
Claude subagenci i orchestration - jak budować zespoły agentów AI
Jeden agent AI jest dobry. Pięciu specjalistycznych agentów pracujących równolegle jest niepokonanych. Właśnie tak działają najlepsze systemy AI w 2026 roku - i tak samo możesz zbudować swój.
Czego się nauczysz z tego artykułu:
Pojedynczy agent AI ma ograniczenia: jeden kontekst, jedno zadanie na raz, jedna specjalizacja. Gdy projekt jest złożony - potrzebujesz zespołu.
Multi-agent systems pozwalają podzielić pracę między wyspecjalizowanych agentów koordynowanych przez orchestratora. To jest zaawansowane użycie Claude - i to właśnie robi różnicę między projektem hobbystycznym a produkcyjnym systemem AI.
Zanim zaczniesz - co powinieneś wiedzieć
Ten artykuł dotyczy zaawansowanych wzorców architektury AI. Zaleca się najpierw przeczytać artykuł o Claude API (lekcja 07) i zrozumieć podstawy wywołania API. Potrzebujesz:
- Podstaw Python (funkcje, klasy, asyncio)
- Wiedzy o tym czym jest API i jak działa Claude API
- Ogólnego pojęcia o programowaniu asynchronicznym (wyjaśniamy poniżej)
Najprostszy sposób: subagent przez prompt
Zanim przejdziemy do kodu - Claude Code potrafi uruchamiać subagentów bez pisania ani jednej linii kodu. Wystarczy napisać w prompcie co ma zrobić:
Claude sam uruchamia subagentów, czeka na wyniki i syntetyzuje odpowiedź - zero konfiguracji. Gdy potrzebujesz pełnej kontroli (logi, retry, integracje z systemami), sięgasz po API. Tym zajmujemy się poniżej.
Co to jest orchestration? (Menedżer i zespół)
Orchestration (z ang. "dyrygowanie") to pattern architektoniczny gdzie jeden komponent (orchestrator) koordynuje pracę wielu innych komponentów (agentów, serwisów, funkcji). Orchestrator wie co trzeba zrobić, deleguje zadania i zbiera wyniki.
Analogia: Menedżer projektu i specjaliści
Wyobraź sobie firmę budowlaną. Kierownik projektu (orchestrator) dostaje zlecenie: "wybuduj dom". Nie robi wszystkiego sam - dzwoni do elektryka, hydraulika i murarza (subagenci). Każdy jest ekspertem w swojej dziedzinie. Pracują równolegle (elektryk i hydraulik mogą robić swoje jednocześnie). Kierownik zbiera wyniki i podejmuje finalne decyzje. Tak samo działa orchestration w AI: jeden Claude-orchestrator koordynuje pracą wielu Claude-subagentów.
Dlaczego to ważne dla programisty? Kiedy piszesz "zrób code review całego projektu" do jednego agenta - ma on limit kontekstu (nie zmieści 100 plików). Ale orchestrator może wysłać każdy folder do osobnego subagenta, który analizuje tylko swój fragment, a orchestrator zbiera wyniki. Skala i jakość niedostępna dla jednego agenta.
Czym są subagenci w Claude Code
Claude Code posiada wbudowane narzędzie Task - pozwala agentowi "spawnować" subagentów którzy wykonują zadania równolegle lub sekwencjalnie. Spawning to tworzenie nowej instancji procesu - tu: nowej sesji Claude ze swoim własnym kontekstem. Orchestrator (główny agent) planuje pracę, subagenci ją wykonują, orchestrator agreguje wyniki.
