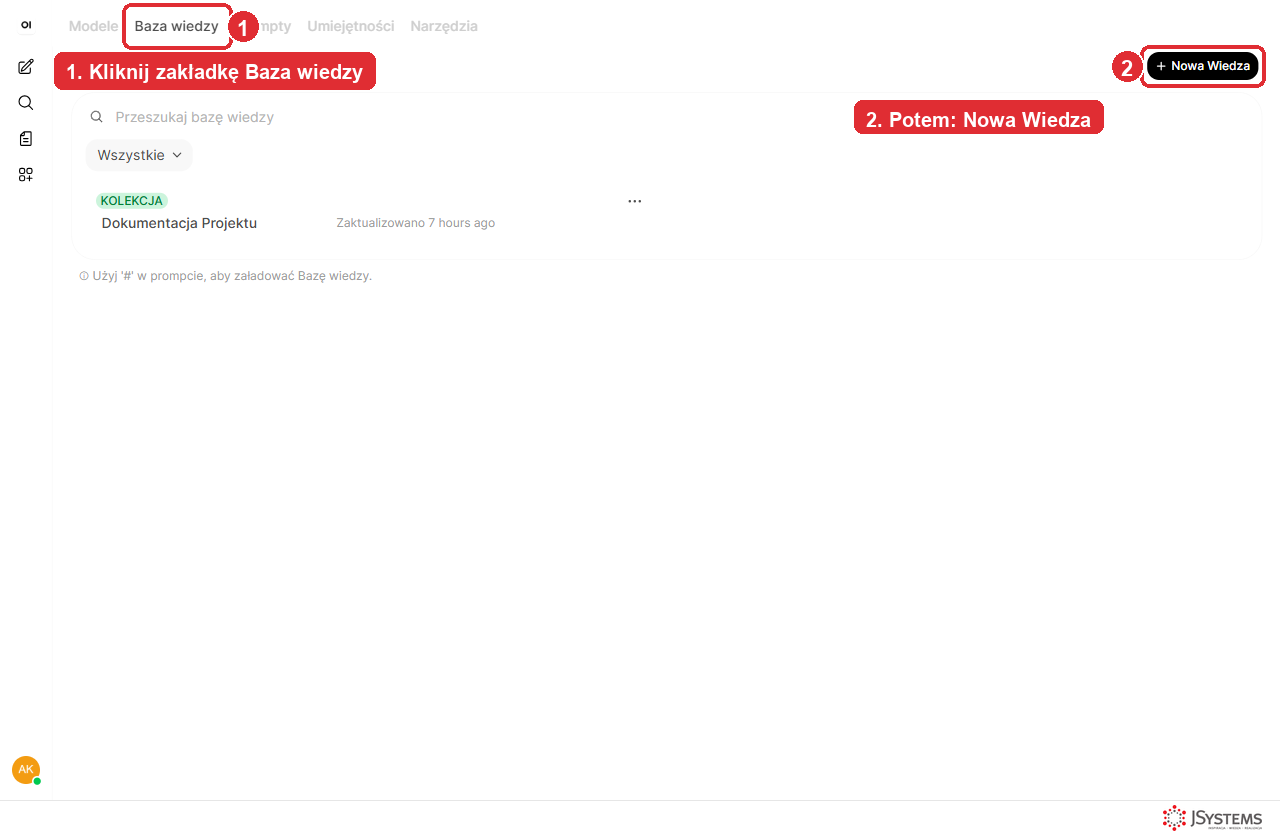
Krok 2. Przejdź na zakładkę Baza wiedzy. Kliknij Baza wiedzy w pasku zakładek, a następnie przycisk + Nowa Wiedza w prawym górnym rogu. Adres bezpośredni: http://localhost:3000/workspace/knowledge.
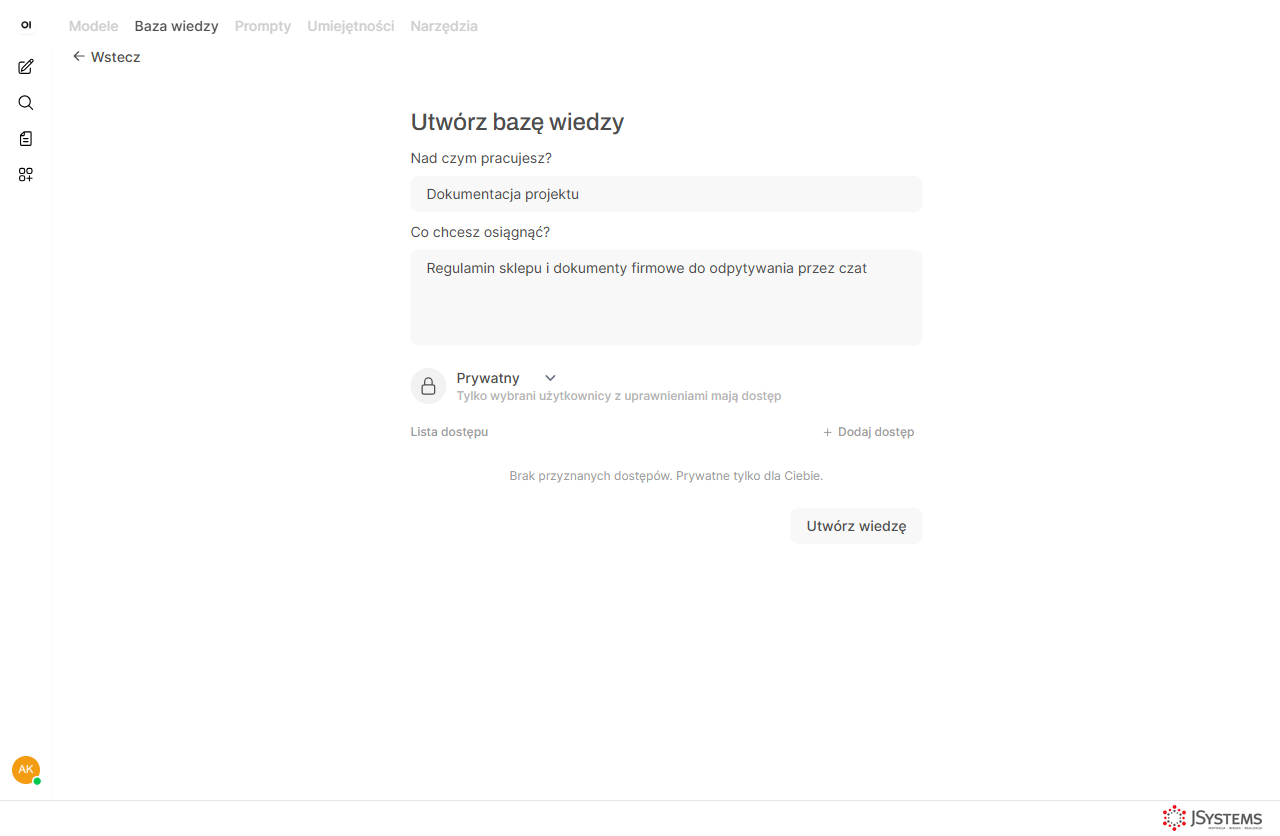
Krok 3. Nazwij bazę. Podaj nazwę (np. „Dokumentacja projektu") i krótki opis, zostaw widoczność Prywatny i kliknij Utwórz wiedzę.
Krok 4. Wgraj dokumenty. Wejdź do bazy i przeciągnij pliki albo kliknij +. Open WebUI akceptuje PDF, DOCX, TXT i Markdown. Każdy dokument jest automatycznie dzielony na fragmenty (chunks) i zamieniany na embeddingi - czyli wektory liczbowe opisujące znaczenie tekstu, po których model potem wyszukuje.
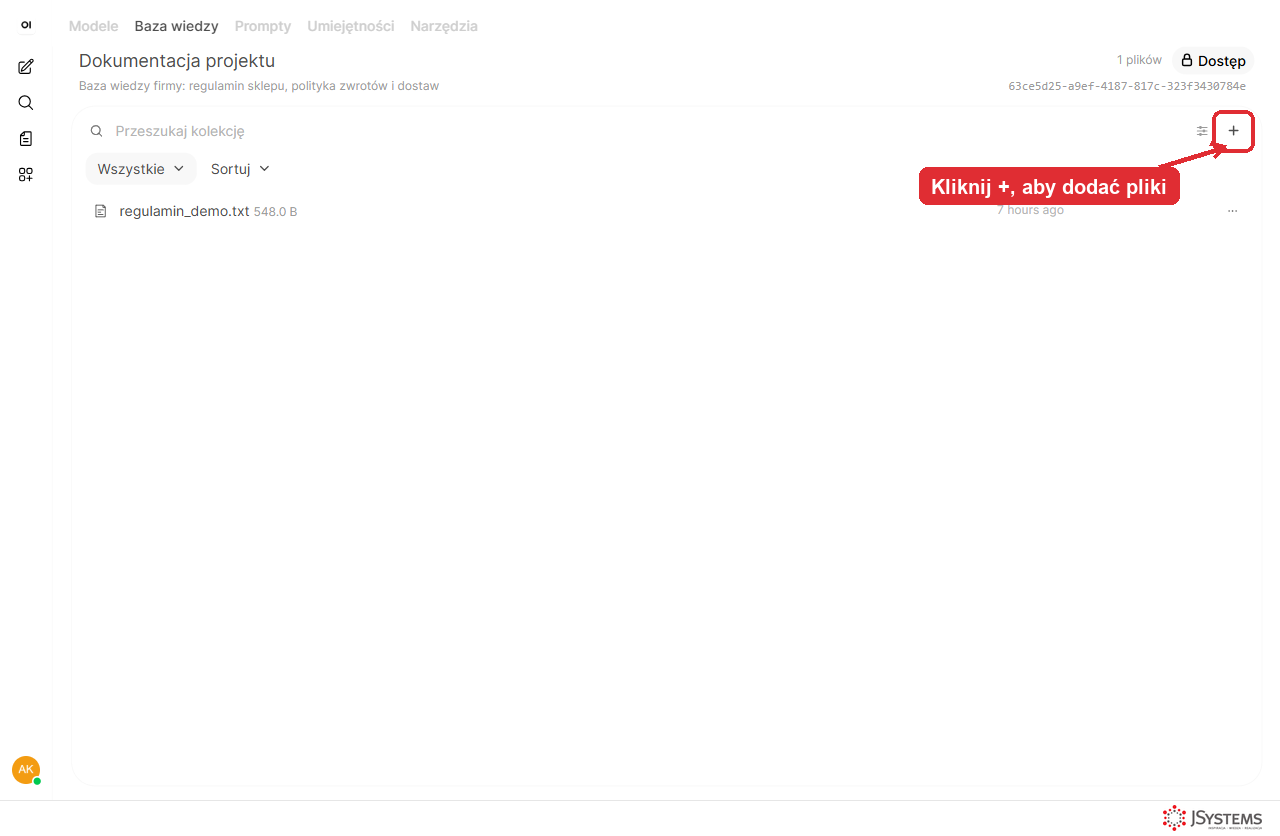
regulamin_demo.txt). Kolejne pliki dodajesz przyciskiem + w prawym górnym rogu lub przeciągając je na listę.Krok 5. Ustaw lokalny model embeddingowy. Domyślnie Open WebUI liczy embeddingi własnym, wbudowanym modelem. Żeby cały RAG był w 100% lokalny i spójny z Ollamą, przełącz model embeddingowy na nomic-embed-text uruchamiany przez Ollamę (pobierz go wcześniej przez ollama pull nomic-embed-text). Robisz to raz, w pięciu ruchach:
5a. Kliknij swój awatar w lewym dolnym rogu i wybierz Panel administracyjny.
