Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
9 czerwca 2026 roku Anthropic pokazał model, który wyłamuje się z dotychczasowego schematu. Zwykle nowa wersja jest „następcą” poprzedniej - Fable 5 został pozycjonowany o całą klasę wyżej niż Opus, w nowej rodzinie o nazwie Mythos. Na chwilę zniknął z dystrybucji (kontrole eksportu ze strony administracji USA), ale od 1 lipca 2026 jest znów dostępny - także na kontach abonamentowych. W tym artykule pokażemy, co ten model wnosi, jak wypada na benchmarkach i czym różni się od Opus 4.8. Wszystkie zrzuty pochodzą z naszego konta na claude.ai, z modelem ustawionym kolejno na Fable 5 i - dla porównania - Opus 4.8.
Do tej pory najmocniejsze modele Anthropic należały do klasy Opus. Fable 5 otwiera nową, wyższą klasę o nazwie Mythos. Ważne, żeby nie pomylić dwóch nazw, bo chodzi o ten sam „mózg” w dwóch wydaniach:
Zanim przejdziemy dalej, dwa pojęcia po polsku, bo będą wracać. Token to najmniejsza porcja tekstu, jaką przetwarza model - z grubsza kawałek słowa. Okno kontekstu to ilość tekstu, jaką model widzi naraz (im większe, tym więcej dokumentów, kodu czy historii rozmowy zmieści się w jednym zadaniu).
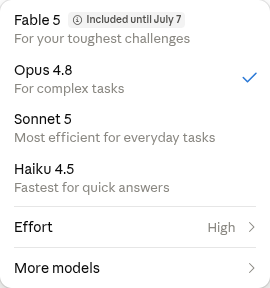
Na naszym koncie Fable 5 pojawia się w liście wyboru modeli, opisany jako „do Twoich najtrudniejszych wyzwań” - nad Opus 4.8 „do złożonych zadań”:
Od strony parametrów Fable 5 obsługuje okno kontekstu do 1 miliona tokenów i potrafi wygenerować w jednej odpowiedzi do 128 tysięcy tokenów. Przyjmuje tekst i obrazy (jest multimodalny). Ale najważniejsza zmiana nie kryje się w liczbach, tylko w tym, jak długo model potrafi pracować nad jednym zadaniem.
Chodzi o zadania agentowe o długim horyzoncie. To takie, w których model wykonuje wiele kroków po kolei, przez dłuższy czas, pilnując celu i wracając do wcześniejszych ustaleń. Anthropic podaje, że Fable „utrzymuje uwagę przez miliony tokenów” - potrafi prowadzić jedno długie, wieloetapowe zadanie bez gubienia wcześniejszych ustaleń, od pierwszego kroku aż po gotowy wynik.