Poniżej widzisz jak orchestrator deleguje trzy niezależne zadania jednocześnie. Zanim przejdziesz do kodu - kluczowe pojęcie:
# Orchestrator widzi to narzędzie:
# Tool: Task
# Description: Uruchom subagenta który wykona określone zadanie
# Parameters:
# description: opis zadania dla subagenta (krótkie podsumowanie)
# prompt: szczegółowe instrukcje (co subagent ma zrobić krok po kroku)
# Orchestrator może uruchomić wiele subagentów RÓWNOLEGLE
# Każdy ma osobny kontekst - nie widzą swoich nawzajem wyników!
Task("Przeanalizuj moduł auth", "Sprawdź testy bezpieczeństwa w src/auth/")
Task("Przeanalizuj moduł payments", "Sprawdź obsługę błędów w src/payments/")
Task("Przeanalizuj moduł users", "Sprawdź walidację w src/users/")
# Wszystkie trzy działają równolegle! Czas = max(auth_time, payments_time, users_time)
# zamiast auth_time + payments_time + users_timePo uruchomieniu powyższego kodu orchestrator "czeka" aż wszystkie trzy analizy wrócą, a następnie może je połączyć w jedno podsumowanie. Sprawdź że każdy agent coś zwrócił zanim użyjesz wyników.
asyncio - programowanie asynchroniczne dla początkujących
Kluczowe słowa kluczowe asyncio - co każde z nich robi:
async def- "ta funkcja może być wstrzymana i wznowiona". Jak zawieszenie rozmowy telefonicznej żeby odebrać drugie połączenie.await- "czekaj na ten wynik, ale nie blokuj całego programu". Jak zlecenie zadania i przejście do następnej rzeczy.asyncio.gather(*tasks)- "uruchom wszystkie naraz i czekaj aż każde skończy". Jak fork-join: rozwidlasz na wiele ścieżek, czekasz aż każda dojdzie do końca, zbierasz wyniki.
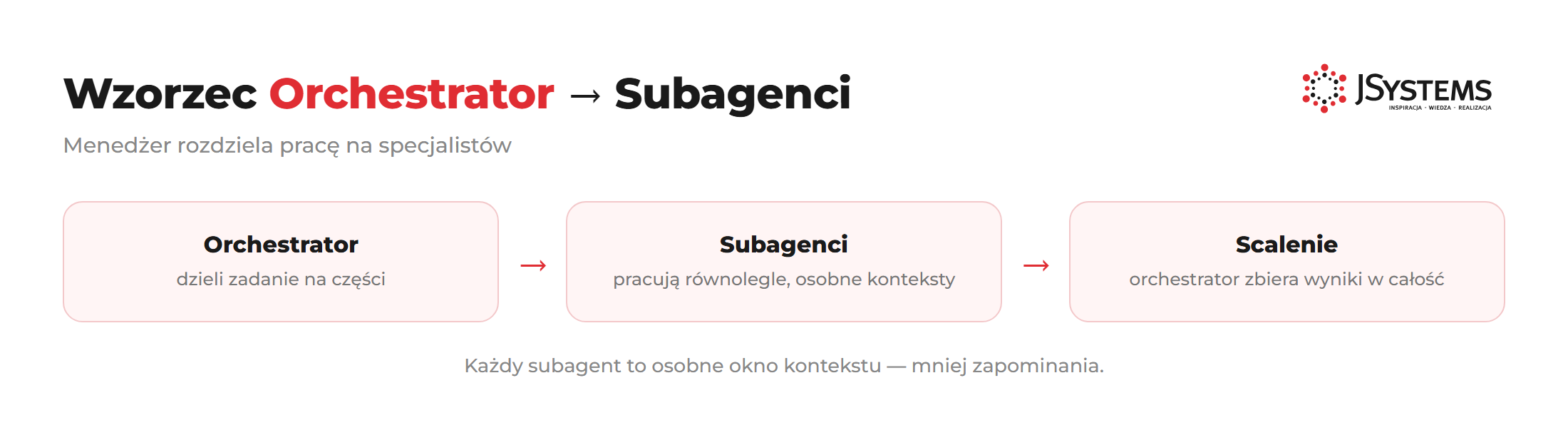
Wzorzec Orchestrator --> Subagenci - krok po kroku
Poniższy przykład pokazuje orchestrator który uruchamia 4 subagentów do code review - każdy specjalizuje się w innym aspekcie, wszystkie działają równolegle. Przejdźmy przez to krok po kroku.
