Blog JSystems - uwalniamy wiedzę!
Blog JSystems - uwalniamy wiedzę!
Rozmawiasz z AI jak z człowiekiem: zadajesz pytanie, dostajesz sensowną odpowiedź, czasem nawet żart. Ale po drugiej stronie nie siedzi żaden człowiek i nie kryje się tam żadna świadomość. Co więc naprawdę się dzieje? W tym artykule rozłożymy to na czynniki pierwsze i pokażemy Ci — obrazowo, bez wzorów i bez żargonu — jak model językowy (w skrócie LLM, od angielskiego large language model, czyli „duży model językowy”) zamienia Twoje pytanie w odpowiedź.
Jedno zastrzeżenie na start: kluczowe liczby i przykłady poniżej — podział zdania na tokeny, prawdopodobieństwa słów, mapa znaczeń czy mechanizm uwagi — pochodzą z prawdziwego modelu językowego, który uruchomiliśmy specjalnie na potrzeby tego artykułu. To nie są ilustracje „mniej więcej”, tylko jego autentyczne wyniki.
Z tego artykułu dowiesz się:
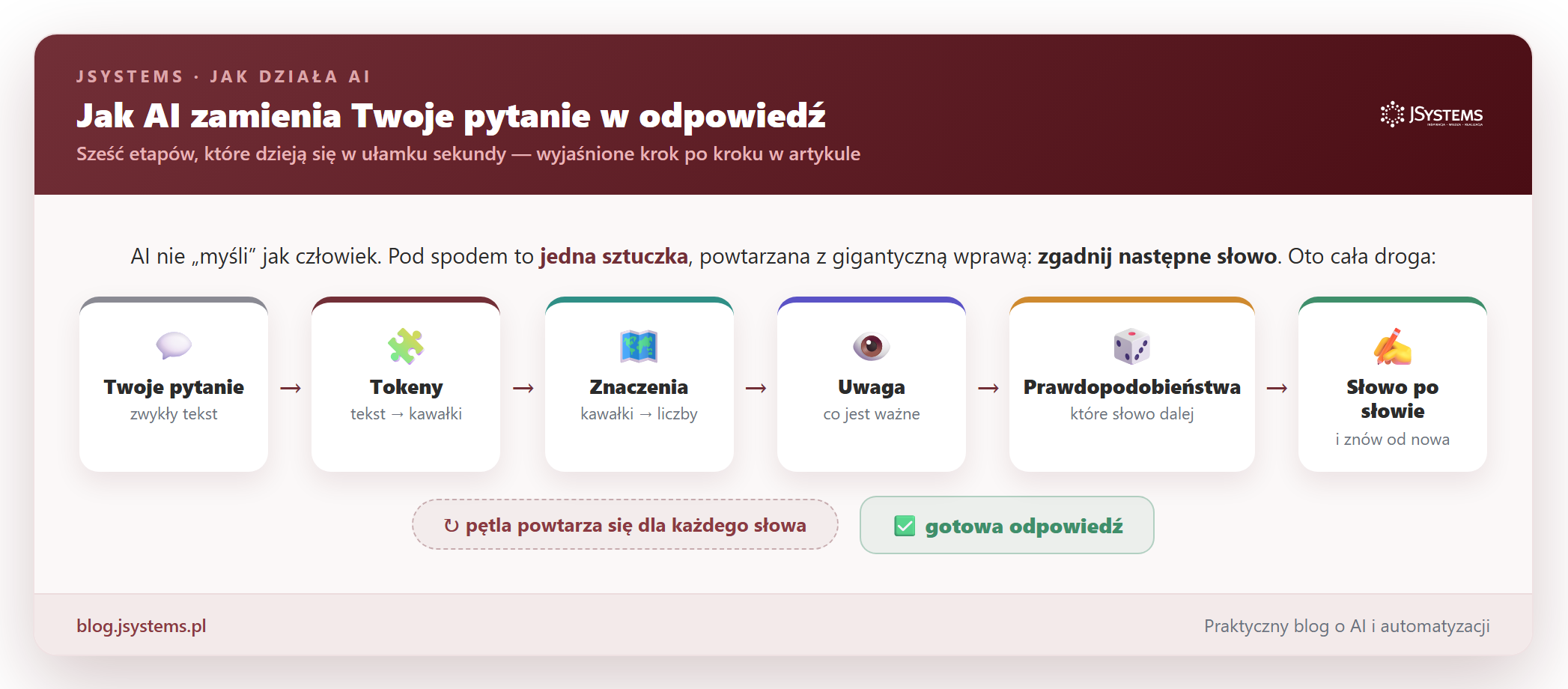
Zacznijmy od najważniejszej rzeczy, która zburzy część wyobrażeń o AI. Pod całą tą inteligencją kryje się jedna, zaskakująco prosta czynność: model patrzy na tekst, który ma do tej pory, i zgaduje, jakie słowo powinno paść jako następne. Potem dokłada to słowo i zgaduje kolejne. I jeszcze raz. I jeszcze raz, aż powstanie cała odpowiedź. To wszystko.
Brzmi znajomo? Bo tę samą sztuczkę masz w telefonie. Gdy piszesz wiadomość, klawiatura podpowiada następne słowo. LLM robi dokładnie to samo, tylko na zupełnie innym poziomie zaawansowania.
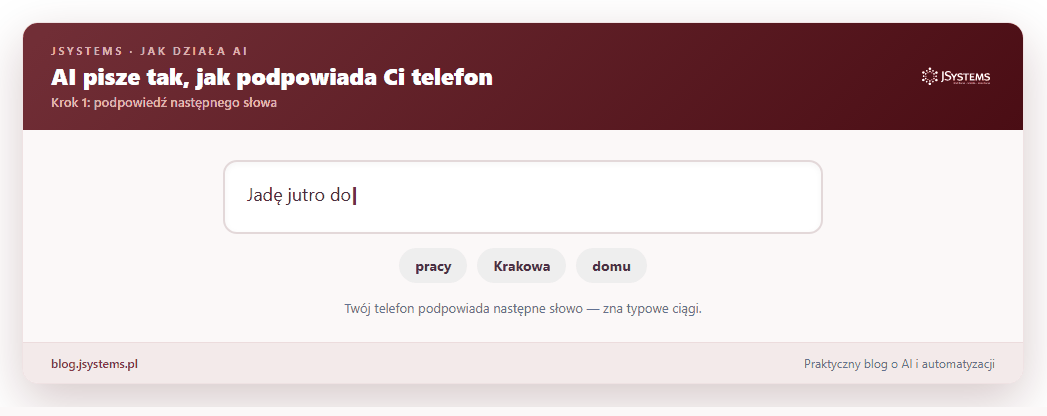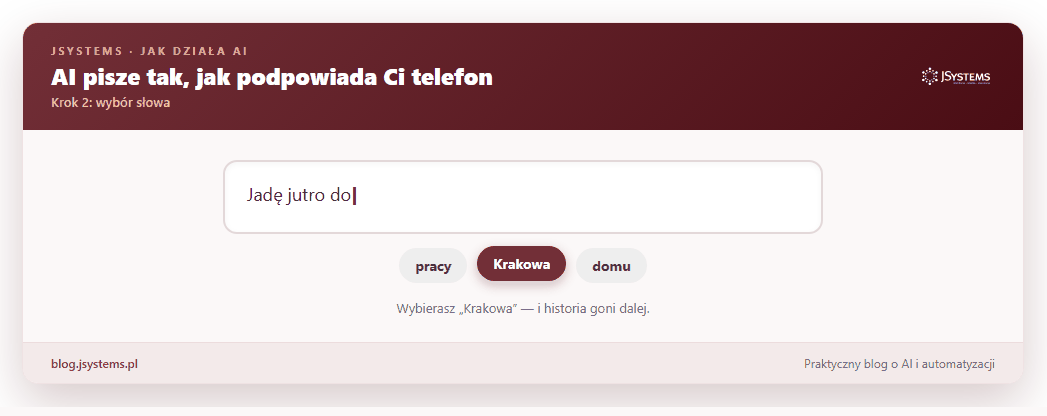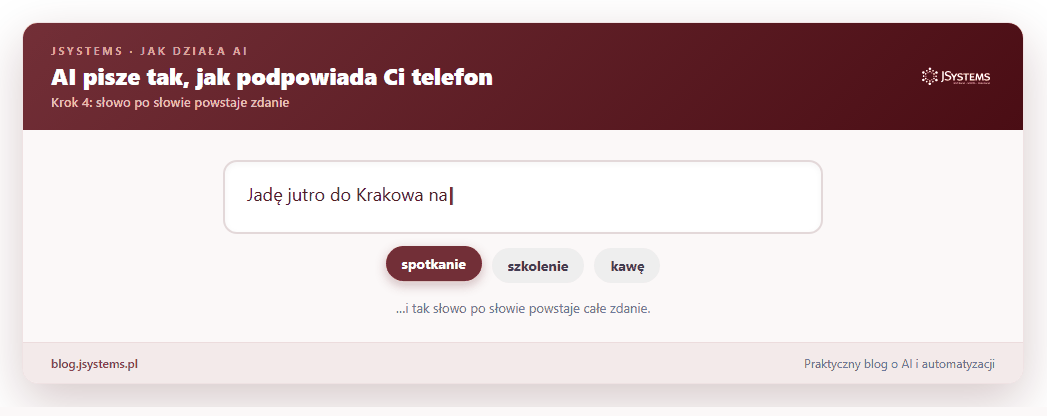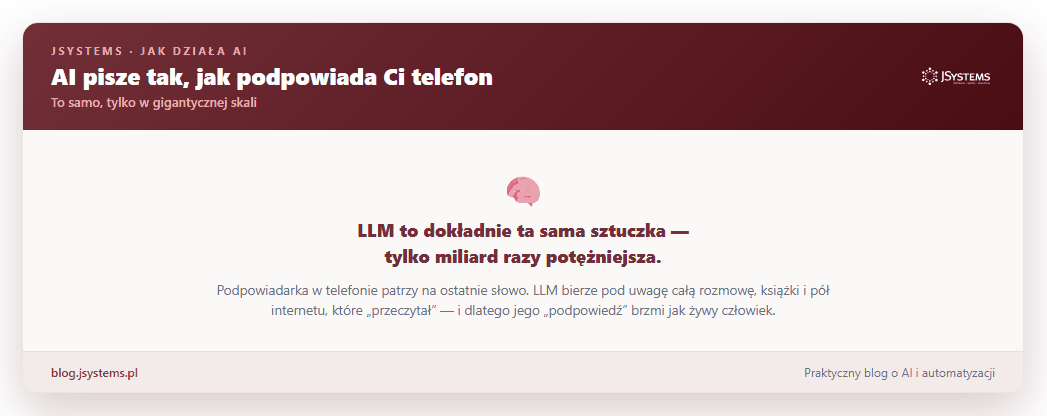
Cała reszta tego artykułu to odpowiedź na jedno pytanie: jak to możliwe, że zwykłe „zgadywanie następnego słowa” daje coś, co potrafi napisać maila, wytłumaczyć trudny temat i odpowiedzieć na Twoje pytanie? Rozłóżmy to krok po kroku.