Kilka innych obszarów, w których model pokazuje pazur:
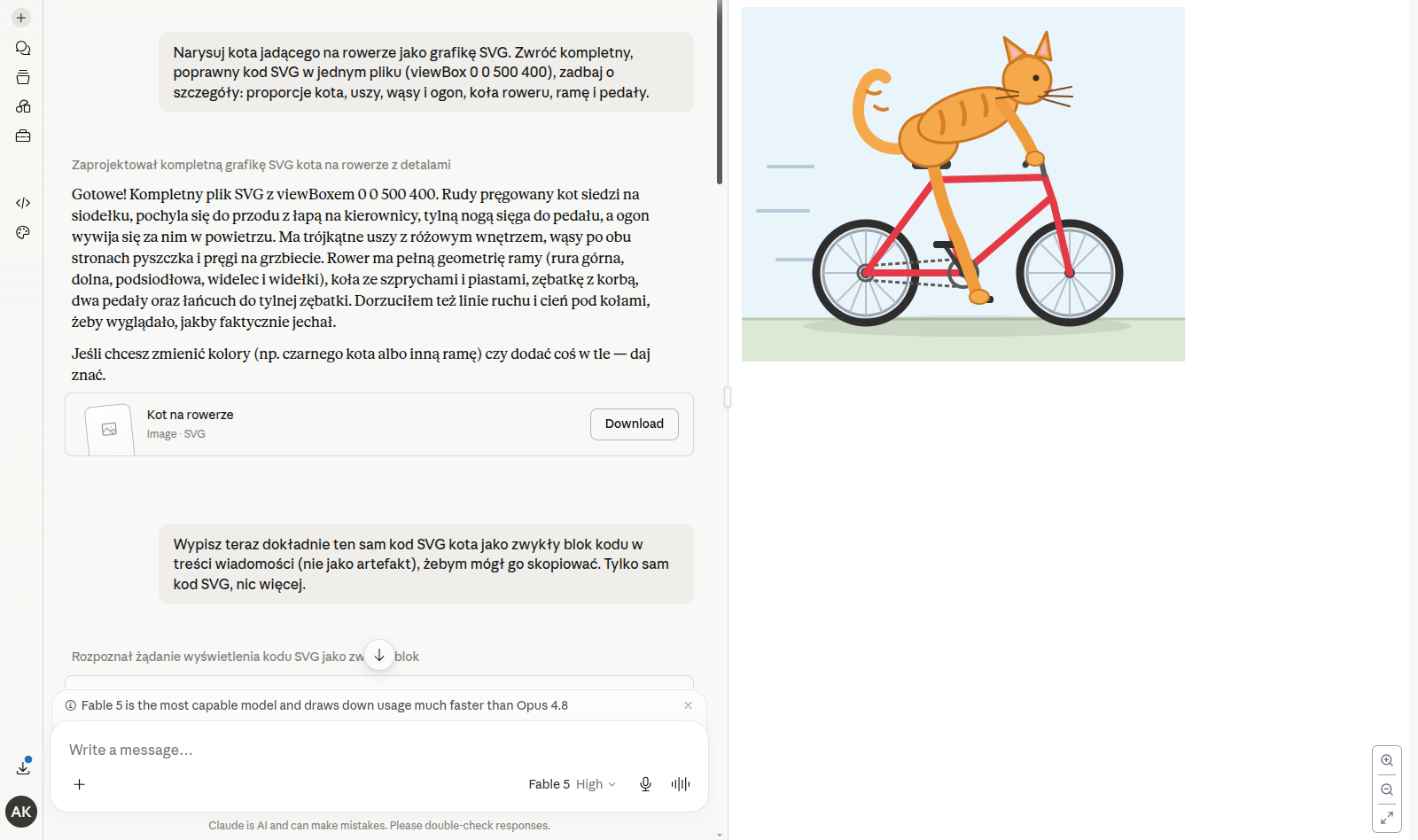
Tak wygląda praca z Fable 5 w oknie rozmowy: po lewej polecenie i odpowiedź modelu, po prawej gotowy, wyrenderowany wynik (tutaj grafika, którą model przygotował na podstawie opisu):
Anthropic pokazuje Fable 5 jako model osiągający czołowe wyniki na większości testów. Dwie liczby, w których widać różnicę wobec Opus 4.8 najwyraźniej, dotyczą kodowania:
Poza kodowaniem Anthropic raportuje, że na teście FrontierCode (od twórców Cognition) Fable ma najwyższy wynik wśród czołowych modeli nawet przy średnim poziomie wysiłku, w analityce jako pierwszy przekroczył 90% (skok o 10 punktów nad Opus), a w zadaniach finansowych osiągnął najwyższy wynik w rozumowaniu na poziomie seniora. Reguła, która się z tego wyłania, jest prosta: im dłuższe i bardziej złożone zadanie, tym większa przewaga Fable. Na krótkich, prostych poleceniach różnica potrafi być niewielka - co za chwilę zobaczymy na żywym przykładzie.
Fable to nie „nowy Opus”, tylko wyższa półka za wyższą cenę. Najkrócej różnice wyglądają tak:
| Cecha | Fable 5 | Opus 4.8 |
|---|---|---|
| Pozycja | rodzina Mythos - o klasę wyżej | dotychczasowa klasa premium |
| Cena wejścia / wyjścia | 10 / 50 USD za mln tokenów | 5 / 25 USD za mln tokenów |
| Cache (odczyt / zapis) | 1,00 / 12,50 USD za mln | 0,50 / 6,25 USD za mln |
| Okno kontekstu | 1 mln tokenów | 1 mln tokenów |
| Modalności | tekst + obrazy | tekst + obrazy |
| Wysiłek rozumowania | regulowany | regulowany |
| Bezpieczeństwo | klasyfikator kieruje wrażliwe tematy do Opus 4.8; retencja 30 dni | dostępna zerowa retencja danych |
| Najlepszy do | najdłuższych, najbardziej złożonych zadań agentowych i naukowych | codziennych złożonych zadań, gdzie liczy się koszt i prywatność |
Cena jest kluczowa: Fable kosztuje mniej więcej dwa razy więcej. Opus 4.8 zostaje więc bardzo sensownym wyborem tam, gdzie liczą się koszty albo zerowa retencja danych - zresztą sam Fable używa Opusa jako „hamulca bezpieczeństwa” (o tym w następnej sekcji).