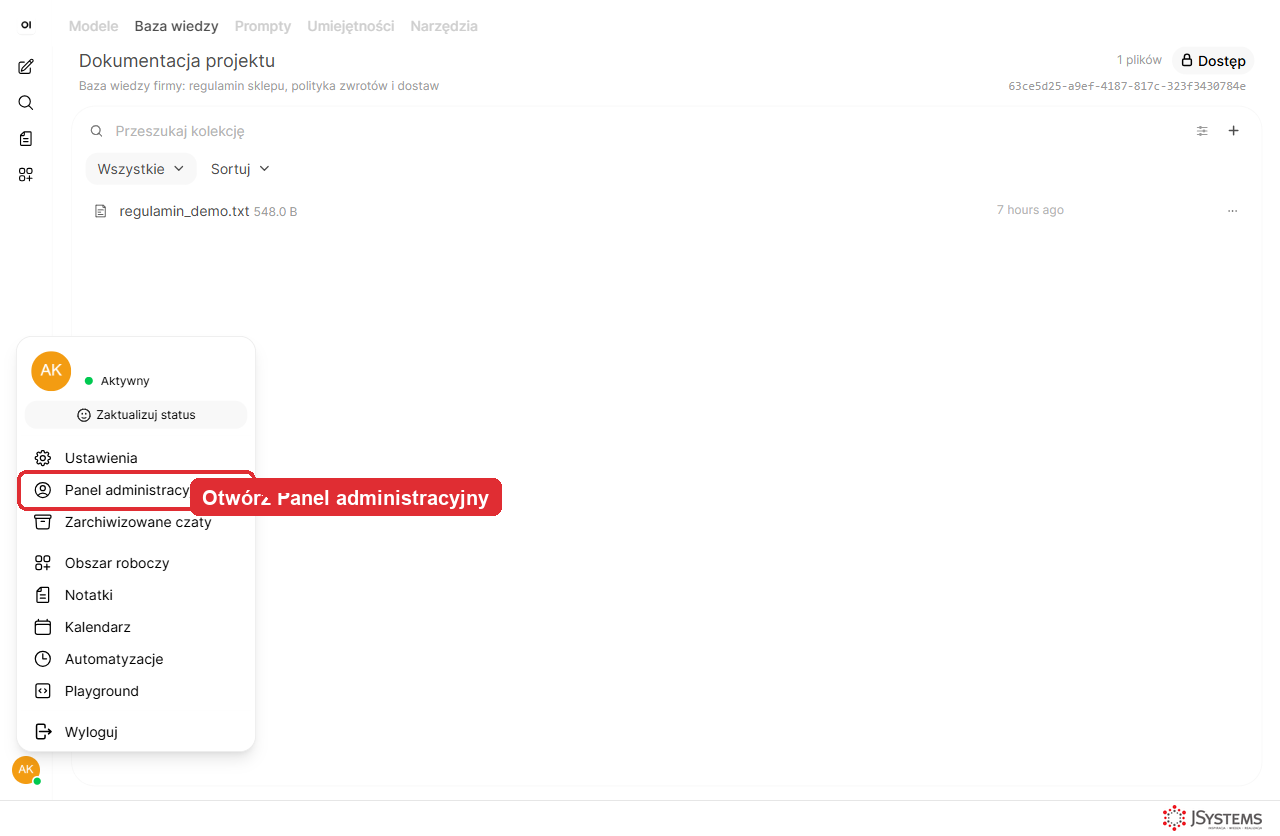
5b. W panelu przejdź do Ustawienia i wybierz w lewym menu zakładkę Dokumenty.
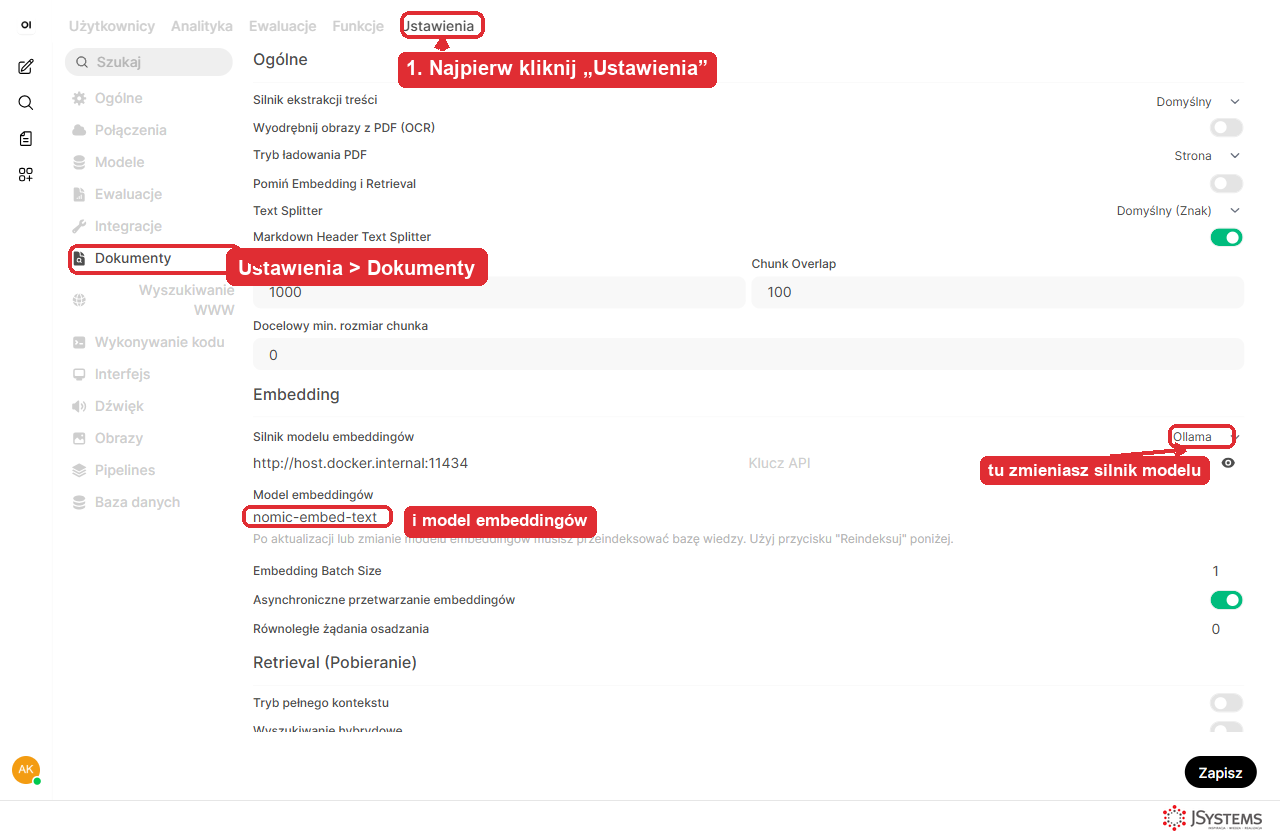
5c. W sekcji Embedding ustaw silnik na Ollama i wpisz model nomic-embed-text. Adres API podpowie się sam (host.docker.internal:11434 - tak kontener Open WebUI widzi Ollamę na Twoim komputerze).

nomic-embed-text. Dzięki temu również wektory liczą się lokalnie - żaden fragment dokumentu nie trafia do chmury.5d. Zapisz ustawienia. Zjedź na sam dół strony i kliknij czarny przycisk Zapisz w prawym dolnym rogu - zatwierdza on wybrany silnik i model embeddingowy. Bez kliknięcia Zapisz zmiana nie wejdzie w życie. Tuż nad tym przyciskiem znajduje się sekcja Strefa krytyczna, której użyjesz w kolejnym kroku.