Pierwsza przeszkoda jest banalna, a kluczowa: komputer nie rozumie liter ani słów. Operuje wyłącznie na liczbach. Dlatego zanim model cokolwiek zrobi z Twoim pytaniem, musi pociąć je na kawałki i każdemu przypisać numer. Te kawałki to tokeny: czasem całe słowo, a czasem tylko jego fragment.
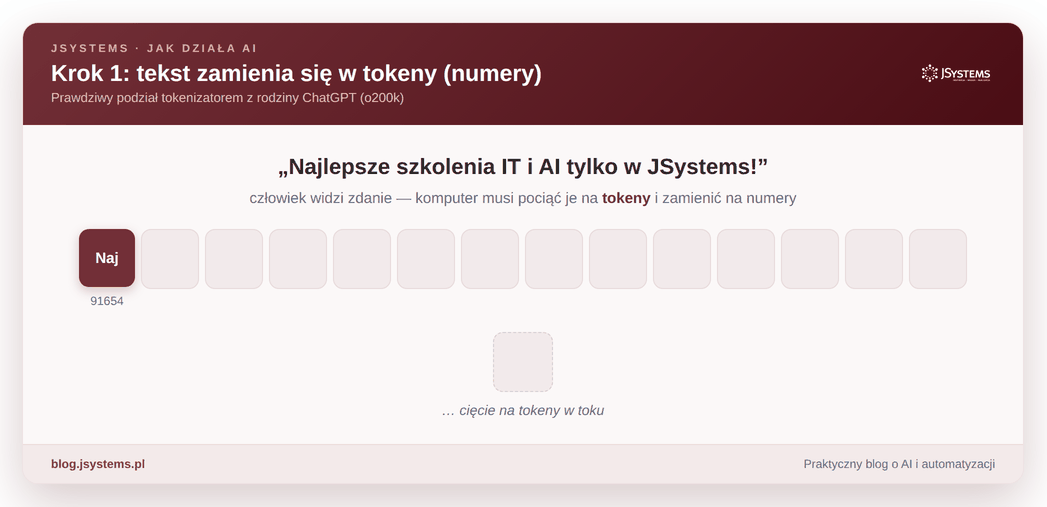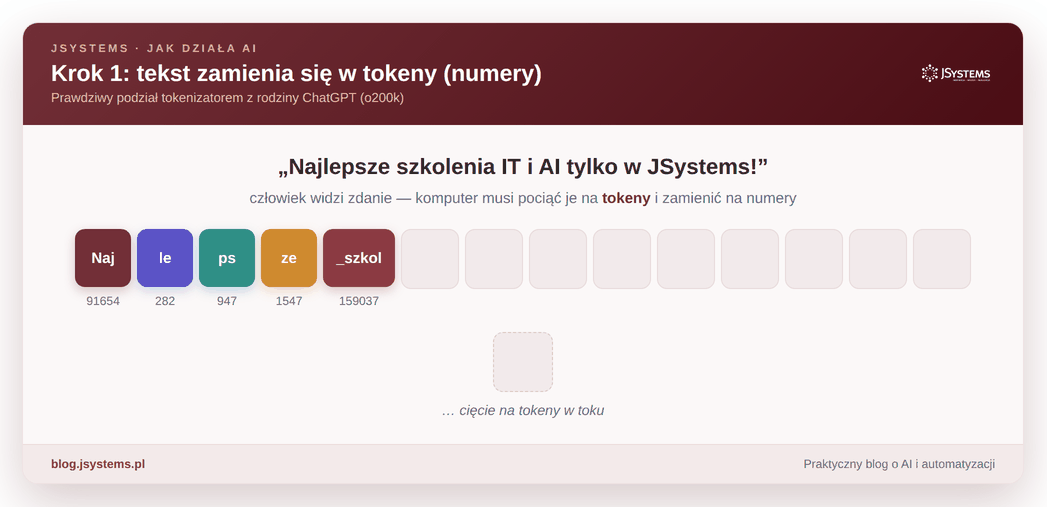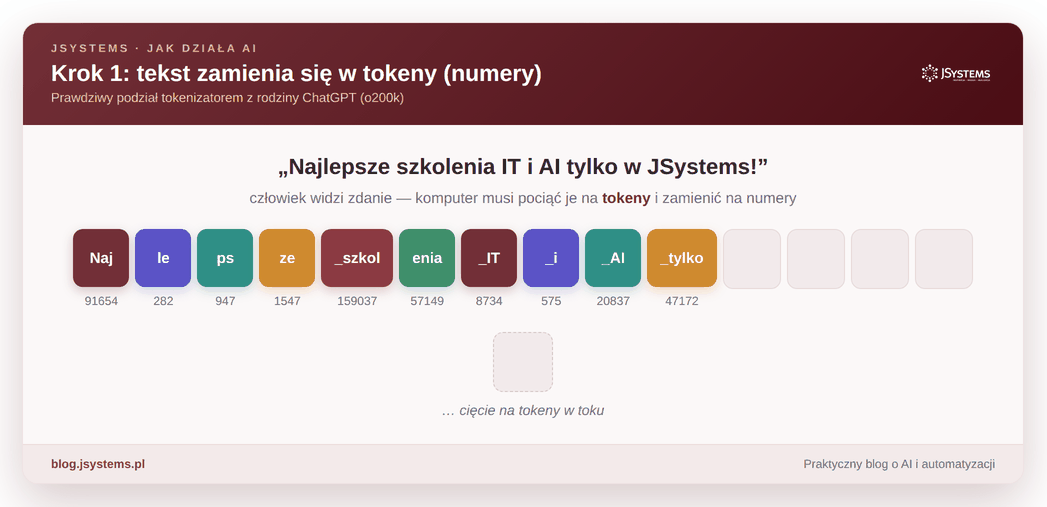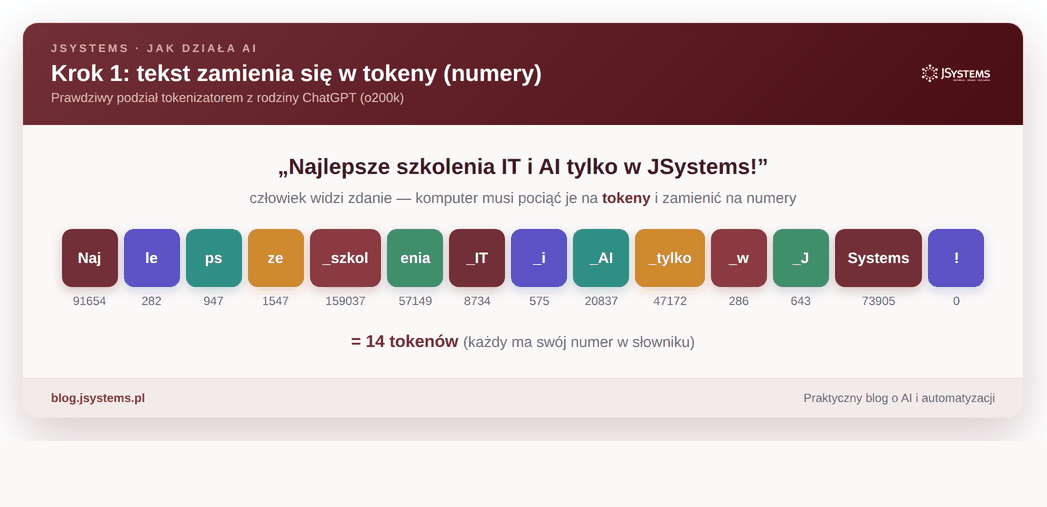
Zwróć uwagę na ciekawą rzecz: token to nie zawsze całe słowo. Częste słowa (jak „i” czy „w”) bywają jednym tokenem, a rzadsze rozpadają się na kawałki. Słowo „Najlepsze” model widzi jako cztery osobne kawałki, a krótkie zdanie „Kot siedzi na macie” — jako siedem tokenów:

sied + zi, a „macie” to mac + ie. Dla modelu to po prostu ciąg numerów.Od tej chwili model nie ma już do czynienia ze słowami, tylko z ciągiem liczb. Cała magia, którą za chwilę zobaczysz, dzieje się właśnie na tych liczbach.
Sam numer tokenu nic jeszcze nie znaczy — „Warszawa” mogłaby mieć numer 5, a „herbata” numer 6, choć nie mają ze sobą nic wspólnego. Dlatego model robi drugi, sprytny krok: każdemu tokenowi nadaje miejsce w ogromnej „przestrzeni znaczeń”. Mówiąc technicznie, zamienia go na długą listę liczb. Taką listę nazywamy wektorem (albo zanurzeniem, po angielsku embedding). Najważniejsze jest to, co z tego wynika: słowa o podobnym znaczeniu lądują blisko siebie.