Krok 1: Definiujemy funkcję subagenta - to "szablon" dla każdego specjalisty. Każdy subagent dostaje własny task_description który kształtuje jego specjalizację i context czyli materiał do analizy.
Krok 2: Tworzymy listę 4 zadań - każde dla innego "specjalisty". Żadne jeszcze nie startuje, to tylko plany.
Krok 3: asyncio.gather(*tasks) startuje wszystkie 4 jednocześnie i czeka aż każdy skończy. Program wstrzymuje się w tym miejscu.
Krok 4: Orchestrator (tym razem droższy model) dostaje 4 niezależne wyniki i scala je w jedno, spójne podsumowanie.
import anthropic
import asyncio # Biblioteka do programowania asynchronicznego
client = anthropic.Anthropic()
# KROK 1: Szablon subagenta
# "async def" = funkcja asynchroniczna - może być wstrzymana podczas oczekiwania
async def run_subagent(task_description: str, context: str) -> str:
"""Uruchom subagenta dla konkretnego zadania"""
# Każdy subagent to osobne wywołanie API - osobny kontekst, osobna "głowica"
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
# System prompt definiuje specjalizację subagenta
system=f"""Jesteś wyspecjalizowanym agentem do: {task_description}.
Wykonaj zadanie i zwróć wynik w formacie JSON.""",
messages=[{"role": "user", "content": context}]
)
return response.content[0].text
async def orchestrate_code_review(pr_diff: str):
"""Orchestrator który uruchamia równoległe code review"""
# KROK 2: Lista zadań - 4 specjaliści, każdy skupiony na czymś innym
tasks = [
run_subagent("analiza bezpieczeństwa", pr_diff), # Szuka podatności
run_subagent("analiza wydajności", pr_diff), # Szuka bottlenecków
run_subagent("analiza zgodności z konwencjami", pr_diff), # Sprawdza styl kodu