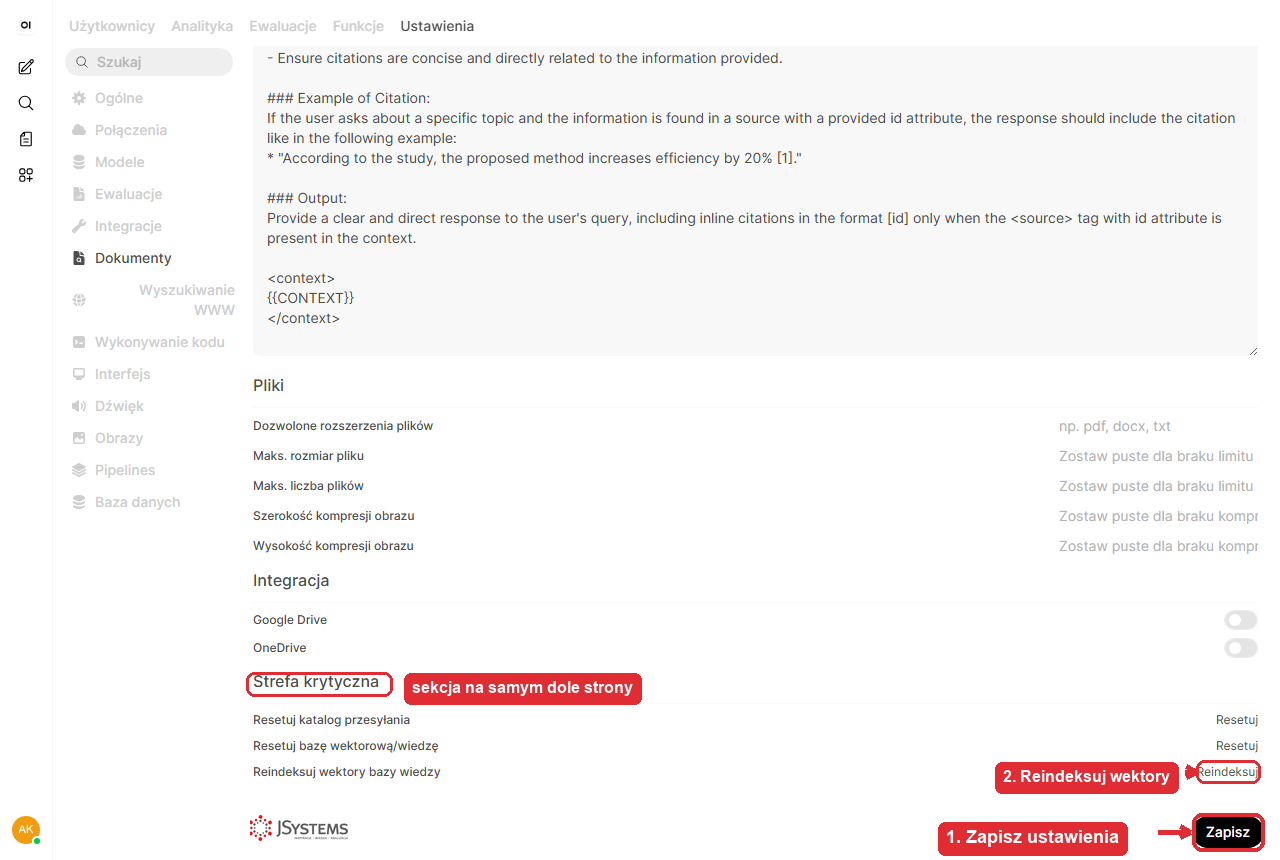
5e. Przeindeksuj bazę wiedzy. W sekcji Strefa krytyczna (tuż nad przyciskiem Zapisz) kliknij Reindeksuj w wierszu „Reindeksuj wektory bazy wiedzy" - to przelicza od nowa embeddingi już wgranych dokumentów nowym modelem. Bez tego stare wektory nie pasują do nowego modelu i wyszukiwanie zwraca słabe wyniki.

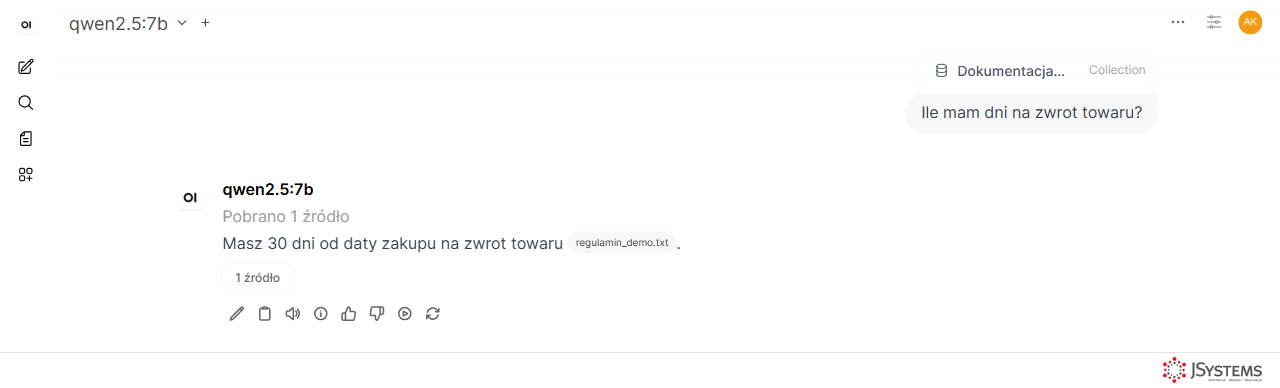
W oknie nowej rozmowy kliknij ikonę + obok pola wiadomości i wybierz Baza wiedzy - zaznacz bazę, którą stworzyłeś. Od tej chwili przed każdą odpowiedzią model automatycznie przeszukuje Twoje dokumenty i wstrzykuje pasujące fragmenty do kontekstu. Możesz też wpisać # bezpośrednio w wiadomości - pojawi się lista baz do wyboru. Model cytuje fragmenty źródłowe, więc wiesz skąd pochodzi dana informacja.
Poza bazą wiedzy: wyszukiwanie w internecie przez lokalny SearXNG, narzędzia (Tools) pisane w Pythonie, zarządzanie wieloma użytkownikami z uprawnieniami, stałe prompty systemowe per model bez Modelfile, i generowanie obrazów przez Stable Diffusion. Możesz postawić Open WebUI na serwerze i udostępnić całemu zespołowi - samohosted odpowiednik ChatGPT Teams, bez miesięcznego abonamentu.
Tu Ollama pokazuje pazur. Po starcie nasłuchuje na http://localhost:11434 i wystawia REST API. Trzy najważniejsze endpointy to /api/generate (pojedyncze zapytanie), /api/chat (rozmowa z historią) i /api/embeddings (wektory).
We wszystkich przykładach pole model podmienisz na dowolny pobrany model - API jest identyczne. Tam, gdzie liczy się jakość polszczyzny, używamy Bielika; gdzie nie ma to znaczenia - szybszego modelu ogólnego.