Najlepiej zobaczyć to na mapie. Poniżej rzut tej przestrzeni na płaszczyznę: prawdziwe pozycje słów wyliczone przez model. Nikt mu nie powiedział, co to zwierzę czy kraj; sam ułożył tę mapę, czytając teksty:
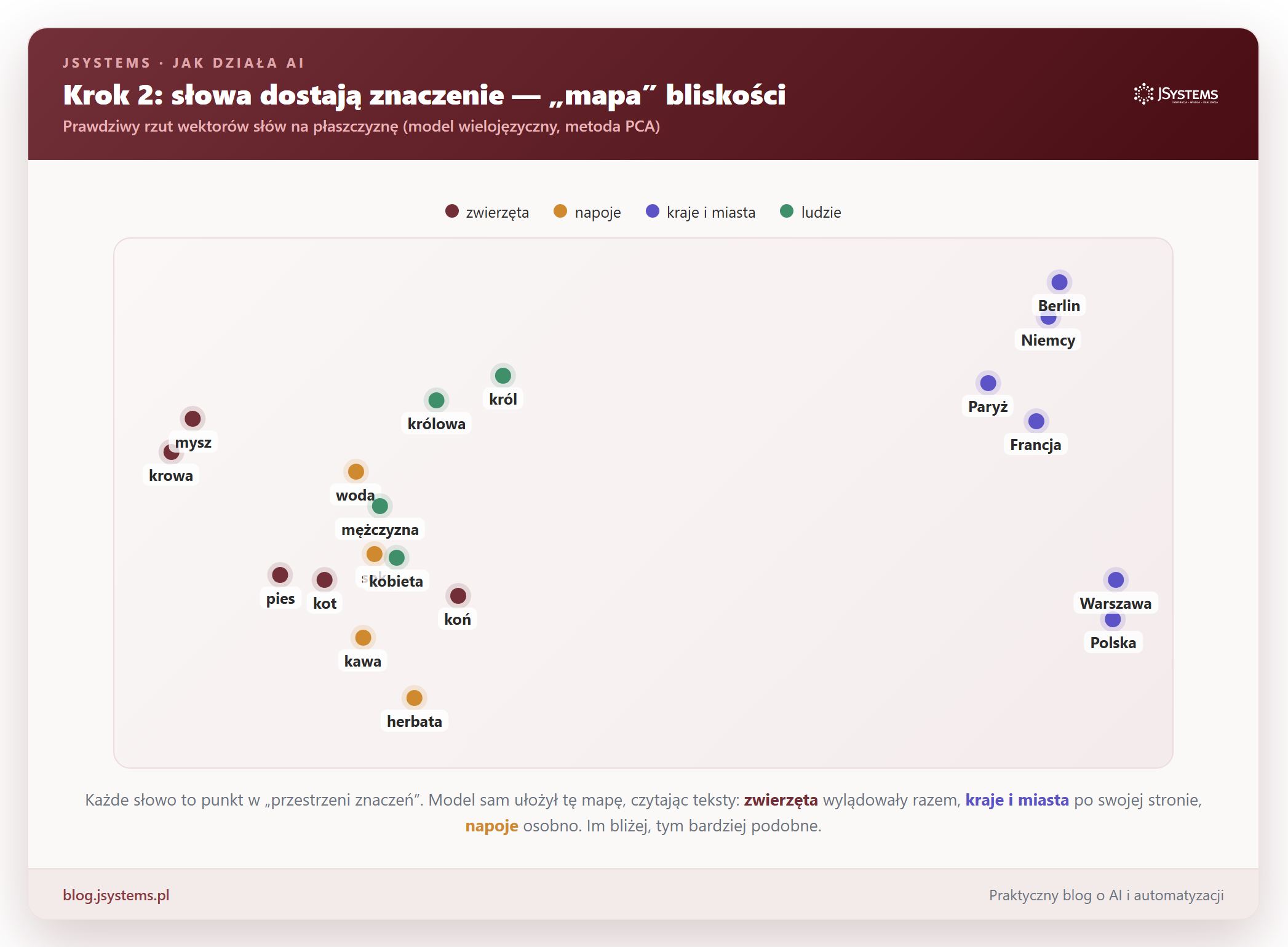
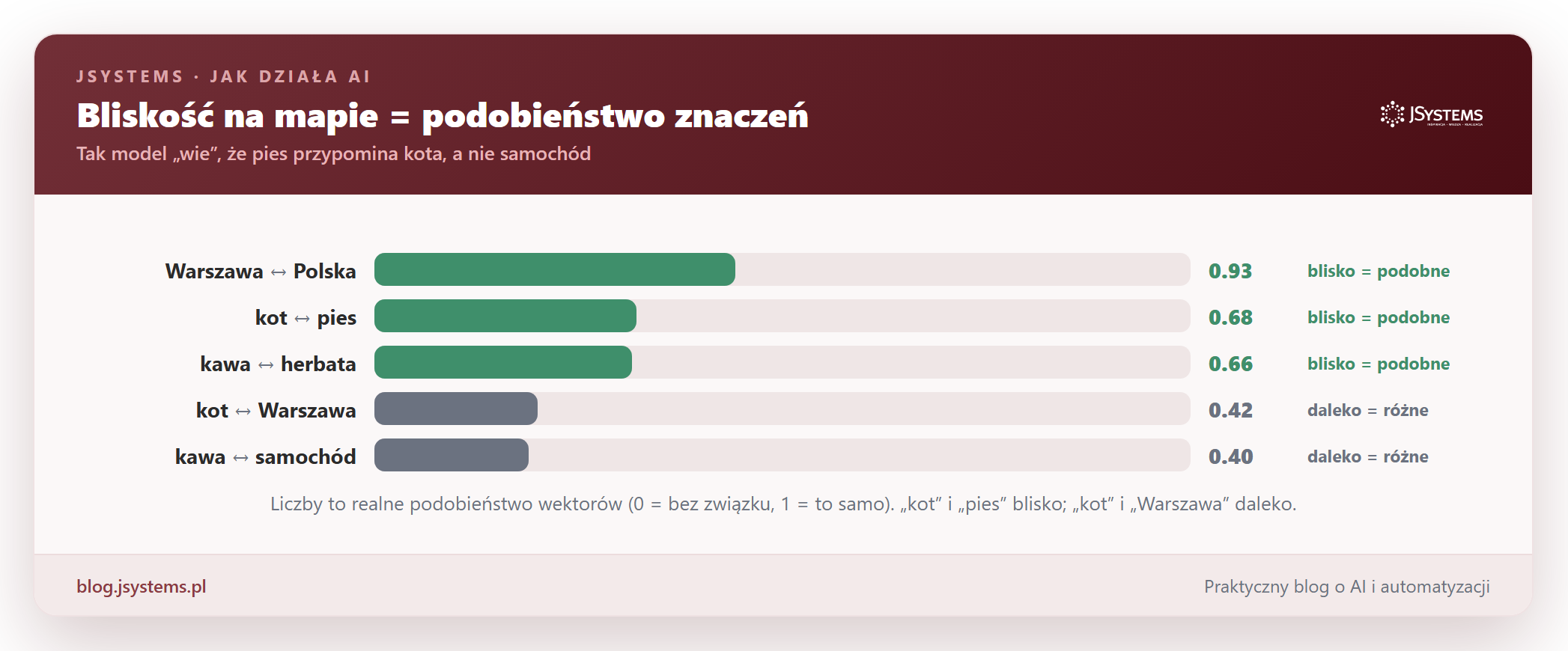
To właśnie dzięki tej mapie model „wie”, że pies przypomina kota, a nie samochód. Bliskość da się nawet zmierzyć liczbą od 0 (zupełnie różne) do 1 (to samo). Oto kilka prawdziwych pomiarów. Zwróć uwagę, jak ładnie pasują do intuicji:
Teraz robi się naprawdę ciekawie. Skoro każde słowo to zestaw liczb, to te liczby można dodawać i odejmować jak w matematyce, a wychodzą z tego sensowne rzeczy. Zadaliśmy modelowi zagadkę: „czym dla Niemiec jest to, czym Warszawa jest dla Polski?”. W języku wektorów to po prostu Warszawa minus Polska plus Niemcy. Odpowiedź modelu, bez żadnej podpowiedzi z naszej strony:
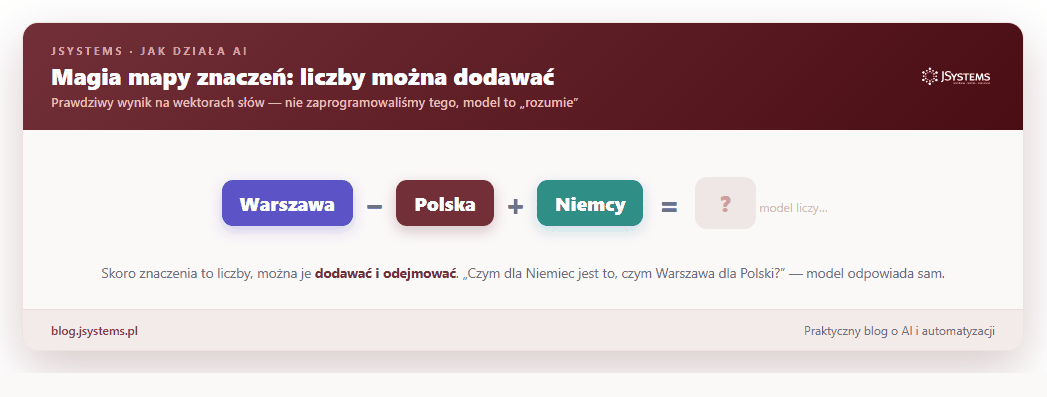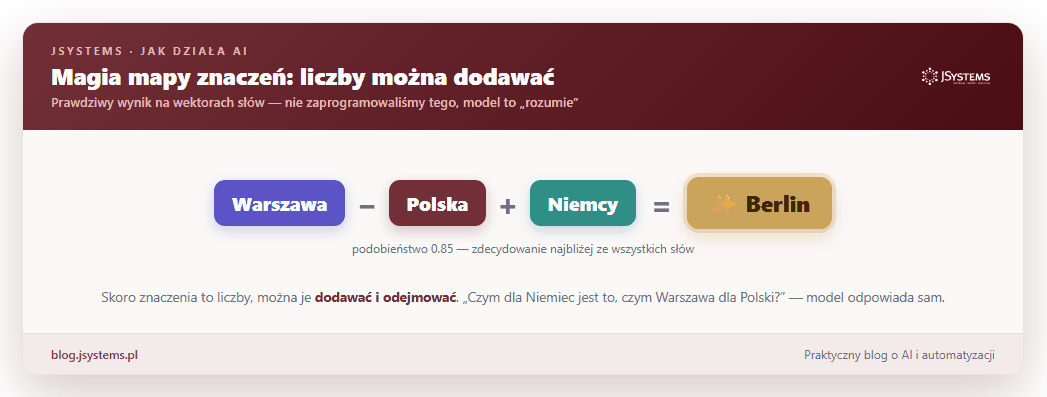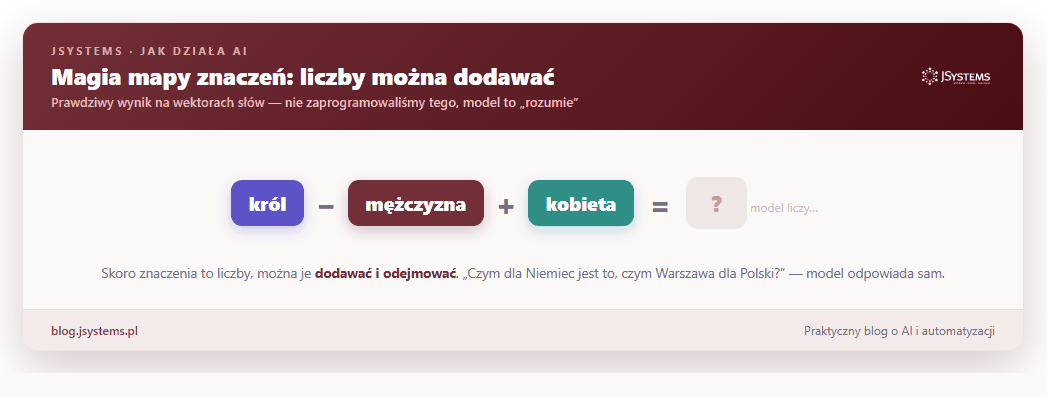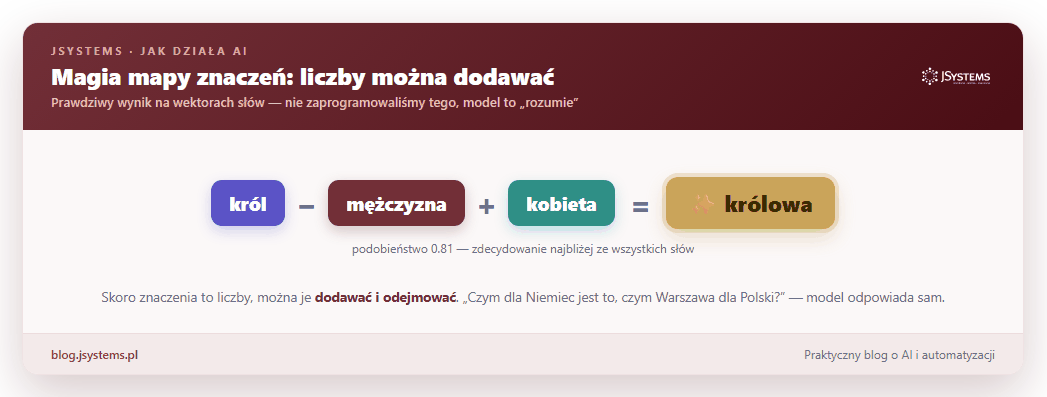