run_subagent("analiza pokrycia testami", pr_diff), # Sprawdza czy testy wystarczają
]
# KROK 3: asyncio.gather(*tasks) = "uruchom wszystkie równolegle, czekaj aż skończą"
# To jak otwarcie 4 zakładek w przeglądarce jednocześnie zamiast po kolei
results = await asyncio.gather(*tasks)
# KROK 4: Orchestrator dostaje 4 niezależne analizy i scala je w jedno
# Tu używamy droższego modelu (Opus) bo to ważniejsze zadanie syntezy
aggregation_prompt = f"""
Masz 4 niezależne analizy tego samego PR:
1. Bezpieczeństwo: {results[0]}
2. Wydajność: {results[1]}
3. Konwencje: {results[2]}
4. Testy: {results[3]}
Stwórz spójne podsumowanie code review z priorytetyzowanymi uwagami.
"""
final = client.messages.create(
# Orchestrator może być droższym/mądrzejszym modelem bo robi trudniejszą syntezę
model="claude-opus-4-7",
max_tokens=1024,
messages=[{"role": "user", "content": aggregation_prompt}]
)
return final.content[0].text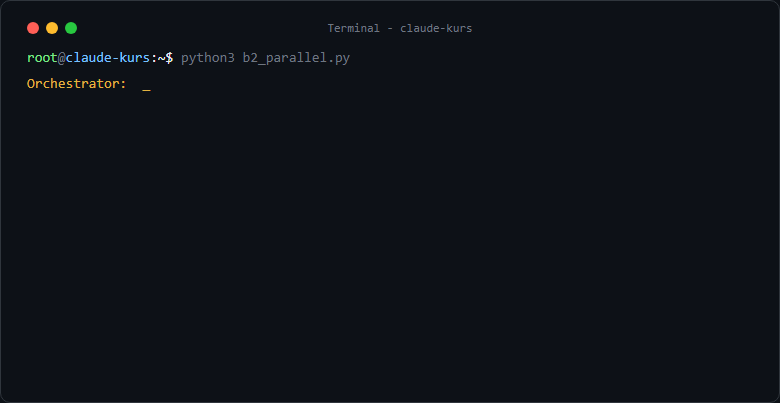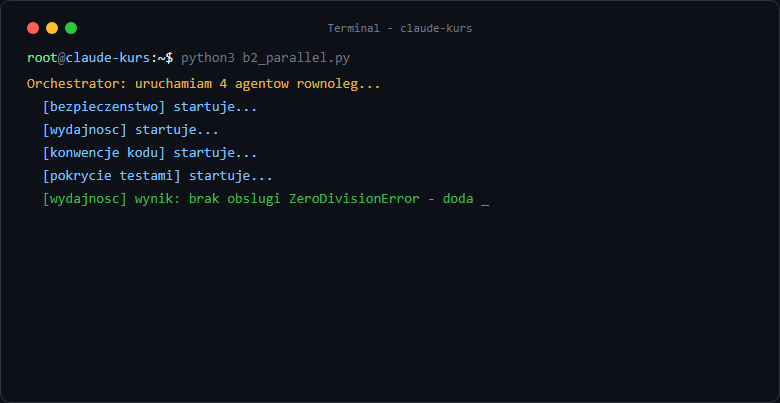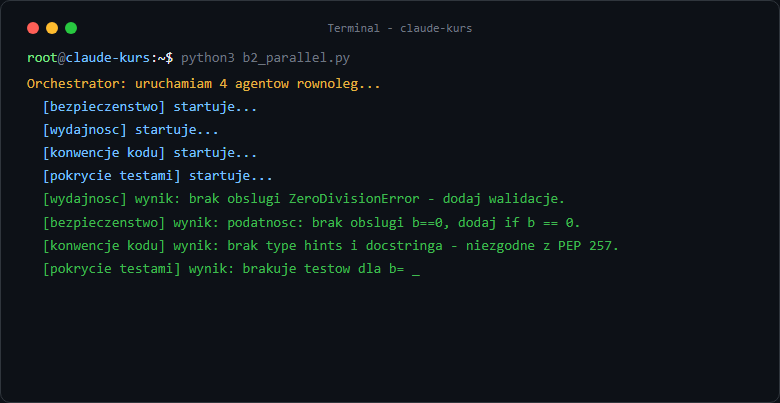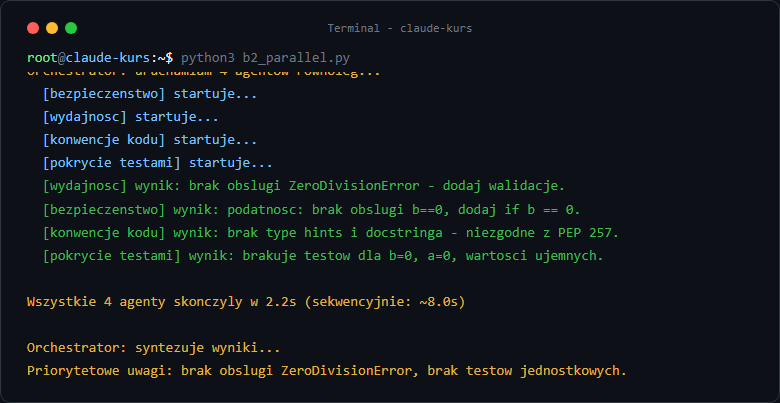
Po uruchomieniu: terminal na chwilę "milknie" - to normalne, 4 agenty pracują równolegle. Po kilku sekundach dostaniesz scalony wynik. Możesz dodać print(f"Agent {i} skończył") po gather żeby potwierdzić że wszystkie 4 wyniki wróciły.
Chcesz budować takie systemy na żywo, z instruktorem?
Szkolenie Claude Code - 3 dni: podstawy, narzędzia, multi-agent systems. Gwarantowane terminy szkolenia.
Sprawdź termin szkolenia -->Wzorzec Specialist Agents - wyspecjalizowane role
Zamiast jednego generalista - kilku specjalistów. Każdy agent dostaje inny system prompt który definiuje jego rolę i "osobowość". Pipeline: jeden po drugim przekazuje sobie wyniki.