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:3b",
"prompt": "Przetlumacz na angielski: Dziekujemy za zamowienie.",
"stream": false
}' 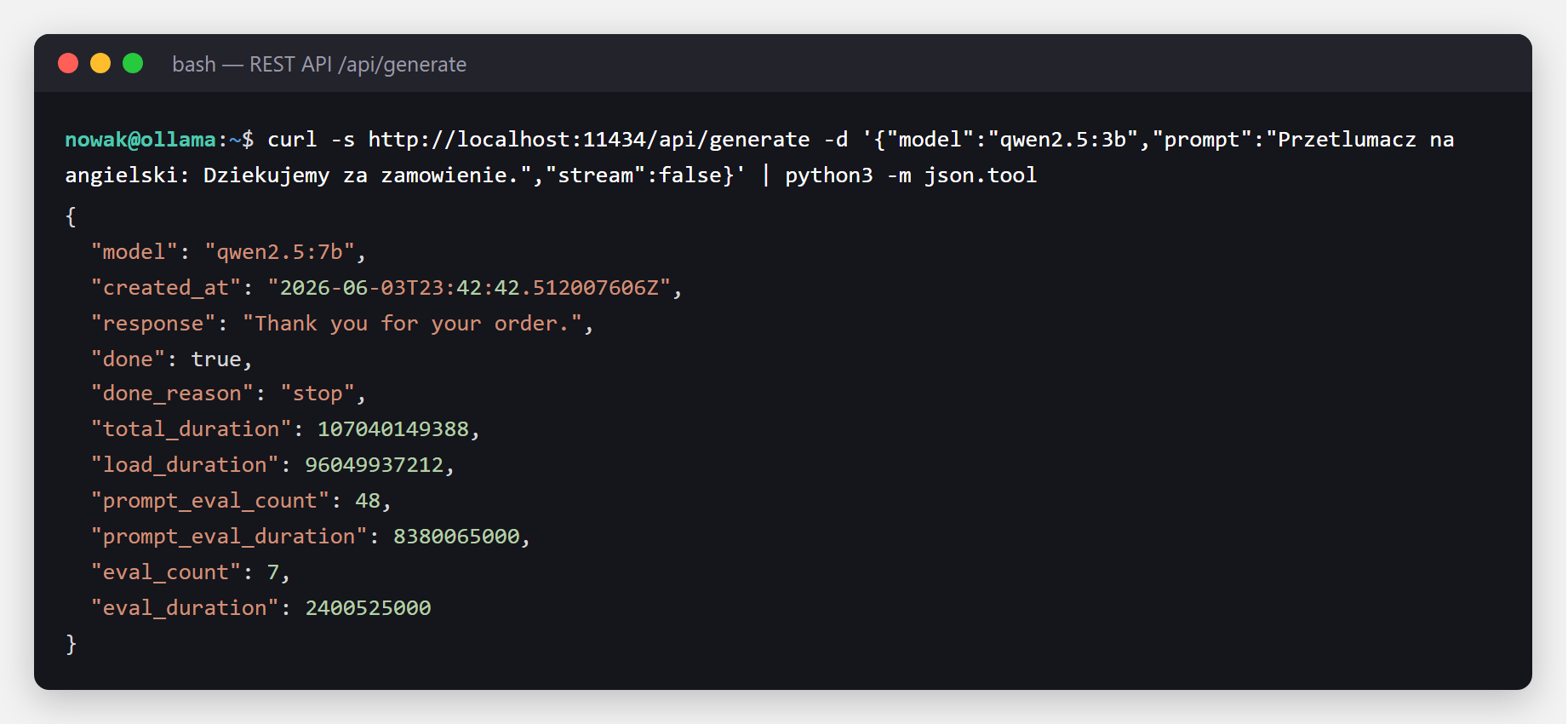
response (tekst), done, eval_count (ile tokenów wygenerowano) i total_duration. Ustawienie "stream": false zwraca całość naraz zamiast strumienia.Najbardziej uniwersalnie - zwykły HTTP. Działa wszędzie, gdzie masz requests:
import requests
resp = requests.post("http://localhost:11434/api/generate", json={
"model": "qwen2.5:3b",
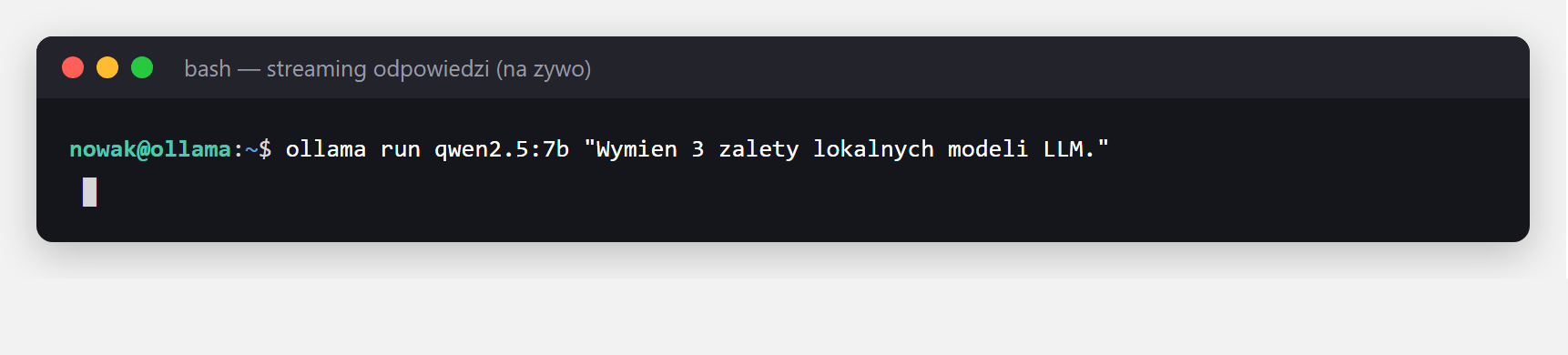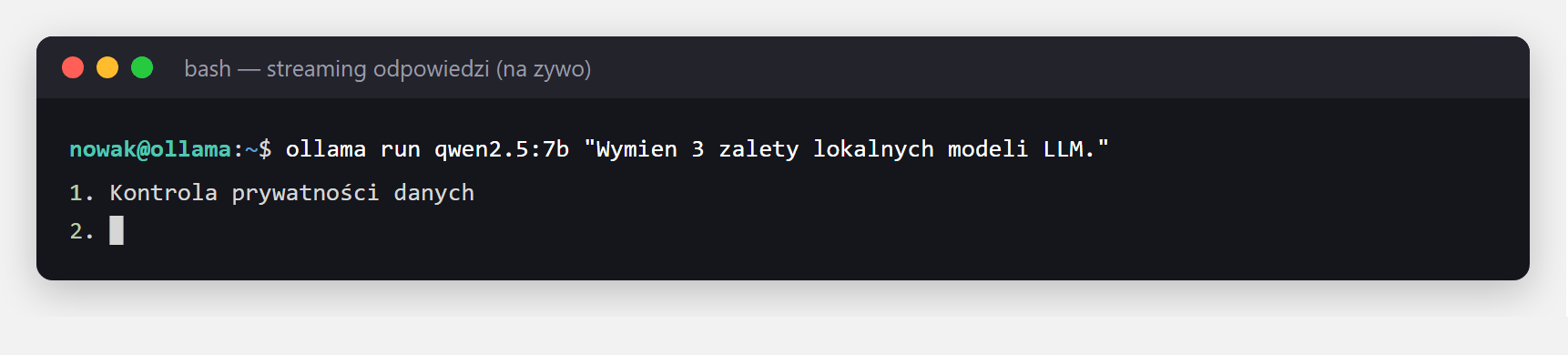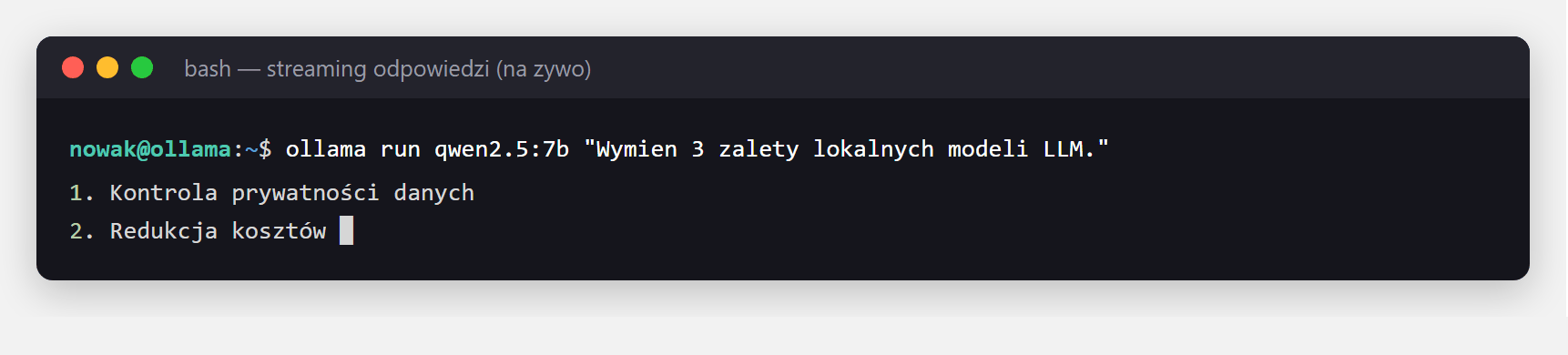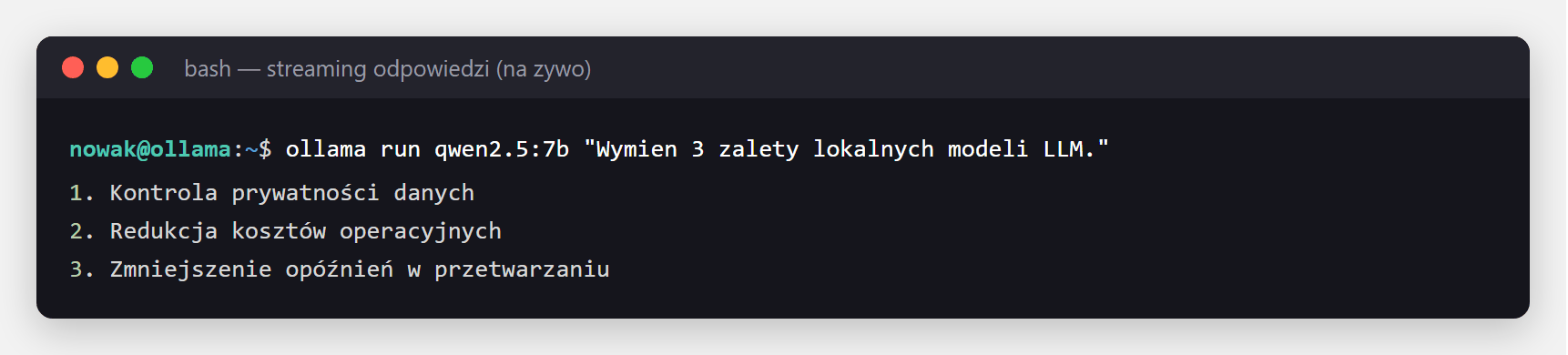
"prompt": "Wypisz 3 zalety lokalnych modeli LLM.",
"stream": False,
"options": {"temperature": 0.3, "num_predict": 200},
})
print(resp.json()["response"])Czytelniej z dedykowaną biblioteką (pip install ollama). Obsługuje rozmowę z historią i prompt systemowy:
import ollama
MODEL = "hf.co/speakleash/Bielik-1.5B-v3.0-Instruct-GGUF" # polski model
resp = ollama.chat(
model=MODEL,
messages=[
{"role": "system", "content": "Jestes asystentem sklepu Nowak. Odpowiadasz krotko i rzeczowo. Zwroty do 30 dni, produkt nieuzywany."},
{"role": "user", "content": "Czy mozna zwrocic otwarty produkt?"},
],
options={"temperature": 0.2},
)
print(resp.message.content)
Najlepsza wiadomość dla tych, którzy mają już kod pod OpenAI: Ollama wystawia endpoint zgodny z OpenAI pod /v1. Wystarczy zmienić base_url i klucz może być dowolny - reszta kodu zostaje bez zmian. Migracja z chmury na lokalne to dosłownie jedna linijka:
from openai import OpenAI
# Zamiast api.openai.com -> lokalna Ollama. Klucz moze byc dowolny.
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
resp = client.chat.completions.create(
model="hf.co/speakleash/Bielik-1.5B-v3.0-Instruct-GGUF",
messages=[{"role": "user", "content": "Wymien 3 zalety automatyzacji powtarzalnych zadan w firmie. Krotko."}],
)
print(resp.choices[0].message.content)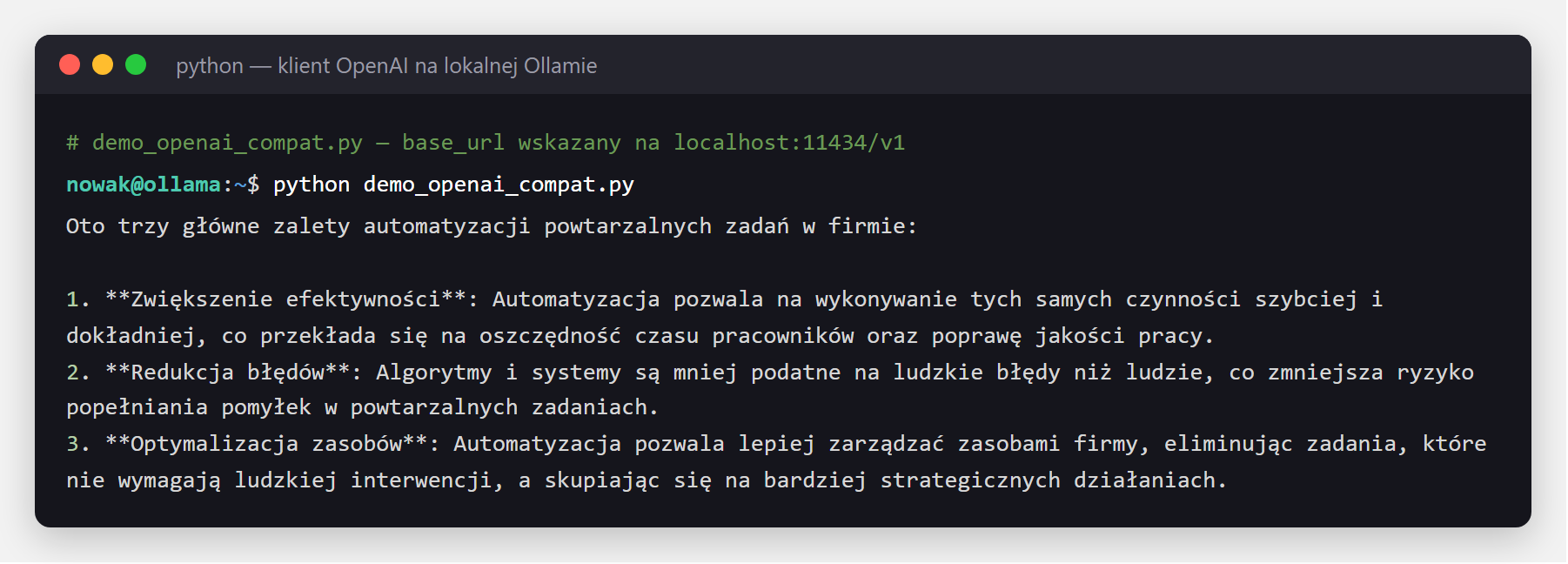
openai wskazana na localhost:11434/v1 rozmawia z lokalnym modelem. Twój istniejący kod pod OpenAI działa bez przepisywania - zmieniasz tylko adres.Żeby odpowiedź pojawiała się na bieżąco (jak w ChatGPT), ustaw stream=True i czytaj fragmenty w pętli:
import ollama
for chunk in ollama.chat(
model="qwen2.5:3b",
messages=[{"role": "user", "content": "Opowiedz krotko o zaletach pracy zdalnej."}],
stream=True,
):
print(chunk.message.content, end="", flush=True)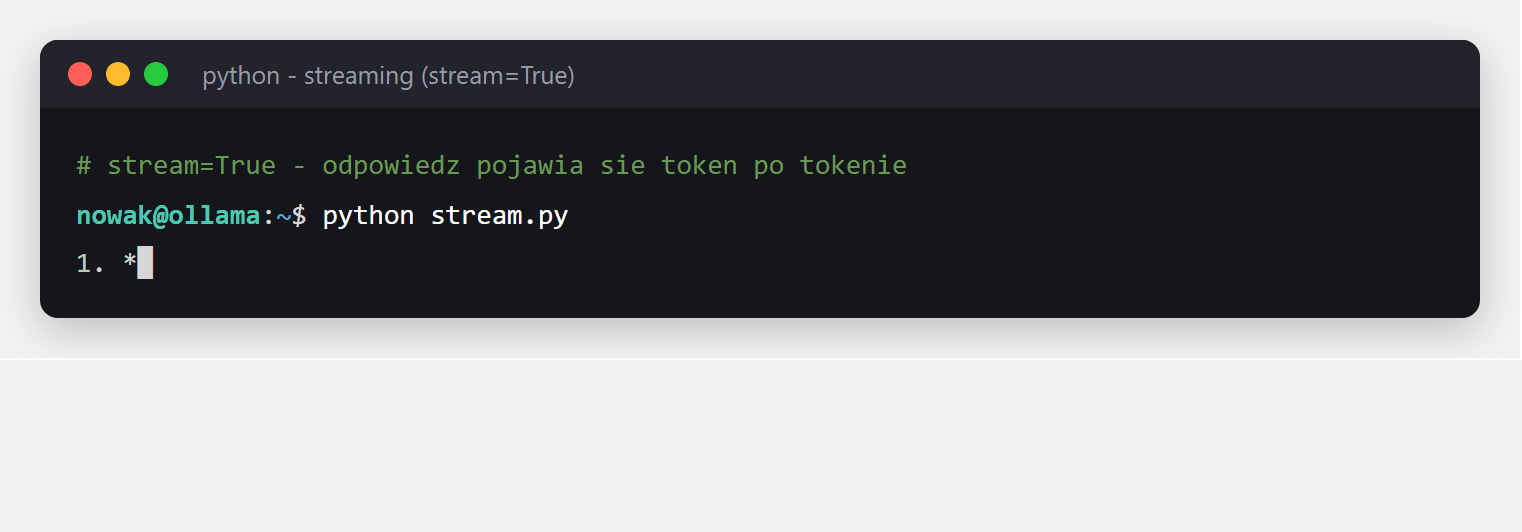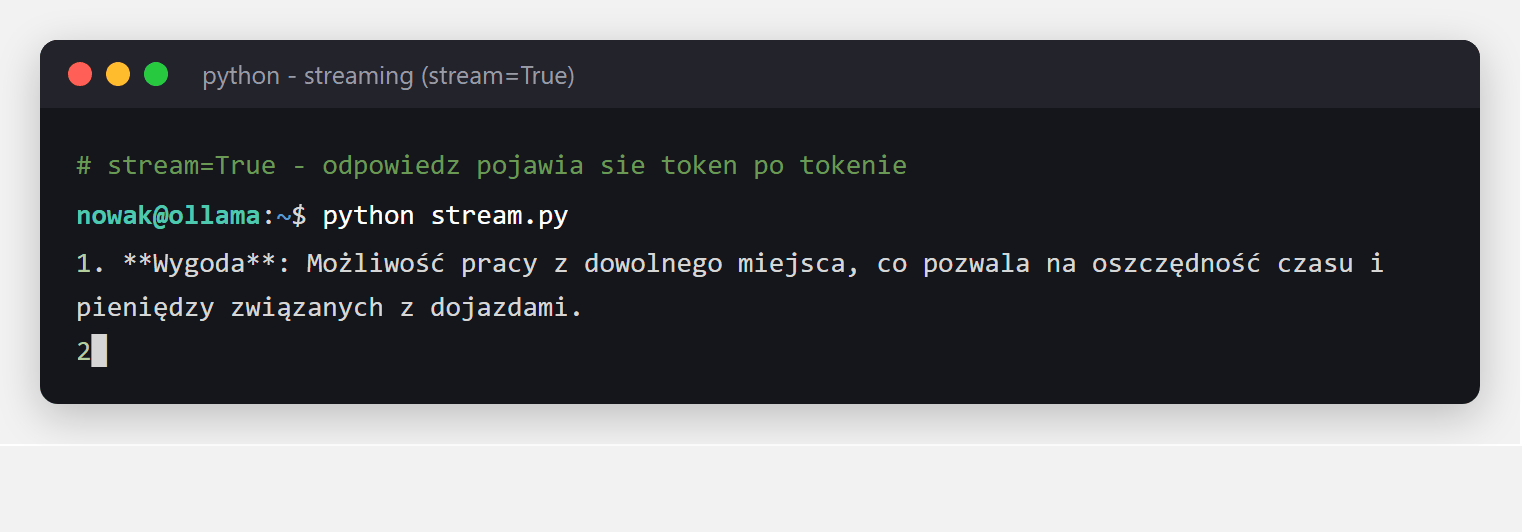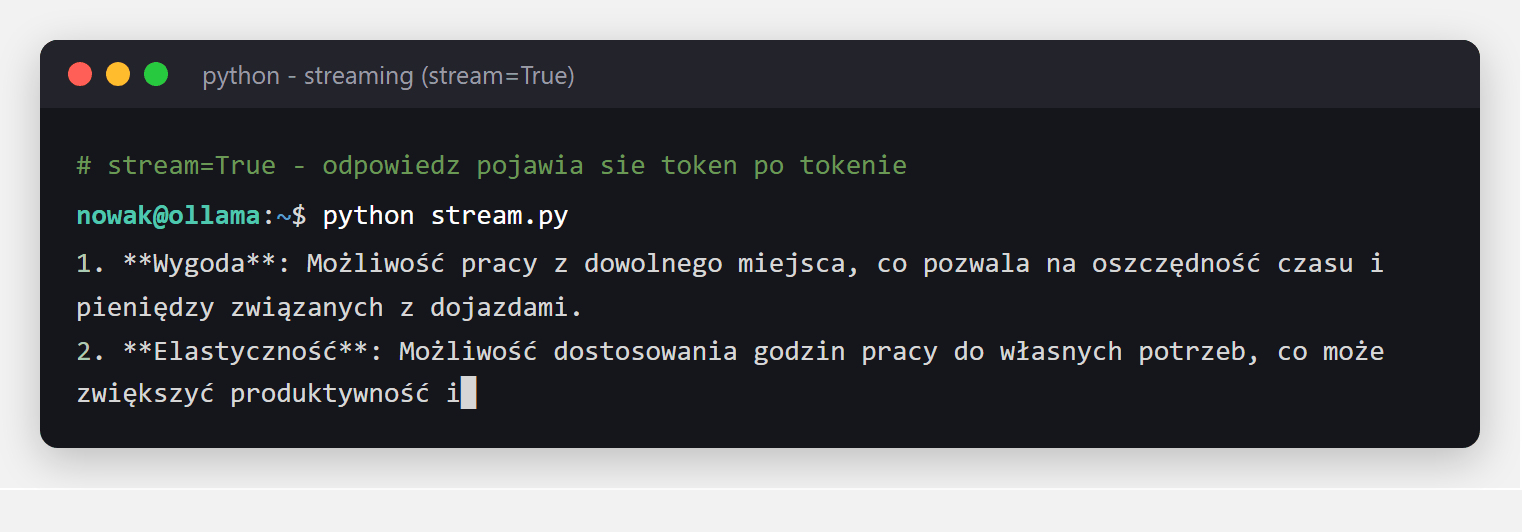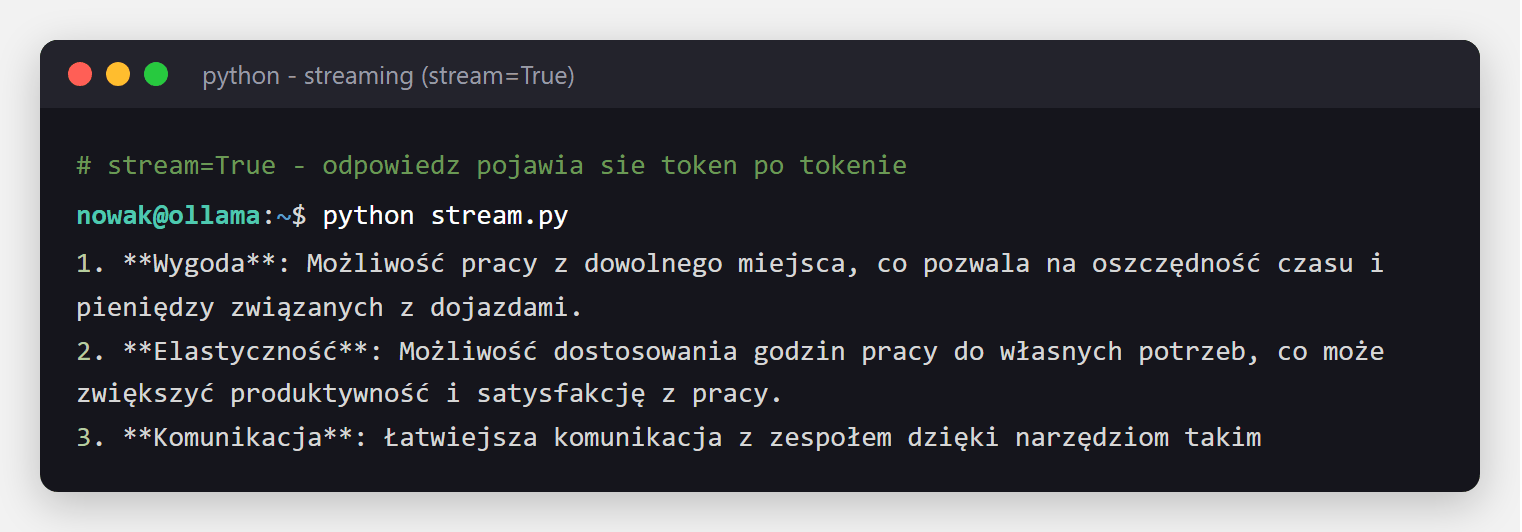
stream=True w praktyce: odpowiedź modelu dopisuje się na bieżąco, token po tokenie, zamiast pojawić się dopiero po wygenerowaniu całości. Użytkownik widzi pierwsze słowa od razu - dokładnie jak w ChatGPT, tylko lokalnie (tu polski Bielik).const res = await fetch("http://localhost:11434/api/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: "qwen2.5:3b",
messages: [{ role: "user", content: "Podaj 2 zastosowania lokalnych LLM w firmie." }],
stream: false,
}),
});
const data = await res.json();
console.log(data.message.content);temperature - losowość (0 = przewidywalnie, faktograficznie; 0.7+ = kreatywnie).num_ctx - długość kontekstu w tokenach. Większy = model „pamięta" więcej, ale zużywa więcej RAM.num_predict - maksymalna długość odpowiedzi. Przydatne, by ograniczyć czas i koszt.keep_alive - jak długo trzymać model w pamięci po zapytaniu. Domyślnie "5m". Ustaw -1 by nigdy nie wyładowywać, 0 by zwolnić RAM natychmiast po odpowiedzi. Można ustawić w ciele API, zmiennej środowiskowej lub Modelfile — szczegóły w sekcji o ollama ps powyżej.seed - ustaw stałą wartość, by uzyskać powtarzalne odpowiedzi (testy).W praktyce parametry liczbowe podajesz w obiekcie options w ciele zapytania (payload), a keep_alive, stream i format jako pola na najwyższym poziomie. Poniżej to samo zapytanie z kompletem opcji - faktograficznie (temperature: 0), z większym kontekstem, krótszą odpowiedzią i stałym ziarnem dla powtarzalności:
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "Wymien w jednym zdaniu trzy zalety lokalnego AI.",
"stream": false,
"keep_alive": "10m",
"options": {
"temperature": 0,
"num_ctx": 8192,
"num_predict": 120,
"seed": 42
}
}'Ten sam options przekażesz też w bibliotece ollama (argument options=...) oraz na endpoincie /api/chat - parametry działają identycznie.
Oryginalne wagi modelu to liczby 16-bitowe. Kwantyzacja zaokrągla je do mniejszej precyzji (np. 4-bitowej - oznaczenie Q4), przez co model zajmuje 3-4× mniej pamięci i liczy szybciej, tracąc minimalnie na jakości. Dla większości zastosowań Q4_K_M to złoty środek. Chcesz wyższej jakości i masz RAM - bierz Q8. Domyślne tagi w Ollamie (np. qwen2.5:3b) to zwykle Q4.
Jak samemu wybrać kwantyzację? Wskazujesz ją tagiem po dwukropku przy pobieraniu - np. ollama pull qwen2.5:7b-instruct-q4_K_M dla wariantu Q4 albo ...-q8_0 dla Q8. Ten sam model w różnych kwantyzacjach to różny rozmiar pliku i inne zużycie pamięci.
Skąd wiesz, jakie tagi ma dany model? Pełną listę wariantów znajdziesz na stronie modelu w katalogu Ollamy, w zakładce Tags - np. ollama.com/library/qwen2.5/tags wylistuje wszystkie kwantyzacje razem z rozmiarem. Szczegóły modelu, który już masz na dysku (kwantyzacja, liczba parametrów, długość kontekstu), pokaże komenda ollama show nazwa_modelu. Dla modeli w formacie GGUF z Hugging Face analogiczną listę - każdy plik .gguf to jedna kwantyzacja - znajdziesz w zakładce Files danego repozytorium.
Poniżej pobraliśmy ten sam mały model 0.5B w dwóch wariantach - widać różnicę w kolumnie SIZE:
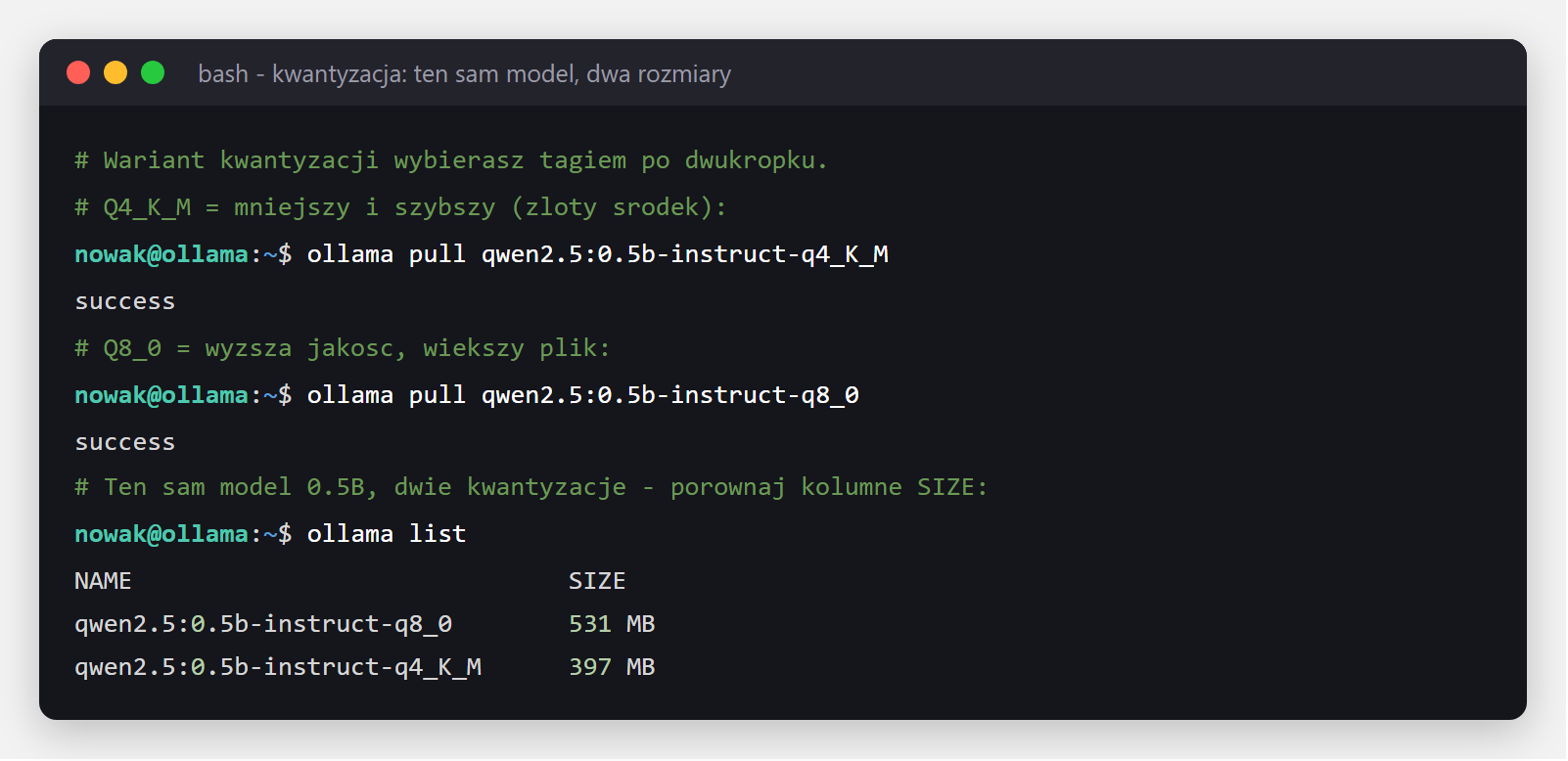
qwen2.5:0.5b pobrany w dwóch kwantyzacjach: q4_K_M waży 397 MB, a q8_0 - 531 MB. Mocniejsza kwantyzacja (Q8) to wyższa jakość kosztem rozmiaru i pamięci.Do automatyzacji bezcenne: każ modelowi zwracać poprawny JSON parametrem format. Koniec z parsowaniem luźnego tekstu:
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:3b",
"prompt": "Wyodrebnij dane z: Jan Kowalski, NIP 1234563218, kwota 1500 zl. Zwroc JSON z polami imie, nip, kwota.",
"format": "json",
"stream": false
}' W odpowiedzi pole response jest już czystym JSON-em - gotowym do json.loads(), zapisania w bazie albo przekazania dalej w procesie, bez parsowania luźnego tekstu:
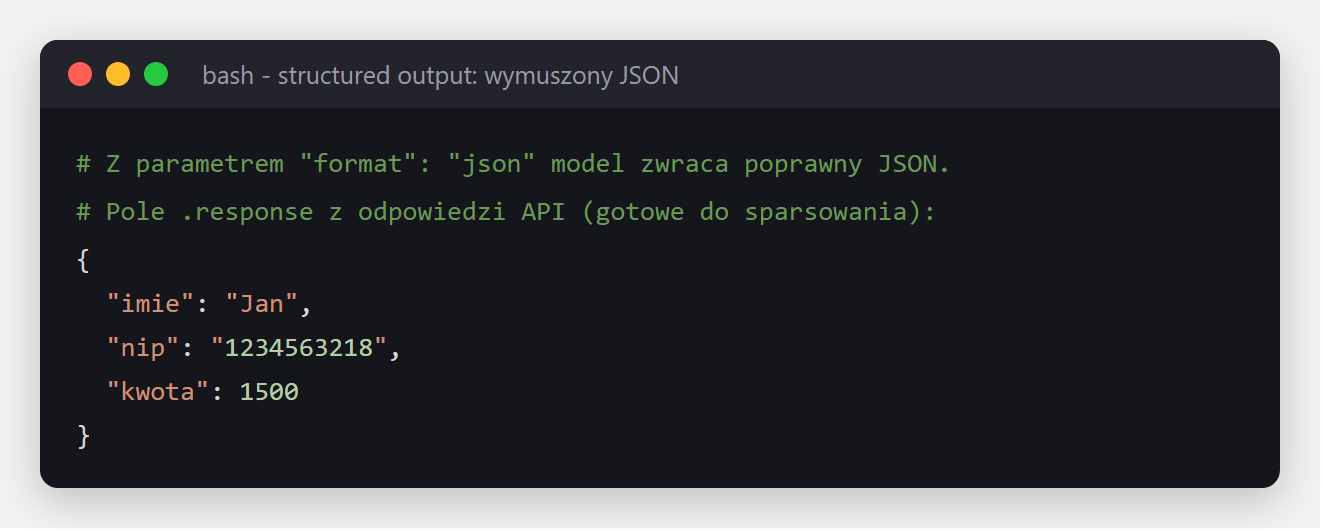