To nie sztuczka ani przypadek. To pokazuje, że model naprawdę uchwycił coś z sensu słów: relacja „stolica swojego kraju” czy „żeńska wersja” jest w tej przestrzeni konkretnym kierunkiem, którym można się przesunąć.
Wróćmy do głównej sztuczki: zgadywania następnego słowa. Jak model dokonuje wyboru? Nie wskazuje jednego słowa. Zamiast tego każdemu możliwemu słowu nadaje szansę — liczbę mówiącą, jak bardzo tu pasuje. Potem losuje spośród nich, częściej sięgając po te z najwyższym wynikiem. Spójrz na prawdziwe szanse policzone przez model dla zdania „Stolicą Polski jest...”:
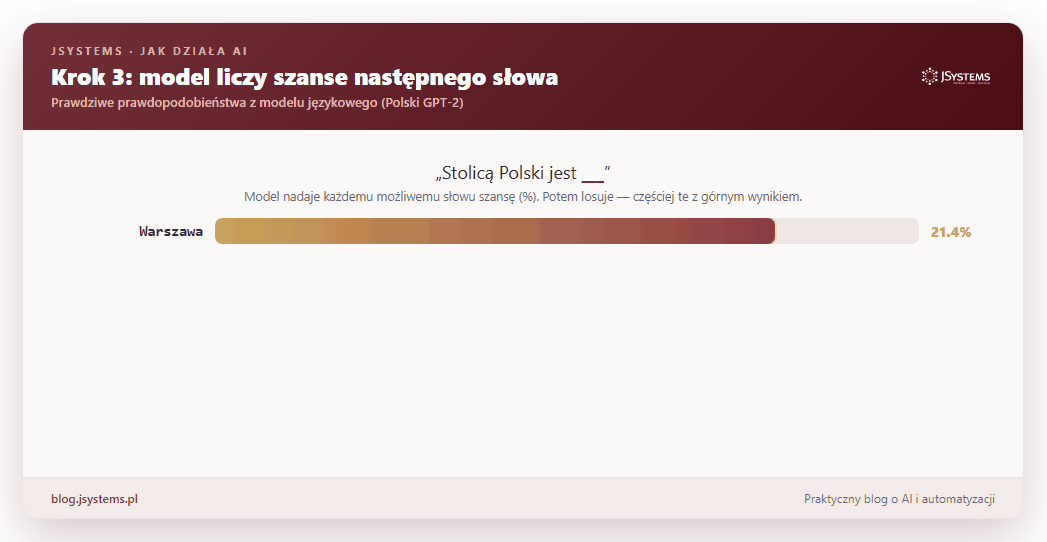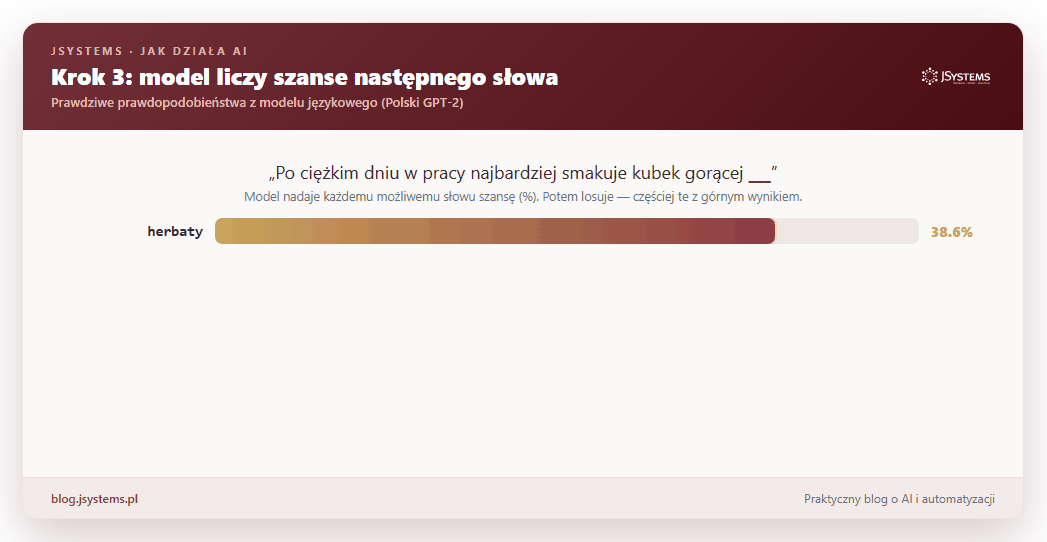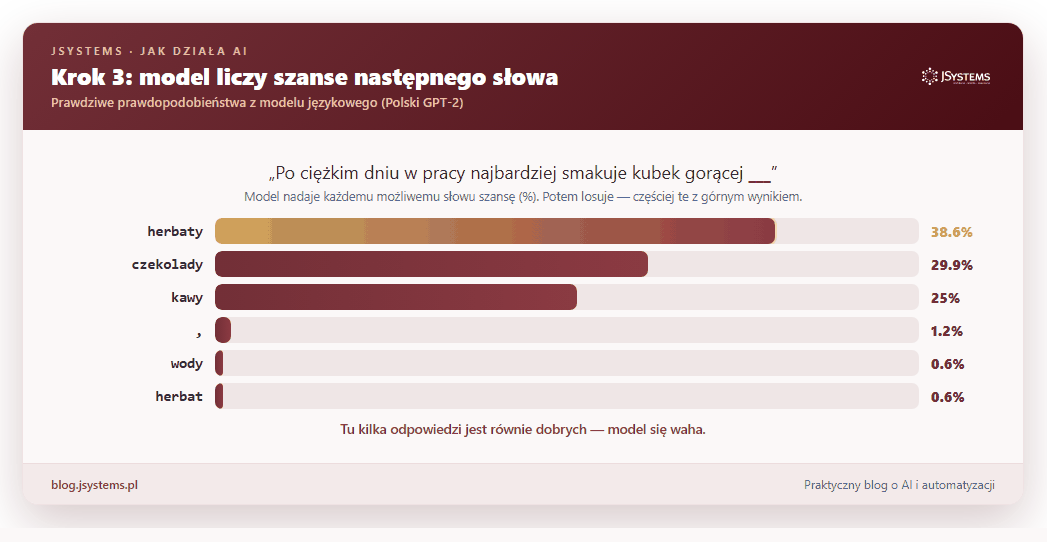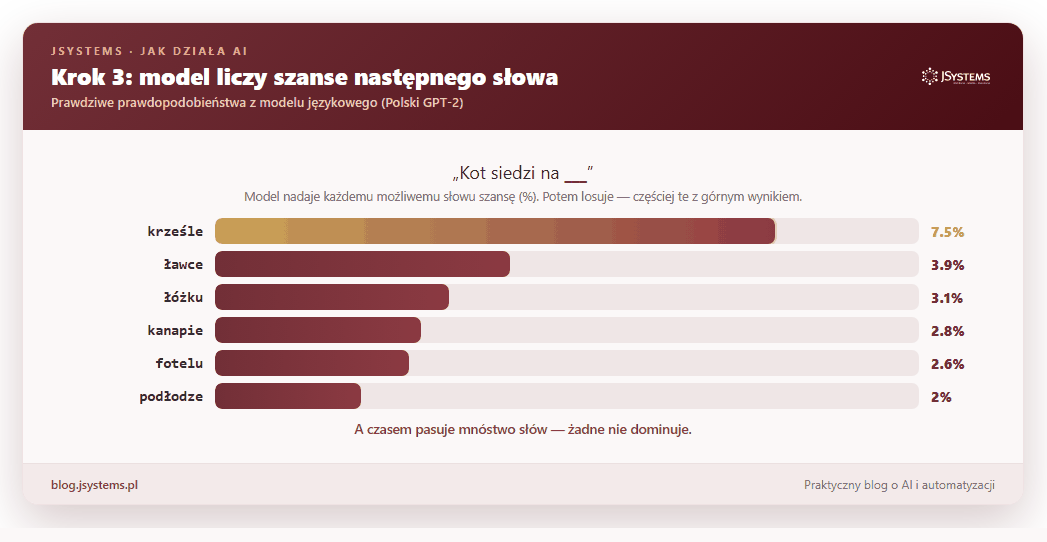
To bardzo ważny obrazek, bo tłumaczy dwie rzeczy. Po pierwsze, model bywa pewny (po „Stolicą Polski jest” Warszawa wygrywa na głowę) albo niepewny (po „Kot siedzi na” pasuje krzesło, ławka, łóżko, kanapa, cała lista). Po drugie, skoro na końcu jest losowanie, to ten sam model na to samo pytanie może odpowiedzieć raz tak, raz nieco inaczej.