Krok 1: Definiujemy słownik specjalistów - każdy ma własny system prompt i wybrany model.
Krok 2: Funkcja run_agent pobiera konfigurację i wywołuje API.
Krok 3: Pipeline sekwencyjny - coder pisze kod, reviewer go ocenia, documenter dokumentuje tylko gdy kod przeszedł review.
# KROK 1: Słownik z konfiguracją każdego specjalisty
AGENTS = {
"coder": {
"system": "Jesteś senior Python developer. Piszesz czysty, testowany kod.",
"model": "claude-sonnet-4-6" # Pełnowymiarowy model dla pisania kodu
},
"reviewer": {
"system": "Jesteś security engineer. Szukasz podatności i błędów bezpieczeństwa.",
"model": "claude-sonnet-4-6"
},
"documenter": {
"system": "Piszesz zwięzłą dokumentację techniczną. Skupiasz się na 'dlaczego', nie 'co'.",
"model": "claude-haiku-4-5" # Tańszy model wystarczy dla prostszego zadania dokumentacji
}
}
# KROK 2: Funkcja uruchamiająca konkretnego specjalistę
def run_agent(agent_name: str, task: str) -> str:
"""Uruchom konkretnego agenta-specjalistę"""
config = AGENTS[agent_name] # Pobieramy konfigurację specjalisty
response = client.messages.create(
model=config["model"], # Każdy specjalista może używać innego modelu
max_tokens=1024,
system=config["system"], # System prompt definiuje specjalizację
messages=[{"role": "user", "content": task}]
)
return response.content[0].text
# KROK 3: Pipeline sekwencyjny - coder -> reviewer -> documenter
# Każdy kolejny agent dostaje wynik poprzedniego
code = run_agent("coder", f"Zaimplementuj: {feature_description}")
review = run_agent("reviewer", f"Sprawdź bezpieczeństwo: {code}")
# Warunek: dokumentujemy tylko jeśli kod przeszedł security review
if "PASS" in review:
docs = run_agent("documenter", f"Udokumentuj: {code}")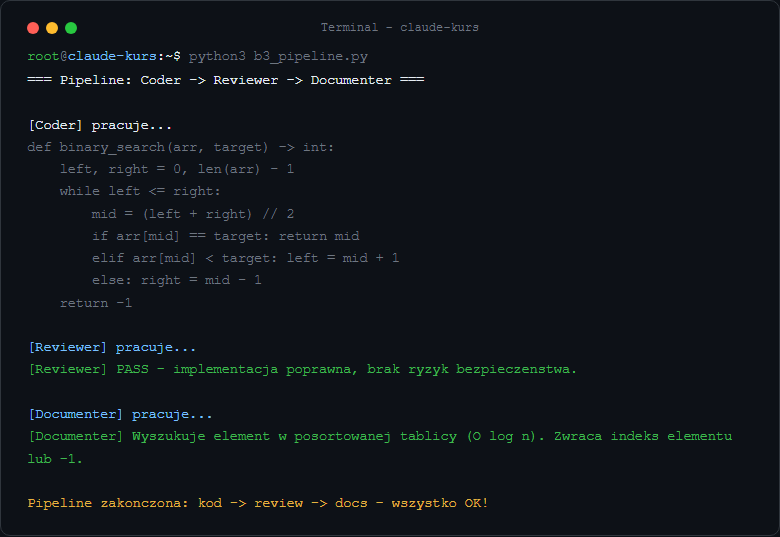
Jeśli chcesz sprawdzić że pipeline działa: dodaj print(f"Coder zwrócił {len(code)} znaków") po pierwszym wywołaniu. Reviewer powinien zwrócić tekst zawierający "PASS" lub "FAIL" - możesz wydrukować review[:100] żeby zobaczyć początek odpowiedzi.