"format": "json" - model wyodrębnił dane do gotowej struktury (imie, nip, kwota). Zamiast zgadywać, gdzie w tekście jest NIP, dostajesz pole do odczytania.Poza oficjalnym rejestrem możesz uruchomić niemal każdy model w formacie GGUF z Hugging Face - bezpośrednio przez Ollamę, podając ścieżkę hf.co/użytkownik/repozytorium. Tak właśnie pobraliśmy polskiego Bielika, którego użyliśmy w przykładach wyżej:
ollama run hf.co/speakleash/Bielik-1.5B-v3.0-Instruct-GGUFMożesz dopisać konkretny wariant kwantyzacji po dwukropku (np. :Q4_K_M), jeśli repozytorium go udostępnia. To otwiera dostęp do tysięcy modeli społeczności - w tym wyspecjalizowanych i lokalnojęzycznych, jak Bielik czy modele z polskiego projektu PLLuM.
Gdzie przeglądać dostępne modele? Wejdź na Hugging Face i odfiltruj modele po formacie GGUF: huggingface.co/models?library=gguf (możesz dodatkowo sortować po popularności i pobraniach). Na karcie wybranego modelu kliknij przycisk „Use this model" i wybierz Ollama - Hugging Face wygeneruje gotową komendę ollama run hf.co/... do skopiowania. Dla polskich modeli warto też zajrzeć na profil SpeakLeash (Bielik) i PLLuM.
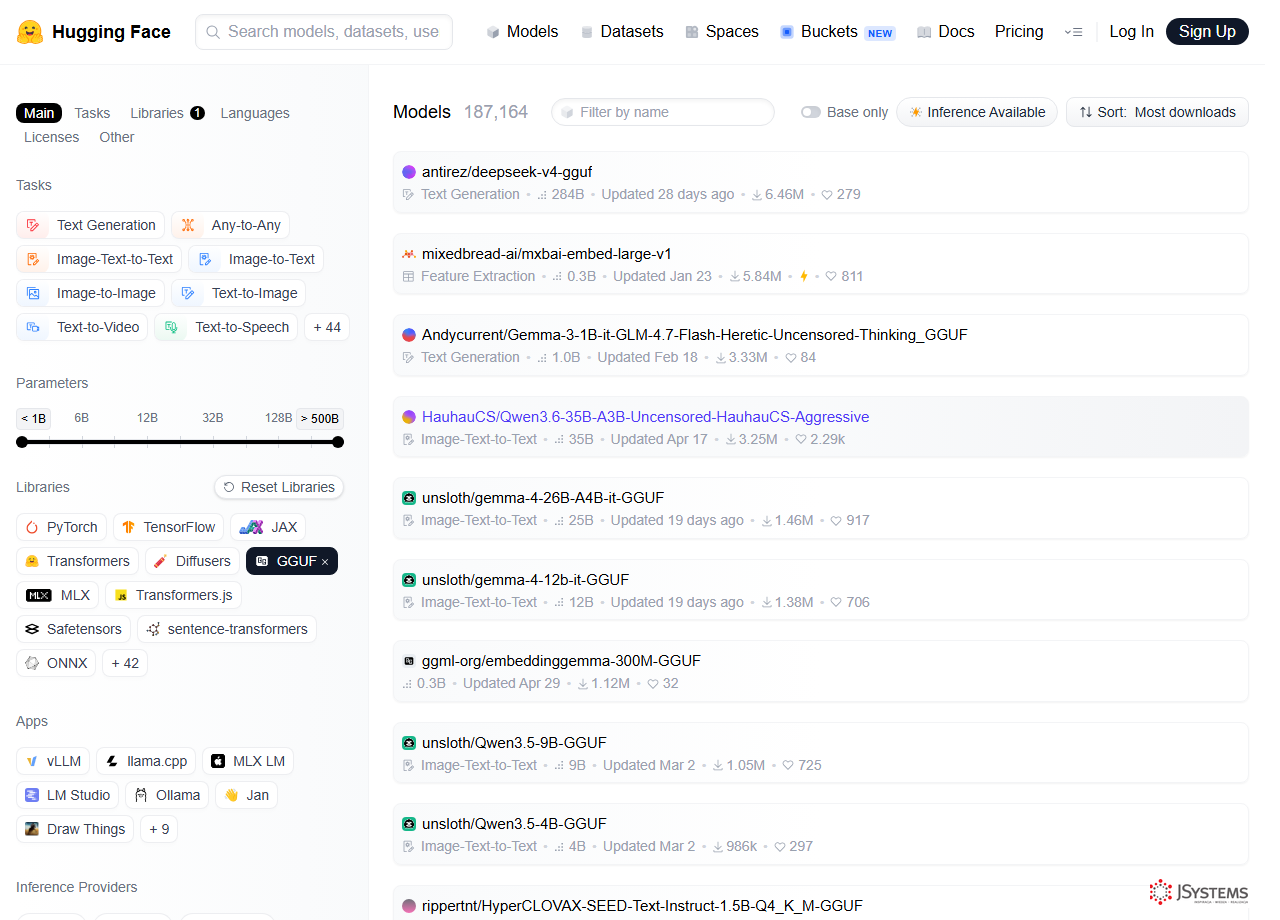
library=gguf - lista modeli w formacie gotowym dla Ollamy, posortowana po liczbie pobrań. Po lewej zawężasz wyniki (zadanie, rozmiar, biblioteka).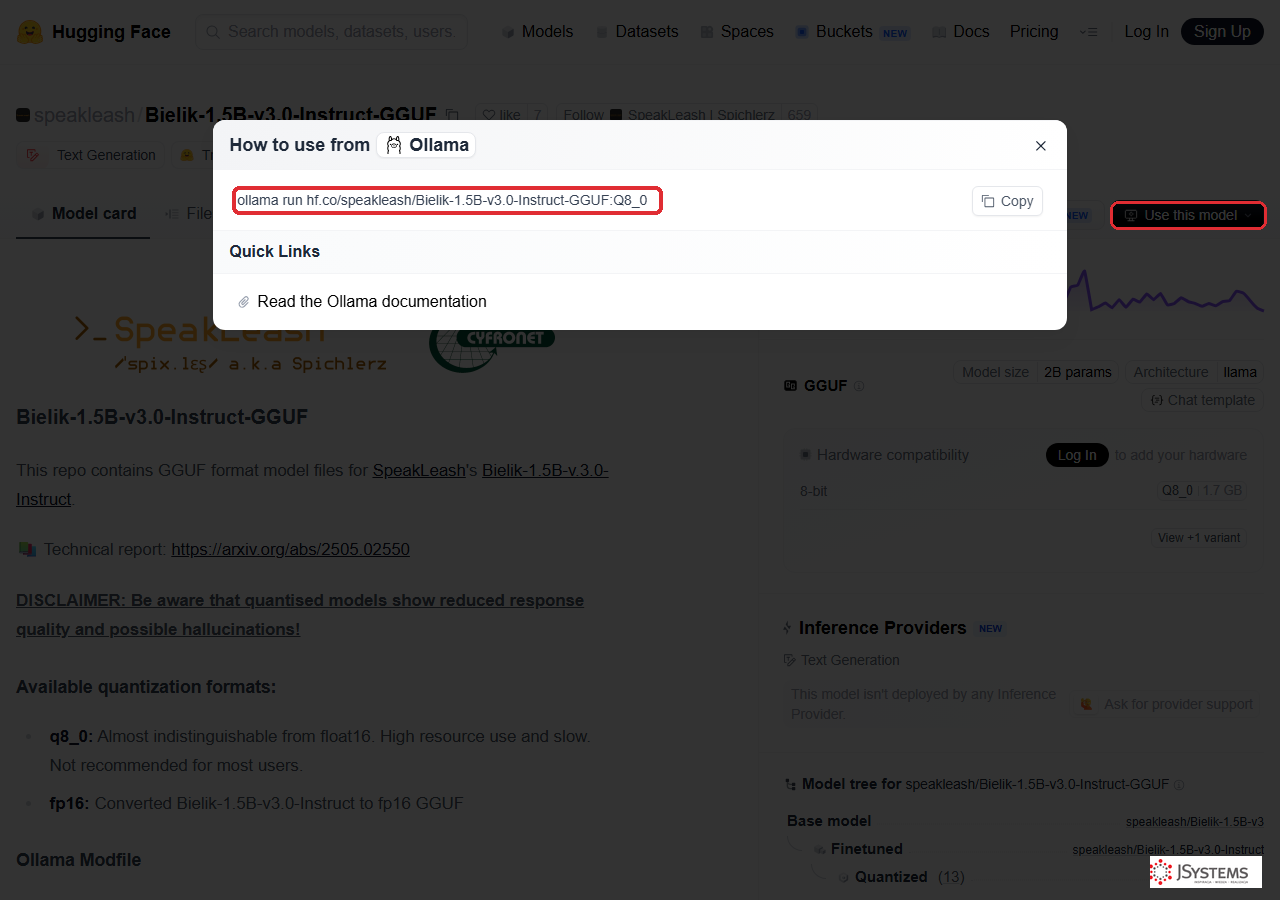
ollama run hf.co/... z przyciskiem Copy. Wklejasz ją w terminal i model się pobiera.Bezpieczeństwo - nie wystawiaj Ollamy do internetu
Domyślnie Ollama słucha tylko lokalnie (127.0.0.1) i nie ma uwierzytelniania. Jeśli ustawisz OLLAMA_HOST=0.0.0.0, żeby udostępnić ją w sieci - zrób to wyłącznie w zaufanej sieci wewnętrznej albo za reverse-proxy z autoryzacją (np. nginx + token). Otwarte API w internecie to zaproszenie do darmowego wykorzystania Twojego sprzętu.
Na koniec coś, co realnie przyda Ci się codziennie, jeśli programujesz: skrypt, który czyta Twoje zmiany w gicie i lokalnym modelem pisze za Ciebie sensowny opis commita. Zero kosztów, działa offline, a Twój kod nie wychodzi z komputera.
Warunek wstępny: masz Ollamę i model do kodu:
ollama pull qwen2.5-coder:1.5bZapisz poniższy skrypt jako commit_ai.py:
#!/usr/bin/env python3
# commit_ai.py - opis commita z "git diff --staged" LOKALNIE przez Ollame.
import subprocess, requests, sys
diff = subprocess.run(["git", "diff", "--staged"], capture_output=True, text=True).stdout
if not diff.strip():
sys.exit("Brak zmian w staging. Najpierw: git add <pliki>")
prompt = f"""Napisz komunikat commita w stylu Conventional Commits, po polsku.