Tym, jak bardzo model „ryzykuje” przy losowaniu, steruje jedno ustawienie zwane temperaturą. Niska temperatura: model niemal zawsze wybiera najbardziej prawdopodobne słowo, więc jest przewidywalny i powtarzalny. Wysoka temperatura: szanse się wyrównują, więc odpowiedzi bywają ciekawsze i bardziej zaskakujące, ale też bardziej losowe. To te same prawdopodobieństwa, tylko inaczej „spłaszczone”:
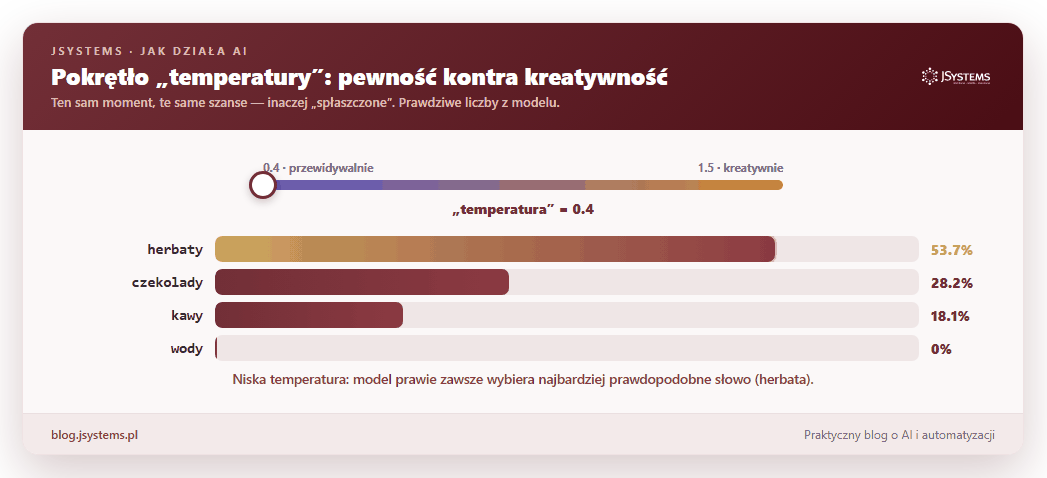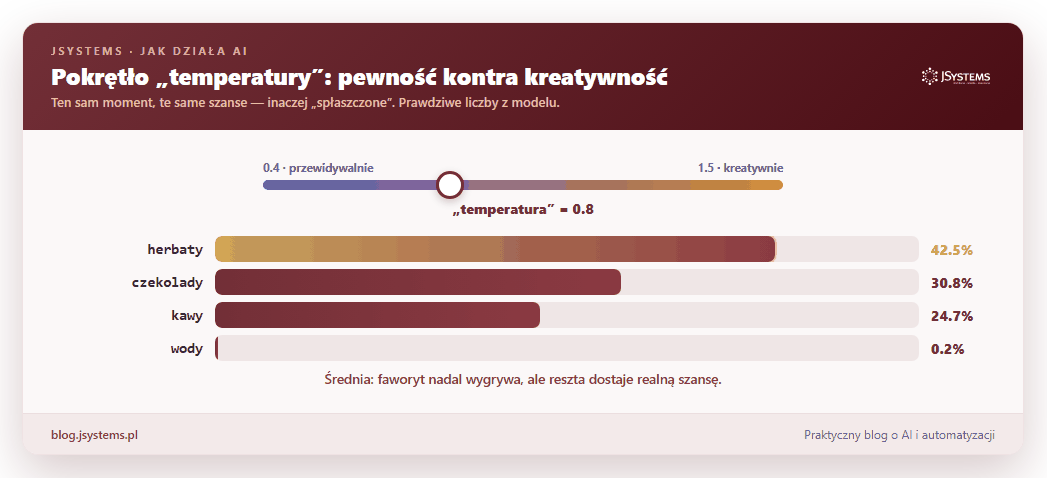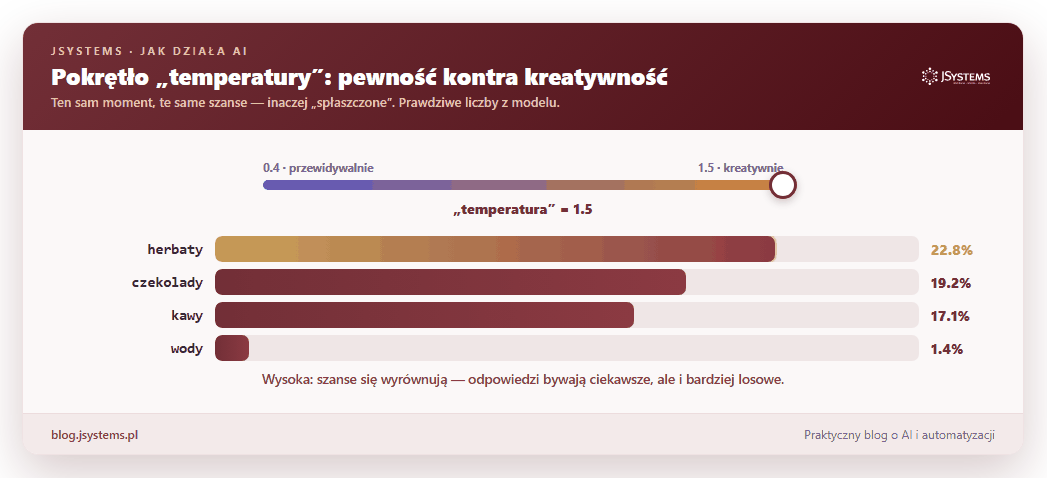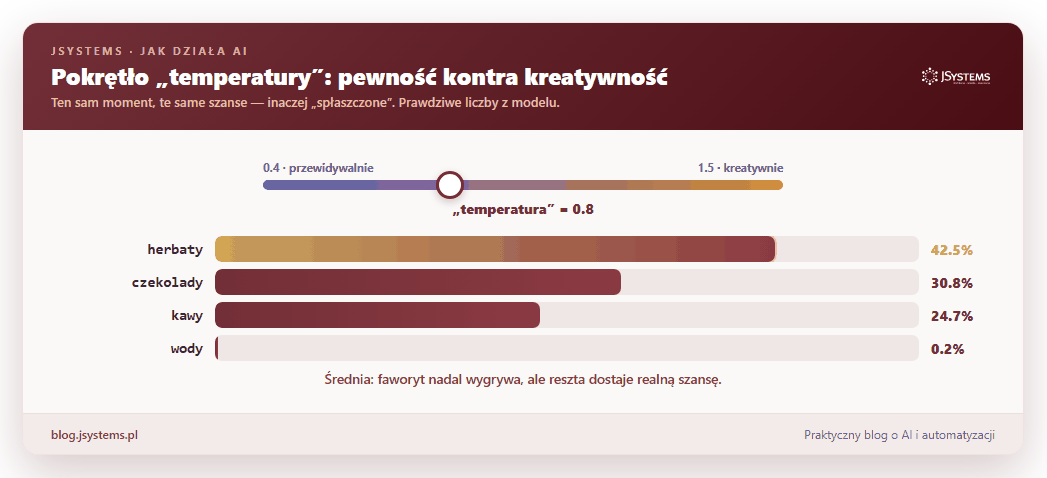
Zostało najważniejsze pytanie: skąd model wie, że po „Stolicą Polski jest” pasuje „Warszawa”, a po „kubek gorącej” pasuje „herbata”? Nikt nie wpisuje mu reguł ani faktów. Cała wiedza bierze się z treningu, a trening to jedna gra powtarzana w kółko na gigantycznej ilości tekstu (książki, artykuły, duża część publicznego internetu): zasłoń słowo, każ modelowi je zgadnąć, sprawdź, czy trafił, i odrobinę popraw jego ustawienia. I tak biliony razy.