Wzorzec Reflection - agent ocenia własną pracę
Reflection to wzorzec gdzie agent ocenia i poprawia własny output w pętli, zanim przekaże wynik dalej. Działa jak "przeczyj swój tekst zanim wyślesz".
Krok 1: Agent wykonuje pierwsze rozwiązanie.
Krok 2: Drugi agent (lub ten sam z innym promptem) ocenia wynik - zwraca ACCEPTED lub REJECTED z powodem.
Krok 3: Jeśli REJECTED - poprawiamy z uwzględnieniem krytyki. Maksymalnie max_iterations razy, żeby uniknąć nieskończonej pętli.
def agent_with_reflection(task: str, max_iterations: int = 3) -> str:
# KROK 1: Pierwsza próba - generujemy rozwiązanie
result = run_agent("coder", task)
# Pętla refleksji - maksymalnie max_iterations razy
for i in range(max_iterations):
# KROK 2: Drugi agent ocenia wynik
critique = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=512,
messages=[{
"role": "user",
"content": f"""Oceń czy ten kod rozwiązuje problem poprawnie.
Problem: {task}
Rozwiązanie: {result}
Odpowiedz: ACCEPTED jeśli rozwiązanie jest dobre,
lub REJECTED: [powód] jeśli wymaga poprawy."""
}]
).content[0].text
# Jeśli ocena pozytywna - wychodzimy z pętli, zwracamy wynik
if "ACCEPTED" in critique:
break
# KROK 3: Jeśli ocena negatywna - poprawiamy na podstawie krytyki
result = run_agent("coder", f"{task}\n\nPoprzednie rozwiązanie miało problemy: {critique}\nPopraw je.")
return result # Zwracamy ostatni zaakceptowany lub najlepszy wynik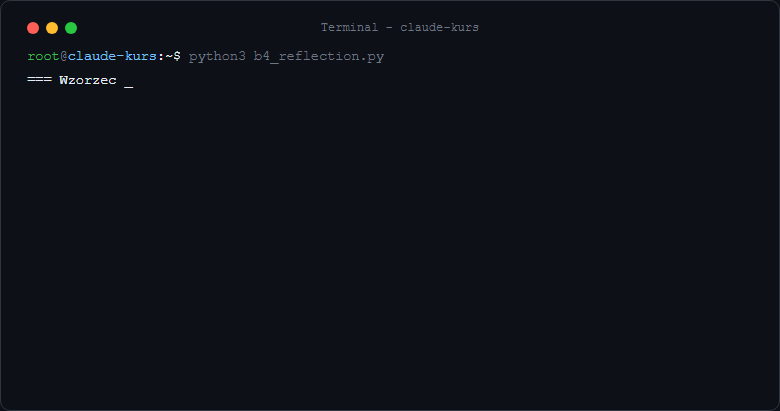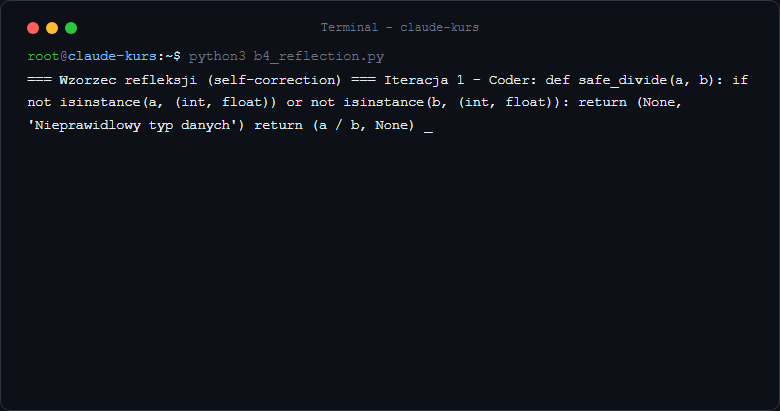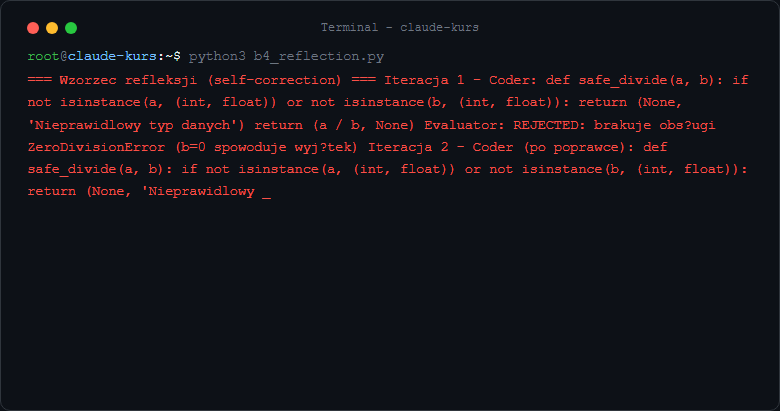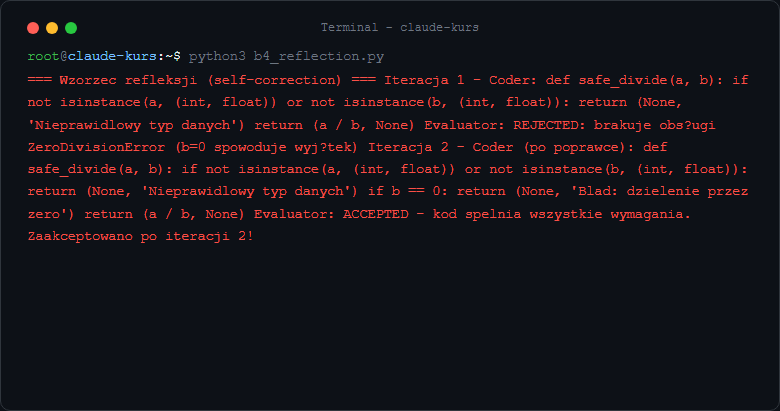