Żeby pokazać różnicę na żywo, daliśmy obu modelom dokładnie to samo polecenie przy tym samym, wysokim poziomie wysiłku: „narysuj kota jadącego na rowerze jako grafikę SVG”. To proste, żartobliwe zadanie rysowania kodem - najważniejsze, że oba modele dostały identyczne polecenie. Oto wyniki obok siebie:


Obie wersje wyszły dobrze - każdy model podszedł do tematu inaczej: Fable postawił na dynamiczną, pochyloną pozę z liniami ruchu, Opus dorzucił pełniejsze tło ze słońcem i łąką. Na tak krótkim zadaniu różnica jest w zasadzie kosmetyczna - i dobrze to ilustruje wcześniejszy wniosek: prawdziwy dystans między tymi modelami widać dopiero na długich, wieloetapowych zadaniach, a nie na jednym poleceniu.
Skoro Mythos to mocniejsza klasa, Anthropic obudował publiczny wariant dodatkowym mechanizmem. W Fable 5 działa klasyfikator (mały model pomocniczy oceniający treść zapytania), który wrażliwe zapytania - z trzech wąskich obszarów wysokiego ryzyka, wymienionych niżej - kieruje do bezpieczniejszego Opus 4.8. Wygląda to tak:
Każde Twoje polecenie przechodzi najpierw przez wbudowany klasyfikator bezpieczeństwa.
Za wrażliwe uznaje trzy tematy: cyberbezpieczeństwo ofensywne (pomoc w atakach), biologię i chemię wysokiego ryzyka oraz próby skopiowania samego modelu (tzw. distillation - „wyciągnięcie” jego zdolności, żeby wytrenować własny). Zwykłe pytania - programowanie, analiza danych, pisanie - wrażliwe nie są.
Jeśli klasyfikator wykryje temat z tych trzech obszarów, odpowiedź przejmuje Opus 4.8. Jeśli nie - a to ponad 95% sesji - odpowiada Fable 5.
Mechanizm uruchamia się rzadko: średnio w mniej niż 5% sesji. Wszystkie zapytania i odpowiedzi klasy Mythos Anthropic przechowuje u siebie przez 30 dni (to tzw. retencja danych - czas, po którym są kasowane) i nie używa ich do trenowania modeli. Odporność na obejścia zabezpieczeń wygląda solidnie - w ponad tysiącu godzin płatnego programu wyszukiwania błędów nie znaleziono uniwersalnego „jailbreaka”, a wobec 30 publicznych technik obchodzenia zabezpieczeń model nie wygenerował ani jednej szkodliwej odpowiedzi w pojedynczej turze. To także powód, dla którego Opus 4.8 - którego można używać z zerową retencją, czyli w ogóle bez zapisywania danych - bywa lepszym wyborem dla danych wrażliwych.
Cały ten artykuł zbudowaliśmy na dwóch zadaniach uruchomionych na naszym koncie - oto one w pigułce:
Z tego wychodzi praktyczna wskazówka, kiedy w ogóle sięgać po droższy model. Fable 5 zwróci swoją wyższą cenę tam, gdzie zadanie jest naprawdę długie i złożone: duży refaktor, wieloetapowa praca agentowa, trudna analiza czy badania naukowe. Do codziennych zadań, gdzie różnica jakości i tak nie przeważy dwukrotnego kosztu, Opus 4.8 albo Sonnet najczęściej w zupełności wystarczą. Warto też pamiętać, że model to jedno, a umiejętność pracy z nim to drugie - dopiero dobrze poprowadzony agent (jasny cel, kontekst, ograniczenia) pokazuje, na co go stać.
Jeśli chcesz zobaczyć na żywo, jak pracować z takimi modelami Anthropic w praktyce - od pojedynczego polecenia po zespoły agentów w narzędziu Claude Code - mamy na to konkretne szkolenie. Szczegóły o samym modelu znajdziesz też na oficjalnej stronie Anthropic.

Praca z modelami Anthropic (w tym Fable) w praktyce: polecenia, kontekst, tryby uprawnień, MCP, hooki i systemy multi-agent - na żywym kodzie podczas trzydniowego szkolenia. Prowadzi Łukasz Matuszewski. Szkolenie ma termin gwarantowany - odbędzie się niezależnie od liczby zgłoszeń.
Szkolenie Claude Code -->
Komentarze (0)
Brak komentarzy...