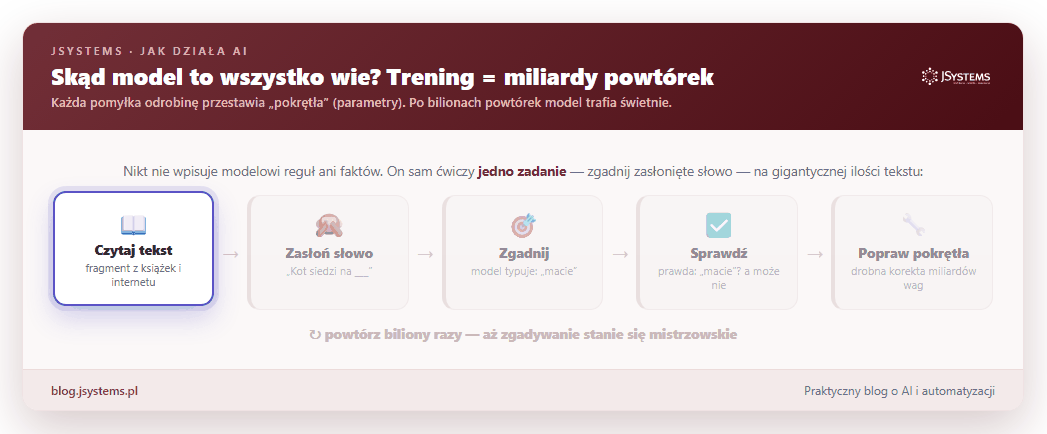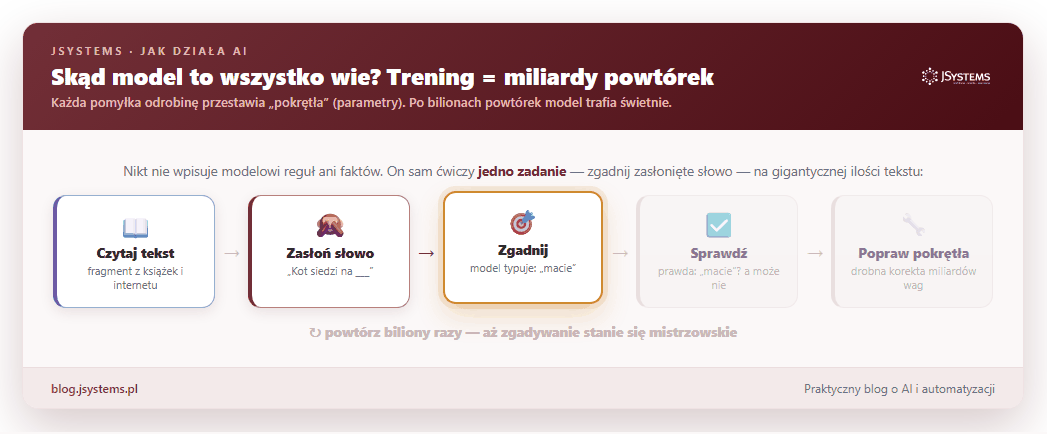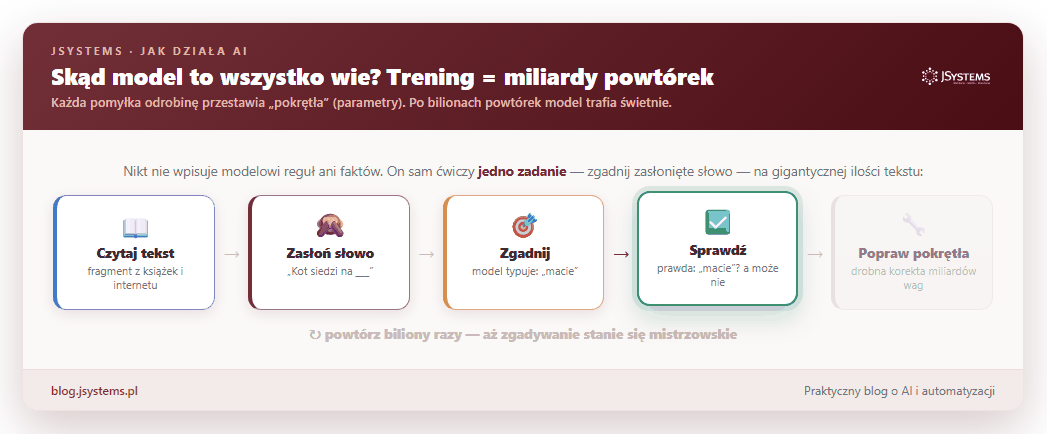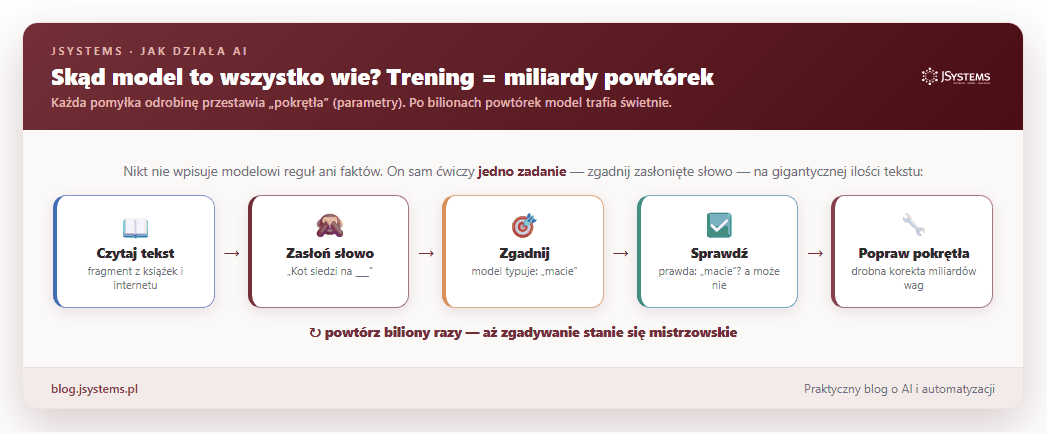
Tych „pokręteł” — fachowo nazywamy je parametrami albo wagami — jest w nowoczesnym modelu miliardy. To one przechowują całą wiedzę: po bilionach powtórek tak się ustawiają, że model zaczyna trafiać po mistrzowsku. Nie ma tam żadnej osobnej „bazy faktów”. Jest tylko gigantyczny zestaw liczbowych ustawień, które razem dają zaskakująco trafne zgadywanie.
Żeby dobrze zgadnąć następne słowo, nie wystarczy patrzeć na ostatni wyraz, trzeba zrozumieć całe zdanie, a często całą rozmowę. Służy do tego mechanizm o nazwie uwaga (po angielsku attention). Działa to tak: przy każdym słowie model spogląda wstecz na wszystkie wcześniejsze słowa i waży, które z nich są teraz istotne.
Najlepiej pokazać to na zaimku. W zdaniu „Klient czekał na paczkę, więc napisał wiadomość z pytaniem o jej status” — do czego odnosi się słowo „jej”? Zobaczmy, na co naprawdę patrzy model:
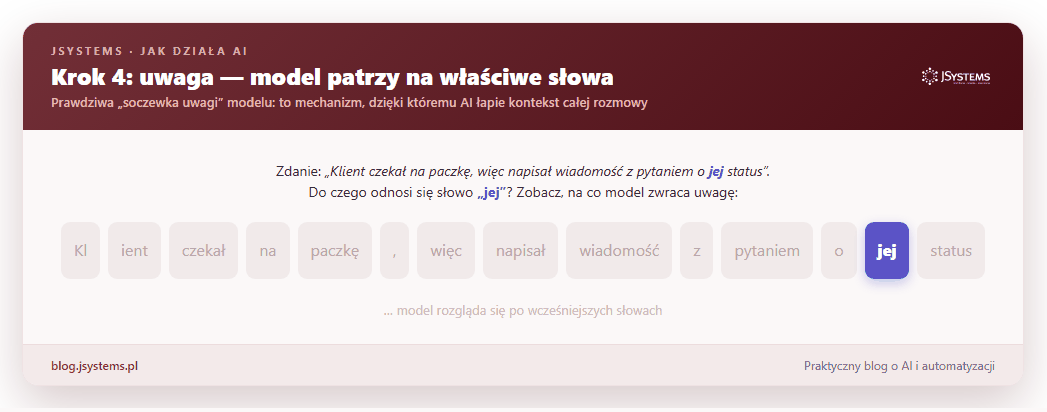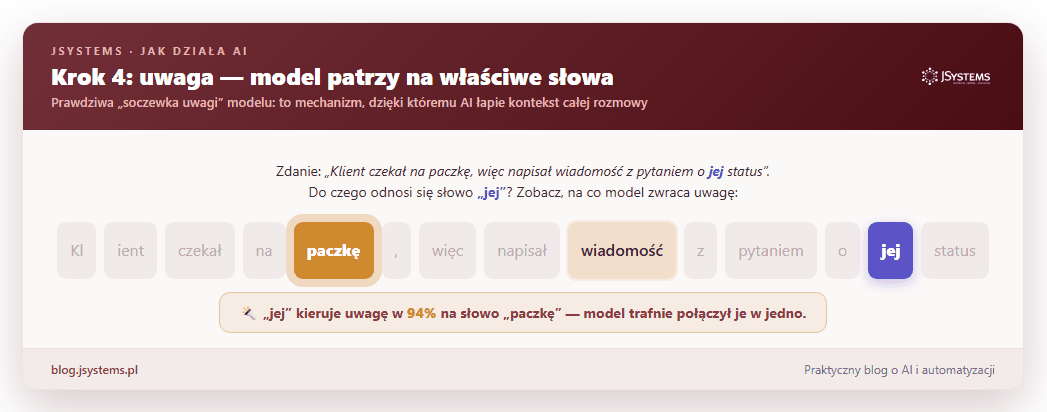
To właśnie dzięki uwadze AI trzyma się tematu, pamięta, o czym była mowa pięć zdań wcześniej, i wie, kto jest kim w rozmowie. Bez tego mechanizmu odpowiedzi byłyby chaotyczne; z nim — spójne i „przemyślane”.
Tu dochodzimy do sedna, które zaskakuje większość ludzi. Jak to możliwe, że proste „zgadywanie następnego słowa” daje coś, co brzmi mądrze i ludzko? Odpowiedź jest piękna w swojej prostocie: żeby naprawdę dobrze zgadywać następne słowo w dowolnym tekście, model musi — sam z siebie — nauczyć się mnóstwa rzeczy.