Jak sprawdzić że reflection działa? Dodaj print(f"Iteracja {i}: {critique[:50]}") wewnątrz pętli - zobaczysz jak agent uczy się z poprzednich błędów.

Kiedy używać multi-agent, kiedy single agent
Multi-agent to nie zawsze lepsze - każdy subagent to dodatkowy koszt tokenów i dodatkowa złożoność debugowania. Zasada: używaj multi-agent gdy korzyści (równoległość, specjalizacja) wyraźnie przeważają nad kosztami.
| Single Agent (jeden Claude) | Multi-Agent (orchestrator + subagenci) |
|---|---|
| Proste, liniowe zadanie ("popraw ten błąd") | Zadanie które można podzielić na niezależne części (analiza 50 plików) |
| Krótki kontekst wystarczy (jeden plik) | Każda część potrzebuje głębokiej specjalizacji (security vs. performance) |
| Mały budżet tokenów | Równoległość skraca czas (kosztem ceny - N agentów = N × koszt) |
| Debugowanie łatwiejsze (jeden log) | Zadanie wymaga niezależnej weryfikacji (coder + reviewer) |
Częste błędy początkujących z multi-agent
Błąd #1: Zakładanie że subagenci "się widzą"
Najczęstszy błąd: myślenie że subagent B automatycznie wie co zrobił subagent A. Każdy subagent ma osobny kontekst - jeśli nie przekażesz mu explicite wyników innych agentów, nie będzie o nich wiedział. Zawsze jawnie przekazuj wyniki przez orchestratora.
Jak to zrobić poprawnie - orchestrator jawnie przekazuje wyniki:
# ZLE - agent B nie wie co zrobil agent A:
result_a = run_subagent("agent-A", code)
result_b = run_subagent("agent-B", code) # brak kontekstu!