Pierwsza linia: <typ>: <zwiezly opis> (typ: feat, fix, docs, refactor, chore).
Potem pusta linia i 1-3 punkty z detalami. Oto zmiany:
{diff[:4000]}"""
r = requests.post("http://localhost:11434/api/generate", json={
"model": "qwen2.5-coder:1.5b", "prompt": prompt,
"stream": False, "options": {"temperature": 0.2, "num_predict": 160},
})
print(r.json()["response"].strip())Używasz tak - dodajesz pliki do commita i odpalasz skrypt:
git add .
python commit_ai.py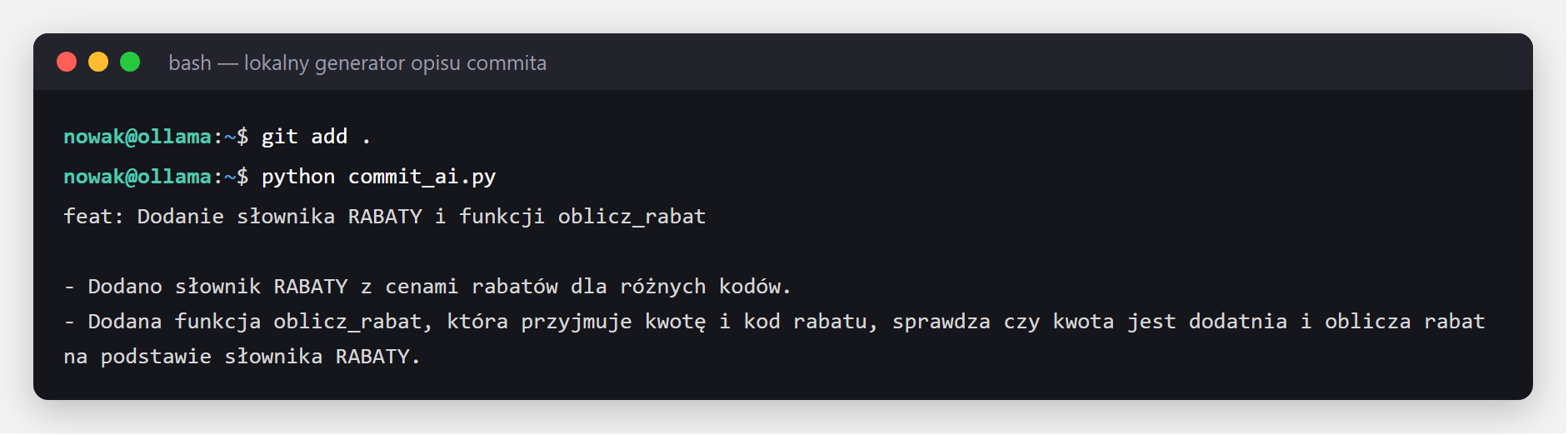
git diff --staged i lokalnym modelem wygenerował gotowy opis commita w stylu Conventional Commits - w sekundy, bez wysyłania kodu gdziekolwiek.Bonus: jednolinijkowy asystent w terminalu
Dorzuć do ~/.bashrc funkcję i pytaj AI z dowolnego miejsca w terminalu komendą ai "twoje pytanie":
ai() { ollama run llama3.2:1b "$*"; }Tak, Ollama jest open source (licencja MIT) i całkowicie bezpłatna. Modele też pobierasz za darmo. Jedyny koszt to Twój sprzęt i prąd - zero opłat za token, zero subskrypcji.
Mały model (1-8B) nie dorówna najlepszym modelom z chmury jakością, ale do wielu zadań (streszczenia, klasyfikacja, odpowiedzi na maile, prosty kod) jest w zupełności wystarczający. Duże modele lokalne (70B) na mocnym sprzęcie potrafią zbliżyć się do chmury. Wybór modelu zależy od zadania - nie zawsze potrzebujesz najmocniejszego.
Modele 1-3B ruszą na zwykłym laptopie z 8 GB RAM (na CPU, wolniej). Dla modeli 7-8B wygodnie mieć 16 GB RAM albo dedykowaną kartę graficzną z własnym VRAM - osobną kartę NVIDIA GeForce RTX (np. RTX 3060/4060 z 8-12 GB VRAM), a nie zintegrowaną grafikę laptopa, która do LLM się nie nadaje. Bardzo dobrze radzi sobie też Apple Silicon (M1-M4). Reguła: tyle GB pamięci, ile miliardów parametrów ma model w kwantyzacji Q4.
Sama Ollama - tak (MIT). Ale każdy model ma własną licencję - sprawdź ją komendą ollama show. Część modeli (np. niektóre Qwen Research) ma ograniczenia komercyjne, podczas gdy Llama, Mistral czy Gemma mają licencje przyjazne biznesowi. Zawsze zweryfikuj licencję konkretnego modelu.
Tak - po pobraniu modelu cała inferencja dzieje się lokalnie. Możesz odłączyć internet i Ollama dalej działa. To kluczowa przewaga przy danych wrażliwych, RODO i tajemnicy przedsiębiorstwa.
Chcesz wykorzystać lokalne modele w praktyce - zbudować z nich agenta albo wpiąć je w automatyzację firmy? Sprawdź nasze szkolenia z terminem gwarantowanym:


Komentarze (0)
Brak komentarzy...