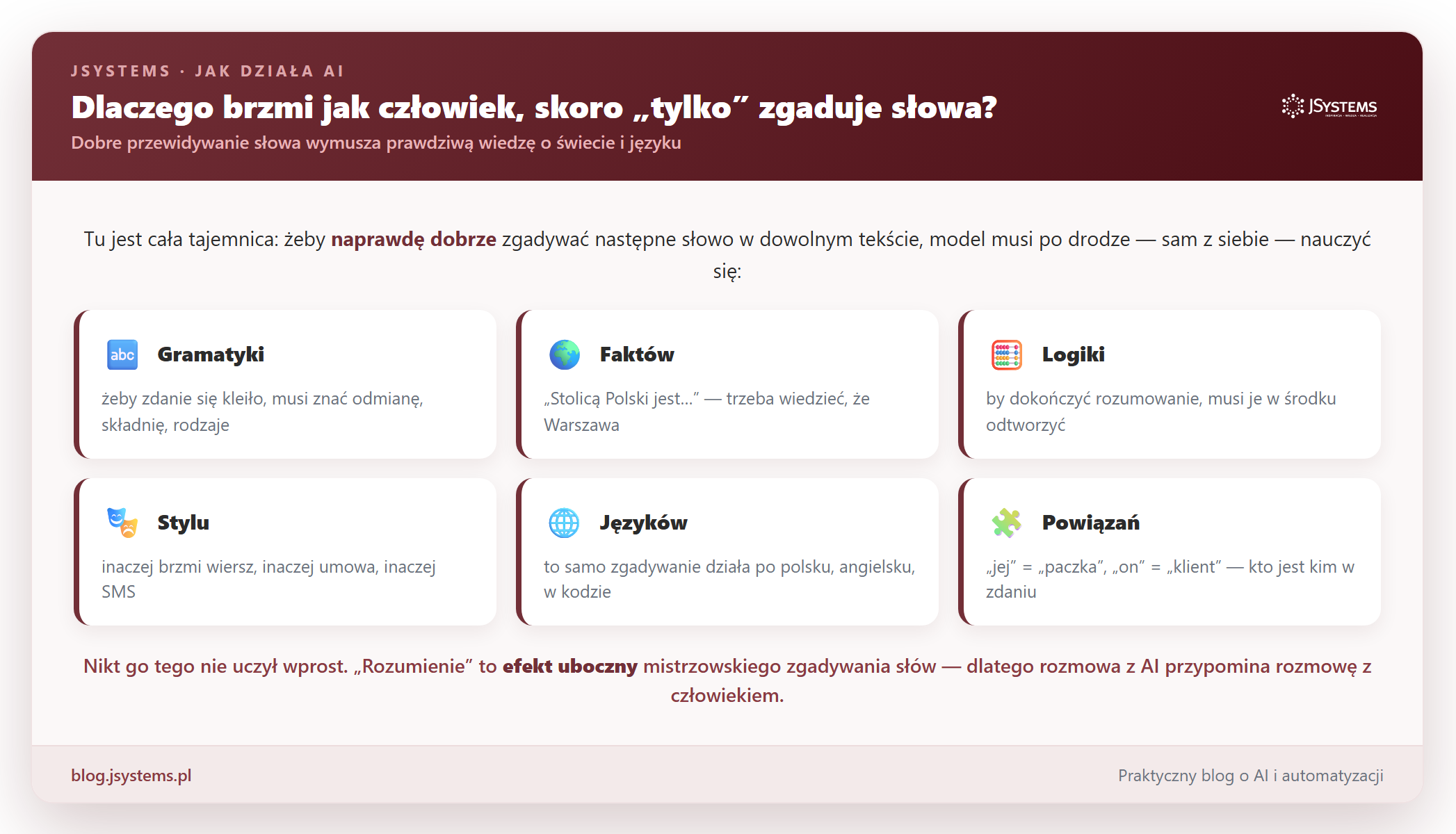
Pomyśl: żeby trafnie dokończyć zdanie „Stolicą Polski jest...”, trzeba znać fakt. Żeby zdanie się kleiło, trzeba znać gramatykę. Żeby dokończyć rozumowanie, trzeba je w środku odtworzyć. Model nie dostał tych umiejętności wprost; „wyhodował” je, bo bez nich nie dałoby się dobrze zgadywać. I właśnie dlatego rozmowa z AI przypomina rozmowę z człowiekiem — choć pod spodem to wciąż ta sama, powtarzana sztuczka.
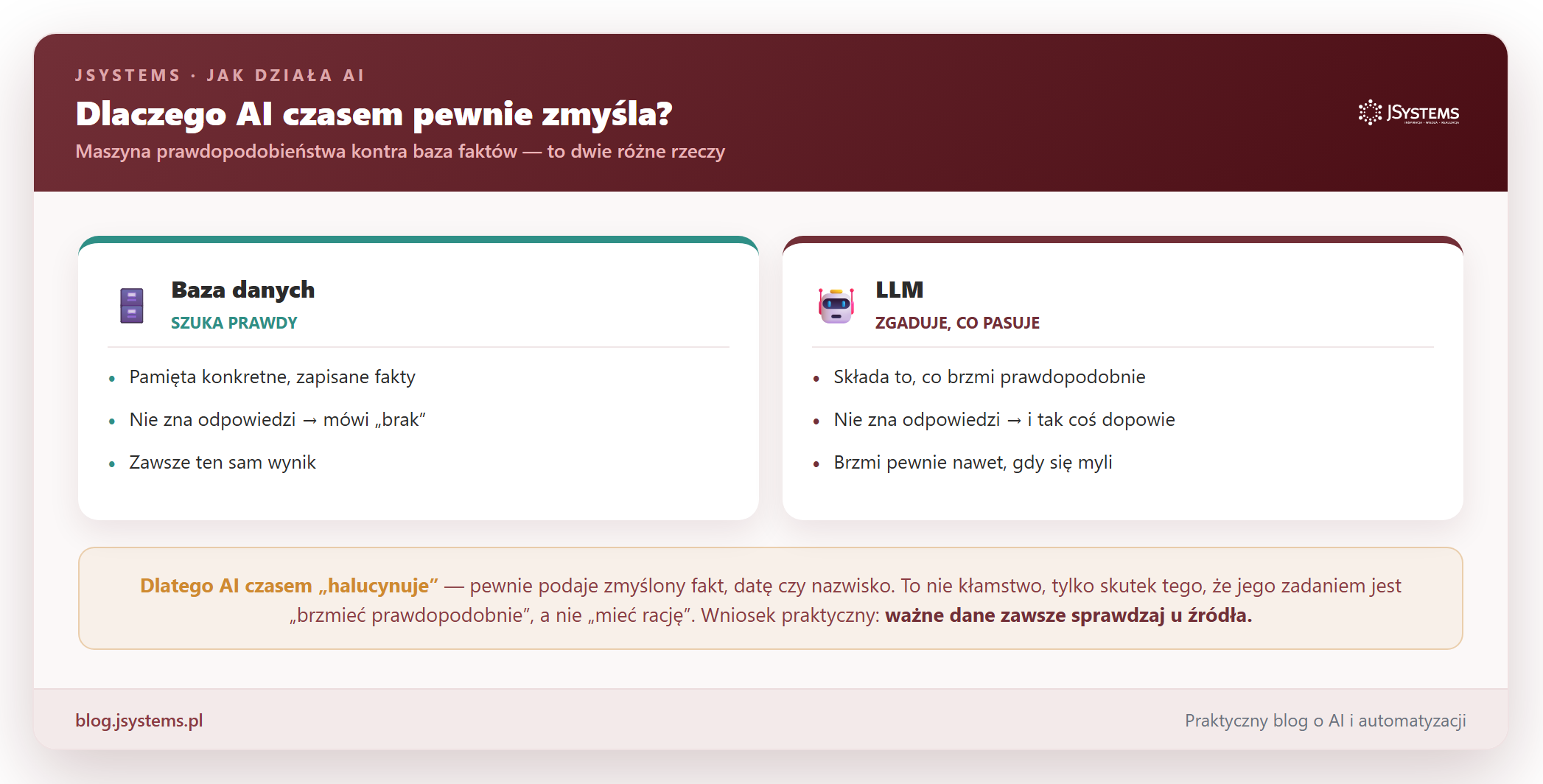
Skoro już rozumiesz, jak to działa, łatwo zrozumiesz też jego największą słabość. Model to maszyna prawdopodobieństwa, a nie baza danych z prawdą. Baza danych zapytana o coś, czego nie ma, powie „brak”. Model nigdy nie powie „brak”, zawsze dopowie najbardziej prawdopodobny ciąg słów. Zwykle trafia, ale czasem pewnym głosem podaje rzecz po prostu nieprawdziwą.
Jest jeszcze jedna brakująca część układanki. Sam „przewidywacz słów” po treningu nie jest jeszcze grzecznym asystentem: zapytany o coś, równie chętnie dopisałby kolejne pytania, zamiast odpowiedzieć. Żeby zamienił się w czat, który odpowiada na polecenia, przechodzi dodatkowy trening z udziałem ludzi.