# DOBRZE - orchestrator jawnie przekazuje wyniki:
security = run_subagent("specjalista-bezpieczenstwo",
f"Przeanalizuj podatnosci w: {code}")
performance = run_subagent("specjalista-wydajnosc",
f"Przeanalizuj wydajnosc: {code}\n"
f"Kontekst od agenta-A: {security}\n"
f"Nie proponuj zmian ktore pogorsza bezpieczenstwo.")
final = run_subagent("orchestrator",
f"Polacz wyniki:\nBezpieczenstwo: {security}\nWydajnosc: {performance}")Orchestrator jest jedynym miejscem, które widzi wszystkie wyniki. Subagenci komunikują się wyłącznie przez niego, nigdy bezpośrednio ze sobą.
Błąd #2: Brak limitu iteracji w reflection loop
Reflection bez max_iterations może działać w nieskończoność - szczególnie gdy kryterium "ACCEPTED" jest zbyt wymagające. Zawsze ustaw górny limit i upewnij się że warunek wyjścia jest osiągalny.
Błąd #3: Budowanie multi-agent "bo fajnie"
Jeśli dodajesz drugi agent bez konkretnego problemu który rozwiązuje - to znak że nie potrzebujesz multi-agent. Dodatkowi agenci to dodatkowe koszty, dodatkowe punkty awarii i trudniejsze debugowanie. Zaczyn od jednego agenta, dodawaj kolejnych tylko gdy masz konkretny powód.
Pułapki multi-agent systems - czego unikać
- Context pollution - subagenci nie widzą swoich nawzajem wyników jeśli nie przekażesz explicite. Jeśli agent A znajdzie bug, agent B o tym nie wie - musisz sam przekazać tę informację w promptcie
- Koszty - N agentów = N × koszt tokenów. Przy 5 subagentach płacisz 5× więcej niż za jednego. Monitoruj zużycie
- Debugging - co gdy jeden subagent zawiedzie? Potrzebujesz logging każdego subagenta osobno i obsługi błędów na poziomie orchestratora
- Infinite loops - orchestrator i subagent mogą się wzajemnie "pingować" w nieskończoność. Zawsze ustaw
max_iterationsi warunek wyjścia
Złota zasada dla juniorów: Zacznij od jednego agenta. Dodaj drugiego tylko gdy widzisz konkretny problem który multi-agent rozwiązuje. Nie buduj wieloagentowego systemu "bo fajnie" - każdy dodatkowy agent to dodatkowa złożoność i koszt.
Opanujesz orchestration i multi-agent patterns - i nagle zadania które zajmowały godziny będą trwać minuty. Twój kod będzie robił więcej, szybciej i lepiej niż pojedynczy agent kiedykolwiek mógłby zaoferować. To jest przewaga której konkurencja nie ma.
4 zasady, które wdrożysz przy zespole agentów
Zespół agentów potrafi więcej niż jeden - ale tylko z tymi zasadami:
- Definiuj subagentów w
.claude/agents/. stwórz tam plik opisujący rolę (np. „reviewer”, „tester”) - Claude Code sam go wywoła, gdy zadanie pasuje. - Multi-agent tylko dla zadań niezależnych. kroki zależne od siebie rób jednym agentem. Równolegle puszczaj to, co naprawdę się nie przeplata.
- Wzorzec Reflection. każ drugiemu agentowi skrytykować pracę pierwszego przed zatwierdzeniem - jakość zauważalnie rośnie.
- Każdy subagent = osobny kontekst. rozdzielenie zadań odciąża główny kontekst i ogranicza „zapominanie” w długich sesjach.

Newsletter bloga JSystems
Otrzymuj każdą nową lekcję prosto na swoją skrzynkę
Nowe lekcje pojawiają się co poniedziałek i czwartek. Zapisz się do newslettera bloga JSystems - dostaniesz powiadomienie zaraz po publikacji każdej lekcji.
Szkolenie Claude Code - od podstaw do multi-agent systems
3 dni: dzień 1 = podstawy + CLAUDE.md, dzień 2 = MCP + narzędzia, dzień 3 = subagenci + orchestration. To jest zaawansowana wiedza której nie znajdziesz w dokumentacji. Termin gwarantowany.
Komentarze (0)
Brak komentarzy...