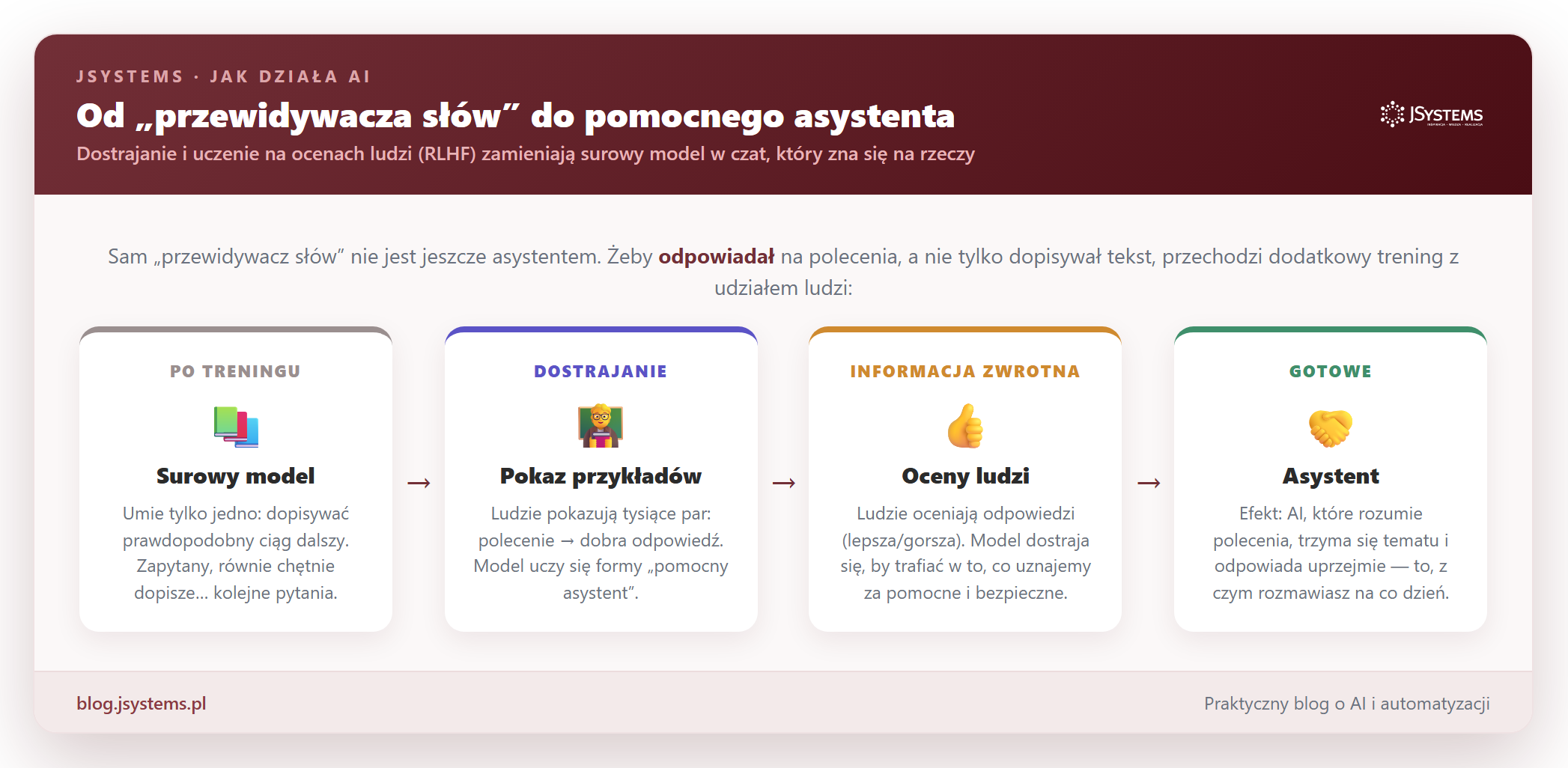
To dlatego AI, z którą rozmawiasz na co dzień, trzyma się tematu, odpowiada grzecznie i stara się być pomocna — tego zachowania nauczyli ją ludzie, oceniając tysiące jej wcześniejszych odpowiedzi.
Połączmy teraz wszystkie elementy. Gdy zadajesz AI pytanie, w ułamku sekundy dzieje się ten ciąg zdarzeń — i co najważniejsze, powtarza się dla każdego kolejnego słowa odpowiedzi:
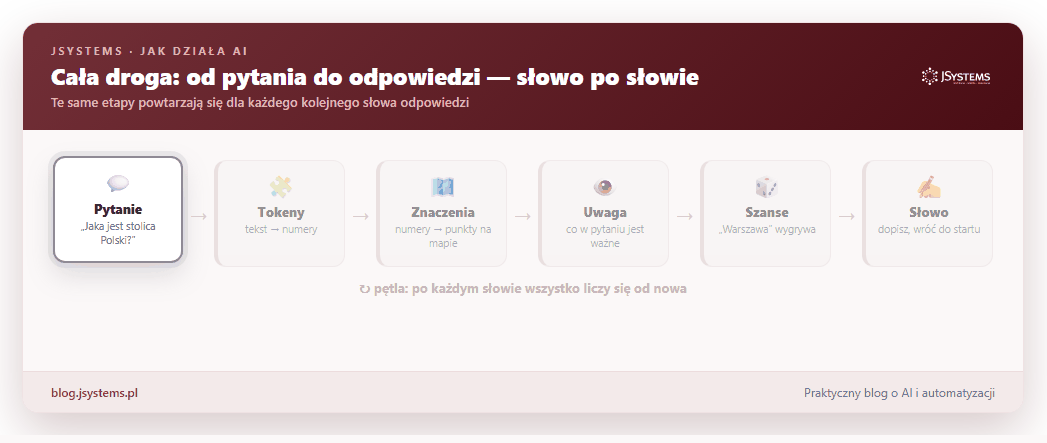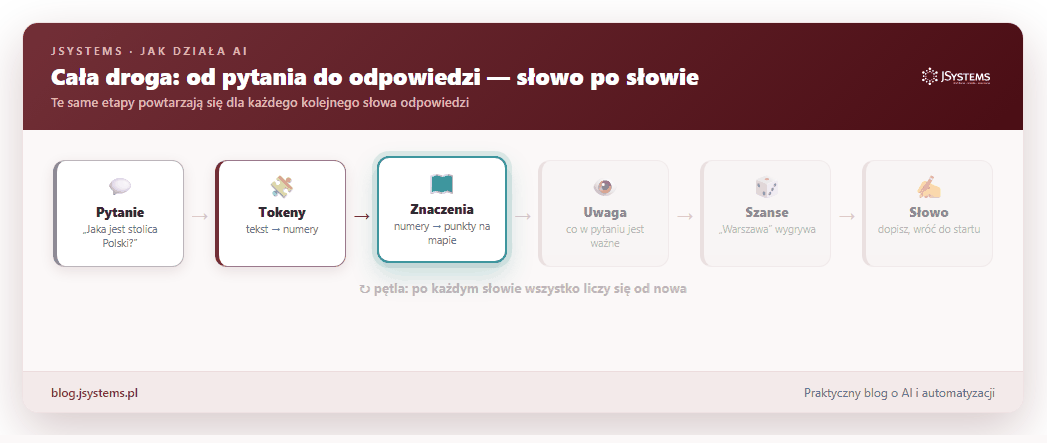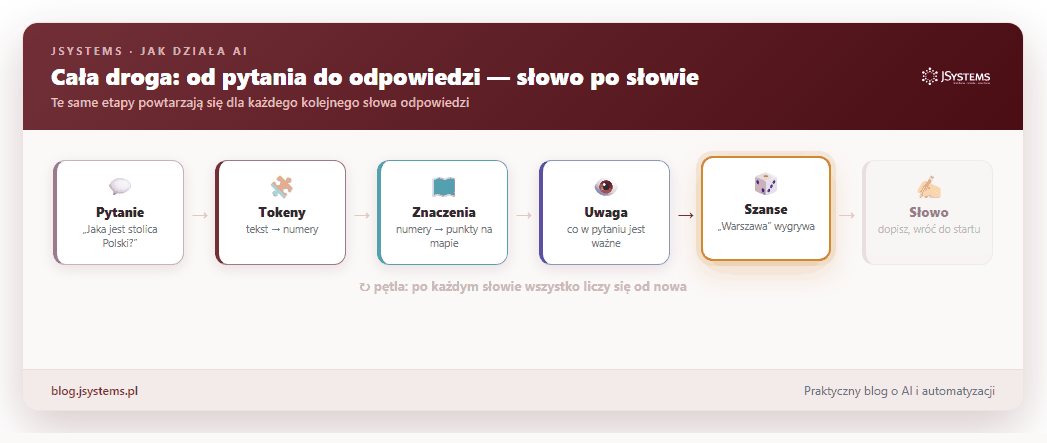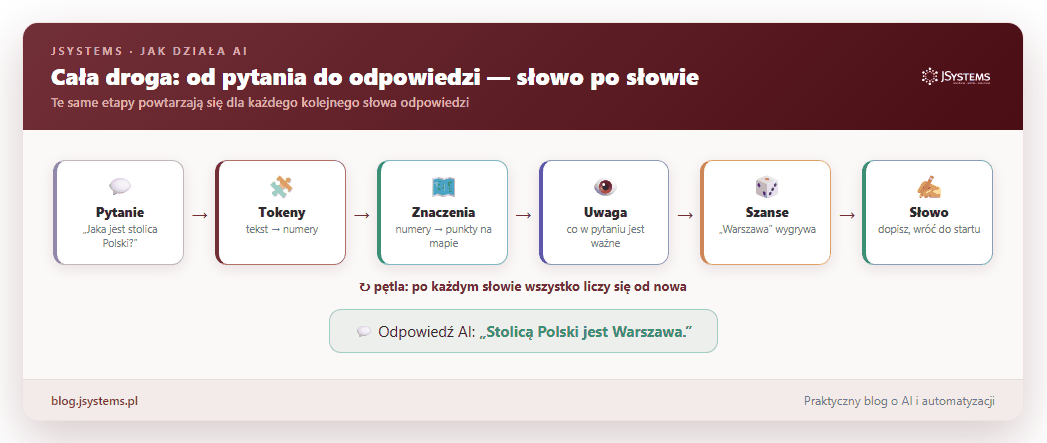
Twoje pytanie zostaje pocięte na tokeny, te zamieniają się w punkty na mapie znaczeń, mechanizm uwagi wyławia z nich to, co istotne, model liczy szanse następnego słowa i jedno z nich wybiera. Potem dokłada je do tekstu i robi to samo jeszcze raz, aż powstanie pełna, sensowna odpowiedź.
Ta wiedza nie jest tylko ciekawostką: bezpośrednio przekłada się na to, jak skutecznie korzystasz z AI:
Najlepsza wiadomość jest taka, że żeby świetnie korzystać z AI, nie musisz umieć programować ani znać matematyki za tym wszystkim. Wystarczy zrozumieć, jak myśli ta maszyna — a tego właśnie uczymy na naszym szkoleniu.

Szkolenie „Sztuczna inteligencja w codziennej pracy” -->
A gdy już oswoisz AI w codziennej pracy, kolejny krok to nauczyć ją działać za Ciebie — samodzielnie wykonywać zadania jako agent:


Komentarze (0)
Brak komentarzy...